







文章目录
什么是神经网络?
房屋预测例子:
输入为特征,比如 size、bedrooms、zip code 等,经过全连接网络,输出房屋价格。
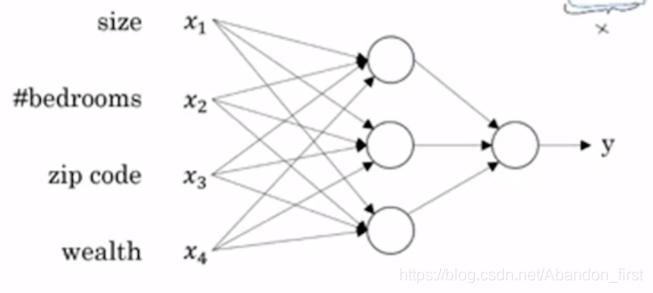
用神经网络进行监督学习
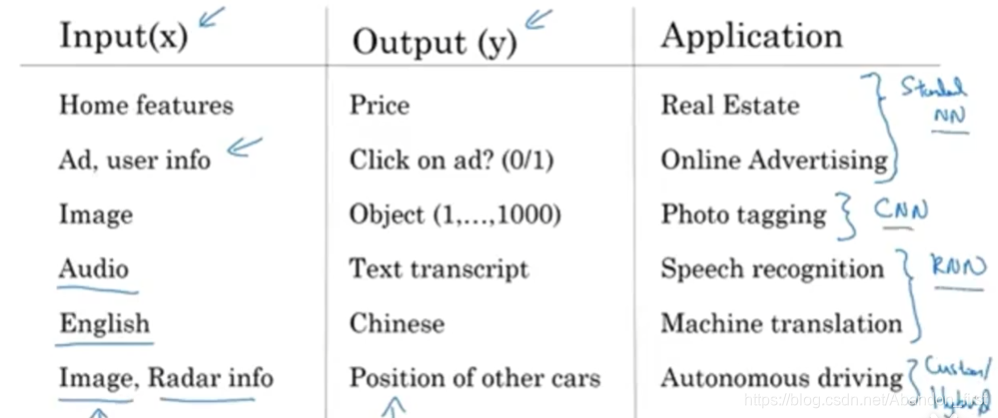
可以进行多种类型的任务,比如估计房价、网络广告、标记图片、语音识别、机器翻译、自动驾驶,所使用的网络种类涵盖了 standard NN、CNN、RNN 和 自定义多模态网络。
所涉及的数据也可以划分为结构化数据表格和非结构化数据图像、语音、文字等。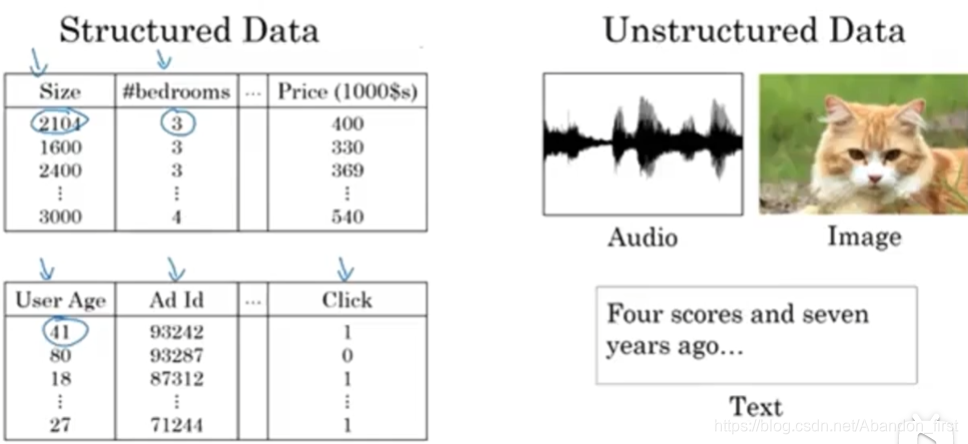
为什么深度学习会兴起
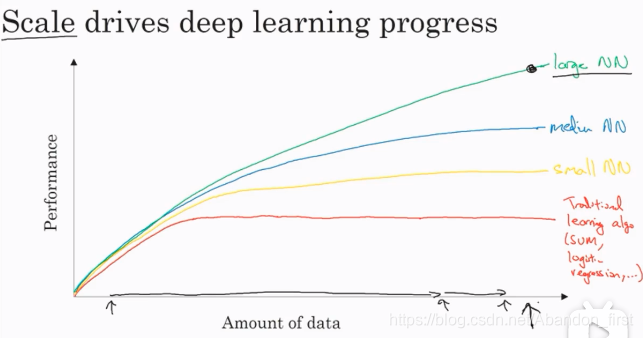
随着大数据时代的到来,深度学习逐渐成为主流。可以理解为,深度学习神经网络的模型表达能力一般优于甚至远远优于传统的机器学习模型,模型参数也大大增加,这是两者各自拥有的特点。当数据量不够的时候,训练神经网络非常容易过拟合,而训练传统的机器学习模型却比较适合。随着数据量尤其某些任务的已标注的数据越来越多时,训练神经网络会比训练传统机器学习模型的收益高得多。
二分分类
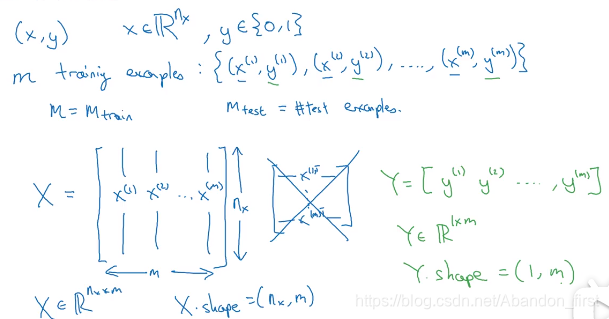
在神经网络的推导过程中,一张图片/样本 flatten 成一个列向量后,然后横向堆叠为矩阵,也就是 m 个样本,特征向量大小为 n(特征空间是 n 维),会堆叠成一个 n 行 m 列的输入矩阵(我不是很喜欢这种,我喜欢 m 行 n 列的……);在此种约定下,每个样本的标记 y 是个 1 行 m 列的矩阵。
多说两句吧,我喜欢 m 行 n 列的是因为矩阵分析中都是以矩阵 A 行 为样本数,列 为特征数,对矩阵 A 的空间进行操作是右乘列向量比如
A
x
=
y
Ax = y
Ax=y 这么个样子。但是此处用 n 行 m 列,其实是更方便去写
y
=
k
x
+
b
y = kx + b
y=kx+b(这么写不严谨,就这么个意思就行)。但其实本质是等价的。
logistic 回归
给定 n 维特征空间的一个样本 x ∈ R x n x \in \mathcal{R}^n_x x∈Rxn(列向量),想求该样本是一只猫的概率为 y ^ \hat y y^(条件概率),模型参数 w ∈ R x n w \in \mathcal{R}^n_x w∈Rxn(列向量), b ∈ R b \in \mathcal{R} b∈R(计算时可以把 w 和 b 放在一起作为 Θ \Theta Θ)。那么有:
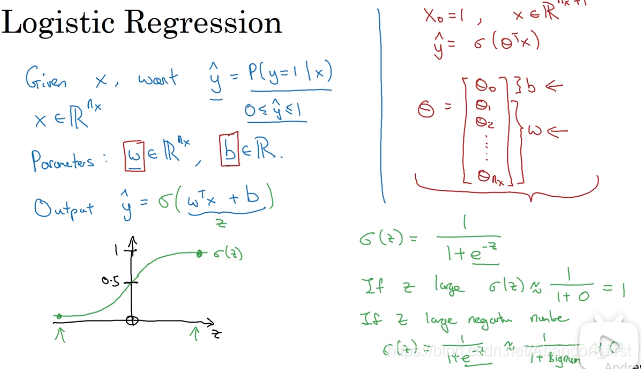
logistic 回归损失函数
朴素地来说,我们希望对于样本数量为 m 的数据集中,预测结果尽可能的接近真实结果。为了训练模型或者说学习到参数,我们需要一个函数来衡量预测与真实结果之间的差异。
这种函数可以有很多,比如均方差函数,但是此处使用 MSE 效果并不好。二分类问题一般使用二值交叉熵损失函数 binary cross entropy,BCE,如下图 L ( y ^ , y ) \mathcal{L}(\hat y, y) L(y^,y)。而对于整个样本数据集来说,损失函数就变成了下图中的 J ( w , b ) J(w, b) J(w,b)。
而所谓的训练学习过程,就是找到那么一组参数 w 和 b,应用在样本集上,使得
J
(
w
,
b
)
J(w, b)
J(w,b) 最小。

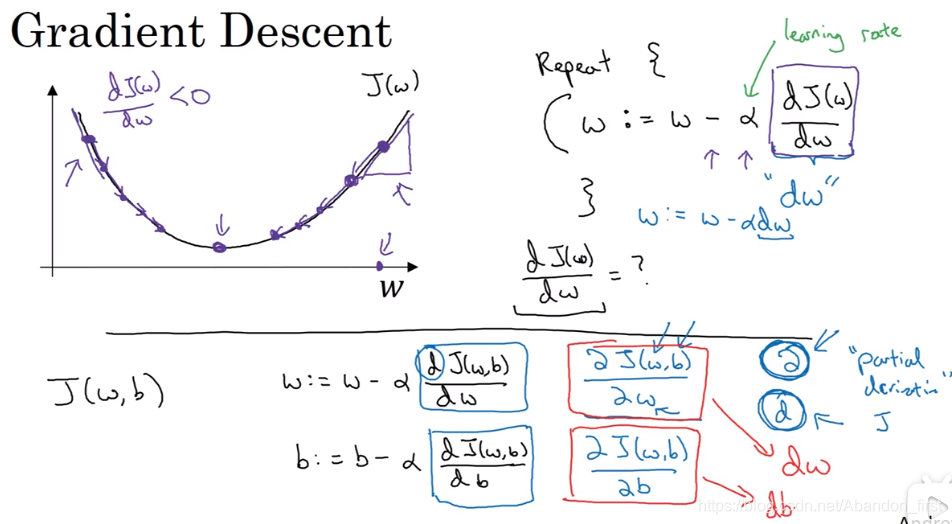
梯度下降法
学习率为
α
\alpha
α,不断地更新参数,直到到达最优解(当然是全局最优解最好)。
计算图
本图为前向计算。

使用计算图求导
链式法则反向求导。

logistic 回归中的梯度下降
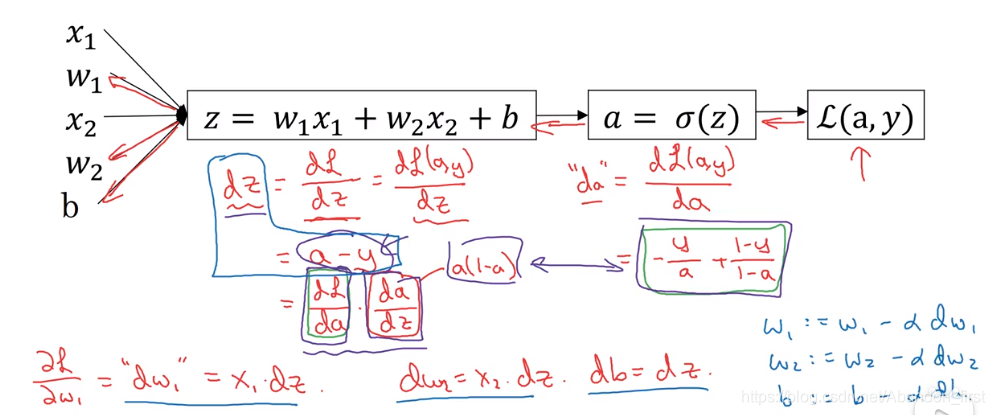
针对单个样本
x
=
[
x
1
,
x
2
]
T
x = [x_1, x_2]^T
x=[x1,x2]T,参数
w
=
[
w
1
,
w
2
]
T
w = [w1, w2]^T
w=[w1,w2]T,以及 loss function 上计算。
z
=
W
T
⋅
X
=
[
w
1
,
w
2
,
b
]
⋅
[
x
1
,
x
2
,
1
]
T
=
w
1
x
1
+
w
2
x
2
+
b
z = W^T \cdot X = [w_1, w_2, b] \cdot [x_1, x_2, 1]^T = w_1 x_1 + w_2 x_2 + b
z=WT⋅X=[w1,w2,b]⋅[x1,x2,1]T=w1x1+w2x2+b
y ^ = a = σ ( z ) \hat y = a = \sigma(z) y^=a=σ(z)
L ( y ^ , y ) = − [ y l g y ^ + ( 1 − y ) l g ( 1 − y ^ ) ] \mathcal{L}(\hat y, y) = -[y lg \hat y + (1-y) lg (1 - \hat y)] L(y^,y)=−[ylgy^+(1−y)lg(1−y^)]
L \mathcal{L} L 对 y ^ \hat y y^ 求导结果为 − y y ^ + 1 − y 1 − y ^ -\frac{y}{\hat y} + \frac{1 - y}{1 - \hat y} −y^y+1−y^1−y
sigmoid 函数求导为 y ^ ∗ ( 1 − y ^ ) \hat y * (1 - \hat y) y^∗(1−y^)
z 对 w 1 w_1 w1 求导为 x 1 x_1 x1。
m 个样本的梯度下降
对于 m 个样本来说,要在 cost function 上计算过程如下图。图中是通过显式地 for 循环来计算权重导数继而进行更新的。后面就会讲到向量化地方式来进行计算,因为数据量太大了,矩阵要用起来了,不然无论是编程代码还是实际运行效率都起不来。

向量化 logistic 回归
不使用 for 循环等。

向量化 logistic 回归的梯度输出
向量化求梯度。
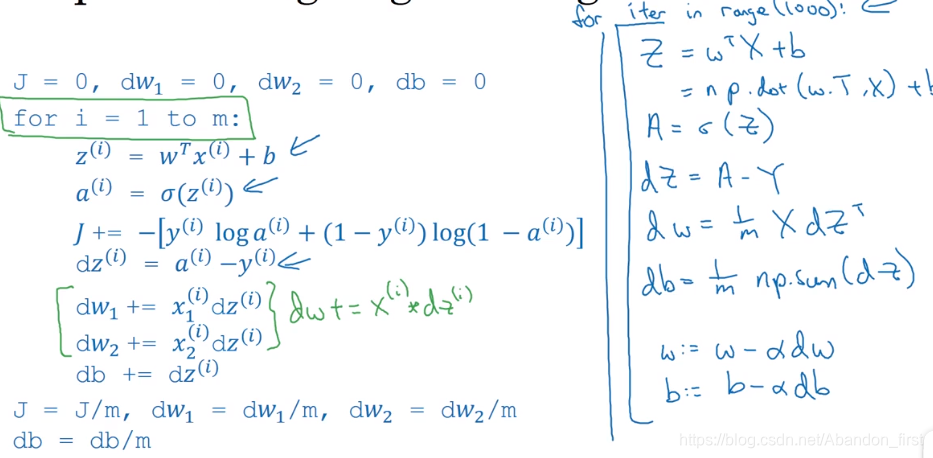
logistic 损失函数的解释

神经网络概览
下图是个两层的神经网络,每个节点运算后都有非线性的,其实就是多层感知机了。图中也包括了前向预测和反向传播。
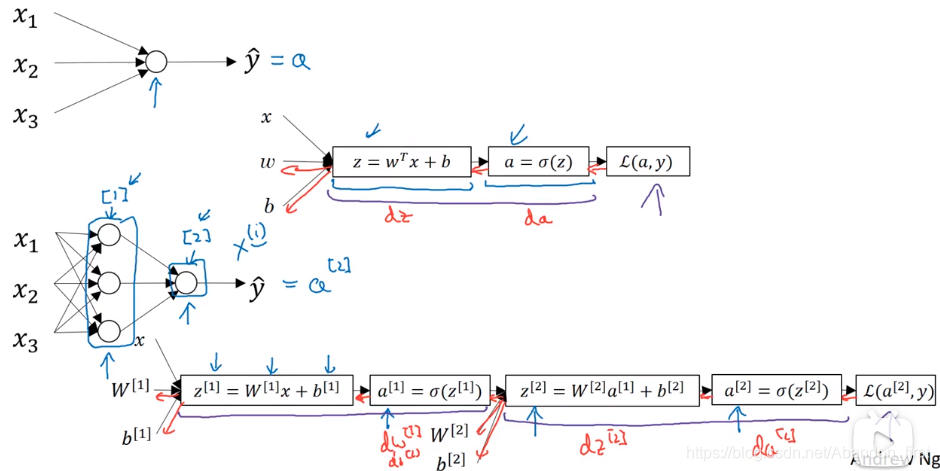
计算神经网络的输出
对于单个样本,有 3 个特征,隐藏层 4 个单元的情况,计算如下。上标表示层数,此时第 1 层中各个神经元对应的权重
w
[
1
]
i
w^[1]_i
w[1]i 都被转置后一行行放在一起为矩阵 W,每行对应一个神经元,所以后面直接写 W × X 而不需要再加转置。列数对应样本数,行数对应特征数。
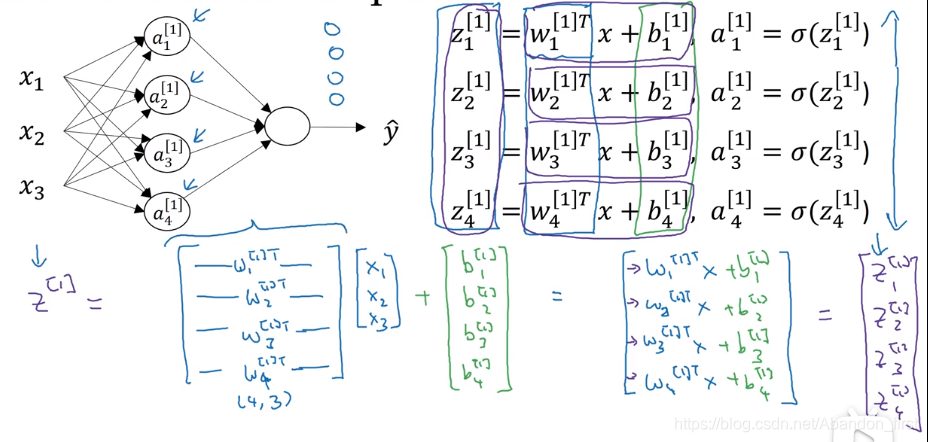
多个样本的向量化
向量化实现的解释
激活函数
- sigmoid 简单,输出范围 0 到 1,还适合当门,但是除了二分类问题的输出层以外,几乎不用, y = 1 1 + e − x y = \frac{1}{1 + e^{-x}} y=1+e−x1,导数 y ′ = y ( 1 − y ) y' = y (1 - y) y′=y(1−y)。
- tanh 比 sigmoid 更好,输出范围 -1 到 1,很适合特征操作, y = e x − e − x e x + e − x y = \frac{e^x - e^{-x}}{e^x + e^{-x}} y=ex+e−xex−e−x,导数 y ′ = 1 − y 2 y' = 1 - y^2 y′=1−y2。
- 常用 Relu 或者 Leaky Relu,虽然左边被抑制了,但是并没什么太大问题,因为神经网络参数实在太多了,部分抑制倒是件好事(有点 dropout 的意思了吧)。
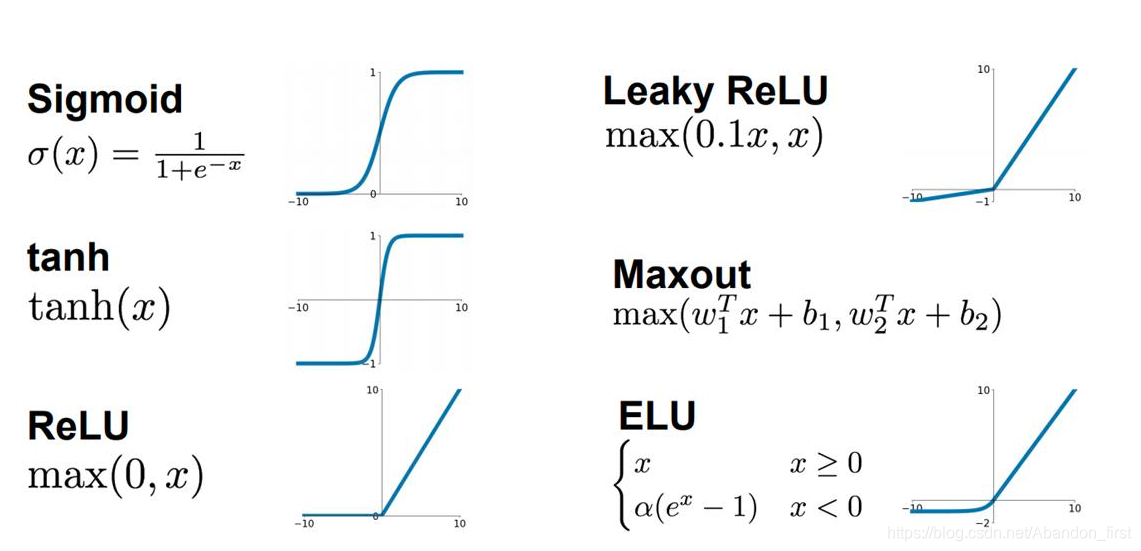
为什么需要非线性激活函数
默认激活函数指的是非线性激活函数。如果没有激活函数,那么模型的能力就只有线性,只能对特征进行线性操作,无论你叠加多少层都是一样的。简单的例子,没有激活函数,异或问题都解决不了。
神经网络的梯度下降法和反向传播
这里我自己写一遍吧,TODO。顺便写一下为啥初始化不能全为 0。(记得吧,因为更新量是 负学习率乘以导数,然后那个导数,最前面的 w 的导数和输入有关,中间 w 的导数和对应节点值要乘积的,如果权重最开始都为 0 ,那么更新不了。)
随机初始化
老师这里说的是,如果全都为 0,那么同一层上的神经元就完全对称,一模一样,一开始做的操作一模一样,对输出的影响也一模一样,反向传播的时候也一模一样,多个隐藏层单元的设计也就毫无意义了。所以 w 的初始化必须是随机的,可以是比较小的随机值,这样刚刚开始学习的时候,落在激活函数中间部分,这样比较容易更新(反之梯度消失)。而 b 不存在什么对称性问题,所以 b 完全可以初始化为 0。
所以正则化也是惩罚权重的绝对值太大,惩罚他们去激活函数的两侧陷入平坦区而无法进一步学习。
深层神经网络
前向和反向传播
这个地方向量化前向和反向传播应该写一写
深层网络中的前向传播
核对矩阵的维数
每个步骤确保无误是 debug 的万能钥匙。
为什么使用深层表示
没有那么多想象空间,名字有点引人“浮想联翩”,逐步操作特征而已。对很多简单的问题,我们都会从逻辑回归开始。实际使用神经网络过程中,可以把网络的层数作为超参数来不断调整。只有在某些问题上,很深的网络才有必要。
这和大脑有什么关系
不排除有些想法会受到大脑或者某些生物现象的启发,但是本质上来讲,大脑和神经网络其实没什么关系。哈哈哈忍不住笑。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









