





已在GitHub开源与本博客同步的YOLOv7_RK3588_object_detect项目,地址:https://github.com/A7bert777/YOLOv7_RK3588_object_detect
详细使用教程,可参考README.md或参考本博客第六章 模型部署
注:本文是以瑞芯微RK3588 SoC进行示例,同时也可支持瑞芯微其他系列SoC:RK3562、RK3566、RK3568、RK3576、RK3399PRO、RK1808、RV1126、RV1126B、RV1103、RV1106、RV1109等,部署流程也基本一致,如需帮助,可通过Github仓库的 README.md 沟通。
一、项目回顾
博主之前有写过YOLO11、YOLOv8目标检测&图像分割、YOLOv10、v5目标检测、MoblieNetv2、ResNet50图像分类的模型训练、转换、部署文章,感兴趣的小伙伴可以了解下:
【YOLO11-obb部署至RK3588】模型训练→转换RKNN→开发板部署
【YOLO11部署至RK3588】模型训练→转换RKNN→开发板部署
【YOLOv10部署RK3588】模型训练→转换rknn→部署流程
【YOLOv8-obb部署至RK3588】模型训练→转换RKNN→开发板部署
【YOLOv8-pose部署至RK3588】模型训练→转换RKNN→开发板部署
【YOLOv8seg部署RK3588】模型训练→转换rknn→部署全流程
【YOLOv8部署至RK3588】模型训练→转换rknn→部署全流程
【YOLOv7部署至RK3588】模型训练→转换RKNN→开发板部署
【YOLOv6部署至RK3588】模型训练→转换RKNN→开发板部署
【YOLOv5部署至RK3588】模型训练→转换RKNN→开发板部署
【MobileNetv2图像分类部署至RK3588】模型训练→转换rknn→部署流程
【ResNet50图像分类部署至RK3588】模型训练→转换RKNN→开发板部署
YOLOv8n部署RK3588开发板全流程(pt→onnx→rknn模型转换、板端后处理检测)
二、模型选择介绍
近期需要做一个针对图像目标检测的模型,并部署到RK3588公版的开发板上,可选择的有YOLOv5、YOLOv8、YOLOv10、YOLO11,其他算法都已经部署过了,目前还没有部署过YOLOv7,因此准备出一篇YOLOv7的全流程部署教程,以此文记录,相互学习,诸君共勉。
三、项目文件梳理
YOLOv7训练、转换、部署所需三个项目文件:
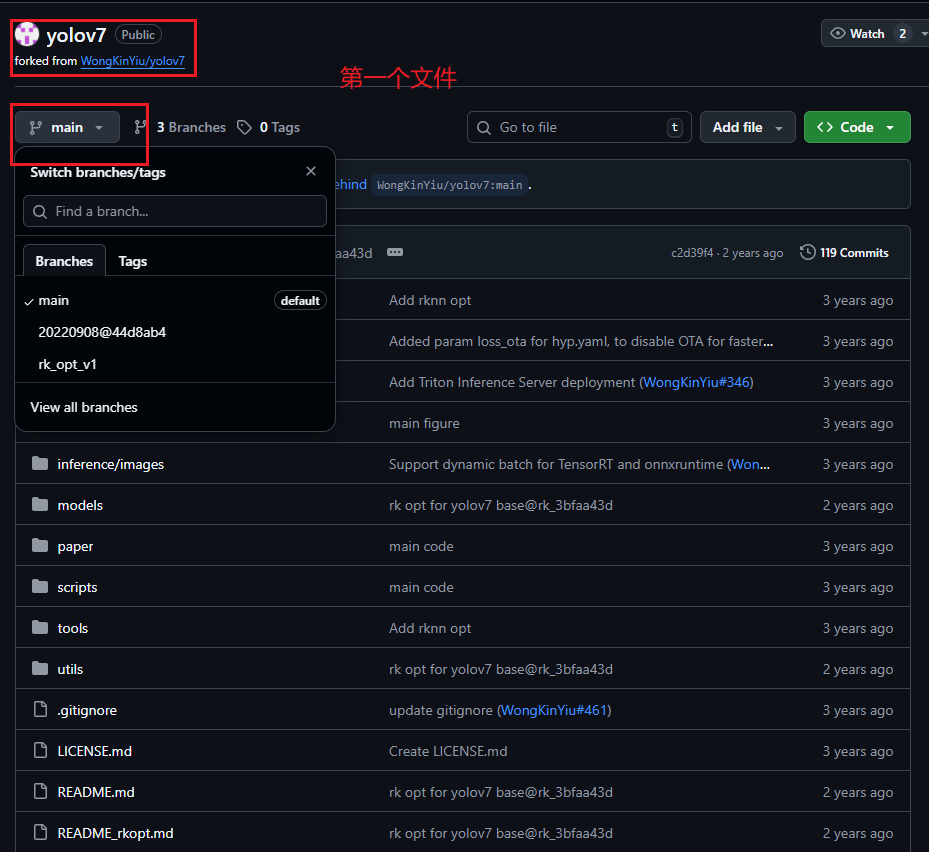
第一个:YOLOv7模型训练以及转换onnx的项目文件(链接在此);
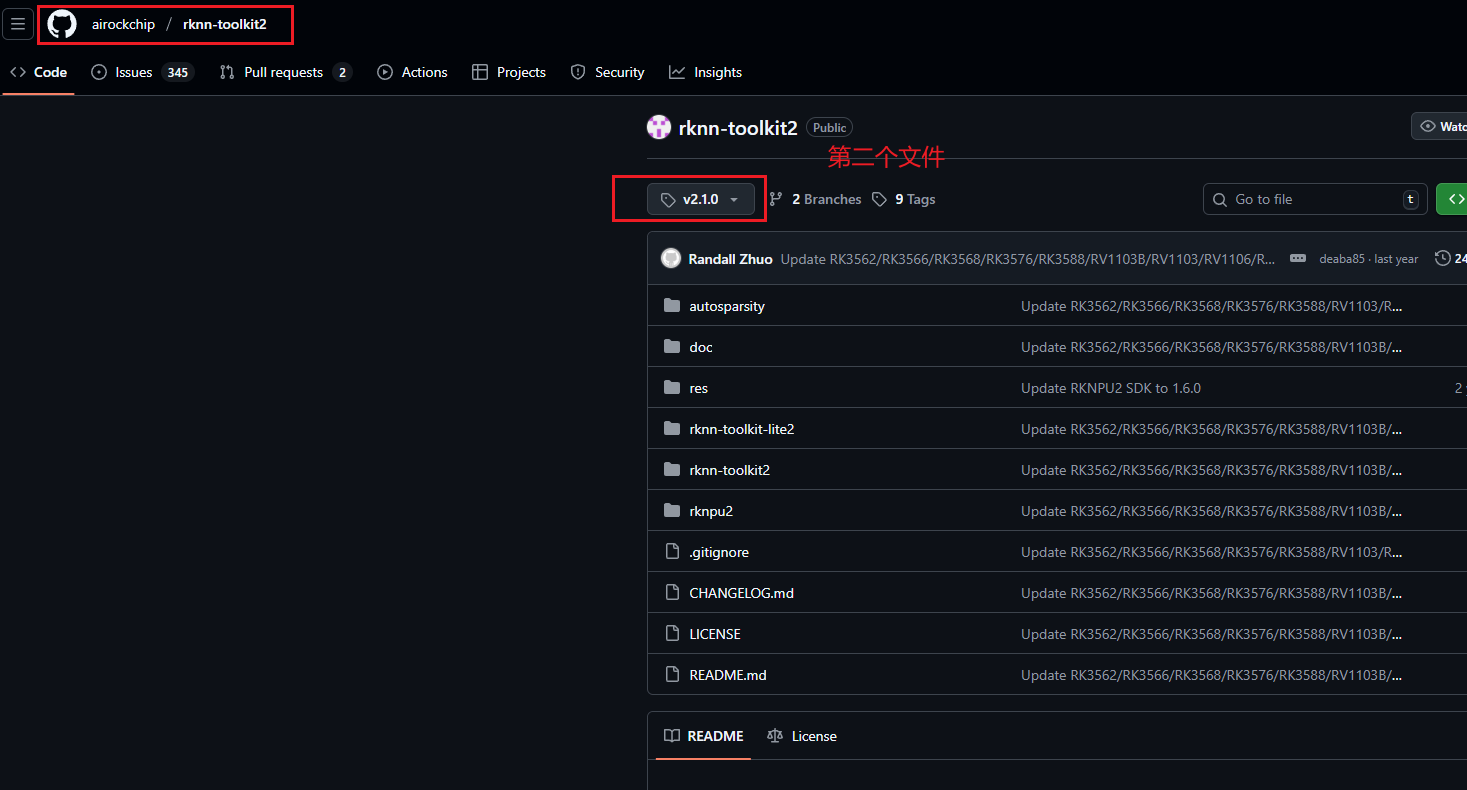
第二个:用于在虚拟机中进行onnx转rknn的虚拟环境配置项目文件(链接在此);
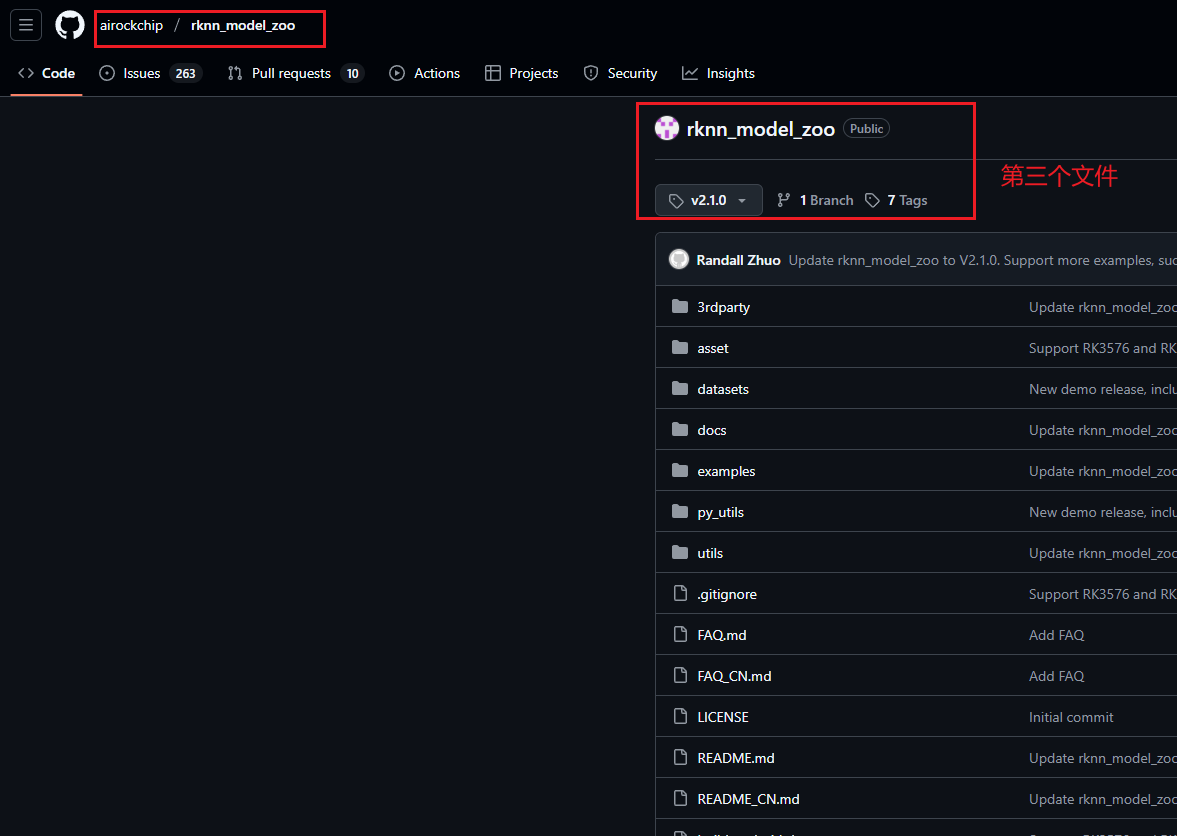
第三个:在开发板上做模型部署的项目文件(链接在此);
这里说下为什么第一个文件要用瑞芯微的仓库而不是ultralytics官方的仓库,瑞芯微的官方回复如下:
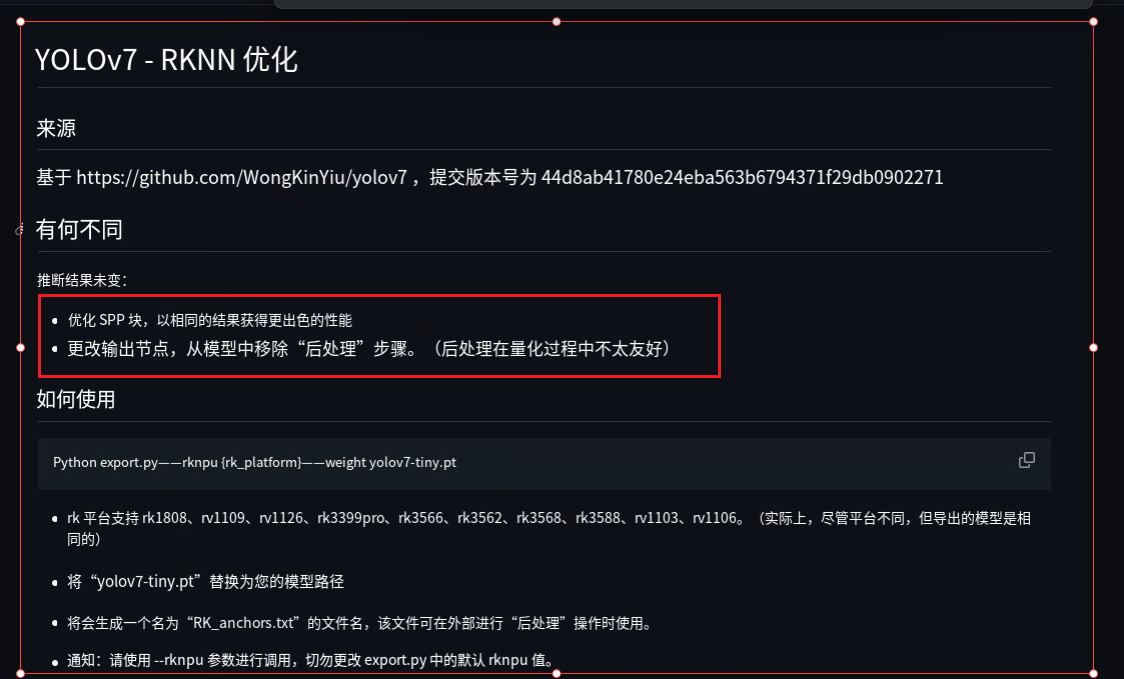
主要是因为要优化SPP块并且更改输出节点,将后处理步骤改成C++代码的实现
当然了,如果你就是想用ultralytics官方的yolov7去训练,其实也没有问题,但要记得在转换ONNX模型时一定要在瑞芯微的yolov7项目下进行**
注:第一个文件使用main版本,第二个和第三个文件均使用2.1.0tag版本
如下所示:
四、YOLOv7模型训练 & PT转ONNX
先将第一个文件 git clone 后,先修改下其中的requirements.txt,原来的requirements.txt如下所示:
# Usage: pip install -r requirements.txt
# Base ----------------------------------------
matplotlib>=3.2.2
numpy>=1.18.5
opencv-python>=4.1.1
Pillow>=7.1.2
PyYAML>=5.3.1
requests>=2.23.0
scipy>=1.4.1
torch>=1.7.0,!=1.12.0
torchvision>=0.8.1,!=0.13.0
tqdm>=4.41.0
protobuf<4.21.3
# Logging -------------------------------------
tensorboard>=2.4.1
# wandb
# Plotting ------------------------------------
pandas>=1.1.4
seaborn>=0.11.0
# Export --------------------------------------
# coremltools>=4.1 # CoreML export
# onnx>=1.9.0 # ONNX export
# onnx-simplifier>=0.3.6 # ONNX simplifier
# scikit-learn==0.19.2 # CoreML quantization
# tensorflow>=2.4.1 # TFLite export
# tensorflowjs>=3.9.0 # TF.js export
# openvino-dev # OpenVINO export
# Extras --------------------------------------
ipython # interactive notebook
psutil # system utilization
thop # FLOPs computation
# albumentations>=1.0.3
# pycocotools>=2.0 # COCO mAP
# roboflow
然后把其中的
# onnx>=1.9.0 # ONNX export
# onnx-simplifier>=0.3.6 # ONNX simplifier
这两行的注释放开,因为我们后面还要用这个环境去转换onnx模型,所以需要onnx包
完整的requirements.txt如下所示:
# Usage: pip install -r requirements.txt
# Base ----------------------------------------
matplotlib>=3.2.2
numpy>=1.18.5
opencv-python>=4.1.1
Pillow>=7.1.2
PyYAML>=5.3.1
requests>=2.23.0
scipy>=1.4.1
torch>=1.7.0,!=1.12.0
torchvision>=0.8.1,!=0.13.0
tqdm>=4.41.0
protobuf<4.21.3
# Logging -------------------------------------
tensorboard>=2.4.1
# wandb
# Plotting ------------------------------------
pandas>=1.1.4
seaborn>=0.11.0
# Export --------------------------------------
# coremltools>=4.1 # CoreML export
onnx>=1.9.0 # ONNX export
onnx-simplifier>=0.3.6 # ONNX simplifier
# scikit-learn==0.19.2 # CoreML quantization
# tensorflow>=2.4.1 # TFLite export
# tensorflowjs>=3.9.0 # TF.js export
# openvino-dev # OpenVINO export
# Extras --------------------------------------
ipython # interactive notebook
psutil # system utilization
thop # FLOPs computation
# albumentations>=1.0.3
# pycocotools>=2.0 # COCO mAP
# roboflow
完整requirements.txt的修改后,可以创建并安装conda环境:
conda create -n yolov7_pt2onnx python=3.8
conda activate yolov7_pt2onnx
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
等待安装完成
将train.py下的 if name == ‘main’: 中的参数进行修改,包括weights、cfg、data、epochs、batch-size等,如下所示:
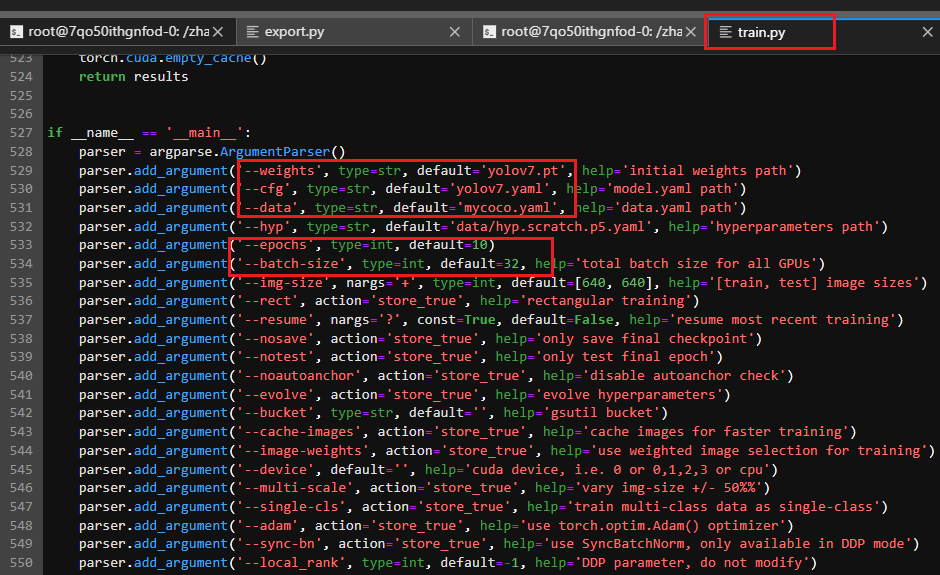
yolov7.pt建议自己去官网先下好,不然训练前做AMP的时候会自动下载,速度较慢
yolov7.yaml如下所示(可直接复制我的):
# parameters
nc: 8 # number of classes
depth_multiple: 1.0 # model depth multiple
width_multiple: 1.0 # layer channel multiple
# anchors
anchors:
- [12,16, 19,36, 40,28] # P3/8
- [36,75, 76,55, 72,146] # P4/16
- [142,110, 192,243, 459,401] # P5/32
# yolov7 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Conv, [32, 3, 1]], # 0
[-1, 1, Conv, [64, 3, 2]], # 1-P1/2
[-1, 1, Conv, [64, 3, 1]],
[-1, 1, Conv, [128, 3, 2]], # 3-P2/4
[-1, 1, Conv, [64, 1, 1]],
[-2, 1, Conv, [64, 1, 1]],
[-1, 1, Conv, [64, 3, 1]],
[-1, 1, Conv, [64, 3, 1]],
[-1, 1, Conv, [64, 3, 1]],
[-1, 1, Conv, [64, 3, 1]],
[[-1, -3, -5, -6], 1, Concat, [1]],
[-1, 1, Conv, [256, 1, 1]], # 11
[-1, 1, MP, []],
[-1, 1, Conv, [128, 1, 1]],
[-3, 1, Conv, [128, 1, 1]],
[-1, 1, Conv, [128, 3, 2]],
[[-1, -3], 1, Concat, [1]], # 16-P3/8
[-1, 1, Conv, [128, 1, 1]],
[-2, 1, Conv, [128, 1, 1]],
[-1, 1, Conv, [128, 3, 1]],
[-1, 1, Conv, [128, 3, 1]],
[-1, 1, Conv, [128, 3, 1]],
[-1, 1, Conv, [128, 3, 1]],
[[-1, -3, -5, -6], 1, Concat, [1]],
[-1, 1, Conv, [512, 1, 1]], # 24
[-1, 1, MP, []],
[-1, 1, Conv, [256, 1, 1]],
[-3, 1, Conv, [256, 1, 1]],
[-1, 1, Conv, [256, 3, 2]],
[[-1, -3], 1, Concat, [1]], # 29-P4/16
[-1, 1, Conv, [256, 1, 1]],
[-2, 1, Conv, [256, 1, 1]],
[-1, 1, Conv, [256, 3, 1]],
[-1, 1, Conv, [256, 3, 1]],
[-1, 1, Conv, [256, 3, 1]],
[-1, 1, Conv, [256, 3, 1]],
[[-1, -3, -5, -6], 1, Concat, [1]],
[-1, 1, Conv, [1024, 1, 1]], # 37
[-1, 1, MP, []],
[-1, 1, Conv, [512, 1, 1]],
[-3, 1, Conv, [512, 1, 1]],
[-1, 1, Conv, [512, 3, 2]],
[[-1, -3], 1, Concat, [1]], # 42-P5/32
[-1, 1, Conv, [256, 1, 1]],
[-2, 1, Conv, [256, 1, 1]],
[-1, 1, Conv, [256, 3, 1]],
[-1, 1, Conv, [256, 3, 1]],
[-1, 1, Conv, [256, 3, 1]],
[-1, 1, Conv, [256, 3, 1]],
[[-1, -3, -5, -6], 1, Concat, [1]],
[-1, 1, Conv, [1024, 1, 1]], # 50
]
# yolov7 head
head:
[[-1, 1, SPPCSPC, [512]], # 51
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[37, 1, Conv, [256, 1, 1]], # route backbone P4
[[-1, -2], 1, Concat, [1]],
[-1, 1, Conv, [256, 1, 1]],
[-2, 1, Conv, [256, 1, 1]],
[-1, 1, Conv, [128, 3, 1]],
[-1, 1, Conv, [128, 3, 1]],
[-1, 1, Conv, [128, 3, 1]],
[-1, 1, Conv, [128, 3, 1]],
[[-1, -2, -3, -4, -5, -6], 1, Concat, [1]],
[-1, 1, Conv, [256, 1, 1]], # 63
[-1, 1, Conv, [128, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[24, 1, Conv, [128, 1, 1]], # route backbone P3
[[-1, -2], 1, Concat, [1]],
[-1, 1, Conv, [128, 1, 1]],
[-2, 1, Conv, [128, 1, 1]],
[-1, 1, Conv, [64, 3, 1]],
[-1, 1, Conv, [64, 3, 1]],
[-1, 1, Conv, [64, 3, 1]],
[-1, 1, Conv, [64, 3, 1]],
[[-1, -2, -3, -4, -5, -6], 1, Concat, [1]],
[-1, 1, Conv, [128, 1, 1]], # 75
[-1, 1, MP, []],
[-1, 1, Conv, [128, 1, 1]],
[-3, 1, Conv, [128, 1, 1]],
[-1, 1, Conv, [128, 3, 2]],
[[-1, -3, 63], 1, Concat, [1]],
[-1, 1, Conv, [256, 1, 1]],
[-2, 1, Conv, [256, 1, 1]],
[-1, 1, Conv, [128, 3, 1]],
[-1, 1, Conv, [128, 3, 1]],
[-1, 1, Conv, [128, 3, 1]],
[-1, 1, Conv, [128, 3, 1]],
[[-1, -2, -3, -4, -5, -6], 1, Concat, [1]],
[-1, 1, Conv, [256, 1, 1]], # 88
[-1, 1, MP, []],
[-1, 1, Conv, [256, 1, 1]],
[-3, 1, Conv, [256, 1, 1]],
[-1, 1, Conv, [256, 3, 2]],
[[-1, -3, 51], 1, Concat, [1]],
[-1, 1, Conv, [512, 1, 1]],
[-2, 1, Conv, [512, 1, 1]],
[-1, 1, Conv, [256, 3, 1]],
[-1, 1, Conv, [256, 3, 1]],
[-1, 1, Conv, [256, 3, 1]],
[-1, 1, Conv, [256, 3, 1]],
[[-1, -2, -3, -4, -5, -6], 1, Concat, [1]],
[-1, 1, Conv, [512, 1, 1]], # 101
[75, 1, RepConv, [256, 3, 1]],
[88, 1, RepConv, [512, 3, 1]],
[101, 1, RepConv, [1024, 3, 1]],
[[102,103,104], 1, IDetect, [nc, anchors]], # Detect(P3, P4, P5)
]
只需改成自己数据集的类别即可,我的数据集中共有8个类别
mycoco.yaml如下所示(可直接复制我的,但是要把数据集路径和类别数量及类别名称改成自己的):
# COCO 2017 dataset http://cocodataset.org
# download command/URL (optional)
#download: bash ./scripts/get_coco.sh
# train and val data as 1) directory: path/images/, 2) file: path/images.txt, or 3) list: [path1/images/, path2/images/]
train: /xxx/Dataset/Constrution/MOCS/MOCS/images/train # 118287 images
val: /xxx/Dataset/Constrution/MOCS/MOCS/images/val # 5000 images
#test: ./coco/test-dev2017.txt # 20288 of 40670 images, submit to https://competitions.codalab.org/competitions/20794
# number of classes
nc: 8
# class names
names: [ 'Worker', 'Bulldozer', 'Excavator', 'Truck', 'Loader', 'Pump truck', 'Concrete transport Mixer', 'Pile driver']
至于batchsize和epoch就因人而异了,我主要是做个演示,所以epoch就设为10,常规设置为300,batchsize为64
执行train.py进行训练:
python train.py
训练完成后,终端结果如下所示:
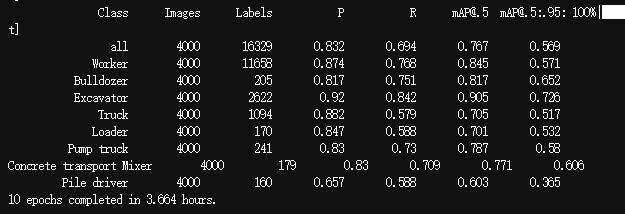
可以看到,仅10个epoch,就花了近四个小时,yolov7的缺点就是模型太大,训练和推理的速度比较慢
训练完成后,将best.pt模型复制到yolov7-main路径下,我将其重命名为yolov7_best.pt,如下所示:
然后在终端执行转换命令:
python export.py --rknpu --weight yolov7_best.pt
结果如下所示:
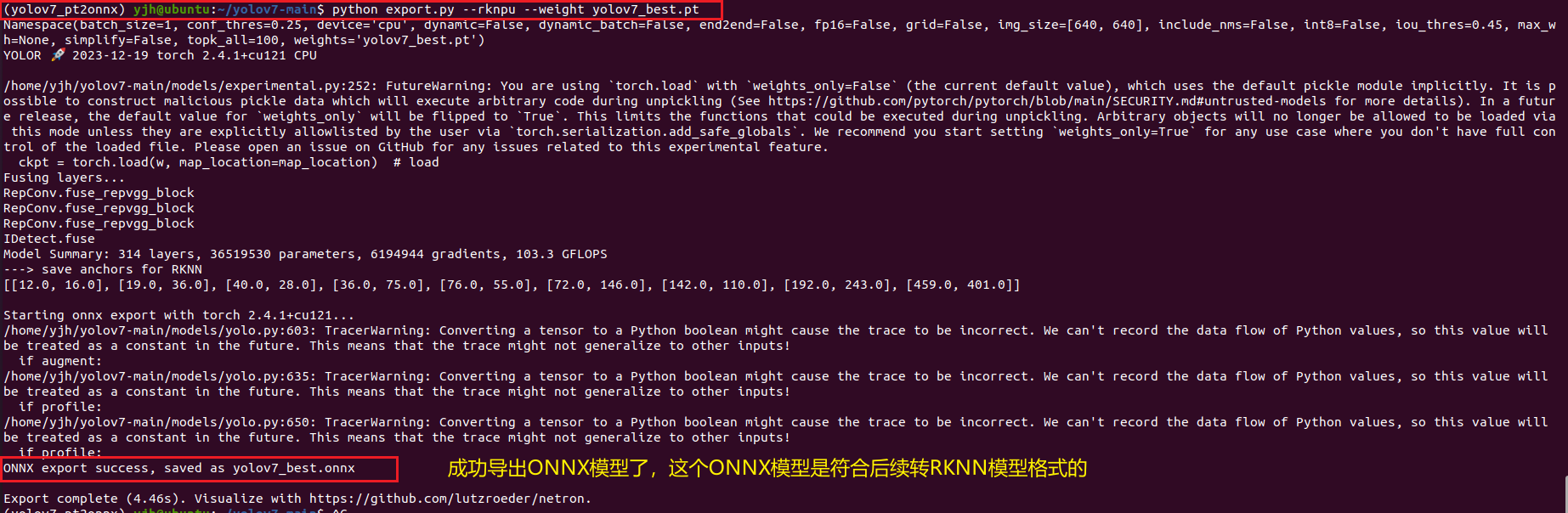
然后就能在yolov7-main路径下看到刚生成的ONNX模型:
用netron工具打开这个onnx模型,输入输出应该大致如下所示:
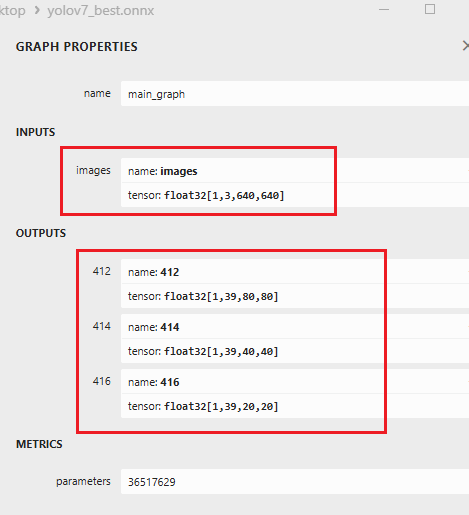
输入应该是一个通道,输出是三个通道,如果不是的话,说明你的ONNX模型转出失败,不符合瑞芯微部署的要求。
五、ONNX转RKNN
在进行这一步的时候,如果你是在云服务器上运行,请先确保你租的卡能支持RKNN的转换运行。博主是在自己的虚拟机中进行转换。
先安装转换环境
这里我们先创建环境:
conda create -n rknn210 python=3.8
创建完成如下所示:

现在需要用到 第二个文件:rknn-toolkit2-2.1.0文件 。
进入rknn-toolkit2-2.1.0\rknn-toolkit2-2.1.0\rknn-toolkit2\packages文件夹下,看到如下内容:

在终端激活环境,在终端输入
pip install -r requirements_cp38-2.1.0.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
然后再输入
pip install rknn_toolkit2-2.1.0+708089d1-cp38-cp38-linux_x86_64.whl
然后,我们的转rknn环境就配置完成了。
现在要进行模型转换,其实大家可以参考rknn_model_zoo-2.1.0\examples\yolov7下的README指导进行转换:
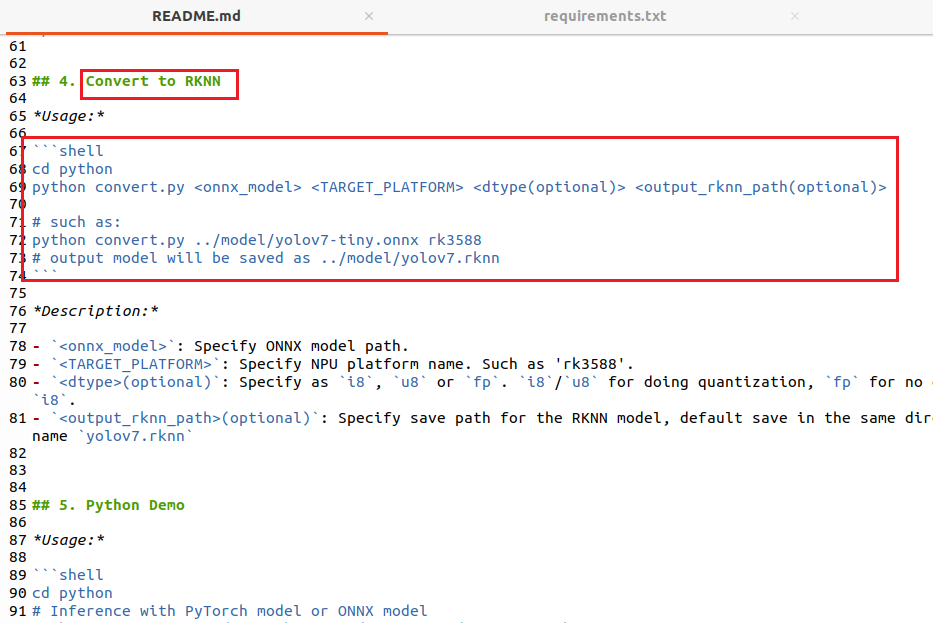
这里我也详细再说一遍转换流程,修改/rknn_model_zoo-2.1/examples/yolov7/python/convert.py,如下所示:
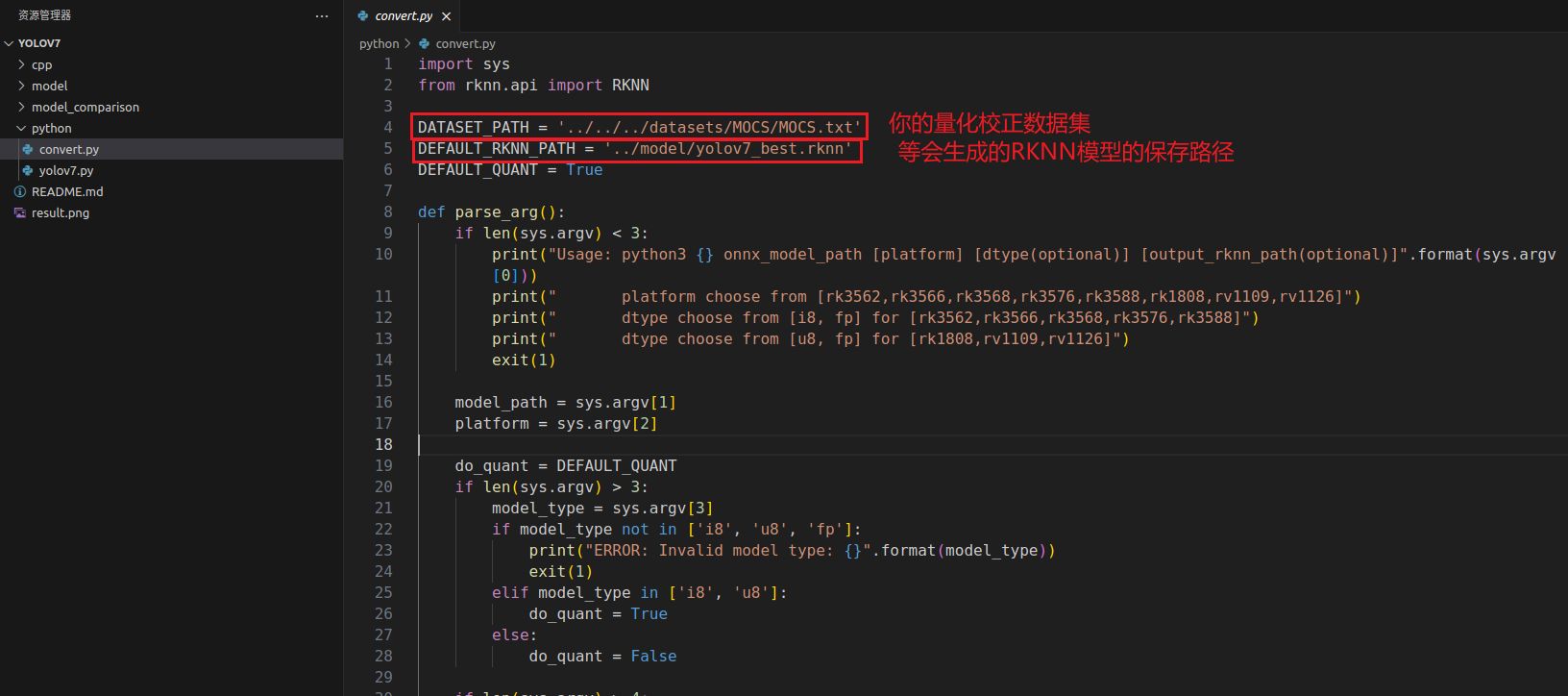
修改完成后,将我们之前得到的onnx模型复制到model文件夹下:
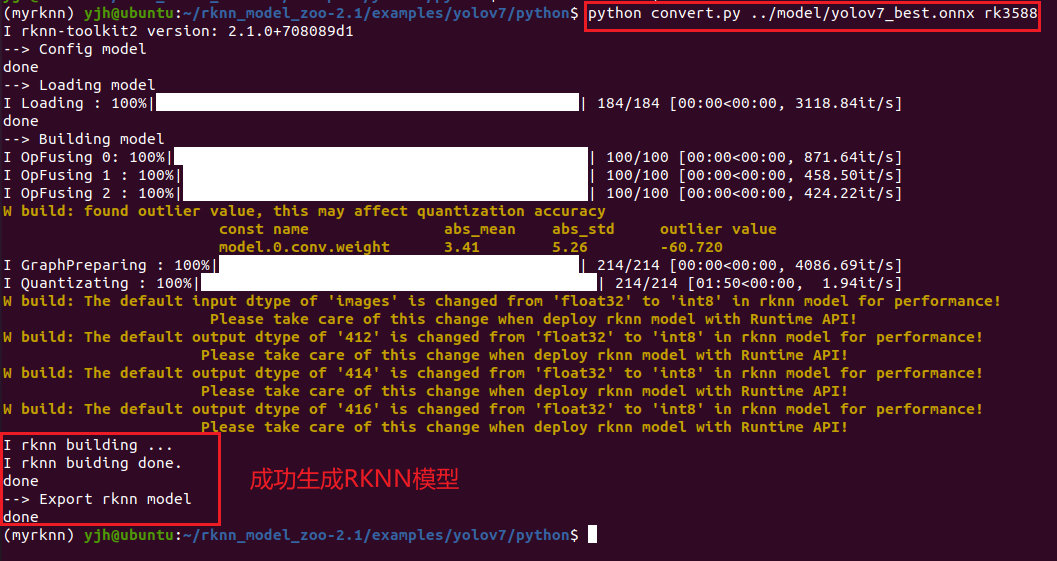
激活刚才提到的conda环境后,执行python文件夹下的转换脚本convert.py:
python convert.py ../model/yolov7_best.onnx rk3588
如下所示:
然后在model文件夹下就会看到生成的RKNN模型:
用netron打开rknn模型,输入输出如下所示:
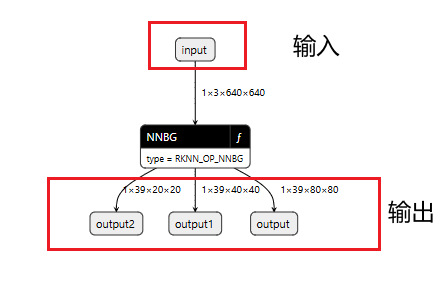
可以看到,正确转出的RKNN模型,和ONNX模型的结构一致,同为1个输入通道,3个输出通道。
六、模型部署
如果前面流程都已实现,模型的结构也没问题的话,则可以进行最后一步:模型端侧部署。
我已经帮大家做好了所有的环境适配工作,科学上网后访问博主GitHub仓库: YOLOv7_RK3588_object_detect,进行简单的路径修改就即可编译运行。
统一声明:
1、这个仓库的项目只能做图片的批量检测,不支持视频流检测,没时间做这个,有需要的自己修改代码。
2、从GitHub的README.md中加QQ后直接说问题和小星星截图,对于常见的相同问题,很多都已在优快云博客中提到了(RKNN转换流程是统一的,可去博主所有的RKNN相关博客下去翻评论),已在评论中详细解释过的问题,不予回复。
我已经把自己的RKNN模型放到了Github项目的model文件夹下、测试图片放到inputimage文件夹下,大家 git clone 后可直接先把build下内容删掉然后重新编译,在用我的RKNN模型和图片直接运行测试。
git clone后把项目复制到开发板上,按如下流程操作:
①:cd build,删除所有build文件夹下的内容
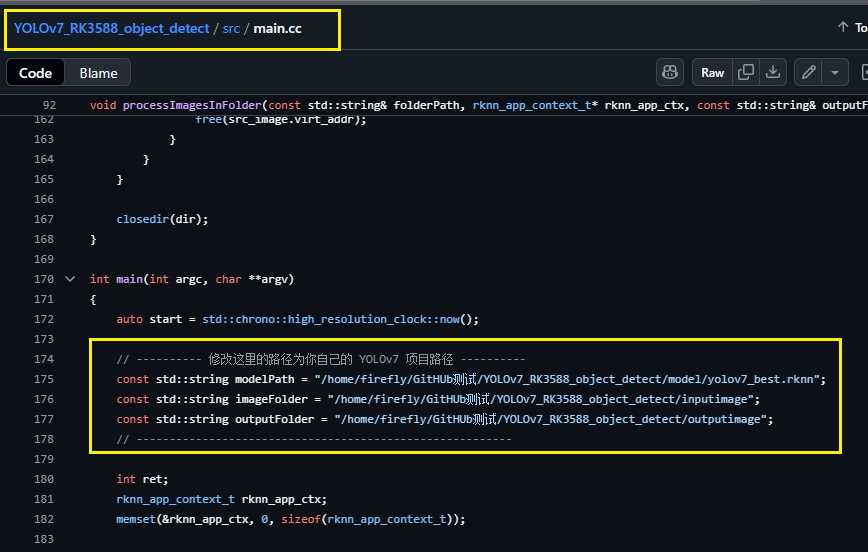
②:cd src 修改main.cc,修改main函数中的如下三个内容,将这三个参数改成自己的绝对路径:
③:cd src 修改postprocess.cc下的txt标签的绝对路径:
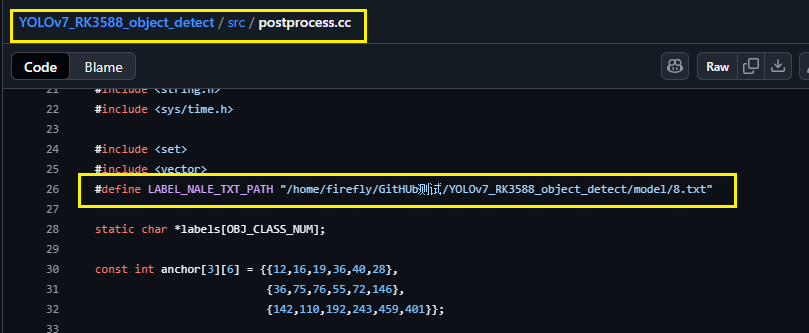
解释一下,这个标签路径中的内容如下所示:
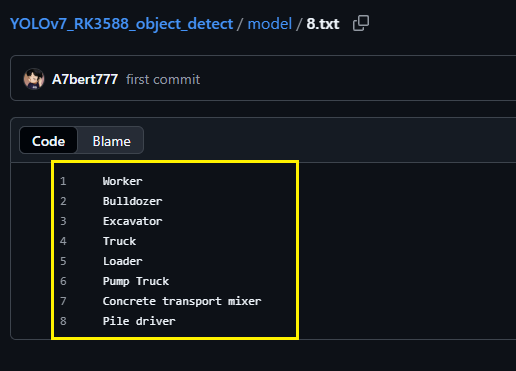
其实就是你在训练模型时在yaml配置文件中的那几个类别名(如果你先用博主的RKNN模型测试,则无需要改txt中的内容)
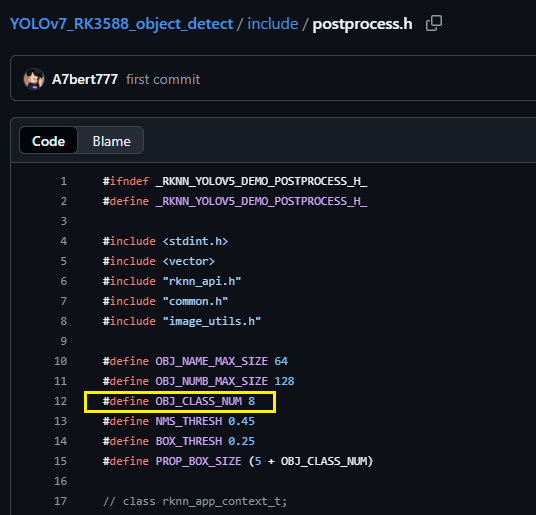
④修改include/postprocess.h 中的宏 OBJ_CLASS_NUM
⑤:把你之前训练好并已转成RKNN格式的模型放到 model 文件夹下,然后把你要检测的所有图片都放到 inputimage 文件夹下,在运行程序后,生成的结果图片在 outputimage 目录下。
⑥:进入build文件夹进行编译
cd build
cmake ..
make
在build下生成可执行文件文件:rknn_yolov7_demo
在build路径下输入
./rknn_yolov7_demo
运行结果如下所示:
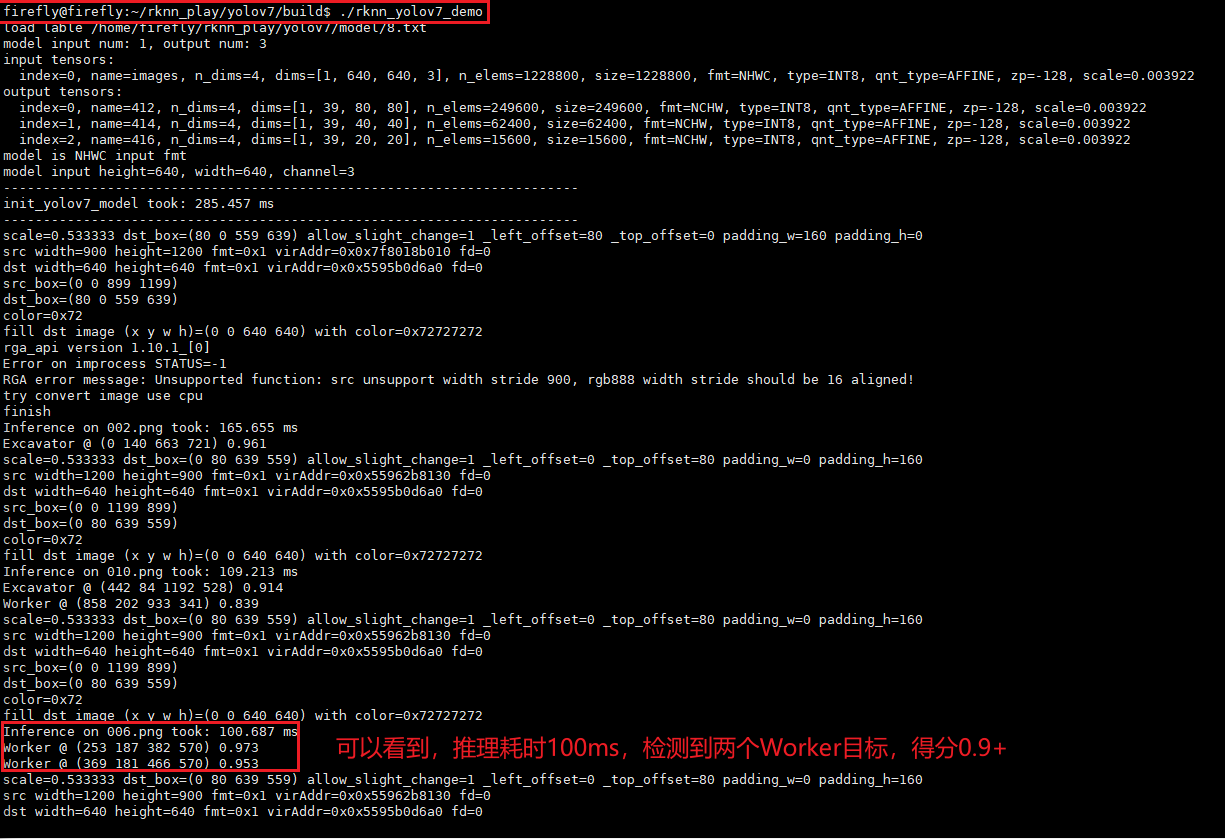
生成的结果图片在 outputimage 目录下,我也将其上传到Github项目中:
在执行完 ./rknn_yolov7_demo 后在 outputimage 下的输出结果图片示例:








上述即博主此次更新的YOLOv7部署RK3588,包含PT转ONNX转RKNN的全流程步骤,欢迎交流!



















 1858
1858

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









