




前言
- 现代Internet服务通常被实现为复杂的、大规模的分布式系统。这些应用程序是由软件模块的集合构成的,这些模块可能由不同的团队开发,可能使用不同的编程语言,可能跨越多个物理设施的数千台机器。在这样的环境中,帮助理解系统行为和对性能问题进行推理的工具是非常宝贵的。
- 现有的分布式追踪工具基本都是借鉴了 google Dapper的设计思想来实现的。google dapper
原理
- 通过收集每一个server接收和发送消息的信息(消息标识符、时间戳)来实现请求的分布式追踪。
Dapper中的模型:
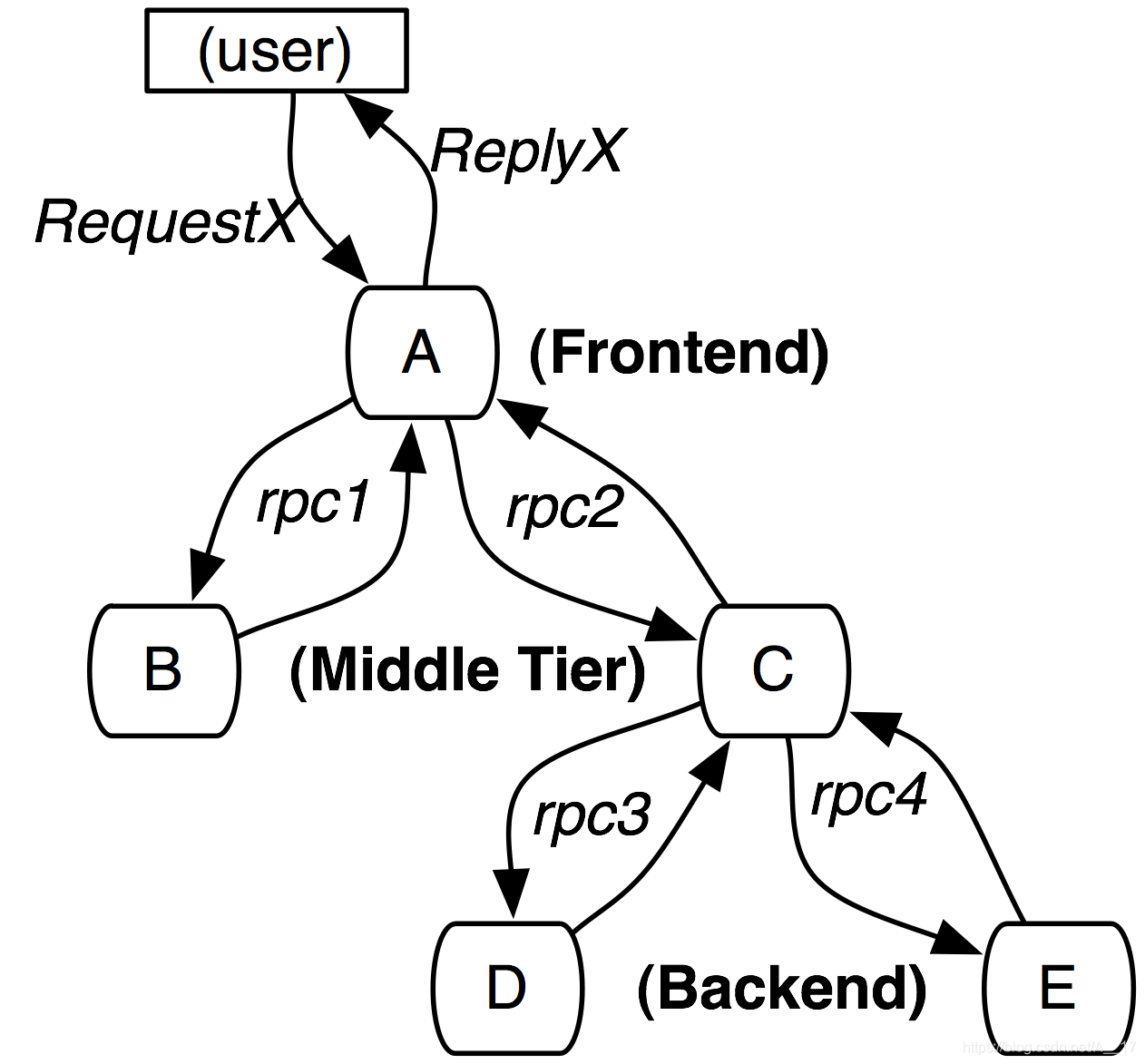
Trace tree
- 追踪树(trace trees):由跨度(span)组成的树形结构,一个追踪树记录着一个链路上所有的调用信息。
-
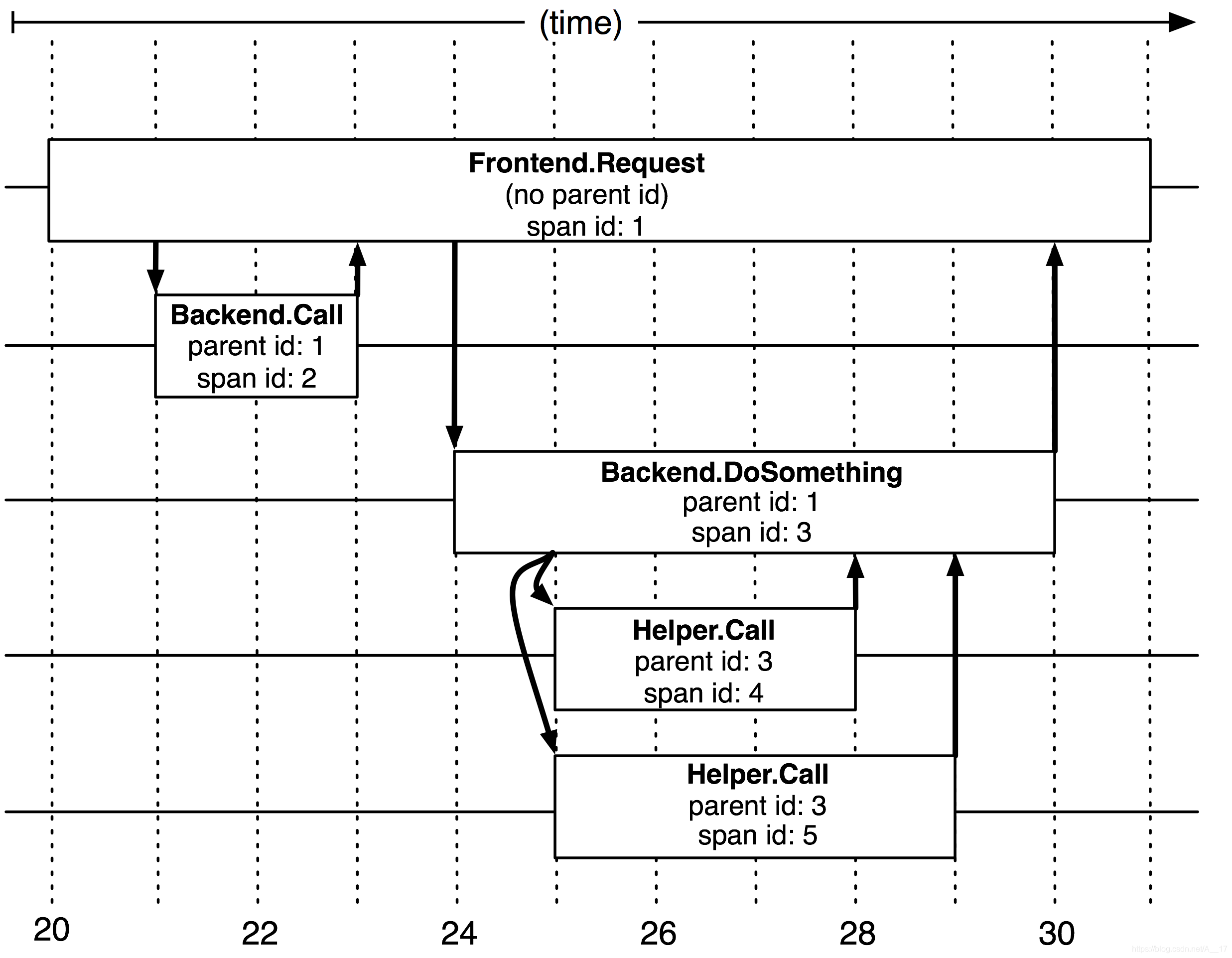
span
- 跨度(span)是追踪树的节点,记录了span的开始和结束时间、RPC耗时数据等。
- 一个追踪树上所有的span都共享一个相同的trace id,同时每个跨度都记录了自身id(span id)和父跨度id(parent id),通过trace id 以及span间的关系来构建某个追踪树。
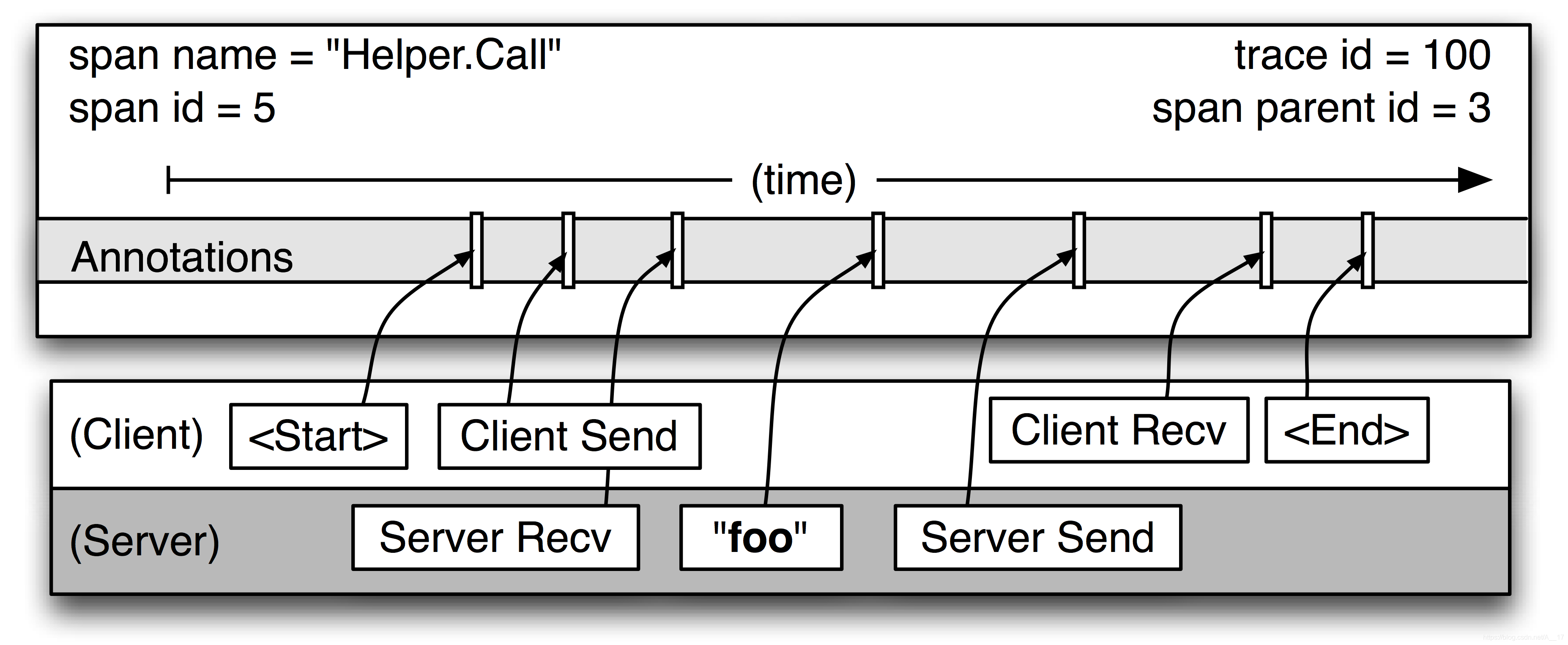
annotations
- 注解:用来支持开发人员追踪自定义的信息。
Trace collection
- 数据的收集,分为三步:
- 将span数据写入到本地日志文件中。
- 通过数据收集器(守护进程)从生产环境的主机中将span数据查询出来。
- 将查询出来的span数据存储到专门记录trace信息的存储系统中。
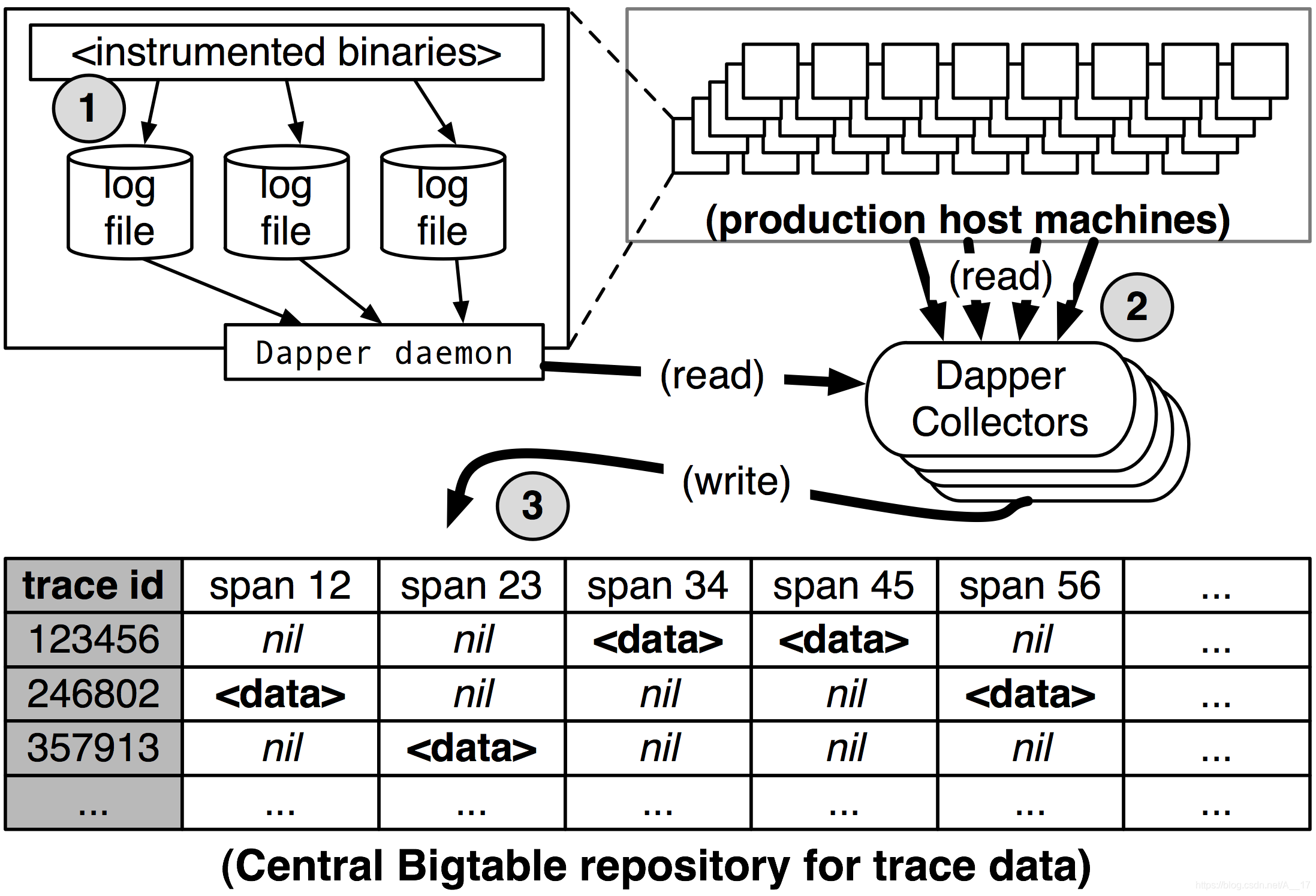
关键点:
追踪上下文(trace id 或 span id)的传递:
-
串行任务模型:使用JDK的ThreadLocal类可以完成同一线程内的值传递。
-
异步任务模型:使用JDK的InheritableThreadLocal类可以完成父线程到子线程的值传递。
-
池化任务模型(分布式追踪链路追踪任务属于这类模型)
-
对于使用线程池等会池化复用线程的执行组件的情况,线程由线程池创建好,并且线程是池化起来反复使用的;
-
应用需要的实际上是把 任务提交给线程池时的ThreadLocal值 传递到 任务执行时。
-
实现池化任务间的值传递:https://github.com/alibaba/transmittable-thread-local
-
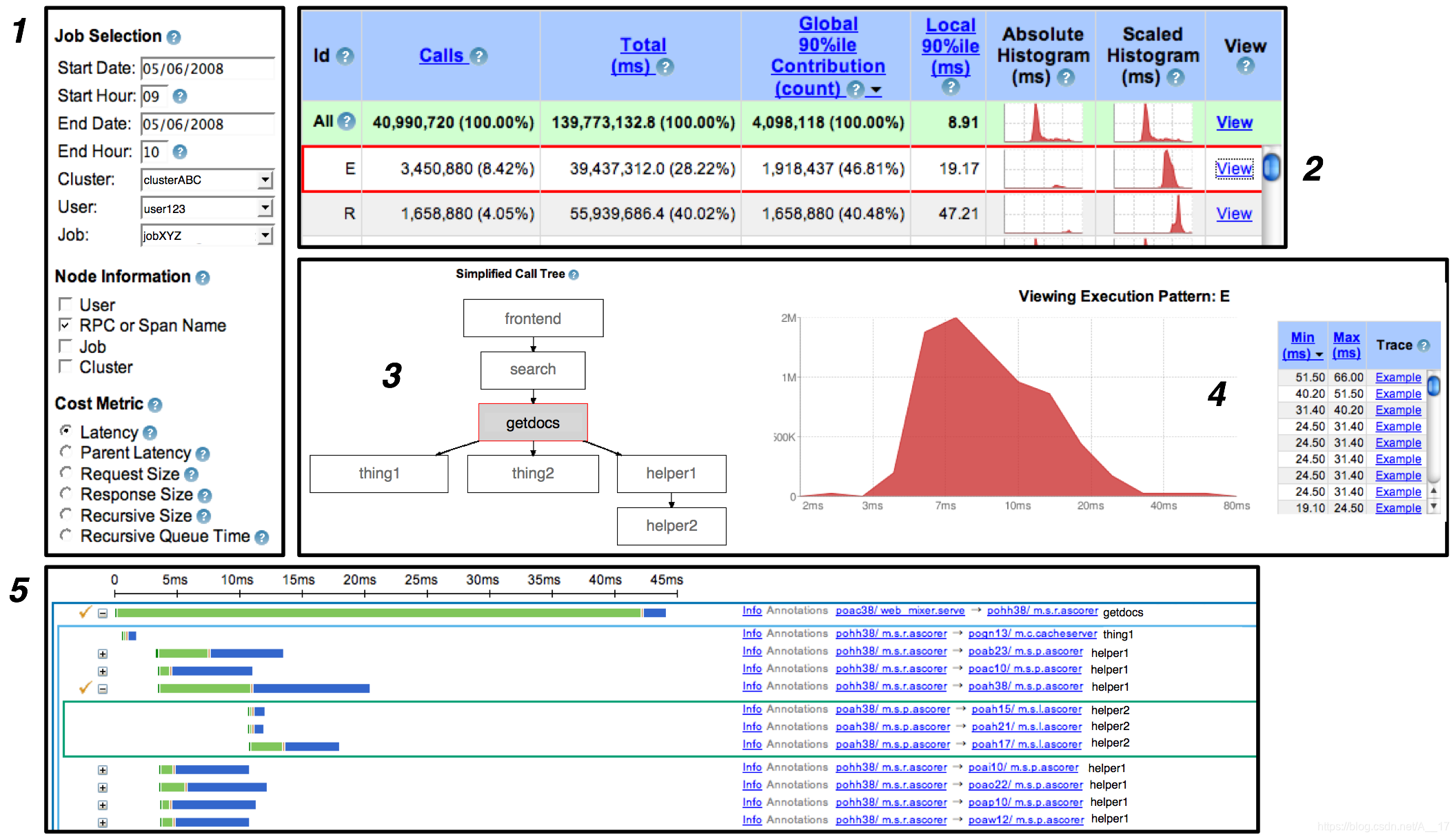
Dapper可视化界面:
Mtrace
- https://tech.meituan.com/2016/10/14/mt-mtrace.html
- 通过在公司内部的各个中间件中进行埋点,实现对每个分布式组件交互时产生的关键信息(机器地址、调用方法、调用耗时、调用结果等)进行采集,对请求耗时瓶颈分析、日志追踪、开发调试 提供了很大的便利。
数据埋点的四个阶段:
-
Client Send : 客户端发起请求时埋点,需要传递一些参数,比如服务的方法名等
Span span = Tracer.clientSend(param); -
Server Recieve : 服务端接收请求时埋点,需要回填一些参数,比如traceId,spanId
Tracer.serverRecv(param); -
ServerSend : 服务端返回请求时埋点,这时会将上下文数据传递到异步上传队列中
Tracer.serverSend(); -
Client Recieve : 客户端接收返回结果时埋点,这时会将上下文数据传递到异步上传队列中
Tracer.clientRecv();
- 说明:在发起 rpc 调用时,rpc中间件会将当前环节的埋点信息同时发送给下游,避免调用链断裂。

















 6万+
6万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









