




目录
选题意义背景
随着全球人口的持续增长和耕地面积的逐渐减少,提高农业生产效率和资源利用率已成为21世纪农业发展的核心挑战。 杂草是农业生产中的主要生物灾害之一,据统计,全球每年因杂草造成的农作物产量损失高达10%-20%,直接影响粮食安全和农业经济效益。藜草作为一种常见的农田杂草,具有生长速度快、繁殖能力强、适应性广等特点,已成为危害农作物生长的重要因素。

传统的杂草防治主要依靠人工识别和化学除草剂的广泛使用,但人工识别效率低下、成本高昂,难以满足大规模农业生产的需求;开发高效、精准的杂草识别与检测技术,对于实现精准施药、减少化学农药使用量、保护生态环境具有重要意义。目标检测作为计算机视觉的核心任务之一,为农作物与杂草的自动识别提供了强有力的技术支持。YOLO系列算法作为目标检测领域的代表性算法,以其高效的实时检测能力和较高的检测精度,在农业领域展现出广阔的应用前景。
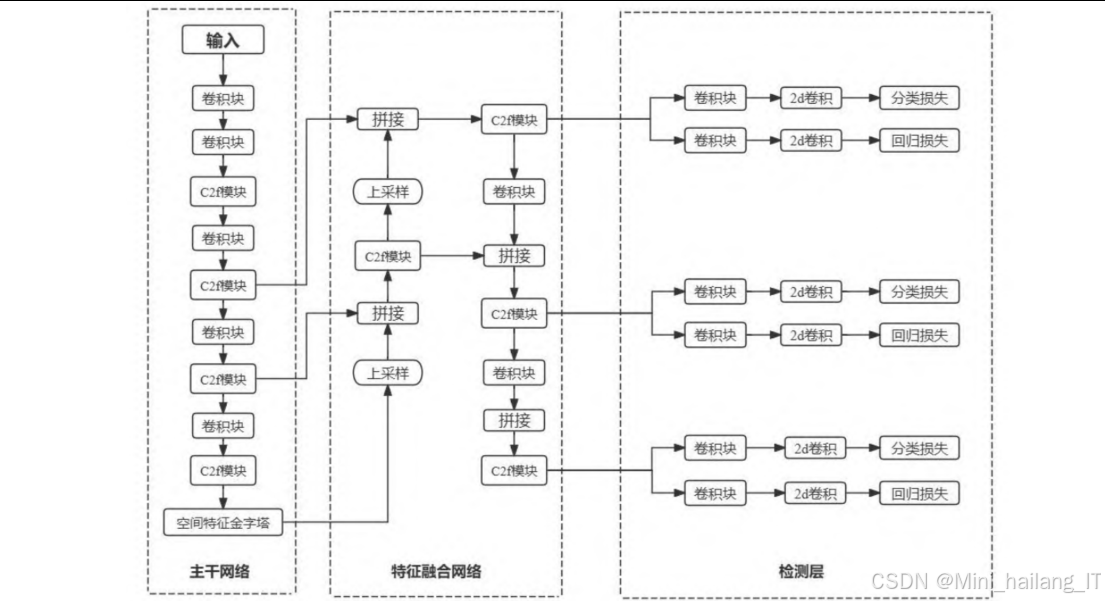
针对上述挑战,本研究提出了一种基于改进YOLOv8的轻量级农作物与藜草检测算法, 通过引入异构卷积、高效局部注意力机制和优化损失函数等创新技术,在保持较高检测精度的同时,显著降低了模型的计算复杂度和参数量,使其更适合在资源受限的农业场景中部署。
数据集
数据集是一个综合性的农作物与藜草图像数据集,由5个公开数据集合并而成。这些数据集均来自于学术研究和公开数据集平台,具有良好的多样性和代表性。获取的原始数据以图像文件形式存储,主要包括JPEG和PNG两种格式。经过初步统计,合并后的数据集共包含6748张图像,涵盖了水稻、棉花、花椒、大豆、玉米等多种农作物以及藜草等多种杂草。数据集中的图像分辨率不一,从320×240到2048×1536像素不等,平均分辨率约为800×600像素。
为了便于模型训练和评估,我们对原始图像进行了统一的标注处理。使用LabelImg工具为每张图像中的目标对象标注了最小外接矩形框,并分配了相应的类别标签。标注文件采用YOLO格式,每个标注文件与对应的图像文件同名但扩展名为.txt。每个标注文件中的每一行代表一个目标对象,包含类别索引和归一化的边界框坐标(中心点x坐标、中心点y坐标、宽度、高度)。
根据研究需求和数据集内容,我们将数据集中的目标对象分为两大类:农作物和杂草。其中,农作物类别包括水稻、棉花、花椒、大豆、玉米等5个亚类别;杂草类别主要以藜草为主,同时也包含了其他常见的田间杂草。具体的类别定义如下:
| 类别索引 | 类别名称 | 类别描述 |
|---|---|---|
| 0 | Rice | 水稻 |
| 1 | Cotton | 棉花 |
| 2 | Prickly_ash | 花椒 |
| 3 | Soybean | 大豆 |
| 4 | Maize | 玉米 |
| 5 | Pigweed | 藜草 |
| 6 | Other_weed | 其他杂草 |
为了确保数据的平衡性,我们对各类别的样本数量进行了统计和分析。经过统计,各类别的样本数量分布如下:水稻约1200个样本,棉花约1050个样本,花椒约950个样本,大豆约1100个样本,玉米约1300个样本,藜草约1800个样本,其他杂草约1200个样本。可以看出,藜草的样本数量相对较多,这主要是因为本研究的重点是藜草检测。
数据分割
为了确保模型训练的有效性和评估的客观性,我们采用了科学的数据分割策略。根据目标检测领域的常规做法,将整个数据集按照7:2:1的比例随机划分,得到训练集、验证集和测试集。 各类别在三个子集中的分布比例与原始数据集基本一致,避免了因类别分布不均导致的模型偏差。此外,我们还采用了分层随机抽样的方法,确保不同作物类型、不同生长阶段、不同环境条件下的图像都能均匀分布在三个子集中。
数据预处理
为了提高模型的鲁棒性和泛化能力,我们对数据集进行了一系列预处理操作,包括图像标准化、数据增强和图像大小调整等。
-
图像大小调整:考虑到模型输入尺寸的一致性要求和计算效率,我们将所有输入图像的分辨率统一调整为640×640像素。在调整过程中,我们保持了图像的宽高比,对不足部分进行了填充。
-
图像标准化:对调整后的图像进行标准化处理,将像素值从0-255范围归一化到0-1范围,以加快模型的收敛速度。
-
数据增强:为了增加数据集的多样性和提高模型的泛化能力,我们采用了多种数据增强技术:
- 随机翻转:水平翻转和垂直翻转,模拟不同角度的观察视角。
- 随机缩放:对图像进行0.8-1.2倍的随机缩放,增强模型对不同尺度目标的识别能力。
- 随机裁剪:随机裁剪图像的部分区域,增强模型对局部特征的敏感度。
- 亮度和对比度调整:随机调整图像的亮度和对比度,模拟不同光照条件下的场景。
- 颜色抖动:随机调整图像的色调、饱和度和明度,增强模型对颜色变化的鲁棒性。
- 高斯噪声添加:向图像中添加适量的高斯噪声,增强模型对噪声的抵抗能力。
-
标注文件同步处理:在对图像进行预处理的同时,我们也对相应的标注文件进行了同步处理。例如,当图像进行翻转、缩放或裁剪操作时,我们相应地调整了标注框的坐标,确保标注信息的准确性。
通过上述预处理操作,我们不仅提高了数据的质量和一致性,还有效地扩充了训练数据的多样性,为后续的模型训练和评估奠定了坚实的基础。
功能模块
主干网络改进
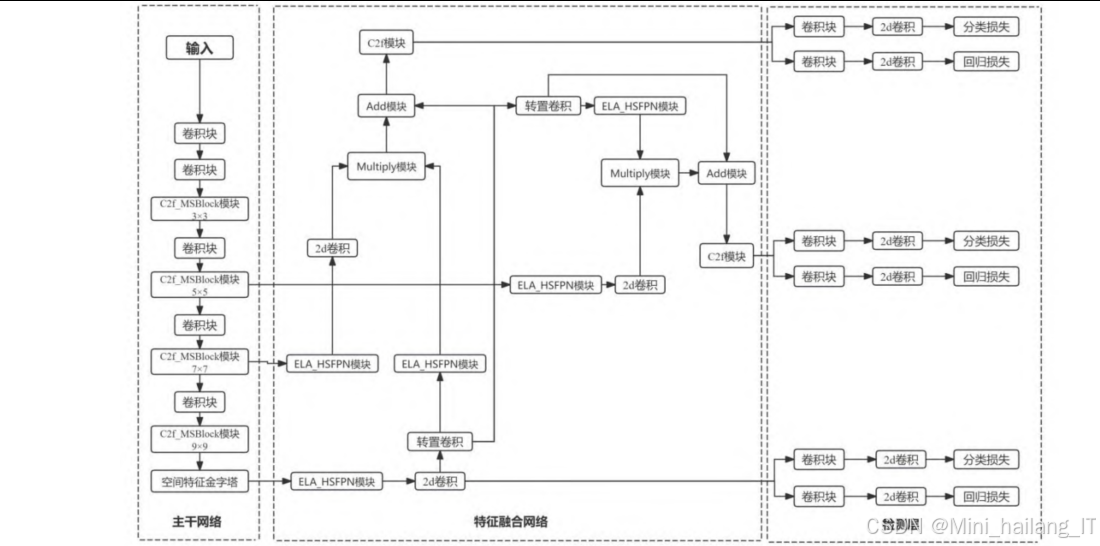
主干网络是目标检测模型的核心组件,负责从输入图像中提取特征信息。在本研究中,我们对YOLOv8的主干网络进行了创新性改进,主要包括MSBlock模块的引入和异构卷积的应用。
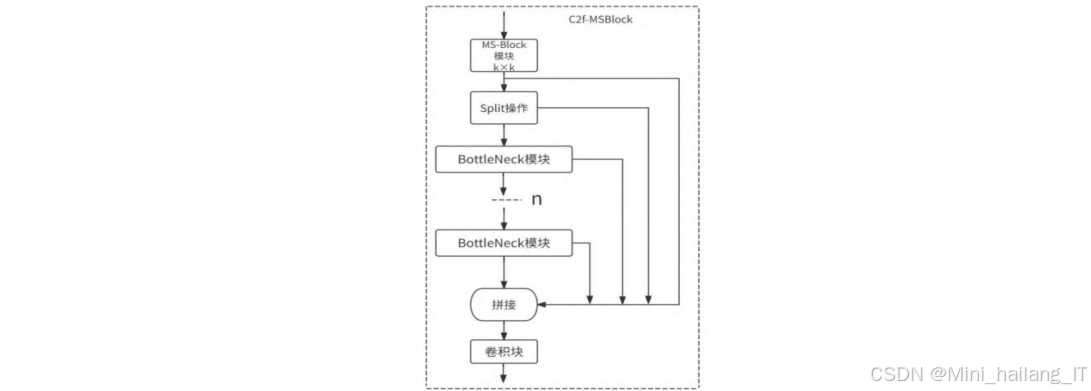
MSBlock模块设计与集成:为了增强模型对多尺度特征的提取能力,我们引入了MSBlock模块,并将其融入到YOLOv8的C2f模块中,形成了新的C2f-MSBlock模块。MSBlock模块采用层次化特征融合策略,将输入特征分割成多个分支,并在每个分支中应用不同大小的卷积核,从而能够同时捕获不同尺度的特征信息。具体来说,MSBlock模块首先通过1×1卷积增加输入特征的通道维度,然后将其分割成n个不同的组。除第一个组外,每个后续组都经过一个逆瓶颈层(Inverted Bottleneck Layer)处理,该逆瓶颈层使用不同大小的卷积核(3×3、5×5、7×7等),以编码不同尺度的特征。最后,所有分支的输出特征被连接起来,并通过1×1卷积进行信息融合,得到最终的输出特征。这种设计使得模型能够在保持计算效率的同时,更全面地捕获目标的多尺度特征。
异构卷积的应用:为了进一步轻量化模型并扩大感受野,我们在C2f-MSBlock模块中应用了异构卷积策略。传统的卷积网络在不同层次通常使用相同大小的卷积核,这限制了模型对不同尺度目标的适应能力。异构卷积则根据特征图的分辨率和网络深度,动态调整卷积核的大小。在本研究中,我们根据编码器不同阶段的特征分辨率,为C2f-MSBlock模块分配了不同大小的卷积核。具体来说,在编码器的浅层阶段(特征图分辨率较高),我们使用较小的卷积核(如3×3),以保留更多的细节信息;而在深层阶段(特征图分辨率较低),我们使用较大的卷积核(如5×5、7×7、9×9),以扩大感受野,捕获更全局的上下文信息。这种异构设计不仅减少了模型的参数量和计算复杂度,还提高了模型对不同尺度目标的检测能力。
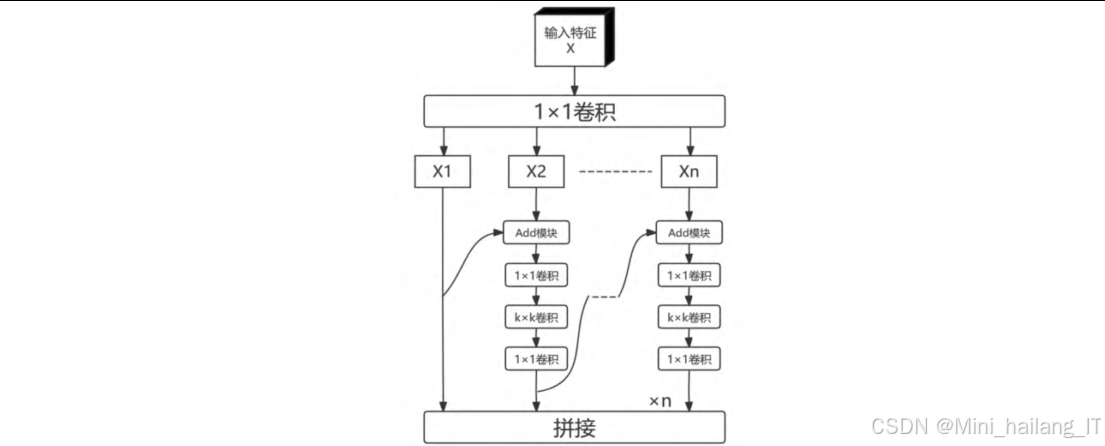
模块实现流程:C2f-MSBlock模块的实现流程主要包括以下几个步骤:首先,输入特征经过1×1卷积进行通道调整;然后,将特征分割成多个分支,每个分支经过不同大小的逆瓶颈层处理;接着,将所有分支的输出连接起来;最后,通过1×1卷积进行特征融合,并与输入特征进行残差连接,得到最终输出。这种设计使得模块在保持轻量化的同时,能够有效地提取和融合多尺度特征信息。
特征融合网络
特征融合网络是目标检测模型的另一个关键组件,负责将不同层次的特征信息进行有效融合,以提高模型对不同尺度目标的检测能力。在本研究中,我们基于HSFPN 结构,引入了高效局部注意力机制( ELA),设计了新的ELA-HSFPN结构。
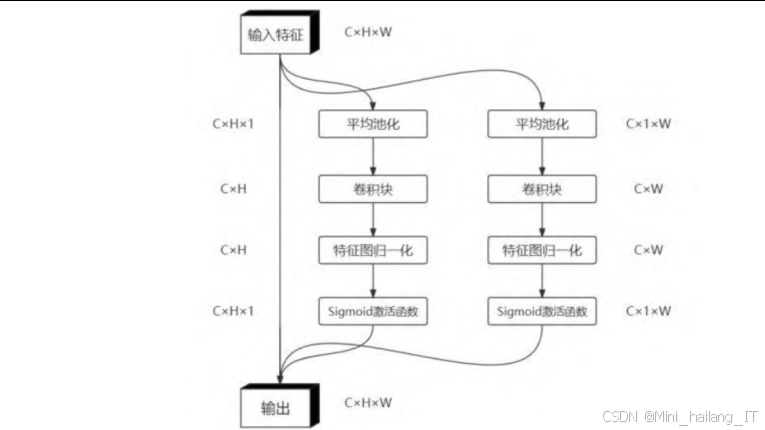
高效局部注意力机制(ELA):为了提高特征融合的效率和精度,我们引入了高效局部注意力机制。传统的注意力机制如坐标注意力(Coordinate Attention,CA)在设计过程中需要多次分离和合并特征图,这不仅增加了计算复杂度,还可能导致通道维度的减少,影响注意力的生成质量。ELA则通过直接编码两个一维位置特征图,无需降维操作即可精确定位感兴趣区域。此外,ELA还引入了空间金字塔池化技术,能够在不同尺度上捕获目标的特征信息。ELA的核心思想是通过轻量级的实现方式,在保持高效率的同时,提高注意力机制的有效性。
ELA-HSFPN结构设计:基于HSFPN的思想,我们设计了ELA-HSFPN结构,将ELA注意力机制融入到特征融合过程中。HSFPN的核心思想是将特征金字塔分为多个子金字塔,每个子金字塔都有自己的特征融合和上采样操作。在ELA-HSFPN中,我们首先在每个子金字塔的特征图上应用ELA注意力机制,生成注意力权重;然后,使用这些权重对低级特征进行筛选和增强;最后,将筛选后的低级特征与高级特征进行融合,形成更具表达能力的特征表示。这种设计使得高级特征能够作为权重,通过注意力机制过滤低级特征中的冗余信息,只保留对目标检测有用的特征,从而提高特征融合的效率和精度。
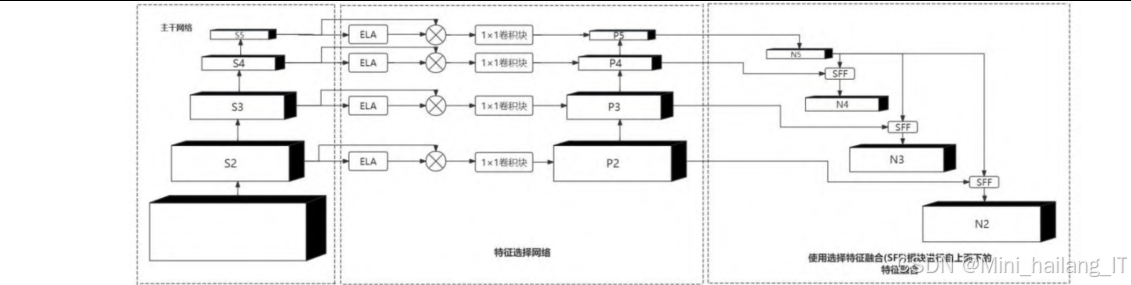
特征融合流程:ELA-HSFPN的特征融合流程主要包括以下几个步骤:首先,从主干网络获取不同尺度的特征图;然后,对每个特征图应用ELA注意力机制,生成注意力权重;接着,使用注意力权重对特征图进行加权处理;最后,通过上采样和跳跃连接,将不同层次的特征进行融合,得到最终的融合特征。这种流程设计使得模型能够在不同尺度上有效地融合低级细节特征和高级语义特征,提高了模型对不同尺度目标的检测能力。
损失函数优化
损失函数是深度学习模型训练的重要组成部分,直接影响模型的训练效果和最终性能。在目标检测任务中,边框回归损失函数的设计尤为关键。在本研究中,我们采用了Inner-SIoU损失函数,以提高边框回归的精度和效率。
Inner-SIoU损失函数原理:Inner-SIoU损失函数是对传统IoU损失函数的改进,通过引入辅助边框来计算IoU损失。传统的IoU损失函数在计算预测框和真实框的重叠度时,没有考虑边界框的内部结构和尺度变化,这可能导致在训练过程中收敛速度慢或精度不足。Inner-SIoU则通过引入尺度因子ratio来控制辅助边框的大小,使得损失函数能够根据不同的数据集和检测任务进行自我调整。具体来说,Inner-SIoU首先根据真实框和预测框的中心点和宽高,计算出对应的辅助边框;然后,计算辅助边框之间的IoU;最后,将Inner-IoU与原始IoU结合,形成最终的损失函数。
损失函数参数调优:为了使Inner-SIoU损失函数更好地适应农作物与藜草检测任务,我们对其关键参数进行了调优。其中,最关键的参数是尺度因子ratio,其取值范围通常为[0.5, 1.5]。当ratio小于1时,辅助边框小于原始边框,能够加速高IoU样本的收敛;当ratio大于1时,辅助边框大于原始边框,对低IoU样本的回归有所增益。通过实验,我们发现当ratio设置为1.2时,模型在本数据集上取得了最佳的性能表现。这表明,对于农作物与藜草检测任务,适当扩大辅助边框的大小,能够更好地处理低IoU样本,提高整体检测精度。
损失函数集成:在实际应用中,我们将Inner-SIoU损失函数与分类损失函数和置信度损失函数结合,形成了完整的多任务损失函数。具体来说,总损失函数由三部分组成:分类损失、置信度损失和边框回归损失。通过调整各部分损失的权重,我们使得模型能够在分类精度和定位精度之间取得良好的平衡。
模型训练与部署
模型训练与部署模块负责模型的参数优化、性能评估和实际应用部署。在本研究中,我们设计了完整的训练流程和部署方案,以确保模型能够在实际应用中发挥最佳效果。
训练过程监控:在训练过程中,我们使用验证集对模型性能进行实时监控,记录了关键指标如mAP、损失值等的变化情况。通过分析这些指标的变化趋势,我们可以及时发现训练过程中存在的问题,并对训练策略进行调整。例如,当验证集上的mAP不再提升时,我们可以提前终止训练,避免过拟合。
模型部署优化:为了使模型能够在资源受限的设备上高效运行,我们对模型进行了部署优化。通过模型剪枝和量化技术,进一步减少了模型的参数量和计算复杂度。我们使用ONNX格式转换模型,使其能够在不同的推理框架中高效运行,针对特定的硬件平台进行了推理优化,提高了模型的推理速度。
算法理论
YOLOv8算法基础
YOLOv8是YOLO系列目标检测算法的最新版本,继承了YOLOv5的成功经验,并在网络架构、训练流程和特征提取能力等方面进行了多项改进。YOLOv8采用了端到端的检测框架,能够同时完成目标的定位和分类任务,具有较高的检测精度和实时性能。
网络架构:YOLOv8的网络架构主要包括三个部分:主干网络(Backbone)、特征融合网络(Neck)和检测头(Head)。主干网络采用了CSPNet(Cross Stage Partial Network)与YOLOv7的ELAN结构相结合的设计,形成了新的C2f模块,能够更有效地提取特征信息。特征融合网络采用了PAN-FPN(Path Aggregation Network - Feature Pyramid Network)结构,通过构建多尺度特征金字塔并促进跨层信息的流通,使网络能够更精准地捕捉不同尺度目标的特征。检测头采用了解耦头设计,通过两条并行路径分别提取目标的类别和位置特征,提高了检测的效率和精度。
工作原理:YOLOv8的工作原理可以概括为以下几个步骤:首先,输入图像经过主干网络的处理,提取出不同层次的特征图;然后,这些特征图通过特征融合网络进行多尺度融合,形成更具表达能力的特征表示;接着,检测头对融合后的特征进行处理,生成目标的类别概率和位置信息;最后,通过非极大值抑制(NMS)算法,过滤掉冗余的预测框,得到最终的检测结果。
MSBlock与异构卷积理论
MSBlock 是一种高效的多尺度特征提取模块,通过并行处理不同尺度的特征信息,提高了模型对多尺度目标的检测能力。异构卷积则是一种根据网络深度动态调整卷积核大小的策略,能够在保持计算效率的同时,扩大模型的感受野。
MSBlock工作原理:MSBlock的核心思想是通过多个分支并行处理不同尺度的特征信息。具体来说,MSBlock首先通过1×1卷积增加输入特征的通道维度,然后将其分割成n个不同的组。除第一个组外,每个后续组都经过一个逆瓶颈层处理,该逆瓶颈层使用不同大小的卷积核,以编码不同尺度的特征。最后,所有分支的输出特征被连接起来,并通过1×1卷积进行信息融合,得到最终的输出特征。这种设计使得MSBlock能够在保持计算效率的同时,更全面地捕获目标的多尺度特征。
异构卷积的理论基础:异构卷积的理论基础在于,不同深度的网络层对特征的感受范围和抽象程度有不同的需求。在网络的浅层,特征图分辨率较高,需要较小的卷积核来保留细节信息;而在网络的深层,特征图分辨率较低,需要较大的卷积核来扩大感受野,捕获更全局的上下文信息。异构卷积通过根据网络深度动态调整卷积核的大小,使网络在不同层次都能高效地提取特征信息。
通过这种设计,MSBlock能够有效地融合不同尺度和层次的特征信息,提高模型的检测能力。
高效局部注意力机制(ELA)理论
高效局部注意力机制(Efficient Local Attention,ELA)是一种轻量级的注意力机制,通过有效地编码位置信息和空间上下文,提高了模型对目标区域的关注能力。
注意力机制基本原理:注意力机制的基本思想是模拟人类视觉系统的选择性注意能力,通过对输入特征分配不同的权重,使模型能够关注对任务更重要的区域。在计算机视觉任务中,注意力机制通常分为通道注意力和空间注意力两种类型。通道注意力关注不同通道的重要性,而空间注意力则关注图像中不同区域的重要性。
ELA的设计思想:ELA的设计思想是通过轻量级的实现方式,在保持高效率的同时,提高注意力机制的有效性。与传统的坐标注意力(CA)不同,ELA不需要多次分离和合并特征图,也不需要进行降维操作,而是直接编码两个一维位置特征图,从而精确定位感兴趣区域。此外,ELA还引入了空间金字塔池化技术,能够在不同尺度上捕获目标的特征信息。
ELA的工作流程:ELA的工作流程主要包括以下几个步骤:首先,输入特征通过空间金字塔池化,捕获不同尺度的特征信息;然后,通过全局平均池化和全局最大池化,分别提取通道方向和空间方向的特征;接着,通过轻量级的卷积操作,生成注意力权重;最后,将注意力权重与输入特征相乘,得到增强后的特征表示。这种设计使得ELA能够在保持轻量化的同时,有效地提高模型的注意力能力。
Inner-SIoU损失函数理论
Inner-SIoU损失函数是对传统IoU损失函数的改进,通过引入辅助边框来计算IoU损失,提高了边框回归的精度和效率。
IoU损失函数的局限性:传统的IoU损失函数在计算预测框和真实框的重叠度时,存在一些局限性。首先,当预测框和真实框不相交时,IoU值为0,无法提供梯度信息,导致训练过程中收敛困难。其次,当预测框和真实框具有相同的IoU值但位置关系不同时,IoU损失无法区分这些情况,可能导致次优解。此外,IoU损失函数没有考虑边界框的内部结构和尺度变化,这可能导致在训练过程中收敛速度慢或精度不足。
Inner-SIoU的改进思想:Inner-SIoU通过引入辅助边框来解决传统IoU损失函数的局限性。具体来说,Inner-SIoU首先根据真实框和预测框的中心点和宽高,计算出对应的辅助边框;然后,计算辅助边框之间的IoU(称为Inner-IoU);最后,将Inner-IoU与原始IoU结合,形成最终的损失函数。通过这种设计,Inner-SIoU能够更精确地评估预测框和真实框之间的重叠程度,从而提高边框回归的精度和效率。
核心代码
C2f-MSBlock模块实现
MSBlock模块首先通过1×1卷积将输入特征的通道数增加到2倍,然后将其分为两部分。其中一部分作为残差连接,另一部分通过一系列逆瓶颈层(InvertedBottleneck)处理,每个逆瓶颈层使用不同大小的卷积核(3×3、5×5、7×7等),以捕获不同尺度的特征信息。最后,将所有部分的输出连接起来,并通过1×1卷积进行特征融合。C2f-MSBlock模块则在此基础上进一步优化,将多个MSBlock模块级联,形成更深的特征提取网络。这种设计使得模块能够在保持轻量化的同时,更有效地提取和融合多尺度特征信息,提高模型的检测能力。C2f-MSBlock模块是本研究的核心创新之一,它通过将MSBlock融入C2f模块,并应用异构卷积策略,显著提高了模型的特征提取能力和计算效率。
class MSBlock(nn.Module):
def __init__(self, c1, c2, n=2, shortcut=True, g=1, e=0.5):
super().__init__()
self.c = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, 2 * self.c, 1, 1)
self.cv2 = Conv((2 + n) * self.c, c2, 1)
self.m = nn.ModuleList(
InvertedBottleneck(self.c, self.c, k=3 + 2 * i) for i in range(n)
)
self.shortcut = shortcut
def forward(self, x):
y = list(self.cv1(x).chunk(2, 1))
y.extend(m(y[-1]) for m in self.m)
return self.cv2(torch.cat(y, 1))
class C2f_MSBlock(nn.Module):
def __init__(self, c1, c2, n=2, shortcut=True, g=1, e=0.5):
super().__init__()
self.c = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, 2 * self.c, 1, 1)
self.cv2 = Conv((2 + n) * self.c, c2, 1)
self.ms_blocks = nn.ModuleList(
MSBlock(self.c, self.c, n=2, shortcut=shortcut, g=g, e=1.0) for _ in range(n)
)
self.shortcut = shortcut
def forward(self, x):
y = list(self.cv1(x).chunk(2, 1))
for ms_block in self.ms_blocks:
y.append(ms_block(y[-1]))
return self.cv2(torch.cat(y, 1))
ELA-HSFPN特征融合网络实现
ELA注意力机制和ELA-HSFPN特征融合网络:ELA模块首先通过水平和垂直两个方向的自适应平均池化,提取特征的位置信息;然后,通过轻量级的卷积操作,生成注意力权重;最后,将注意力权重与输入特征相乘,得到增强后的特征表示。ELA-HSFPN网络则在此基础上,通过上采样和跳跃连接,将不同层次的特征进行融合。具体来说,深层特征首先经过处理,然后通过上采样与中层特征融合;融合后的特征再通过上采样与浅层特征融合。在每一层特征处理过程中,都应用了ELA注意力机制,以提高特征的表达能力。这种设计使得网络能够在不同尺度上有效地融合低级细节特征和高级语义特征,提高了模型对不同尺度目标的检测能力。ELA-HSFPN特征融合网络是本研究的另一个核心创新,它通过将高效局部注意力机制(ELA)融入HSFPN结构,显著提高了特征融合的效率和精度。
class ELA(nn.Module):
def __init__(self, c1, c2, reduction=32):
super().__init__()
self.pool_h = nn.AdaptiveAvgPool2d((None, 1))
self.pool_w = nn.AdaptiveAvgPool2d((1, None))
self.cv1 = Conv(c1, c2 // reduction, 1, 1)
self.cv2 = Conv(c2 // reduction, c2, 1, 1, act=False)
self.act = nn.SiLU()
def forward(self, x):
n, c, h, w = x.shape
x_h = self.pool_h(x)
x_w = self.pool_w(x).permute(0, 1, 3, 2)
y = torch.cat([x_h, x_w], dim=2)
y = self.cv1(y)
y = self.act(y)
x_h, x_w = torch.split(y, [h, w], dim=2)
x_w = x_w.permute(0, 1, 3, 2)
y = self.cv2(x_h.sigmoid() * x_w.sigmoid())
return x * y
class ELA_HSFPN(nn.Module):
def __init__(self, ch=[256, 512, 1024], out_ch=256):
super().__init__()
self.upsample = nn.Upsample(scale_factor=2, mode='nearest')
self.cv1 = Conv(ch[2], out_ch, 1, 1)
self.cv2 = Conv(ch[1], out_ch, 1, 1)
self.cv3 = Conv(ch[0], out_ch, 1, 1)
self.ela1 = ELA(out_ch, out_ch)
self.ela2 = ELA(out_ch, out_ch)
self.ela3 = ELA(out_ch, out_ch)
def forward(self, x):
x3, x2, x1 = x # 深层、中层、浅层特征
# 处理深层特征
p3 = self.cv1(x3)
p3 = self.ela1(p3)
# 处理中层特征
p2 = self.cv2(x2)
p2 = p2 + self.upsample(p3)
p2 = self.ela2(p2)
# 处理浅层特征
p1 = self.cv3(x1)
p1 = p1 + self.upsample(p2)
p1 = self.ela3(p1)
return p1, p2, p3
Inner-SIoU损失函数实现
Inner-SIoU损失函数:函数接收预测框和真实框的坐标,以及辅助边框的尺度因子ratio。然后,根据这些信息,计算出预测框和真实框的中心点坐标和宽高。接着,根据中心点和宽高,以及尺度因子ratio,计算出对应的辅助边框坐标。然后,计算辅助边框之间的交集和并集,从而得到Inner-IoU值。最后,结合SIoU损失函数的其他组成部分(重叠度、方向、距离等),计算出最终的Inner-SIoU损失值。通过这种设计,Inner-SIoU损失函数能够更精确地评估预测框和真实框之间的重叠程度,特别是对于边界框的核心部分,从而提高边框回归的精度和效率。Inner-SIoU损失函数是本研究的第三个核心创新,它通过引入辅助边框来计算IoU损失,提高了边框回归的精度和效率。
def inner_iou_loss(pred, target, ratio=1.2, eps=1e-7):
# pred: [batch, 4] - 预测框坐标 (x1, y1, x2, y2)
# target: [batch, 4] - 真实框坐标 (x1, y1, x2, y2)
# ratio: 辅助边框的尺度因子
# 计算中心点和宽高
pred_center_x = (pred[:, 0] + pred[:, 2]) / 2
pred_center_y = (pred[:, 1] + pred[:, 3]) / 2
pred_w = pred[:, 2] - pred[:, 0]
pred_h = pred[:, 3] - pred[:, 1]
target_center_x = (target[:, 0] + target[:, 2]) / 2
target_center_y = (target[:, 1] + target[:, 3]) / 2
target_w = target[:, 2] - target[:, 0]
target_h = target[:, 3] - target[:, 1]
# 计算辅助边框
# 真实框的辅助边框
target_bl = target_center_x - target_w * ratio / 2
target_br = target_center_x + target_w * ratio / 2
target_bt = target_center_y - target_h * ratio / 2
target_bb = target_center_y + target_h * ratio / 2
# 预测框的辅助边框
pred_bl = pred_center_x - pred_w * ratio / 2
pred_br = pred_center_x + pred_w * ratio / 2
pred_bt = pred_center_y - pred_h * ratio / 2
pred_bb = pred_center_y + pred_h * ratio / 2
# 计算辅助边框的交集
inter_left = torch.maximum(pred_bl, target_bl)
inter_right = torch.minimum(pred_br, target_br)
inter_top = torch.maximum(pred_bt, target_bt)
inter_bottom = torch.minimum(pred_bb, target_bb)
inter_width = torch.maximum(inter_right - inter_left, torch.zeros_like(inter_right))
inter_height = torch.maximum(inter_bottom - inter_top, torch.zeros_like(inter_bottom))
inter_area = inter_width * inter_height
# 计算辅助边框的并集
target_area = (target_br - target_bl) * (target_bb - target_bt)
pred_area = (pred_br - pred_bl) * (pred_bb - pred_bt)
union_area = target_area + pred_area - inter_area + eps
# 计算Inner-IoU
inner_iou = inter_area / union_area
# 计算SIoU损失
# 计算重叠度
overlap = torch.minimum(pred_w, target_w) / torch.maximum(pred_w, target_w)
# 计算方向
angle_cost = torch.abs(pred_center_x - target_center_x) / (torch.maximum(pred_w, target_w) + eps)
angle_cost += torch.abs(pred_center_y - target_center_y) / (torch.maximum(pred_h, target_h) + eps)
angle_cost /= 2
# 计算距离
dist_cost = (torch.abs(pred_center_x - target_center_x) ** 2 +
torch.abs(pred_center_y - target_center_y) ** 2) / (torch.maximum(pred_w, target_w) * torch.maximum(pred_h, target_h) + eps)
# SIoU损失
siou_loss = 1 - inner_iou + (0.5 - overlap / 2) + angle_cost + dist_cost
return siou_loss.mean()
重难点和创新点
研究重点
本研究的重点在于设计一种高效、精准的农作物与藜草检测算法,以满足精准农业的实际需求。具体来说,研究重点主要包括以下几个方面:
多尺度特征提取与融合:农作物与杂草在自然环境中具有较大的尺度变化,从几厘米的幼苗到几十厘米的成株,都需要算法能够准确识别。因此,如何有效地提取和融合不同尺度的特征信息,是提高检测精度的关键。本研究通过引入MSBlock模块和ELA-HSFPN结构,实现了高效的多尺度特征提取与融合,显著提高了模型对不同尺度目标的检测能力。
模型轻量化设计:考虑到农业应用场景(如无人机、机器人等)的计算资源限制,模型的轻量化设计是研究的另一个重点。本研究通过异构卷积、模块重构等技术,在保持较高检测精度的同时,显著降低了模型的参数量和计算复杂度,使其更适合在资源受限的设备上部署。
复杂环境适应性:农田环境复杂多变,光照条件、土壤背景、作物生长阶段等因素都会影响检测效果。因此,如何提高模型对复杂环境的适应能力,是研究的又一个重点。本研究通过数据增强、注意力机制等技术,提高了模型的鲁棒性和泛化能力,使其能够在各种复杂环境下保持稳定的检测性能。
创新点
本研究的主要创新点包括以下几个方面:
C2f-MSBlock模块的设计与应用:本研究创新性地将MSBlock模块融入C2f模块,形成了新的C2f-MSBlock模块。该模块通过层次化特征融合策略,能够同时捕获不同尺度的特征信息,提高了模型的特征提取能力。此外,通过在不同阶段应用异构卷积,进一步提高了模型的效率和精度。
ELA-HSFPN特征融合网络的设计:本研究基于HSFPN结构,引入了高效局部注意力机制(ELA),设计了新的ELA-HSFPN特征融合网络。该网络通过注意力机制对特征进行选择和增强,使得模型能够更加关注对目标检测至关重要的区域,提高了特征融合的效率和精度。
Inner-SIoU损失函数的应用:本研究将Inner-SIoU损失函数应用于边框回归任务,通过引入辅助边框来计算IoU损失,提高了边框回归的精度和效率。
总结
本研究针对农作物与藜草检测任务的需求和挑战,提出了一种基于改进YOLOv8的轻量级检测算法:通过对主干网络、特征融合网络和损失函数三个方面的创新改进,该算法在保持较高检测精度的同时,显著降低了模型的计算复杂度和参数量,使其更适合在资源受限的农业场景中部署:
-
主干网络将MSBlock模块融入C2f模块,形成了新的C2f-MSBlock模块,并应用了异构卷积策略。这种设计使得模型能够更有效地提取和融合多尺度特征信息,提高了特征提取的效率和精度。
-
特征融合网络方面基于HSFPN结构,引入了高效局部注意力机制(ELA),设计了新的ELA-HSFPN特征融合网络。该网络通过注意力机制对特征进行选择和增强,使得模型能够更加关注对目标检测至关重要的区域,提高了特征融合的效率和精度。
-
损失函数采用了Inner-SIoU损失函数,通过引入辅助边框来计算IoU损失,提高了边框回归的精度和效率。
本研究的成果为农作物与杂草的精准识别提供了新的技术方案,也为推动精准农业的发展和农业可持续发展战略的实施提供了有力支撑。未来的研究方向包括:进一步优化模型结构,提高检测速度;拓展算法的应用范围,使其能够识别更多种类的农作物和杂草;将算法与农业机械设备集成,实现智能化的农田管理和杂草防治。
参考文献
[1] Chen Y M, Yuan X B, Wu R Q, et al. YOLO-MS: Rethinking Multi-Scale Representation Learning for Real-time Object Detection[J]. arXiv preprint arXiv:2308.05480, 2023.
[2] Wang C Y, Liao H Y, Wu Y H, et al. CSPNet: A new backbone that can enhance learning capability of CNN[C]//Proceedings of the IEEE/CVF conference on computer vision and pattern recognition workshops, 2020: 390-391.
[3] Liu S, Qi L, Qin H, et al. Path aggregation network for instance segmentation[C]//Proceedings of the IEEE conference on computer vision and pattern recognition, 2018: 8759-8768.
[4] Lin T Y, Dollár P, Girshick R, et al. Feature pyramid networks for object detection[C]//Proceedings of the IEEE conference on computer vision and pattern recognition, 2017: 2117-2125.
[5] Hou Q, Zhou D, Feng J. Coordinate Attention for Efficient Mobile Network Design[C]//Proceedings of the IEEE conference on computer vision and pattern recognition, 2021: 13713-13722.
[6] Xu W, Wan Y. ELA: Efficient Local Attention for Deep Convolutional Neural Networks[J]. arXiv preprint arXiv:2403.01123, 2024.
[7] Zhang H, Xu C, Zhang S J. Inner-ioU: More Effective Intersection over Union Loss with Auxiliary Bounding Box[J]. arXiv preprint arXiv:2311.02877, 2023.
[8] Gevorgyan Z. SIoU loss: more powerful learning for bounding box regression[EB/OL]. [2024-05-23]. https://arxiv.org/abs/2205.12740.


















 11万+
11万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









