




前言
📅大四是整个大学期间最忙碌的时光,一边要忙着备考或实习为毕业后面临的就业升学做准备,一边要为毕业设计耗费大量精力。近几年各个学校要求的毕设项目越来越难,有不少课题是研究生级别难度的,对本科同学来说是充满挑战。为帮助大家顺利通过和节省时间与精力投入到更重要的就业和考试中去,学长分享优质的选题经验和毕设项目与技术思路。
🚀对毕设有任何疑问都可以问学长哦!
大家好,这里是海浪学长计算机毕设专题,本次分享的课题是
🎯基于python的校园舆情信息检测系统
项目背景
随着社交媒体的普及和信息传播的快速发展,校园舆情管理变得越来越重要。校园舆情信息的准确监测和及时处理对于维护校园秩序、提高学校形象具有重要意义。基于Python的校园舆情信息检测系统能够利用文本挖掘、自然语言处理等技术,对校园舆情信息进行自动化分析和识别,帮助学校及时发现和解决潜在的问题。
算法理论基础
2.1 文本分类算法
SVM是一种强大的分类算法,能够有效地处理高维数据和大规模数据集。在校园舆情信息检测系统中,SVM可以对文本进行分类,帮助系统准确判断舆情信息的倾向性,如正面、负面或中性。SVM通过最大化分类边界与样本点的间隔,具有较好的鲁棒性和泛化能力。这意味着即使面对噪声和数据不完全分离的情况,SVM仍然能够进行准确分类,并且对于新的未见数据也能有较好的预测能力。
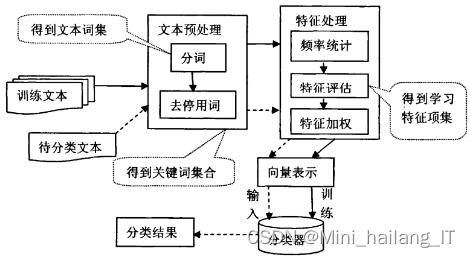
SVM的组成结构包括:
-
输入数据:校园舆情信息检测系统中的输入数据为文本数据,通常表示为向量或矩阵形式,其中每个特征对应一个维度。
-
特征提取:在SVM中,需要对输入文本进行特征提取,将其转化为可用于分类的特征向量。常见的特征提取方法包括词袋模型、TF-IDF等。
-
训练过程:SVM的训练过程是通过优化算法,根据训练数据找到最优的超平面,使得分类边界具有最大的间隔,并最小化训练误差。
-
分类预测:在训练完成后,SVM可以用于对新的未见数据进行分类预测,根据其特征向量与决策边界的位置关系来判断其所属类别。
2.2 情感分析算法
尽管CNN最初是用于图像处理的,但它也可以应用于文本分类任务。CNN通过卷积层和池化层的组合,能够有效地捕捉文本中的局部特征和语义信息,从而提高校园舆情信息的分类准确性。CNN可以自动学习并提取文本的特征表示。通过多个卷积层和激活函数,CNN能够对文本数据进行多层次的特征抽取,从低级特征(如字符级别)到高级特征(如词组和句子级别),进而更好地捕捉文本的语义和上下文信息。
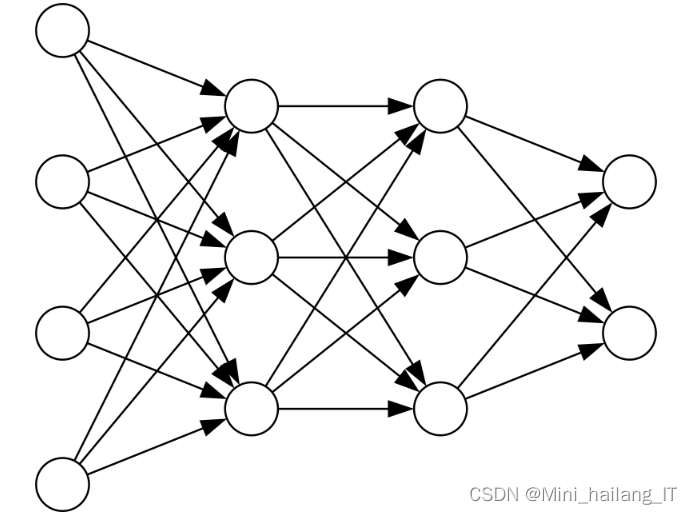
CNN的原理基于神经网络和卷积运算的思想,主要用于图像和序列数据的处理。在校园舆情信息检测系统中,CNN的组成结构包括:
- 卷积层:卷积层是CNN的核心部分,通过卷积操作对输入数据进行特征提取。在文本处理中,卷积操作可以捕捉不同长度的短语和语义特征,并生成特征图。
- 激活函数:激活函数引入非线性变换,增加网络的表达能力。在CNN中常用的激活函数包括ReLU、Sigmoid和Tanh,用于引入非线性特征。
- 池化层:池化层用于减小特征图的尺寸和参数数量,对提取的特征进行下采样。常见的池化操作包括最大池化和平均池化,有助于减少计算量和过拟合。
- 全连接层:全连接层用于将池化层输出的特征进行展平,并与输出层进行连接。在校园舆情信息检测系统中,全连接层可以将提取的文本特征映射到具体的类别或情感倾向。
- 输出层:输出层根据具体的任务和分类需求,选择适当的激活函数和损失函数,进行分类或回归预测。
2.3 主题建模算法
LDA主题建模是一种基于文本数据的分析方法,通过推断文档-主题分布和主题-词分布来发现文本中的隐藏主题结构。它将文本看作是由多个主题的混合组成,每个主题具有一定的词分布。LDA的推断过程通过迭代更新主题分配,逐步优化模型参数。该方法可以应用于文本分类、信息检索和推荐系统等领域,帮助理解文本含义和发现潜在的主题关联。
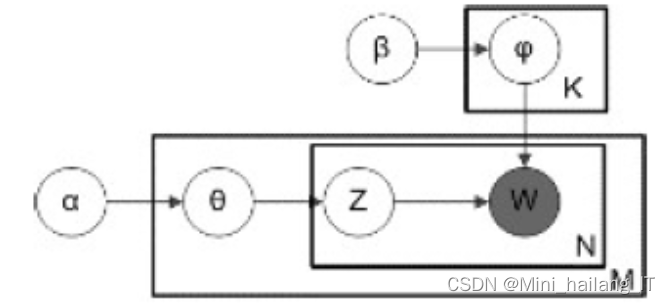
数据集
由于网络上缺乏现有的合适数据集,我决定自己收集数据并制作一个全新的数据集来支持基于Python的校园舆情信息检测系统的研究。我首先收集了来自学校内部社交媒体平台和校园论坛的大量帖子和评论,涵盖了各种校园事件和话题。然后,我使用Python编写了一个网络爬虫程序,自动抓取相关数据并进行清洗和整理。在数据清洗过程中,我去除了无关的广告信息和噪声数据,保留了与校园舆情相关的文本内容。通过这个自制的数据集,我能够提供更具代表性的训练样本,以及用于评估和测试的数据集。
模型实验
基于 Python 的校园舆情信息检测系统的设计思路包括以下内容:
-
数据采集:设计一个数据采集模块,通过爬虫技术从各种校园舆情信息源(如社交媒体、论坛、新闻网站等)获取相关数据。可以使用 Python 的库(如Requests、BeautifulSoup、Selenium等)来实现数据的抓取和解析。
-
文本预处理:对采集到的文本数据进行预处理,包括去除HTML标签、分词、去除停用词、词性标注等。可以使用 Python 的自然语言处理库(如NLTK、spaCy等)来完成文本预处理的任务。
-
情感分析:使用情感分析技术来判断舆情信息的情感倾向,即判断是正面、负面还是中性的情感。可以使用已有的情感词典或机器学习方法,如朴素贝叶斯、支持向量机等,来实现情感分析功能。Python 的库(如TextBlob、scikit-learn等)提供了相关的功能和算法。
-
关键词提取:使用关键词提取技术来识别舆情信息中的关键词和主题。可以使用基于统计的方法(如TF-IDF、TextRank等)或基于机器学习的方法(如主题模型、词嵌入等)来提取关键词。Python 的库(如Gensim、scikit-learn等)提供了相关的算法和工具。
-
实体识别:使用实体识别技术来识别舆情信息中的具体实体,如人名、地名、组织机构等。可以使用基于规则的方法或基于机器学习的方法(如命名实体识别算法)来实现实体识别功能。Python 的库(如spaCy、NLTK等)提供了相应的算法和工具。
-
可视化和报告:设计一个用户界面,展示舆情信息的分析结果和报告。可以使用 Python 的可视化库(如Matplotlib、Plotly等)来创建图表和可视化效果,使用户能够直观地了解校园舆情信息的分析结果。
-
模型训练和更新:可以考虑使用机器学习方法对舆情信息进行分类和预测。通过使用已标注的数据集,可以训练模型并进行分类,以便更准确地检测和分析舆情信息。此外,还需要定期更新模型,以适应舆情信息的变化和演化。

















 1395
1395

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









