




 本文介绍了如何利用机器学习技术,特别是卷积神经网络和目标检测算法,设计一个芯片缺陷识别系统。重点讲述了算法理论基础,如LeNet和Inception模块的应用,以及模型训练中的数据处理、模型选择(如YOLO模型的优化)和结果分析,使用Tensorboard进行可视化监控以优化训练过程。
本文介绍了如何利用机器学习技术,特别是卷积神经网络和目标检测算法,设计一个芯片缺陷识别系统。重点讲述了算法理论基础,如LeNet和Inception模块的应用,以及模型训练中的数据处理、模型选择(如YOLO模型的优化)和结果分析,使用Tensorboard进行可视化监控以优化训练过程。
目录
前言
📅大四是整个大学期间最忙碌的时光,一边要忙着备考或实习为毕业后面临的就业升学做准备,一边要为毕业设计耗费大量精力。近几年各个学校要求的毕设项目越来越难,有不少课题是研究生级别难度的,对本科同学来说是充满挑战。为帮助大家顺利通过和节省时间与精力投入到更重要的就业和考试中去,学长分享优质的选题经验和毕设项目与技术思路。
🚀对毕设有任何疑问都可以问学长哦!
选题指导:
大家好,这里是海浪学长毕设专题,本次分享的课题是
🎯基于机器学习的芯片缺陷识别检测系统
一、课题背景与意义
在芯片制造过程中,由于工艺变异、设备故障或材料缺陷等原因,芯片可能会出现各种类型的缺陷,如电路连接错误、线路断开和材料污染等。准确地识别和检测芯片缺陷对于确保产品质量和提高制造效率至关重要。芯片缺陷识别能够为电子制造和质量控制提供科学工具和决策支持,提高缺陷检测的准确性和效率,推动电子制造和智能制造的发展与应用。
二、设计思路
2.1.算法理论基础
神经认知机中使用了S-细胞和C-细胞两种不同的结构。由S-细胞提取数据中的局部特征,C-细胞对于这些特征的形变如位移不产生敏感,因此网络具有平移不变性,使得输入的局部特征逐渐积累,并在更深层的网络中进行分类。随后,在此基础上,LeCun等人使用了反向传播算法思想设计并训练了LeNet网络,它在一些图像分类应用中取得较好的分类结果,之后的卷积神经网络则在LeNet网络的基础上不断发展。
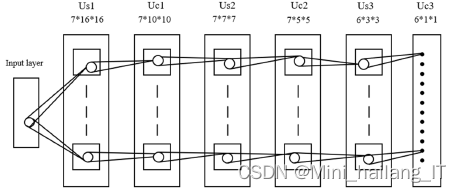
与传统神经网络中层与层之间采用的全连接方法不同,卷积神经网络通过局部感受野、神经元权重共享等方式,将特征图作为层与层之间连接的方式,这种方式指数性地减少了计算时所需参数,降低了网络复杂度,使得卷积神经网络较传统神经网络训练速度大大提升,也使得针对图像、视频等大矩阵输入数据的网络训练有可能实现。
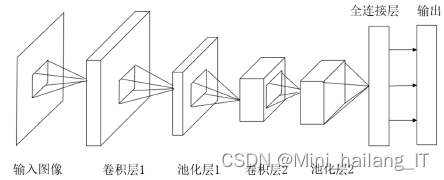
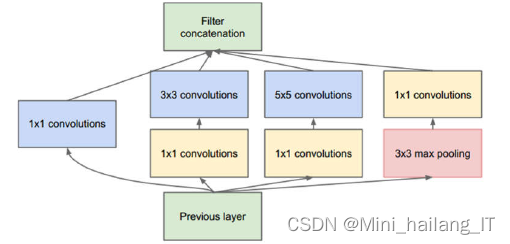
在网络中加入了inception模块,增加网络深度和宽度的同时实现了减少参数的效果。同时期的VGG网络也大幅改变了传统CNN的结构,把网络加深到了20层左右,使得图像识别的error rate也大幅提升到6.7%,接近人类的5.1%。使用一般意义上的有参层来直接学习残差比直接学习输入、输出间映射收敛速度更快,同时提升最终的分类精度。在参加网络的基础上提出了DenseNet架构,该架构将网络中的每一层都进行链接,每层的输入由所有之前层的特征映射组成,其输出将传输给每个后续层。这种新型结构不仅能解决梯度消失问题,而且能提高网络的参数效率,在参数不变的情况下,复用所学习到的特性信息,提高网络效率。
代码如下(示例):
# 定义Inception模块
class InceptionModule(nn.Module):
def __init__(self, in_channels, out_channels):
super(InceptionModule, self).__init__()
self.branch1x1 = nn.Conv2d(in_channels, out_channels[0], kernel_size=1)
self.branch3x3 = nn.Sequential(
nn.Conv2d(in_channels, out_channels[1], kernel_size=1),
nn.Conv2d(out_channels[1], out_channels[2], kernel_size=3, padding=1)
)
self.branch5x5 = nn.Sequential(
nn.Conv2d(in_channels, out_channels[3], kernel_size=1),
nn.Conv2d(out_channels[3], out_channels[4], kernel_size=5, padding=2)
)
self.branch_pool = nn.Sequential(
nn.MaxPool2d(kernel_size=3, stride=1, padding=1),
nn.Conv2d(in_channels, out_channels[5], kernel_size=1)
)
def forward(self, x):
branch1x1 = self.branch1x1(x)
branch3x3 = self.branch3x3(x)
branch5x5 = self.branch5x5(x)
branch_pool = self.branch_pool(x)
outputs = [branch1x1, branch3x3, branch5x5, branch_pool]
return torch.cat(outputs, 1)
# 创建一个简化版的Inception模块
inception_module = InceptionModule(in_channels=256, out_channels=[64, 96, 128, 16, 32, 32])2.2 检测算法实现
目标检测算法的预测值和真实值为目标的位置信息以及其对应的目标标签,因此会对其定位精度以及分类能力这两方面进行评价。在对网络目标定位精度进行评价时,通常采用IoU值作为评判标准。IoU的定义为网络预测框以目标真实定位框之间的交并比。
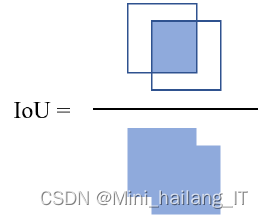
对网络分类能力进行评价时,会采用计算网络平均精度(AP)的方法。具体步骤为先设定一个阈值,该阈值一般为0.5,当该预测框的IoU值大于0.5时,则认为网络对该目标的检测正确,即该结果为真正例(TP);而当IoU小于阈值时,则认为该结果为假正例(FP);当真实框存在但是网络未检测出该目标时,该例为假反例(FN)。
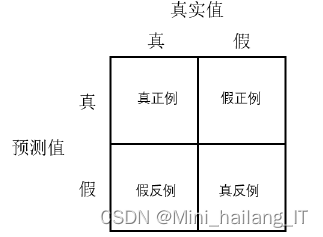
AP的定义为查准率-查全率曲线下面积,通常来说AP值越高,表示目标检测效果越好。

代码如下(示例):
def calculate_iou(pred_box, true_box):
# 计算交集的坐标
x1 = max(pred_box[0], true_box[0])
y1 = max(pred_box[1], true_box[1])
x2 = min(pred_box[2], true_box[2])
y2 = min(pred_box[3], true_box[3])
# 计算交集的面积
intersection_area = max(0, x2 - x1 + 1) * max(0, y2 - y1 + 1)
# 计算预测框和真实框的面积
pred_box_area = (pred_box[2] - pred_box[0] + 1) * (pred_box[3] - pred_box[1] + 1)
true_box_area = (true_box[2] - true_box[0] + 1) * (true_box[3] - true_box[1] + 1)
# 计算并集的面积
union_area = pred_box_area + true_box_area - intersection_area
# 计算IoU
iou = intersection_area / union_area
return iou三、模型训练
3.1 实验环境
对于 Faster R-CNN 而言对于计算资源的需求更高,因此 CPU 难以满足计算所需内存或运算周期过长。因此在训练 Faster R-CNN 时需要选择安装 GPU 的服务器。训练环境为 python3.7、TensorFlow1.14.0 以及 keras2.1.5,选用的 GPU 版本为 NVIDIA GTX 1080Ti 显卡,显存为 11GB。
3.2 数据处理
在芯片缺陷检测系统中,数据集的数据扩充和数据标记是至关重要的步骤。它们可以帮助提高系统的性能和鲁棒性,从而更准确地检测芯片上的缺陷。
数据扩充是通过对原始图像进行各种变换和增强操作来增加数据集的多样性和数量。这些操作可以包括旋转、翻转、平移、缩放、噪声添加等。通过这些变换,可以模拟不同的角度、尺度和光照条件,以提供更广泛的训练样本。此外,还可以应用图像增强技术,如对比度增强、亮度调整、滤波等,以增加图像的多样性和鲁棒性。
相关代码示例:
def data_augmentation(image):
# 旋转
angle = np.random.randint(-30, 30)
rows, cols, _ = image.shape
M = cv2.getRotationMatrix2D((cols / 2, rows / 2), angle, 1)
rotated = cv2.warpAffine(image, M, (cols, rows))
# 翻转
flip = np.random.choice([True, False])
if flip:
flipped = cv2.flip(rotated, 1)
else:
flipped = rotated
# 平移
dx = np.random.randint(-20, 20)
dy = np.random.randint(-20, 20)
translation_matrix = np.float32([[1, 0, dx], [0, 1, dy]])
translated = cv2.warpAffine(flipped, translation_matrix, (cols, rows))
# 缩放
scale = np.random.uniform(0.8, 1.2)
scaled = cv2.resize(translated, None, fx=scale, fy=scale)
# 噪声添加
noise = np.random.normal(0, 1, image.shape).astype(np.uint8)
noisy = cv2.add(scaled, noise)
return noisy
# 加载原始图像
original_image = cv2.imread('original_image.jpg')
# 数据扩充
augmented_image = data_augmentation(original_image)
数据标记是为每个图像提供准确的标签或边界框,以指示芯片上的缺陷位置和类型。标记过程需要人工进行,标注人员需要对芯片缺陷具有准确的识别能力。对于缺陷检测,需要标注每个缺陷的位置和边界框。这样,系统就可以学习到缺陷的形状、大小和位置信息。
相关代码示例:
def label_defects(image, defect_locations):
labeled_image = image.copy()
for defect_loc in defect_locations:
x, y, w, h = defect_loc
cv2.rectangle(labeled_image, (x, y), (x + w, y + h), (0, 0, 255), 2) # 在缺陷位置画边界框
return labeled_image
# 加载原始图像
image = cv2.imread('chip_image.jpg')
# 假设我们有一些已知的缺陷位置
defect_locations = [(100, 100, 50, 50), (200, 200, 30, 30)] # (x, y, width, height) 格式
# 进行数据标记
labeled_image = label_defects(image, defect_locations)
# 显示结果
cv2.imshow('Original Image', image)
cv2.imshow('Labeled Image', labeled_image)
cv2.waitKey(0)
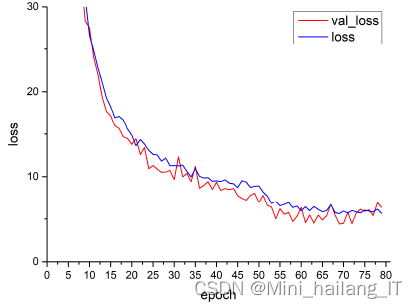
cv2.destroyAllWindows()Tensorboard 是 TensorFlow 提供的一组可视化工具,可以用来监控训练过程中各个指标的变化情况,有助于开发者了解训练进度从而更好地理解、调试以及优化程序。Tensorboard 还可以用来绘制深度学习网络模型的计算图以及训练时的其他信息,比如计算各个层时所用到的参数个数。本文使用 Tensorboard 来监控网络模型的损失函数变化曲线,通过观察训练集以及验证集上的损失函数收敛情况,阻止网络进入过拟合或者欠拟合的状态,当损失函数收敛到某一程度时,必要情况下可以提前停止训练。
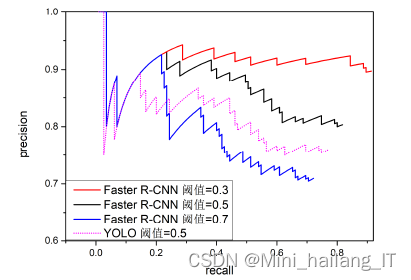
在识别能力上自选锚框 YOLO 模型>默认锚框 YOLO 模型>默认锚框 tiny YOLO 模型。而训练时间方面 tiny YOLO 模型要大大少于 YOLO 模型。其中自选锚框的 darknet-53 模型在识别精度上是三种模型中最高的,主要原因是使用了带有先验性的锚框能比默认锚框更好地预测边界框先验尺寸和真实值之间的偏移量,使得预测结果的 IoU 值更高,与 tiny YOLO 模型相比较,YOLO 网络的模型参数更多,模型更容易泛化,增加网络的深度能提升网络的识别准确率。而在检测图像速度方面,tiny YOLO 模型由于模型参数少,因此要优于其他两种模型。
3.3 结果分析
使用 Tensorboard 监控训练过程,网络训练时选择 BP 算法和 SGD 算法实现训练,激活函数选择ReLU 函数,特征提取卷积层参数选择在 ImageNet 数据集上经过预训练的网络参数,其它层是用随机的高斯分布初始化权重。初始学习率设定为 1×10^{-4},每个周期迭代次数为 1000 次,总共训练 200 个周期。



















 8402
8402

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









