








专栏导读
✍ 作者简介:i阿极,优快云 数据分析领域优质创作者,专注于分享python数据分析领域知识。
✍ 本文录入于《python网络爬虫实战教学》,本专栏针对大学生、初级数据分析工程师精心打造,对python基础知识点逐一击破,不断学习,提升自我。
✍ 订阅后,可以阅读《python网络爬虫实战教学》中全部文章内容,包含python基础语法、数据结构和文件操作,科学计算,实现文件内容操作,实现数据可视化等等。
✍ 其他专栏:《数据分析案例》 ,《机器学习案例》😊😊😊如果觉得文章不错或能帮助到你学习,可以点赞👍收藏📁评论📒+关注哦!👍👍👍
1.目标
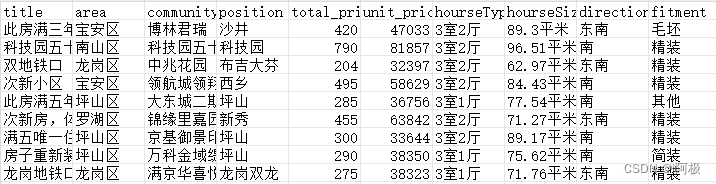
爬取深圳2024年链家二手房数据,内容有
title,area,community,position,total_price,unit_price,hourseType,hourseSize,direction,fitment
此房满三年,高楼层南向视野无遮挡,毛坯原始户型三房,宝安区,博林君瑞,沙井,420,47033 ,3室2厅,89.3平米,东南,毛坯
数据量为3000条,为数据分析、机器学习、毕设做数据支撑。
2.导入相关库
import csv
from bs4 import BeautifulSoup
import requests
csv 是 Python 的一个标准库,用于读写 CSV(逗号分隔值)文件。CSV 是一种常见的文件格式,用于存储表格数据(如电子表格或数据库)。
BeautifulSoup 是一个 Python 库,用于从 HTML 和 XML 文件中提取数据。它通常与像 lxml 或 html.parser 这样的解析器一起使用。
requests 是一个 Python 库,用于发送 HTTP 请求。它使发送 HTTP 请求(如 GET、POST 等)变得简单。
3.获取每个二手房的链接
for i in range(1,101):
url = f'https://sz.lianjia.com/ershoufang/pg{i}rs%E6%B7%B1%E5%9C%B3/'
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36"
}
data = requests.get(url=url, headers=headers).text
soup = BeautifulSoup(data,'lxml')
a_tags = soup.find_all('a', class_='noresultRecommend')
for a_tag in a_tags:
href = a_tag.get('href')
href_list.append(href)
代码解释:
循环遍历页面:通过修改URL中的页码参数(pg{i}),代码循环遍历从第一页到第一百页(包含第一页,不包含第一百零一页)的页面。
模拟浏览器行为:通过设置HTTP请求头中的User-Agent字段,代码模拟了来自一个真实浏览器的请求,以避免被网站识别为爬虫。
发送HTTP GET请求:使用requests.get()方法向每个页面发送HTTP GET请求,并获取响应的文本内容。
解析HTML:使用BeautifulSoup库和’lxml’解析器解析响应的HTML内容,以便进一步提取数据。
查找特定链接:通过调用find_all()方法,代码查找所有具有类名’noresultRecommend’的 < a > 标签(链接)。
存储链接:遍历找到的链接,提取它们的href属性(即链接地址),并将这些地址添加到一个名为href_list的列表中。注意,在实际运行代码之前,需要确保已经定义了href_list列表。
4.获取每个链接中的相关数据
for j in range(len(href_list)):
try:
print(href_list[j])
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36"
}
data = requests.get(url=href_list[j], headers=headers).text
soup = BeautifulSoup(data,'lxml')
#title
title_h1 = soup.find('h1',class_='main')
for titles in title_h1:
title = titles
#area
area_span = soup.find('span',class_='info')
area_a = area_span.find('a').text
for position_a in area_span.find_all('a')[-1]:
position = position_a
#community
community = soup.find('a',class_='info').text
#total_price
try:
total_price_div = soup.find('div',class_='price')
for total_price_span in total_price_div.find('span',class_='total'):
total_price = total_price_span
except:
total_price = None
# unit_price
try:
unit_price_span = soup.find('span',class_='unitPriceValue')
unit_price = unit_price_span.get_text(strip=True, separator=" ")[:-4]
except:
unit_price = None
#hourseType
hourseType = soup.find('div',class_='mainInfo').text
#hourseSize
hourseSize_div = soup.find('div',class_='area')
for hourseSize_divs in hourseSize_div.find('div',class_='mainInfo'):
hourseSize = hourseSize_divs
#direction
direction_div = soup.find('div',class_='type')
for direction_divs in direction_div.find('div',class_='mainInfo'):
direction = direction_divs
#fitment
fitment_div = soup.find('div',class_='type')
for fitment_divs in fitment_div.find('div',class_='subInfo'):
fitment = fitment_divs[-2:]
代码解释:
对列表href_list循环,获取列表里的链接,爬取需要的内容:
title,area,community,position,total_price,unit_price,hourseType,hourseSize,direction,fitment
此房满三年,高楼层南向视野无遮挡,毛坯原始户型三房,宝安区,博林君瑞,沙井,420,47033 ,3室2厅,89.3平米,东南,毛坯
5.保存数据
with open('深圳2024年链家二手房信息_1.csv', mode='w', newline='', encoding='utf-8') as csv_file:
fieldnames = [
'title', 'area', 'community', 'position', 'total_price',
'unit_price', 'hourseType', 'hourseSize', 'direction', 'fitment'
]
writer = csv.DictWriter(csv_file, fieldnames=fieldnames)
writer.writeheader()
代码解释:
这段代码的主要目的是创建一个新的 CSV 文件(或覆盖现有的同名文件),并写入一个包含多个字段名的表头。这些字段名定义了 CSV 文件中将要包含的列。接下来,你可以使用 writer.writerow(dict_row) 方法来向 CSV 文件中写入包含这些字段的字典数据行。
6.数据展示
如果需要数据集或源码(每个代码详解)可在博主首页的“资源”下载。
挣点小外快:需要其他城市的数据集可联系博主
📢文章下方有交流学习区!一起学习进步!💪💪💪
📢首发优快云博客,创作不易,如果觉得文章不错,可以点赞👍收藏📁评论📒
📢你的支持和鼓励是我创作的动力❗❗❗



















 518
518

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











