



零基础搞定RAG应用:用LangChain搭建会“读文档”的AI客服!
你是不是也想过,能不能让AI直接读取你公司的最新文档、网页文章,甚至PDF资料,然后精准地回答用户问题?不再依赖模型的老知识,也不用费劲微调?——这就是RAG(检索增强生成)技术的魅力!
今天我就带大家一步步实现一个真正的RAG应用:从网页抓内容、处理文本、构建检索链,到最终实现基于真实文档的智能问答。不用怕复杂,我们会用LangChain这个超好用的工具,像搭积木一样把功能堆起来!
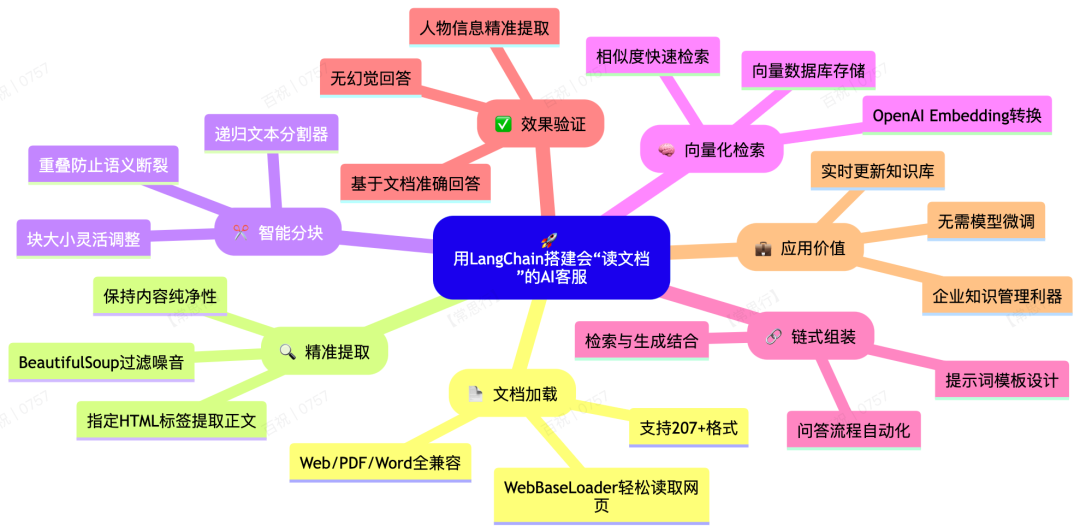
一、从哪里读文档?网页、PDF、Word都没问题!
我们首先要解决一个问题:怎么把不同格式的文档“喂”给AI? LangChain提供了将近207种文档加载器,几乎覆盖所有常见格式。
比如:
- 网页内容用
WebBaseLoader - PDF文件用
PyPDFLoader - Word文档用
Docx2txtLoader
✅ 你完全不用担心格式问题!
以网页为例,假设我们想读取新华网一篇关于“AI与人才需求”的文章,可以这样写:
from langchain.document_loaders import WebBaseLoader
url = "https://example.com/ai-news" # 替换成实际网址
loader = WebBaseLoader(url)
documents = loader.load()
就这么简单,documents 里就是网页的文本内容啦!
二、只要文字,不要图片广告!用BeautifulSoup精准提取
网页上常有图片、广告、视频等干扰内容,我们怎么精准提取正文? 这时候可以配合 BeautifulSoup 这个库(注意安装:pip install beautifulsoup4),通过指定HTML标签提取内容。
例如,如果你发现正文都在 <div class="main-content"> 里,就可以这样设置:
loader = WebBaseLoader(
web_paths=(url),
bs_kwargs={"parse_only": {"class_": "main-content"}}
)
这样就只会抓取指定区域内的文本,其他内容自动忽略!
loader = WebBaseLoader(
web_paths=[url],
bs_kwargs=dict(
parse_only = bs4.SoupStarainer(class_=("main-content"))
)
)
三、文档太长怎么办?切块处理是关键!
直接扔一整篇文章给AI效果很差——容易丢失细节、处理速度慢。 所以一定要做 Text Chunking(文本分块)!
LangChain提供了多种分块工具,最常用的是 RecursiveCharacterTextSplitter。它支持设置:
chunk_size:每块大小(按字符数)chunk_overlap:块与块之间的重叠字符数(防止语义被切断)
from langchain.text_splitter import RecursiveCharacterTextSplitter
splitter = RecursiveCharacterTextSplitter(
chunk_size=500,
chunk_overlap=100
)
chunks = splitter.split_documents(documents)
重叠部分很重要!比如“猎聘大数据研究院”如果被切成“猎聘”和“大数据研究院”,意思就残破了。重叠100字符能很大程度上避免这个问题。
四、把文本变成向量:AI才能看懂和检索
文字切块后,要转换成数值向量才能被AI处理。 这里我们用OpenAI的Embedding模型(或者其他开源模型也行),配合向量数据库(比如Chroma、FAISS)。
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import Chroma
embeddings = OpenAIEmbeddings()
vectorstore = Chroma.from_documents(chunks, embeddings)
retriever = vectorstore.as_retriever()
现在我们就有了一个 检索器(retriever),它可以根据用户问题快速找到最相关的文本块!
五、组装整个流程:提示词 + 检索 + 生成答案
最精彩的环节来了——把检索器和大模型组装成一条链! 我们要做到:用户提问 → 检索相关文档 → 生成答案。
首先,设计一个提示词模板,告诉AI怎么利用检索到的内容:
from langchain.prompts import ChatPromptTemplate
template = """
你是一个专业的问答助手,请根据以下上下文回答问题:
{context}
问题:{input}
"""
prompt = ChatPromptTemplate.from_template(template)
然后,把检索器、提示词、模型组装成链:
from langchain.chains import create_retrieval_chain
from langchain.chains.combine_documents import create_stuff_documents_chain
from langchain_openai import ChatOpenAI
model = ChatOpenAI(model="gpt-3.5-turbo")
document_chain = create_stuff_documents_chain(model, prompt)
rag_chain = create_retrieval_chain(retriever, document_chain)
大功告成!现在我们可以提问了:
response = rag_chain.invoke({"input": "张成刚是谁?"})
print(response["answer"])
六、效果验证:真的能基于文档回答!
我们测试两个问题:
- ❓“张成刚是谁?” ✅ AI正确回答:“首都经贸大学副教授”(完全来自网页内容)
- ❓“报道中还提到了哪些人?” ✅ AI列出:“刘征、周元(老万马有才创始总经理)”
完全基于文档,没有胡说八道!这就是RAG的价值——让AI答有所据,绝不信口开河。
七、总结:RAG是企业知识管理的利器
通过这个例子,你已经掌握了用LangChain搭建RAG应用的核心流程:
- 加载文档:Web/PDF/Word都能吃进去
- 精准提取:用BeautifulSoup剔除噪音
- 智能分块:设置重叠防止语义断裂
- 向量检索:把文本变成可检索的向量
- 组装成链:提示词 + 检索 + 生成答案
未来你可以:
- 接入企业内部的PDF、Word、Notion文档
- 尝试不同的分块策略和向量数据库
- 加入对话历史,做成多轮问答客服
RAG让我们不再依赖模型的老知识,也不用费劲做微调。直接让AI“阅读”你的最新资料,实时回答问题——这才是真正的智能助手!
✨动手试试吧! 完整代码已涵盖在上面,你只需要准备一个OpenAI API Key和一篇想处理的文档,就能搭建属于自己的文档问答系统啦~
最近这几年,经济形式下行,IT行业面临经济周期波动与AI产业结构调整的双重压力,很多人都迫于无奈,要么被裁,要么被降薪,苦不堪言。但我想说的是一个行业下行那必然会有上行行业,目前AI大模型的趋势就很不错,大家应该也经常听说大模型,也知道这是趋势,但苦于没有入门的契机,现在他来了,我在本平台找到了一个非常适合新手学习大模型的资源。大家想学习和了解大模型的,可以**点击这里前往查看**

















 368
368

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









