



当前AI大模型市场风起云涌,国产模型正以前所未有的速度追赶国际先进水平。根据中国信息通信研究院《人工智能算力基础设施赋能研究报告(2025年)》显示,推进基础预训练大模型的训练需要具备E级计算能力的高端万卡集群中心支撑,而国产大模型在技术架构和应用效果上已达到国际领先水平。面对DeepSeek V3.2和Qwen3 Max这两款备受瞩目的国产大模型,企业决策者该如何选择?本文将通过全维度对比分析,为您提供最权威的选型指南。
一、核心架构与技术特性对比
1.1 模型架构深度解析
DeepSeek V3.2采用了先进的混合专家模型(MoE)架构,拥有671B参数规模,但实际激活参数约为37B,这种设计在保证性能的同时显著降低了推理成本。该模型支持64K上下文长度,最大输出可达16K tokens,特别针对数学推理和代码生成进行了深度优化。
Qwen3 Max同样基于MoE架构构建,参数规模与DeepSeek相当,但在多模态处理能力上表现更为突出。该模型不仅支持文本生成,还具备图像理解、图像生成等多模态能力,上下文窗口支持128K tokens,为长文档处理提供了更大的空间。
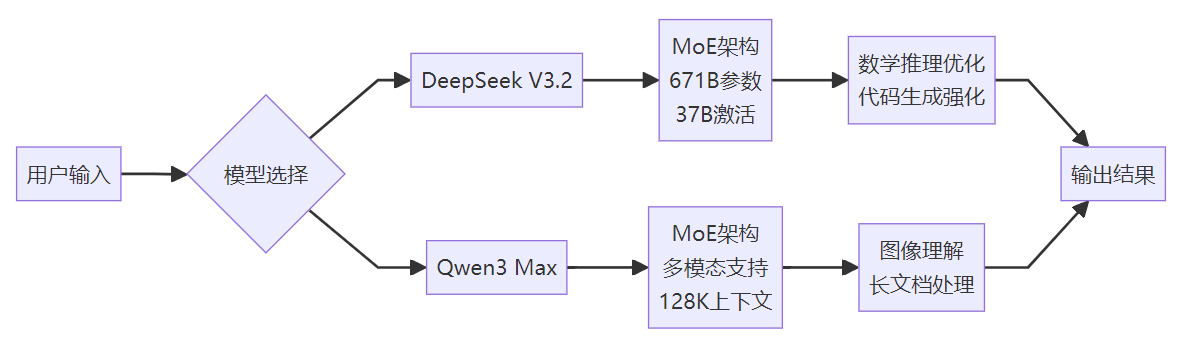
图:DeepSeek V3.2与Qwen3 Max架构对比流程
1.2 技术创新亮点
在技术创新方面,DeepSeek V3.2引入了稀疏注意力机制DSA(Deep Sparse Attention),旨在优化长文本训练与推理效率。这一创新使得模型在处理复杂推理任务时能够更精准地分配计算资源,实现了训练推理提效的目标。
Qwen3 Max则在多模态融合技术上实现了突破,其独特的"图像生成纵横比选择"功能允许用户自定义输出图像的比例,这在实际应用中为创意设计和内容生成提供了更大的灵活性。
二、性能基准测试全面解析
基于多个权威评测平台的最新数据,我们对两款模型在核心能力维度进行了全面对比:
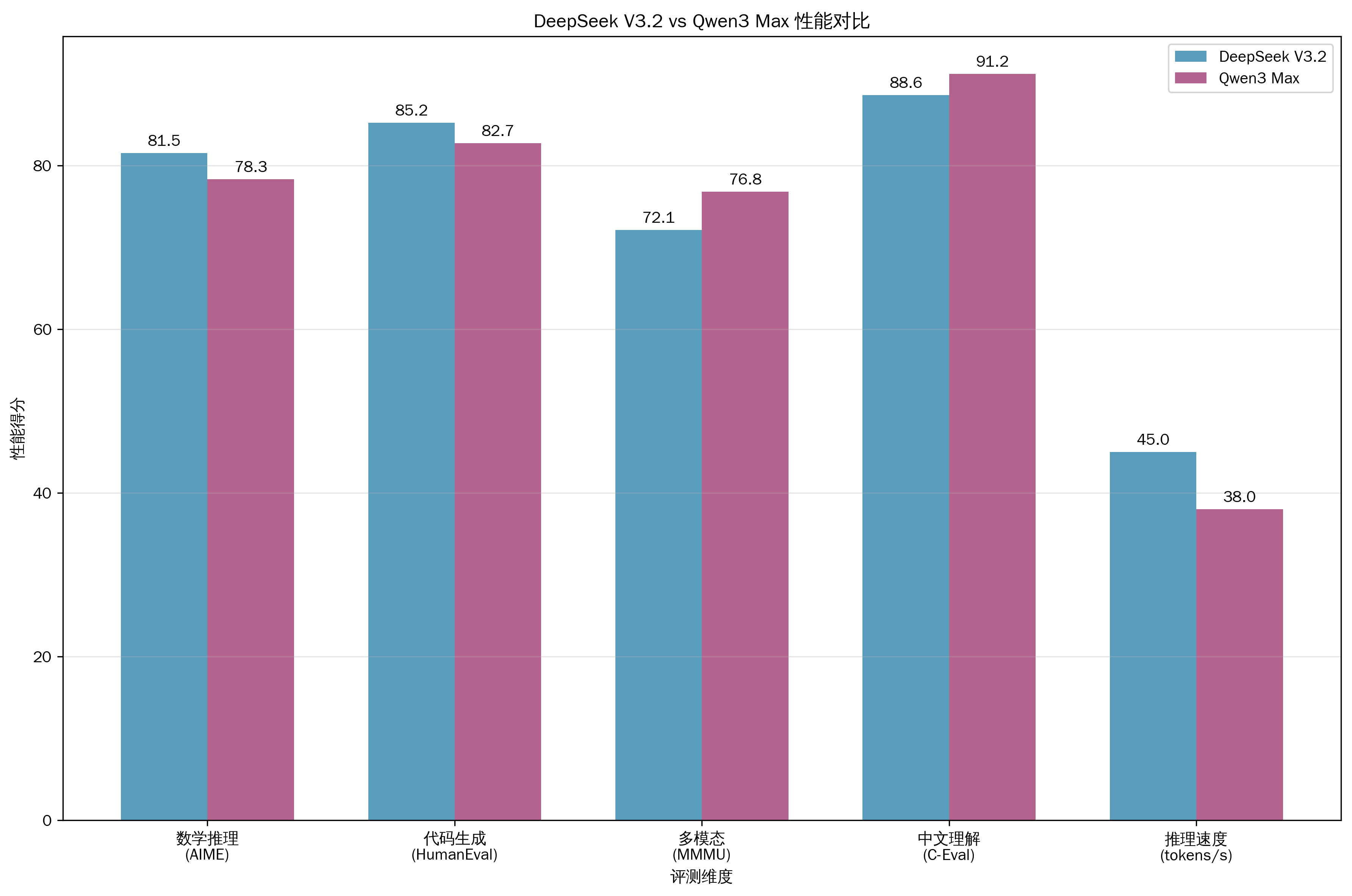
图:DeepSeek V3.2 vs Qwen3 Max 性能对比
从评测结果可以看出,DeepSeek V3.2在数学推理(AIME评测81.5分)和代码生成(HumanEval 85.2分)方面表现突出,这得益于其针对性的训练优化。而Qwen3 Max在中文理解(C-Eval 91.2分)和多模态处理(MMMU 76.8分)方面更胜一筹,体现了其在本土化和多模态能力上的技术优势。
三、企业级应用场景适配指南
3.1 行业应用场景分析
不同行业对AI模型的需求存在显著差异,选择合适的模型对于应用效果至关重要:
金融行业应用:
-
DeepSeek V3.2适用场景:风险评估模型、量化交易策略、财务报表分析
-
核心优势:强大的数学推理能力,能够处理复杂的金融计算和风险建模
教育行业应用:
-
Qwen3 Max适用场景:智能教学助手、多媒体课件生成、学习效果评估
-
核心优势:多模态处理能力,能够理解和生成图文并茂的教学内容
制造业应用:
-
DeepSeek V3.2适用场景:生产流程优化、设备故障预测、质量控制算法
-
Qwen3 Max适用场景:产品设计辅助、技术文档生成、培训材料制作
3.2 部署模式选择
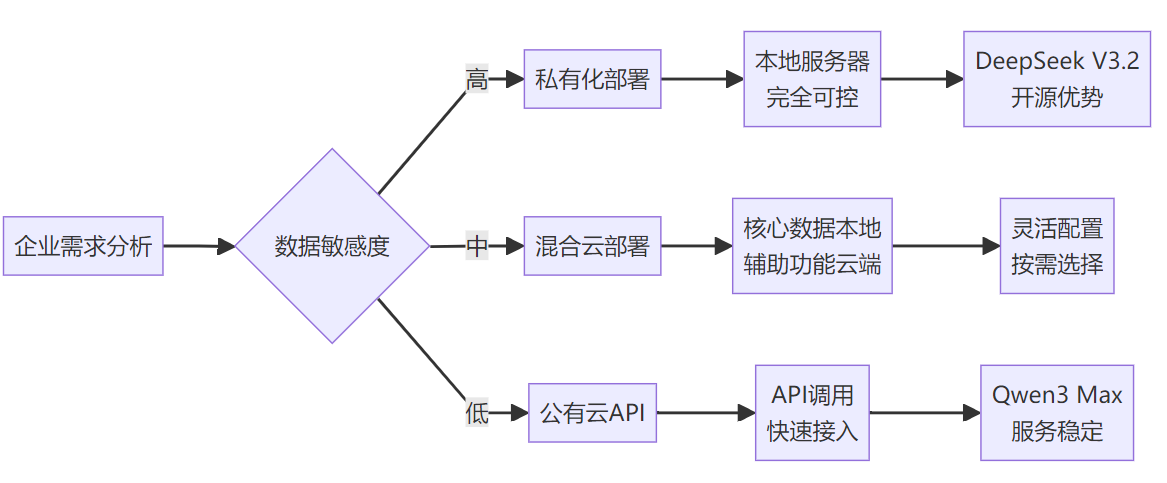
图:企业AI模型部署决策流程
对于数据安全要求较高的企业,DeepSeek V3.2的开源特性提供了更大的部署灵活性。企业可以在自有服务器上部署模型,确保数据不出境的同时享受先进的AI能力。而Qwen3 Max通过阿里云提供的企业级服务,在数据安全和服务稳定性方面也有良好保障。
四、开源生态与技术支持对比
4.1 开源社区活跃度
DeepSeek V3.2作为开源模型,拥有活跃的开发者社区。开发者可以自由访问模型权重、训练代码和技术文档,这为企业进行深度定制和优化提供了可能。社区贡献的插件和工具也大大降低了集成难度。
Qwen3 Max虽然不完全开源,但阿里巴巴提供了丰富的开发工具和API文档。通过阿里云的技术支持体系,企业可以获得专业的技术咨询和问题解决方案。
4.2 技术生态完整性
| 维度 | DeepSeek V3.2 | Qwen3-Max |
|---|---|---|
| 模型开源性 | ✔️ 完全开源(可下载模型权重) | ❌ 闭源,仅云端 API |
| 参数规模(总参数) | 671B(MoE,激活约 37B) | 1T+(更大规模) |
| API 价格 | 整体较低(低成本策略) | 中等偏高(旗舰模型) |
| 推理性能 / 效率 | MoE 架构 + 稀疏注意力,效率高 | 超大模型,推理成本高 |
| 通用任务能力(质量) | 强,表现快速提升 | 极强,旗舰模型 |
| 长文本处理能力 | 优秀(架构优化明显) | 强,但成本更高 |
| 企业级支持 | 中等(生态刚起步) | 强(阿里云基础设施) |
| 生态工具链 | 中等 | 非常成熟(ModelScope、阿里云工具链) |
| 社区活跃度(开源社区) | 极高(开源优势带动) | 中等(Max 版闭源) |
| 使用门槛 | 需要更多工程能力 | 直接 API,简单易用 |
五、中国市场本土化优势分析
5.1 中文语料优化
两款模型都在中文语料处理方面进行了深度优化,但各有特色:
DeepSeek V3.2在中文数学和编程领域表现突出,能够准确理解中文描述的技术问题并给出相应的代码解决方案。这对于国内的技术团队来说具有重要价值。
Qwen3 Max在中文文本理解和生成方面更为全面,特别是在商业文档、创意写作等应用场景中,能够产生更符合中文表达习惯的内容。
5.2 合规性与数据安全
在数据合规方面,两款模型都严格遵循中国的相关法律法规:
-
数据本土化:模型训练和推理过程中的数据处理均在境内完成
-
内容审核机制:内置完善的内容安全过滤系统,确保输出内容合规
-
隐私保护:采用先进的隐私计算技术,保护用户数据安全
六、选型决策矩阵与建议
| 应用场景 | 推荐模型 | 核心理由 | 适用企业类型 |
|---|---|---|---|
| 数学计算密集型 | DeepSeek V3.2 | 数学推理能力突出,成本极低 | 金融、科研、工程 |
| 代码开发辅助 | DeepSeek V3.2 | 代码生成质量高,开源可定制 | 软件公司、技术团队 |
| 内容创作与营销 | Qwen3 Max | 中文表达自然,多模态支持 | 媒体、广告、电商 |
| 客户服务与咨询 | Qwen3 Max | 对话能力强,理解准确度高 | 服务业、咨询公司 |
| 教育培训 | Qwen3 Max | 多模态教学,内容生成丰富 | 教育机构、企业培训 |
| 大规模批量处理 | DeepSeek V3.2 | 成本优势显著,性能稳定 | 制造业、物流业 |
国产AI的未来竞争优势
纵观DeepSeek V3.2与Qwen3 Max的全面对比,我们看到国产大模型正在以技术创新和成本优势重新定义AI应用的边界。DeepSeek V3.2以其卓越的数学推理能力和极致的性价比,为企业提供了高效的AI解决方案;Qwen3 Max则以其全面的多模态能力和本土化优势,满足了企业多样化的应用需求。
选择哪款模型并非简单的优劣判断,而是基于企业具体需求、技术架构和发展战略的综合考量。在这个AI技术快速演进的时代,企业需要的不仅是一个强大的模型,更需要一个能够灵活适应业务变化、确保数据安全、提供持续技术支持的完整解决方案。
随着国产AI技术的不断成熟和生态的日益完善,我们有理由相信,中国的AI企业将在全球竞争中占据越来越重要的地位,为全球用户提供更优质、更智能的AI服务。

















 2397
2397

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









