



Prompt Caching:从技术原理到企业落地的全景图
当企业级AI应用规模化部署时,推理延迟和成本控制成为核心挑战。根据最新的MLSys 2024研究数据显示,传统LLM推理在处理长提示词时,首Token延迟(TTFT)往往成为用户体验的瓶颈。而Prompt Caching技术的出现,正在重新定义AI推理效率的边界——通过智能复用已计算的注意力状态,实现GPU推理速度8倍提升、CPU推理速度60倍提升的突破性表现。本文将深入解析这一革命性技术的工作原理、实施策略和企业级应用实践。
一、Prompt Caching技术概述:重新定义AI推理效率
Prompt Caching(提示缓存)是一种通过预计算和存储频繁出现文本段的注意力状态,来加速大语言模型推理过程的优化技术。其核心理念在于识别并复用提示词中的重复元素,从而显著降低计算成本和响应延迟。
1.1 技术定义与核心价值
Anthropic官方文档将Prompt Caching定义为"一种通过允许从特定前缀恢复来优化API使用的强大功能"。这种技术特别适用于包含大量重复内容的场景,如系统提示词、文档上下文、多轮对话历史等。
核心价值体现:
- 性能提升:显著减少首Token延迟(TTFT),提升用户体验
- 成本优化:通过复用计算结果,大幅降低推理成本
- 规模化支持:为企业级AI应用提供更高效的资源利用方案
1.2 应用背景与发展趋势
随着企业对AI应用的依赖程度不断加深,传统的"每次从零开始计算"模式已无法满足高频、大规模的应用需求。Prompt Caching技术的兴起,正是为了解决这一痛点。据MLSys 2024论文研究显示,在文档问答和推荐系统等场景中,这项技术能够实现8倍到60倍的性能提升。
图:Prompt Caching vs 传统方案性能对比
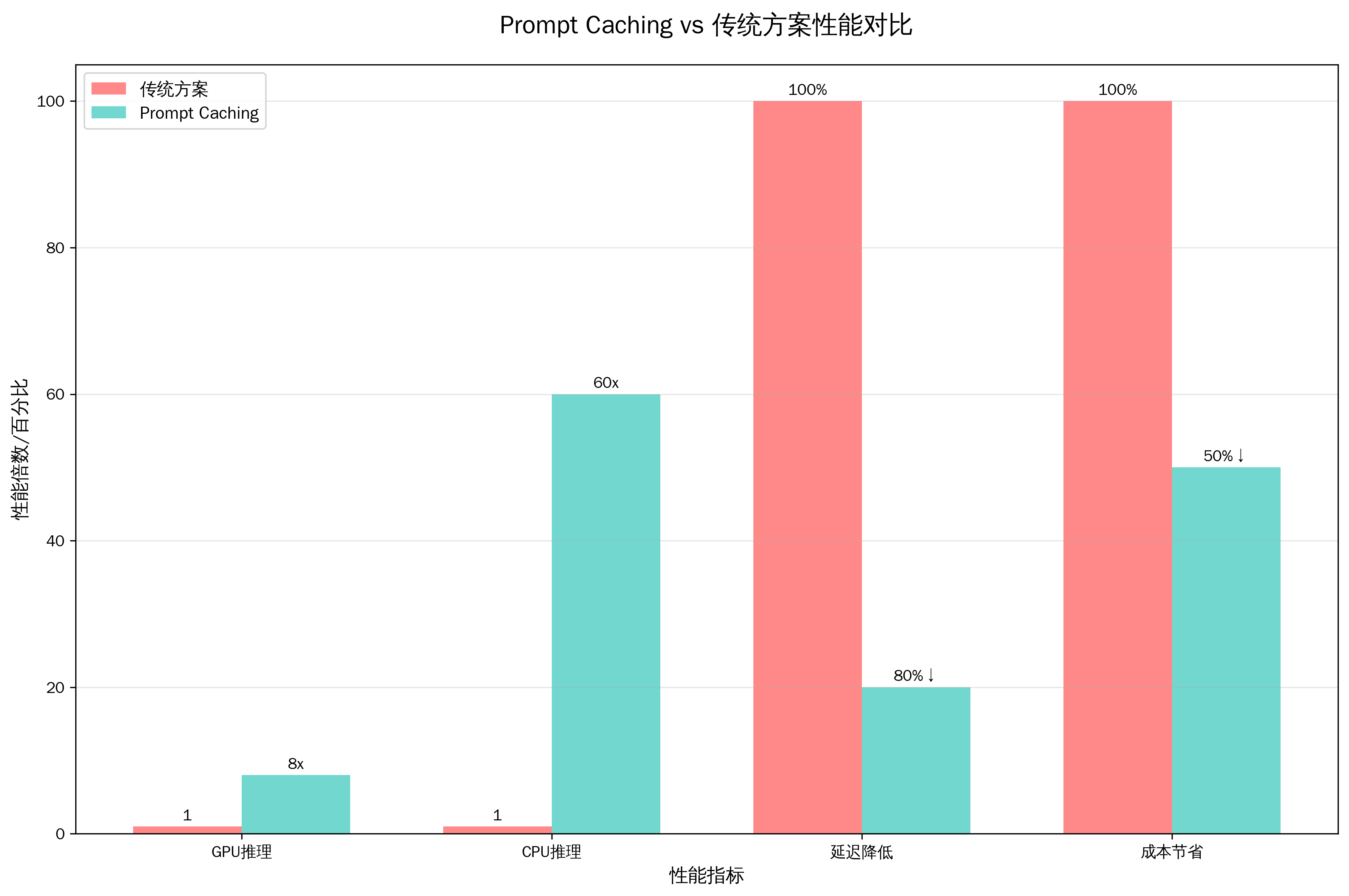
如上图所示,Prompt Caching在多个关键指标上都展现出显著优势,特别是在CPU推理场景下的60倍性能提升,为资源受限的企业环境提供了理想的解决方案。
二、技术原理深度解析:智能复用的实现机制
2.1 前缀匹配与Trie数据结构
Prompt Caching的核心机制基于前缀匹配算法。当系统接收到新的提示词时,会检查其前缀部分是否与已缓存的内容匹配。这一过程通过Trie(字典树)数据结构实现,确保O(m)时间复杂度的高效查找,其中m为前缀长度。
前缀匹配的技术优势:
- 高效识别:利用Trie树结构快速定位匹配前缀
- 灵活扩展:支持多层级的缓存策略
- 实用性强:符合大多数实际应用中"前固定、后变化"的提示词模式
2.2 注意力状态复用机制
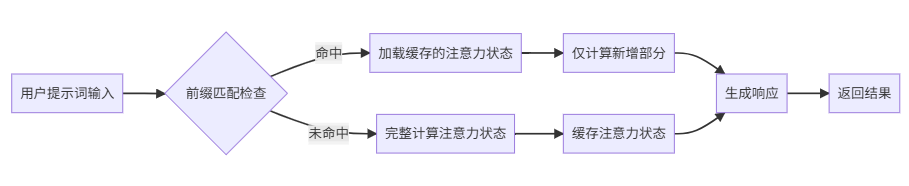
图:Prompt Caching工作流程
如流程图所示,Prompt Caching通过预计算和存储注意力状态,实现了计算资源的智能复用。这种机制不仅减少了重复计算,还保证了输出结果的一致性和准确性。
2.3 与KV Caching的技术区别
许多开发者容易将Prompt Caching与KV Caching混淆。实际上,两者存在本质差异:
| 对比维度 | KV Caching | Prompt Caching |
|---|---|---|
| 作用范围 | 单次会话内的序列优化 | 跨会话的全局优化 |
| 缓存对象 | Key-Value注意力矩阵 | 完整的注意力状态 |
| 应用场景 | 自回归生成优化 | 重复提示词优化 |
| 性能提升 | 单次推理加速 | 整体吞吐量提升 |
三、主流平台实现对比:技术生态全景分析
3.1 OpenAI实现特性
OpenAI的Prompt Caching采用自动化策略,对长度超过1024个token的提示词自动启用缓存。其特点包括:
- 自动启用:无需代码修改,系统自动优化
- 智能路由:将请求路由到处理过相同提示词的服务器
- 成本效益:可实现高达50%的成本节省
3.2 Anthropic Claude方案
Claude的实现更加灵活,通过cache_control参数提供精确控制:
{
"system": [
{
"type": "text",
"text": "系统提示词内容",
"cache_control": {"type": "ephemeral"}
}
]
}
Claude方案优势:
- 精确控制:可指定具体的缓存断点
- 灵活配置:支持多个缓存段的独立管理
- 时效控制:默认5分钟,可扩展至1小时
3.3 AWS Bedrock集成
AWS Bedrock将Prompt Caching与云原生架构深度融合,提供企业级的缓存解决方案。其特色在于与AWS生态系统的无缝集成,支持多种AI模型的统一缓存管理。
图:不同应用场景的缓存效果分析
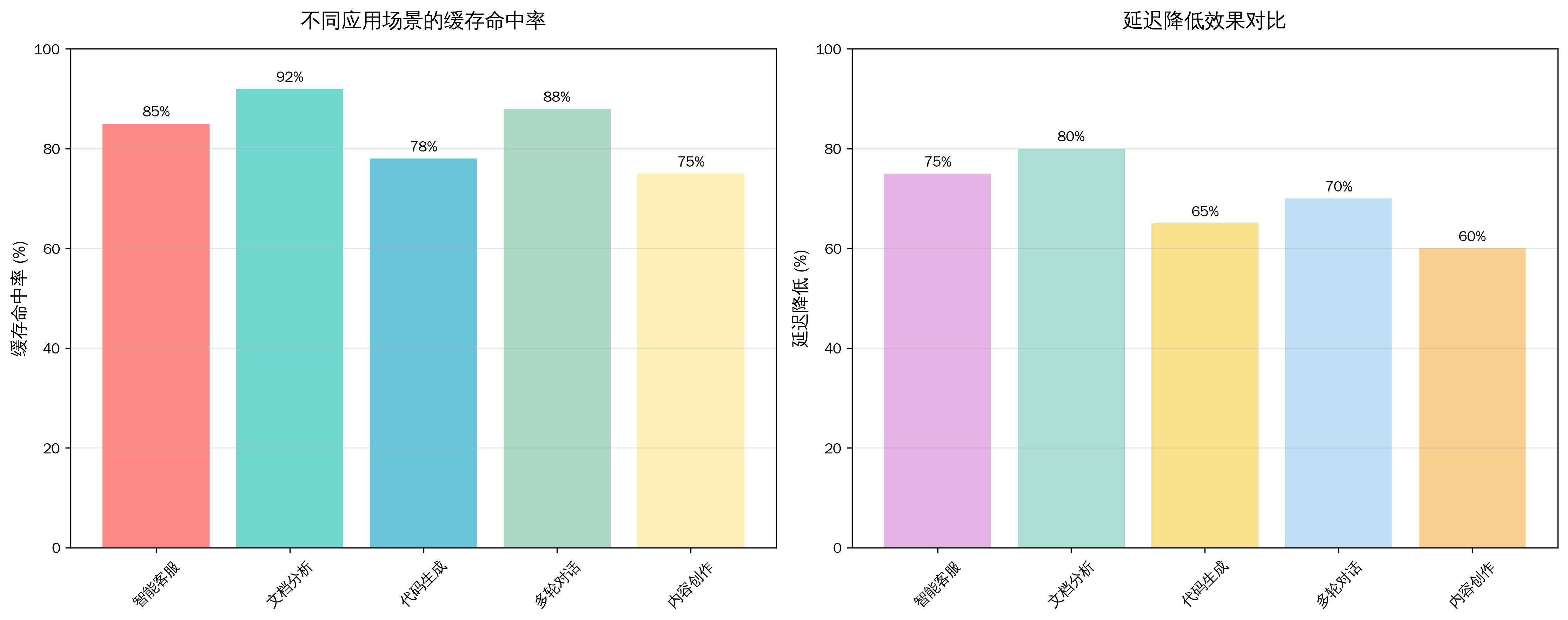
从上图可以看出,不同应用场景下Prompt Caching的效果存在差异。文档分析场景的缓存命中率最高(92%),这主要因为文档内容相对固定,而智能客服场景虽然命中率为85%,但在延迟降低方面表现优异(75%)。
四、最佳实践与应用场景:实战指导手册
4.1 提示词结构优化策略
为了最大化Prompt Caching的效果,需要遵循以下结构化原则:
最佳实践要点:
- 静态内容前置:将系统提示词、背景信息等不变内容放在开头
- 动态内容后置:用户特定信息和变化内容放在结尾
- 合理分段:使用明确的分隔符区分不同内容块
- 长度控制:确保静态部分超过缓存阈值(通常1024 tokens)
4.2 企业级部署场景分析
智能客服系统:
在大规模客服场景中,系统提示词和常见问题模板可以有效缓存。以某企业服务公司为例,通过部署Prompt Caching优化的AI客服系统,实现了7×24小时全自动服务,问题解决率提升4倍,客户满意度提升15%。
文档分析与知识问答:
对于需要处理大量文档的场景,Prompt Caching能够缓存文档内容,大幅提升后续查询的响应速度。这种应用在法律咨询、技术文档检索等领域特别有效。
代码生成与审查:
在软件开发场景中,常用的编程规范、API文档等可以作为缓存内容,加速代码生成和审查过程。
4.3 缓存策略配置指南
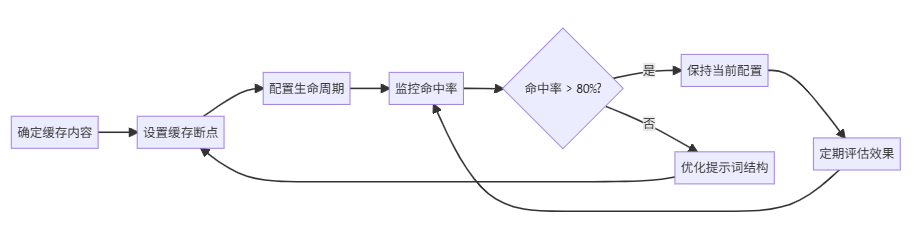
图:缓存策略配置流程
重新定义AI推理效率的技术革命
Prompt Caching技术正在重塑企业级AI应用的性能边界。通过智能复用计算资源,这项技术不仅实现了8-60倍的性能提升,更为企业AI转型提供了成本可控的规模化路径。
随着AI应用场景的不断扩展,Prompt Caching将成为企业提升AI系统效率、降低运营成本的关键技术。对于正在规划AI转型的企业而言,深入理解并合理应用这一技术,将是获得竞争优势的重要因素。
立即开始评估您的AI系统架构,识别Prompt Caching的应用机会,让AI真正成为企业的高效数字员工。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









