 阿拉伯语OCR识别难点与技术方案
阿拉伯语OCR识别难点与技术方案




概述
阿拉伯语OCR(光学字符识别)在技术上比拉丁语系(如英语、法语)更具挑战性,主要受其独特的书写规则、复杂的字形变化以及上下文依赖影响。
核心难点
(1) 连写(Cursive Script)与字符变形
问题:阿拉伯语字母在单词中必须连写,且形状随位置变化(独立、词首、词中、词尾)。例如,字母 "هـ"(Ha) 在不同位置写法不同:
独立:ه
词首:هـ
词中:ـهـ
词尾:ـه
挑战:传统OCR按字符切割的方式失效,必须结合上下文分析。
(2) 从右向左书写(RTL, Right-to-Left)
问题:阿拉伯语文本从右向左排列,但数字和部分外来词(如英文)仍从左向右,导致混合排版。
挑战:OCR引擎需动态调整识别方向,避免混淆。
(3) 相似字符易混淆
问题:多个字母仅靠点(Nuqat)的数量和位置区分,如:
ت(Ta) vs. ث(Tha)(两点 vs. 三点)
ج(Jeem) vs. ح(Hah) vs. خ(Khah)(形状相似,仅内部细节不同)
挑战:低分辨率图像或手写体易导致误识别。
(4) 变音符号(Diacritics)影响语义
问题:阿拉伯语使用短元音符号(如 َ、ِ、ُ)标注发音,但日常文本中常省略,导致歧义。
例如:كِتَاب(Kitab,书) vs. كَتَبَ(Kataba,他写了)
挑战:OCR需结合NLP进行语义消歧。
技术实现方案
(1) 深度学习模型优化
- CNN + LSTM/Transformer架构
- CNN(卷积神经网络):提取字符局部特征(如点、连笔)。
- LSTM/Transformer:处理序列依赖,适应RTL和连写规则。
- 代表模型:
- CRNN(CNN+RNN):传统方案,适合印刷体。
- SAR(Show, Attend and Read):基于注意力机制,提升手写体识别。
- 数据增强(Data Augmentation)
- 生成倾斜、模糊、噪声样本,提升模型鲁棒性。
- 使用GAN(生成对抗网络)合成多样手写体数据。
(2) 字符分割与上下文建模
- 连写字符分割(Segmentation-Free OCR)
- 不依赖单字符切割,直接对整个单词进行端到端识别(如Google的Tesseract 4.0+改进)。
- 语言模型(NLP后处理)
- 结合BERT阿拉伯语变体(如AraBERT)纠正拼写错误。
(3) 多方向文本检测
混合排版处理
- 使用EAST(Efficient and Accurate Scene Text Detector)检测文本方向,区分RTL和LTR内容。
(4) 变音符号恢复
Seq2Seq模型
- 训练模型自动补全省略的变音符号(类似机器翻译任务)。
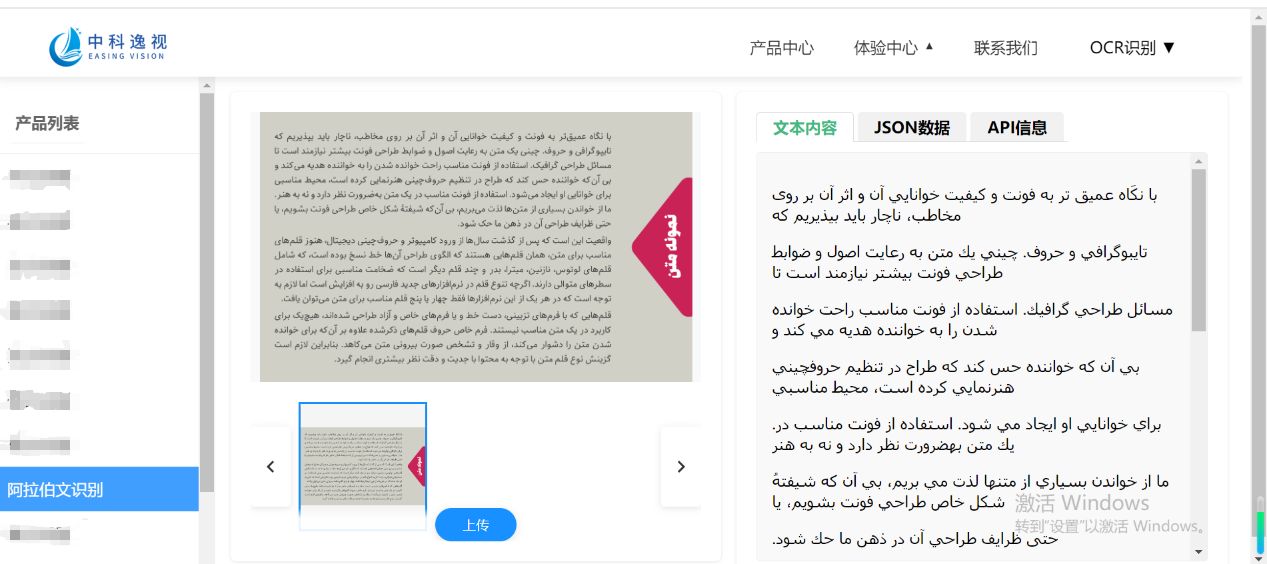
未来优化方向
- 少样本学习(Few-Shot Learning):降低对手写数据量的依赖。
- 多模态融合:结合语音输入辅助OCR(如用户朗读修正识别结果)。
- 边缘计算:轻量化模型,支持手机端离线识别。

















 2725
2725

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









