







大模型(LLM)是一种人工智能模型,旨在理解和生成人类语言。它们在大量的文本数据上进行训练,可以执行广泛的任务,包括文本总结、翻译、情感分析等等。LLM的特点是规模庞大,包含数十亿的参数,帮助它们学习语言数据中的复杂模式。这些模型通常基于深度学习架构,如转化器,这有助于它们在各种NLP任务上取得令人印象深刻的表现。
2022年底,OpenAI 推出的基于 GPT-3.5 的大型语言模型 ChatGPT,由于其优秀的表现,ChatGPT 及其背后的大型语言模型迅速成为人工智能领域的热门话题,吸引了广大科研人员和开发者的关注和参与。

本周精选了5篇LLM领域的优秀论文,为了方便大家阅读,只列出了论文标题、AMiner AI综述等信息,如果感兴趣可点击查看原文,PC端数据同步(收藏即可在PC端查看),每日新论文也可登录小程序查看。
如果想要对某篇论文进行深入对话,可以直接复制论文链接到浏览器上或者直达AMiner AI页面:
https://www.aminer.cn/chat/g/explain?f=cs
1.Crafting Interpretable Embeddings by Asking LLMs Questions
本文探讨了一种通过向大型语言模型(LLM)提问来生成可解释嵌入的方法。尽管LLM在自然语言处理任务中极大地改进了文本嵌入,但其不透明性以及对神经科学等科学领域的渗透,使得对可解释性的需求日益增长。本文提出,是否可以通过LLM提示获得可解释的嵌入。为此,我们引入了一种新的嵌入方法——问答嵌入(QA-Emb),其中每个特征代表了一个向LLM提出的是/否问题答案。训练QA-Emb实际上是通过选择一组底层问题而非学习模型权重来实现的。我们使用QA-Emb灵活地生成可解释模型,以预测语言刺激引起的fMRI体素反应。实验结果表明,QA-Emb显著超越了已知可解释基线,且所需问题数量非常少。这为构建灵活的特征空间铺平了道路,这些特征空间能够具体化和评估我们对语义大脑表示的理解。此外,我们还发现QA-Emb可以用一个有效的模型进行有效近似,并在简单的NLP任务中探索了更广泛的应用。
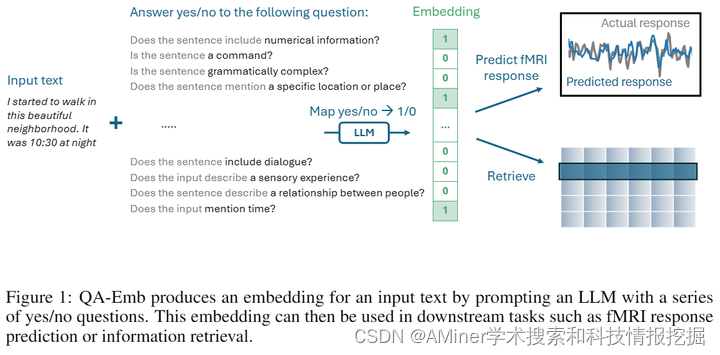
链接:https://www.aminer.cn/pub/66553aff01d2a3fbfc9fd022/?f=cs
2.A Survey of Multimodal Large Language Model from A Data-centric Perspective
这篇论文从以数据为中心的视角全面调查了多模态大型语言模型(MLLM)。人类通过视觉、嗅觉、听觉和触觉等多种感官感知世界,与此类似,多模态大型语言模型通过集成和处理来自文本、视觉、音频、视频和3D环境等多个模态的数据,增强了传统大型语言模型的能力。数据在开发和完善这些模型中起着关键作用。本文具体探讨了在MLLM的预训练和适应阶段准备多模态数据的方法,分析了数据集的评估方法,并回顾了评估MLLM的基准。此外,本文还概述了未来的研究方向。这项工作旨在为研究人员提供对MLLM的数据驱动方面的深入了解,促进在这个领域进一步探索和创新。
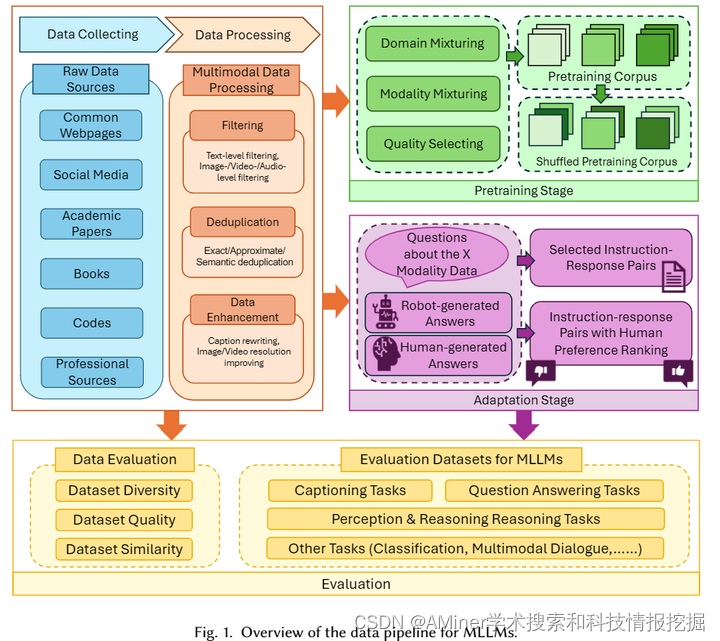
链接:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









