



大型推理模型(LRMs)的兴起标志着计算推理领域的范式转变。然而,这一进步也颠覆了传统的 Agent 框架,而这些框架传统上是由以执行为导向的大型语言模型(LLMs)所锚定的,深入理解LRMs在AI Agents中的作用势在必行。
ReAct范式下的整体性能表现。a) 不同任务和模型的性能表现;b) 效率和成本比较。

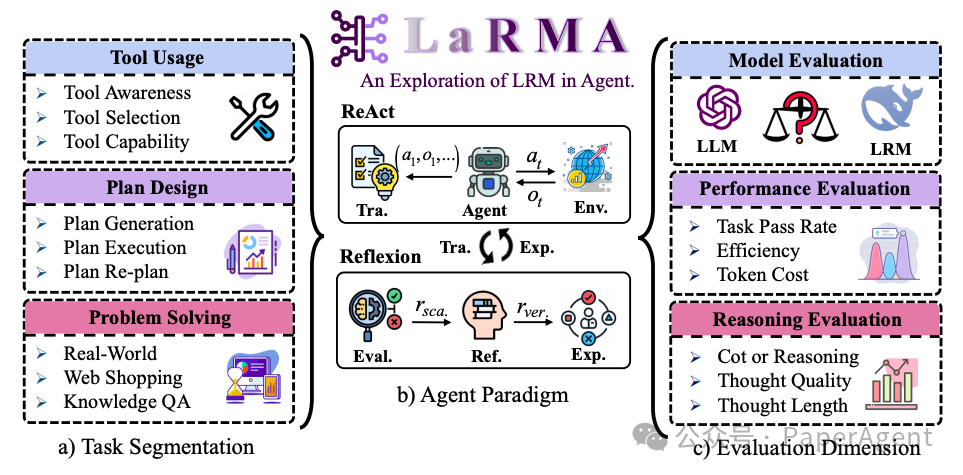
为了探索这一变革,提出了LaRMA框架,该框架涵盖了工具使用、计划设计和问题解决等九项任务,并使用三种顶级LLMs(例如Claude3.5-sonnet)和五种领先的LRMs(例如DeepSeek-R1、QWQ-32B-Preview)进行了评估,并得出了一些AI Agents设计的重要结论。
LaRMA框架分为三个阶段:
-
任务分割:将任务分解为工具使用、计划设计和问题解决三个维度,进一步细分为具体子任务,以探索推理需求。
-
范式选择:选择ReAct和Reflexion两种范式,分别考察实时交互和迭代反思对推理的影响。
-
性能评估:使用多种LLMs和LRMs,通过准确率、效率和成本等多维度指标评估推理的实际影响。
实验设置
-
LLMs:包括LLaMA3.1-70B、GPT-4o和Claude3.5-sonnet。
-
LRMs:包括DeepSeek-R1、Claude3.7-sonnet、Gemini-2.0-Flash、QWQ-32B-Preview和GLM-Zero。
-
数据集:使用METATOOL、API-Bank、PlanBench、ALFWorld、Web Shop和HotpotQA等数据集。
-
评估指标:准确率、效率(执行时间或交互步骤)和成本(计算资源消耗,如内存或功耗)。

关键结论
-
性能比较:
-
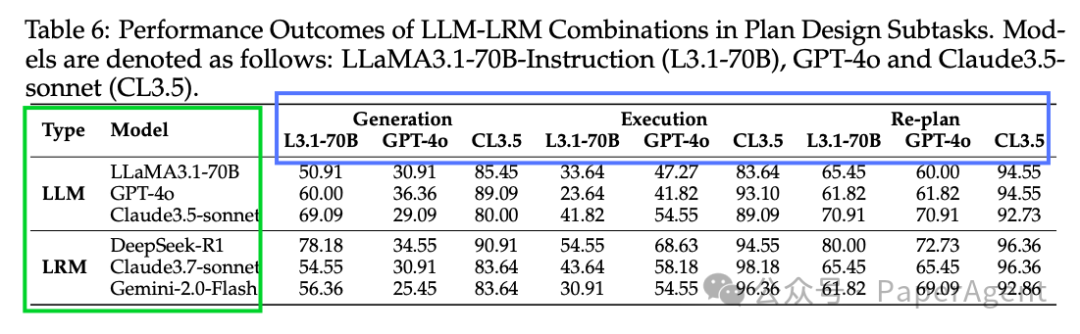
LRMs在推理密集型任务(如计划设计)中优于LLMs,准确率超过90%。
-
LLMs在执行驱动的任务(如工具使用)中表现更好,准确率较高。
-
混合配置:将LLMs作为执行组件,LRMs作为反思组件,可以优化性能,尤其是在复杂的推理任务中。
-


-
效率和成本:
-
LRMs在推理密集型任务中表现出更高的计算成本和更长的处理时间。
-
LLMs在执行驱动的任务中效率更高,成本更低。
-

-
推理过程的挑战:
-
过度思考:LRMs在简单任务中可能会过度思考,导致不必要的计算开销。
-
忽视事实:LRMs有时会忽视与外部环境的交互,依赖内部推理,可能导致决策失误。
-

-
混合架构的优势:
-
将LLMs的执行效率与LRMs的推理深度相结合,可以实现更优的Agent性能。
-



https://arxiv.org/pdf/2503.11074Large Reasoning Models in Agent Scenarios: Exploring the Necessity of Reasoning Capabilities

















 1477
1477

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









