



作者:姜富春
原文:https://zhuanlan.zhihu.com/p/14993645091
导语
LLM Post-Training过程中,会出现较多使用Reward Model的场景。那么LLM中Reward Model是什么?其实简单说就是按照人的偏好制定的一种奖励规则。比如在文创场景:
-
• 场景1:创作的内容越丰富,越有层次的结果认为是好结果,奖励分会高,相反奖励分就低。
-
• 场景2:创作的内容越通俗易懂越好,奖励分高,越阳春白雪越差,奖励分越低
所以从上面的场景可以看出,Reward Model是按业务自定义的规则做的偏好打分,有比较强的主观性。
当前Reward Model 有两种主流的范式:
-
• ORM(Outcome Reward Model): 在生成模型中,通常是对生成的结果整体做一个打分。
-
• PRM (Process Reward Model):在生成的过程,分步骤,对每一步进行打分,是更细粒度的奖励模型。在CloseAI推出O1之后,PRM逐渐成为业界研究的新宠 。
由于两种范式有较大的区别,本文只聚焦讲解ORM。(PRM后续会单独整理一文)
我们在了解RM的训练过程之前,先聊聊RM在LLM研发中到底有啥用?
1.LLM场景中RM的作用
在LLM研发范式中,RM的作用真的是大大地!毫不夸张地说,有了一个好的RM模型,你的业务才能起飞,形成真正的迭代的飞轮。
下面列举几个RM的使用场景,看看他的作用。
1.1. RLHF中的关键一环
当年openAI 还真的open的时候,让我们学会了RLHF的新研发范式,其中step2就是训练一个RM,如下图1所示。(paper链接[1]),有了RM后RLHF才能转起来。RLHF是训LLM的大杀器,随着LLM模型能力从一个文科生(GPT-4) -> 理科生(openAI O1)的演进,Reinforce Learning的角色越来越重要,RM又是RL中不可或缺的部分。

图1、OpenAI instructGPT RLHF架构图
1.2. 拒绝采样 + SFT
我们仔细看看真OpenAI(Mata)的Llama3.1的paper(paper地址[3])。post-training阶段的训练流程,如下图2所示。这是一个飞轮迭代的过程,Llama转了6轮。

图2、Llama3 post-training 框图
我们来看看Llama做Post-training的飞轮过程:
1.持续通过人工标注或机造方式富集偏好pair样本,训练Reward Model
2.基于当前能力最好的模型,随机采集一批,每个Prompt拿最好的模型做 次数据生成采样,每个Prompt就得到条 数据
3.拒绝采样:对第2步采样 个数据,用Reward Model打分,并从中选取打分最高 topN 条样本。作为指令微调的精选样本,训练SFT Model。
4.训完SFT Model,再通过持续收集的偏好对样本(同步骤1)做对齐学习(Llama使用的是DPO)。最终得到了一个比当前模型更好的模型
5.持续做步骤1~步骤4,飞轮迭代优化模型。
拒绝采样是我们自动化做样本工程的非常重要方法,这里面Reward Model 是最关键的角色。
我个人理解,拒绝采样也是一种对齐学习的方法,本质上跟PPO和DPO发挥的作用是一样的,只是一个是直接在SFT阶段做对齐,一个是在SFT后做对齐。
1.3. 业务场景的Verifier
我们总说LLM在应用场景落地时,会有幻觉问题、有安全控制等问题,当然这些能力都能在训练中模型优化。但总有些恶意攻击者,或总有些不经意的场景会突破模型的能力范畴,模型会给出智障的回答。在这种场景下,模型后面可以接一个判别器(Verifier),对结果做个校验,满足判别阈值之上的结果才输出,不满足判别条件的做再生成或兜底降级处理。Reward Model就是就可以充当这个判别器的角色,可以对LLM的结果做一层校验控制,以输出更可靠的结果,如图3所示。(当然也有Reward Model失控的场景,这属于Reward Hacking范畴,这是一个比较深刻的话题,本人当前涉及比较浅薄,暂不讨论这块)

图3、业务落地Reward Model作为判别器控制生成结果
相信通过上面的介绍,我们了解了Reward Model,也意识到了Reward Model的重要性。我们可以结合自己的场景,好好想想、也该好好搞搞Reward Model吧。标注样本的时候想想Reward Model的样本怎么采集、怎么标注,别一股脑上来就是SFT,到项目干完还是SFT,完全飞轮不起来。(才思泉涌,说跑偏了......)
我们回到正题~
本文接下来主要基于OpenRLHF源码,详细讲解下ORM(Outcome Reward Model)的训练过程。(注:为方便阅读,本文后面统一将ORM称为Reward Model, 简写RM)
2.源码解读Reward Model训练过程
RM训练的入口函数详见:train_rm.py。接下来我从样本、数据处理、模型结构、loss几个方面详细讲解下RM的训练过程
2.1. 样本数据
训Reward Model的样本数据一般是一个pairwise的训练数据。典型的样本格式是个三元组
一条question样本,带着两个answer,一条正例、一条负例。对于生成模型的RM的样本,通常会对这个三元组称做
也可以表述成另一种二元组的形式:
把prompt 拼接上每个回答,构成一个完整的问答对,pair前一项 prompt + chosen 表示一个好的问答对;后一项 表示一个差的问答对。
本文以huggingface的一个Reward样本数据为例(地址:preference_dataset_mixture2_and_safe_pku[4]),看下具体的样本格式。如下图:
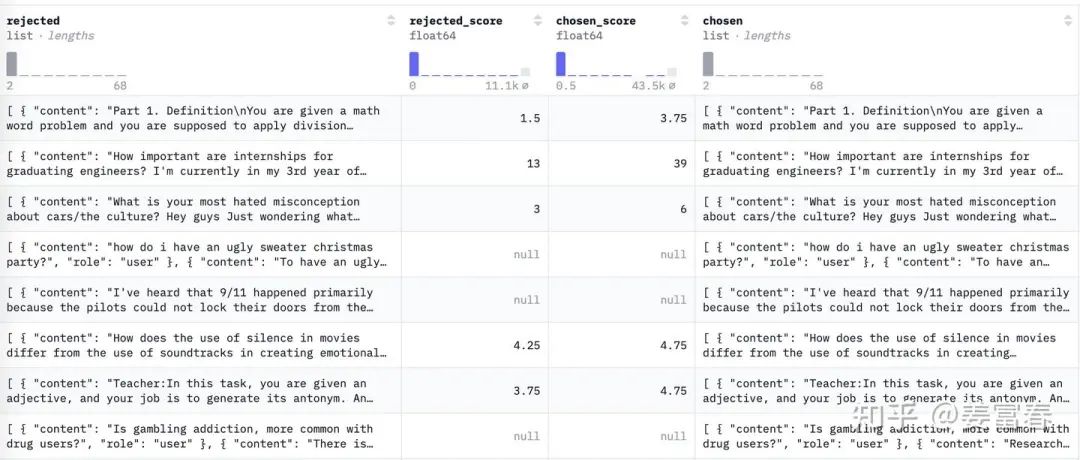
图4、偏好样本数据图例
数据共有四列,除了上面描述的 chosen 和 rejected 两列(这两列是拼接了prompt的格式),还有两列chosen_score 和 rejected_score,表示样本的置信度,可以按该打分的绝对值和差值做些样本筛选处理。
我们展开一条样本看下:

图5、一条偏好pair样本
上面这条样本是个chat格式的,这是NLP领域处理会话任务的一种较通用的格式。上面一条样本中chosen 和 rejected内部都有两轮对话。每条对话有角色(role)和内容(content)两部分组成。在该样本中,user角色的会话相当于prompt,assistant角色的会话相当于模型生成的结果。
注:
1. 上面的样本格式是处理成公式(3)表述的二元组的格式,chosen 和 rejected 都拼接了一样的prompt。
2. 这种样本格式只是一种for对话场景的一种特殊格式。可根据业务场景灵活处理成格式不一样<chosen,rejected> pair。
下面我们来看看对这样的明文的样本数据,如何转成训练数据feed给模型的。
2.2. 数据处理
我们知道最终喂给生成模型的数据是扁平的字符串做tokenizer处理后的token_id序列,那如何从上面的json格式的对话数据,转成扁平的字符串。可能我们自然的会想到用json.dumps()处理成字符串。但json里面有大量的『转义双引号』。对于模型学习,这些格式化分割符都是影响会话连贯的噪声。
为了把chat格式数据转成扁平字符串格式,huggingface在Tokenizer类中提供了一个通用的转换方法,如下方法所示。详见:huggingface chat_templating文档[5]
tokenizer.apply_chat_template(chat, tokenize=False)
通过上面方法操作,会对会话数据加上特殊的token标记来扁平化处理好样本数据。在去掉结构化的同时,保留样本的可读性。以上面图5的样本中的chosen部分为例,处理前后的样本格式,如下图6所示:
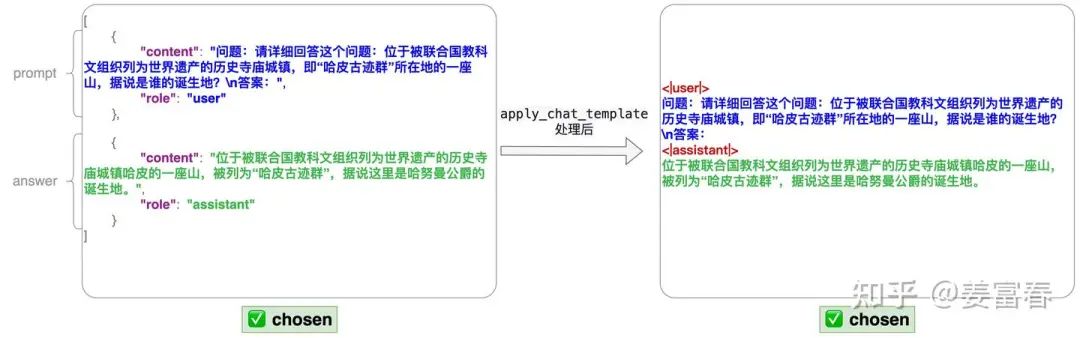
图6、chat_templating处理数据过程
从图中我们可以看到,对于结构化的数据,通过增加<|user|> 、<|assistant|> 特殊token来标记会话,将数据扁平化。
注:这里的<|user|> 、<|assistant|>是能根据自己的业务需求定制化开发的,不是固定不变的token,详见官方文档[6]。
源码中数据处理的核心逻辑封装在RewardDataset中,详见:reward_dataset.py[7]。样本数据处理逻辑比较清晰,我们图示化出处理过程,如图7所示。
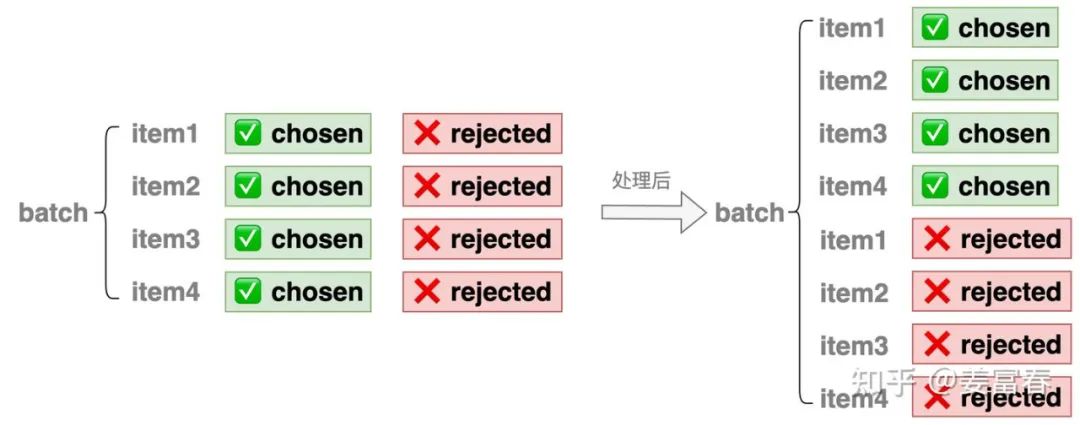
图7、数据做转置处理
数据处理过程中,将一个 的样本除了做chat_templating、token化等处理。还把每条样本的chosen 和 rejected部分拆开,变成两条样本,最终组成了一个 长度的样本,并且所有的chosen样本排在前 行,所有的rejected样本排在后 行。
至此我们理解了Reward Model样本处理的过程。接下来就是模型训练了。我们先看下RewardModel的模型结构。
2.3. Reward 模型结构
模型结构就是生成模型(LLM)之上,加了一个regression head,然后获取每条样本的最后token(eos)位置的打分作为该条样本的整体得分,如图8所示。
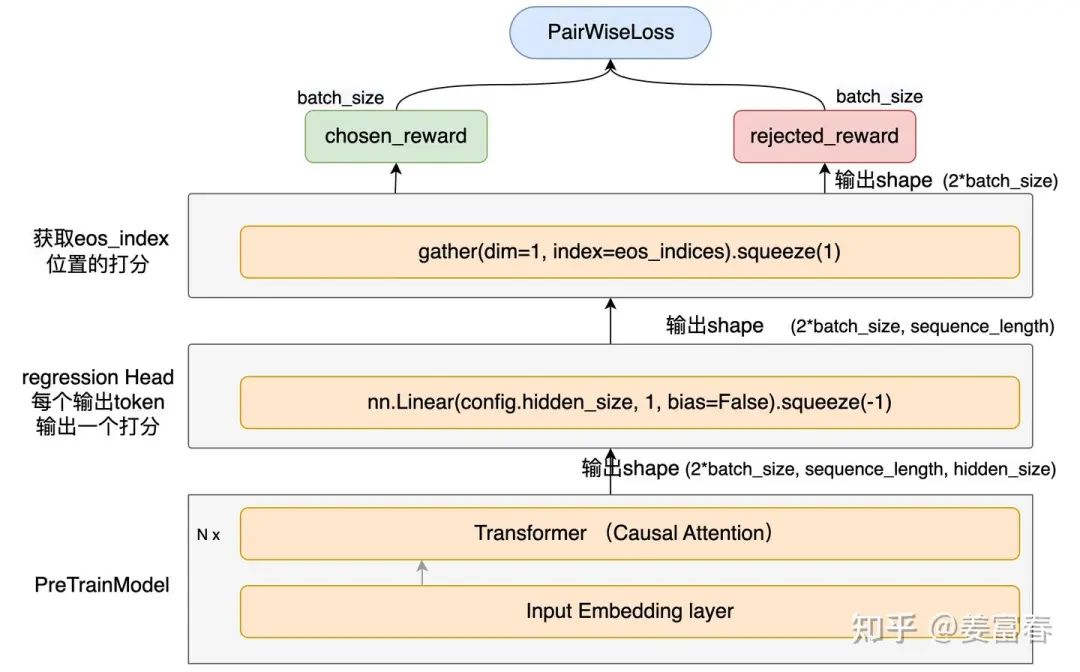
图8、Reward 模型结果
还记得我们上面处理样本,如图7所示,前Batch条chosen样本,后Batch条rejected样本,所以模型预估输出打分后,又对前后两半数据做了分片处理,抽取出chosen_rewards和rejected_rewards。如下操作:
# 源码: https://github.com/OpenRLHF/OpenRLHF/blob/main/openrlhf/trainer/rm_trainer.py#L355C5-L355C45
def packed_samples_forward(self, model, ...)
all_values = model(...)
################
# 参考图7数据处理的过程,就理解下面的操作了~
################
half_len = len(packed_seq_lens) // 2
chosen_rewards = all_values[:half_len]
rejected_rewards = all_values[half_len:]
接下来我们再看看有个chosen_rewards和rejected_rewards后的loss计算过程。
2.4. Loss 函数
源码中提供了两种loss,分别是PairWiseLoss和LogExpLoss,具体实现如下:
class PairWiseLoss(nn.Module):
'''
Pairwise Loss for Reward Model
'''
def forward(self, chosen_reward, reject_reward, margin):
if margin is not None:
loss = -F.logsigmoid(chosen_reward - reject_reward - margin)
else:
loss = -F.logsigmoid(chosen_reward - reject_reward)
return loss.mean()
classLogExpLoss(nn.Module):
'''
Pairwise Loss for Reward Model
Details: https://arxiv.org/abs/2204.05862
'''
def forward(self, chosen_reward, reject_reward, margin):
loss = torch.log(1 + torch.exp(reject_reward - chosen_reward)).mean()
return loss
乍一看两个loss完全不一样,但单简推导下,其实是一个东西,如下推导:
我们再看下PairWiseLoss的曲线图,如图9所示。当 时loss急剧上升,表示正例样本的得分小于负例样本的得分,产出较大的loss, 回传产生较大梯度更新模型。当 基本趋近于0,表示正例得分大于负例的得分是合理的,不产生loss。我们也可以看到PairWiseLoss有个良好的属性:自带margin效果。 因为在0附近也会产生一定的loss,来更新模型,拉大正负例的差距。
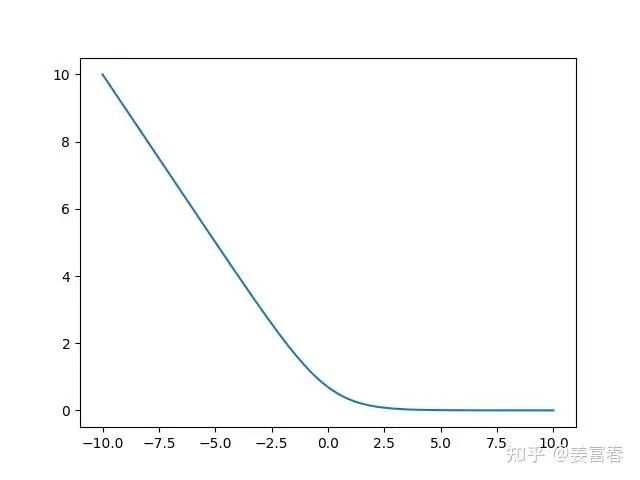
图9、PairWiseLoss函数曲线图
至此,我们基于OpenRLHF源码,完整描述了Reward Model训练过程。回头看看,其实Reward Model训练就是传统的机器学习PairWise训练过程。搞清楚Reward Model的正负样本数据和格式,无他~
3.总结
本文描述了ORM (Outcome Reward Model)的定义和作用。并基于OpenRLHF源码详细解读了ORM的训练过程。在RM的研发范式中,还有最近比较火热的PRM(Process Reward Model)。
引用链接
[1] paper链接:https://arxiv.org/pdf/2203.02155
[2]姜富春:OpenRLHF源码解读:1.理解PPO单机训练:https://zhuanlan.zhihu.com/p/13043187674
[3]paper地址:https://arxiv.org/pdf/2407.21783
[4]preference_dataset_mixture2_and_safe_pku:https://huggingface.co/datasets/weqweasdas/preference_dataset_mixture2_and_safe_pku
[5]huggingface chat_templating文档:https://huggingface.co/docs/transformers/main/chat_templating
[6]官方文档:https://huggingface.co/docs/transformers/main/chat_templating

















 813
813

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









