




作者丨Taki@知乎
来源丨https://zhuanlan.zhihu.com/p/704761512
编辑丨极市平台
导读
在传统的 LoRA 中加入一个 Mixer 矩阵,进行混个不同子空间的信息。
Nothing will work unless you do. --Maya Angelou
本文主要介绍一篇论文是怎么诞生。
文章的基本信息是:
标题:Mixture-of-Subspaces in Low-Rank Adaptation
链接:
https://arxiv.org/pdf/2406.11909
代码:
https://github.com/wutaiqiang/MoSLoRA
简介:在传统的 LoRA 中加入一个 Mixer 矩阵,进行混个不同子空间的信息。设计非常简单:
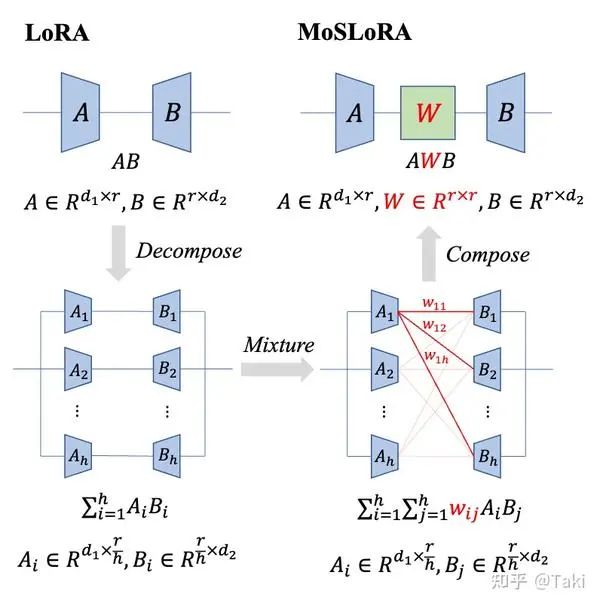
最初的想法
说来也是巧合,之前有很多的文章尝试将 LoRA 和 MoE 结合起来,他们基本上都是把 LoRA 当做 MoE 的 Expert,然后塞到 MoE 结构之中,之前也介绍过一些,如文章 https://zhuanlan.zhihu.com/p/676782109、 https://zhuanlan.zhihu.com/p/676557458、 https://zhuanlan.zhihu.com/p/676268097、https://zhuanlan.zhihu.com/p/675186369。这些文章无疑都是将 LoRA 看作 MoE 的 expert,一来缺乏动机,二来影响了 LoRA 的可合并性,三来 训练还慢。
闲来与同事聊天,同事说没见过有文章把 MoE 塞到 LoRA 里面,我当时愣了一下。啊?MoE 塞到 LoRA 里面,意思是说把 MoE 的那种 gate+多专家去做 LoRA 的 lora_A 和 lora_B ?
最直观的设计就是:
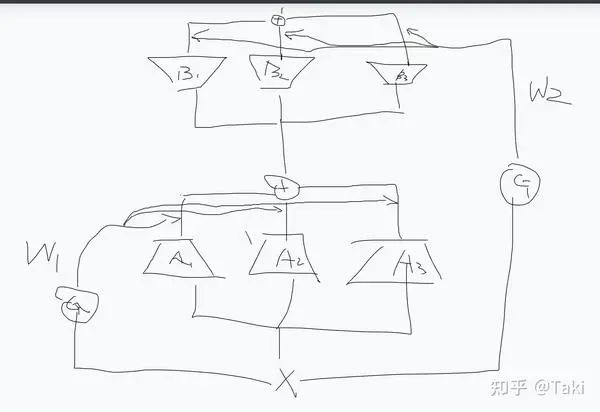
有点抽象,但稍微知道点 MoE 和 LoRA 的应该都能懂
其实想出这种设计还是很直接的,毕竟 lora 和 MoE 都是很成熟,很简单的设计。
先不谈有没有动机,反正水文章嘛,都能找到点。就说这个设计,其实有点不合适,为什么呢?
核心就在于 Gate 这玩意,MoE 是希望尽可能训多
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2217
2217

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









