







 这篇博客详细介绍了如何在CentOS 7系统上安装配置Hadoop伪分布环境,包括虚拟机安装、CentOS系统配置、SSH无密码登录、Java环境配置以及Hadoop0.20.0的安装步骤。作者分享了安装过程中的注意事项和配置细节,适合初学者参考。
这篇博客详细介绍了如何在CentOS 7系统上安装配置Hadoop伪分布环境,包括虚拟机安装、CentOS系统配置、SSH无密码登录、Java环境配置以及Hadoop0.20.0的安装步骤。作者分享了安装过程中的注意事项和配置细节,适合初学者参考。
目录
零、前言
(一)、前言
最近在做wikipedia的东西,需要大规模处理数据,因此就需要使用hadoop工具操作。一开始想安装的linux版本是ubuntu 14和hadoop 2.x版本,但是安装完成后发现操作wiki的jar包要比较老版本的hadoop,最终选择了使用较多的CentOS 7版本的linux系统和hadoop 0.20.0版本。java环境配置的jdk1.7,自从jdk更新为jdk和jar合并以后,很多地方都不太适应,1.8版本又怕不契合最终选择jdk 1.7安装。
由于每个linux系统操作不太一样,所以要看安装要版本对应。不同hadoop版本的前部分安装大同小异,一直到第五部分的(一)步骤都是一样的,可以进行些参考。有一些步骤是我认为方便后续操作的,觉得麻烦可以忽略,因为这段时间配置过了很多遍,会写的比较详细,尽量做到傻瓜操作。强调一下:本文配置的是伪分布模式!伪分布!伪分布!。不说废话了,进入正题。
(二)、所需软件安装包、压缩包及下载地址
1. VMware Workstation 14(虚拟机软件):链接:https://pan.baidu.com/s/1auDLNGooMD4khVcyLfwBBQ 提取码:4trs
2. JDK 1.7 linux x64版:链接:https://pan.baidu.com/s/1r0fT27FrEmECjePIOvOiJg 提取码:qg32
3. Hadoop 0.20.0 版本 :链接:https://pan.baidu.com/s/1-wkxdhXaOAFTkncp2dlWig 提取码:8lcs
4. Linux系统安装镜像CentOS 7(清华):http://mirrors.tuna.tsinghua.edu.cn/centos/7.6.1810/isos/x86_64/CentOS-7-x86_64-DVD-1810.iso(同时吐槽一下百度云吃相越来越难看,不是会员大于4g的文件不能上传!)
一、虚拟机安装及CentOS系统配置
(一)、VMware虚拟机软件安装(其实这里没什么好说的就是普通的软件安装)
1.下载完成之后解压
2.打开解压后的文件中就是安装包

3.打开上图显示的exe文件进行安装,注意路径这里尽量不要装在C盘就OK。
(二)、CentOS系统安装
1. 打开VMware,点击“创建新的虚拟机按钮”:

2. 选择需要安装的系统镜像文件(以下开始没有提及的位置都可以直接按“确定”或“下一步”)

3. 确定安装名称及虚拟机安装位置(虚拟机名称会在安装后显示在左侧信息栏。安装位置选择尽量不要在C盘,且目标盘空间需要足够大。)(没有提到的操作可以直接按“确定”或“下一步”)

4. 磁盘大小确定(由于在hadoop中运行的一般都是超大型文件,因此尽量在第一次安装虚拟机时就将磁盘设置足够大,这里我设置80G,且设置为单个文件。是因为可能后续操作中一个文件就有几十G,如果分区可能无法装入。注意:一旦后续空间不足,追加磁盘操作比较复杂且很容易出错误)(没有提到的操作可以直接按“确定”或“下一步”)

5.点击“完成”,就相当于你有了一台电脑。然后开始安装电脑的系统——CentOS。

6.上一步点击“完成”后,虚拟机开启,安装系统。点击虚拟机界面进入操作,“↑”和“↓”用于选择,这里选择“Install CentOS 7”。

7. 选择语言,选择自己喜欢的。。。我就选汉语了。这一步就不放图片了。
8. 语言选择后,自动进入“安装信息摘要”界面,需要选择安装模式,默认安装只有命令行模式,没有图形化界面。这里点击“安装选择”按钮,点开后先在左侧栏选择“GNOME桌面”,右侧所有条目打勾。(其他标有感叹号的打开点击确定就可以了)


9. 点击开始安装后,开始安装系统。此时可以设置linux系统的root用户密码(root用户即系统的超级管理员),点击感叹号那个图标开始设置。

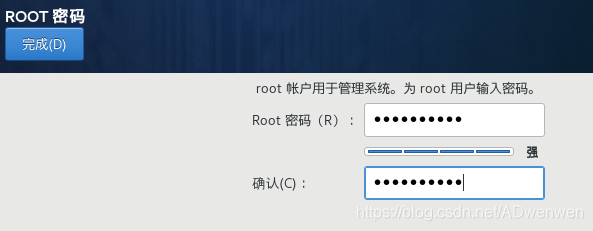
打开密码设置页面如下,注意这个密码需要牢记(记为密码A)。root账户密码设置完毕后。点击完成等待系统安装完毕即可。返回安装界面另一个感叹号会自动消失。不用再设置。
10. 系统安装完成后配置
系统安装完后会需要点击重启,重启后进入系统还有一些小配置,如确定协议、时区选择等等。这里比较重要的是会需要设置用户名和密码,这里的用户名是之后开机时的用户名,这里密码也就是开机需要输入的密码(记为密码B)。之后就开始开始应用该系统了。
这里简单记一下啊,开机用密码B,在命令行中使用root权限用密码A。之后建立hadoop用户并设置密码后全用密码C。
二、CentOS系统及网络配置
(一)、上网设置及静态IP配置
本身安装hadoop环境就需要静态IP的配置,而安装完成这个版本的CentOS7后发现不能上网,所以这两个问题一起解决。
1. 首先,在桌面右键打开命令窗口(打开终端),cd到网络配置目录下,找到网络配置文件
$ cd /etc/sysconfig/network-scripts
$ ls运行结果如下:

2. 设置虚拟机网络连接方式
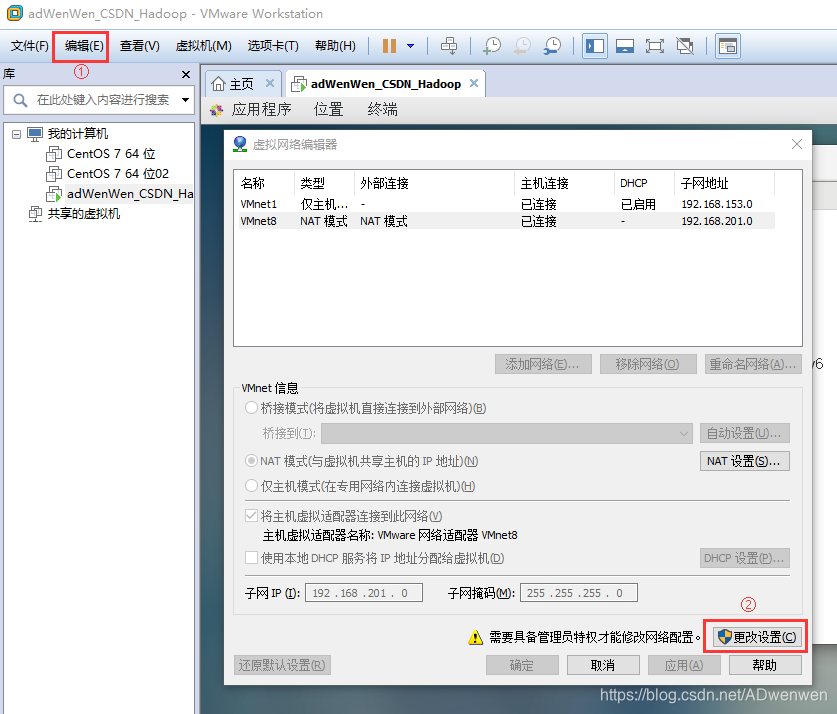
在虚拟机软件界面左上角,选择“编辑”(图中①位置)→“虚拟网络编辑器”。打开后将右下角的更改设置(图中②)的权限打开,鼠标左键再确定就好。
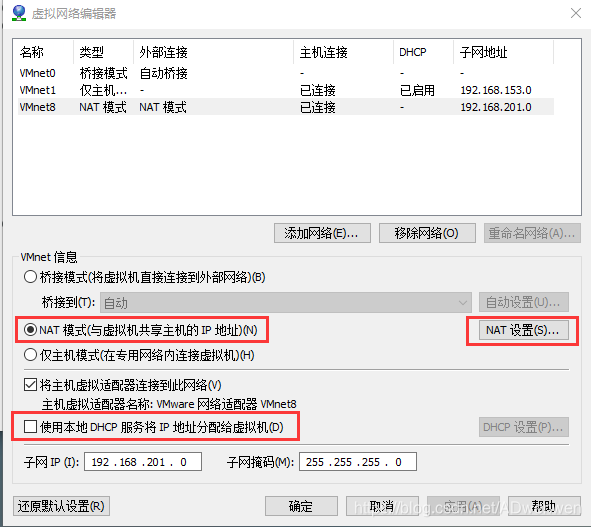
设置VMnet8网络,①.选择NAT模式,②.不再勾选“使用DHCP服务将IP地址分配给虚拟机”这个选项,③.打开NAT设置选项。
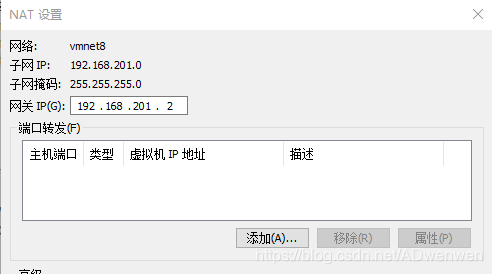
在NAT设置中主要记住网关就可以了,如下图“192.168.201.2”。
3. 回到系统命令终端中,打开编辑名为ifcfg-ens33的文件。可能需要root权限,输入如下命令后,再输入密码进行文件编辑
$ sudo vim ifcfg-ens33按“i”键对文件进行插入操作,将其中改为如下内容:
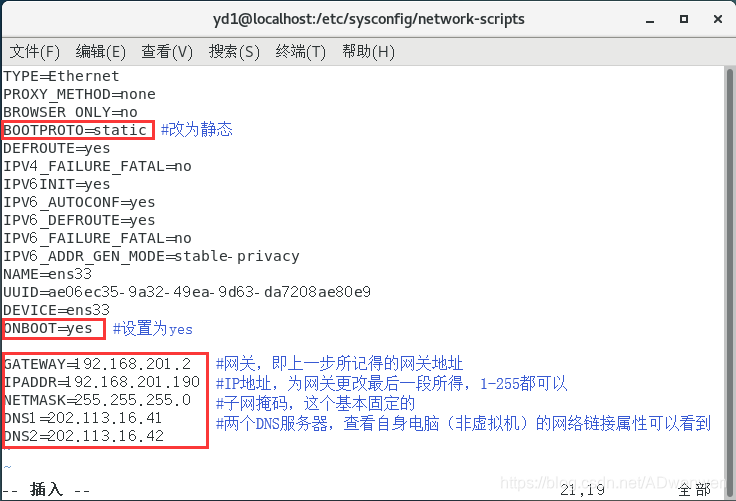
填写完成后,退出编辑器的命令是:先按一下“esc”键,退出编辑状态,再按住“shift”键按“z”键两下,退回命令终端
4. 重启网络服务,输入密码后测试,ping一下百度。(由于linux中ping不会停止,按住Ctrl+z进行停止)。出现如下说明网络连接没有问题了。
$ sudo service network restart
$ ping www.baidu.com
5. 更改hosts
在③我们已经将虚拟机的ip改为静态ip,因此为了后续方便,将ip与localhost联系起来。编辑hosts的方式与之前编辑ifcfg-ens33文件的方式类似:
$ sudo vim /etc/hosts在打开的hosts中添加一行,192.168.201.190 localhost,结果如下:

(二)、hadoop用户组创建
1. 获得root权限;创建hadoop用户;设置用户密码;分配用户组。注意一下,这个密码我们记成密码C,密码C是hadoop用户的登录密码,也是在hadoop用户使用sudo命令时的密码(之后全用密码C)。
$ su
$ useradd -m hadoop -s /bin/bash
$ passwd hadoop
$ usermod -a -G hadoop hadoop2. 更改权限(由于前面已经获取root权限,这里的sudo可以省略)
$ sudo vim /etc/sudoers找到root ALL=(ALL) ALL,按“i”进入插入状态,在其下添加hadoop ALL=(ALL) ALL,退出时操作为:先按“esc”退出插入状态,然后打一个冒号“:”,之后输入“wq!”三个字符,按回车即可修改成功。
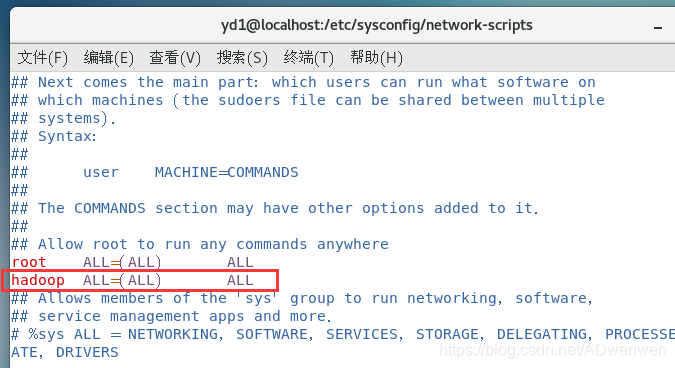
3. 切换用户并重启系统更换用户(第二句为重启命令)
重启后使用hadoop用户登录!
$ su hadoop
$ sudo reboot (三)、快捷键及屏幕锁定设置(可以跳过)
重启后,使用hadoop用户登录。此时为了以后方便,可以进行一些简单的设置。如果不需要这步是完全可以跳过的。
1. 设置终端快捷键
之前Ubuntu是有默认的打开终端快捷键的,即“Ctrl+alt+t”。而CentOS系统是没有的,我们可以自己设置。
①. 首先打开系统设置
②. 选择“设备”→“Keyboard”→右侧信息栏拉到最底部
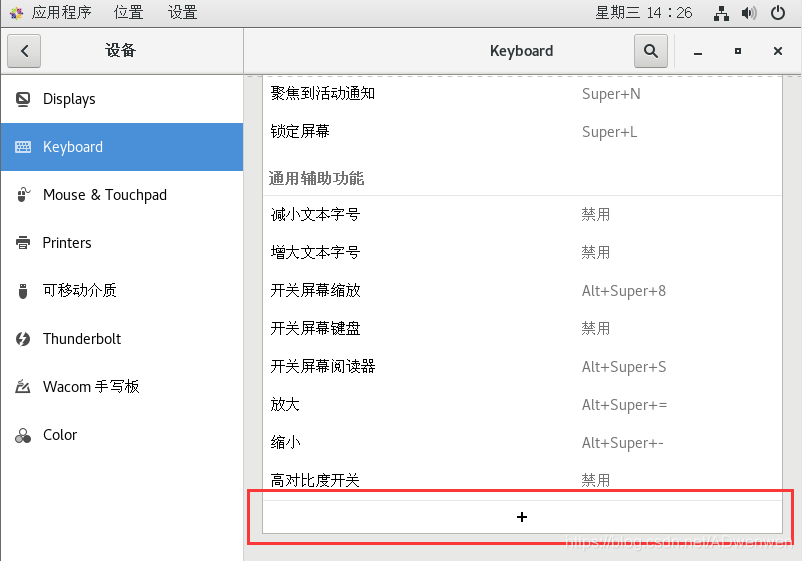
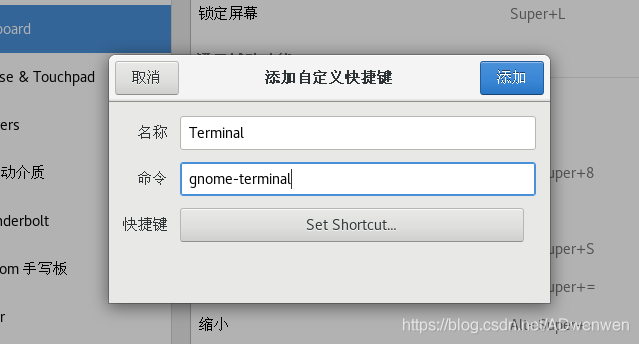
③. 点击右侧“+”按钮,按如下进行输入,其中名称可以随意输入,命令栏是固定的,快捷键点击“Set Shortcut...”按钮后,按照自己的喜好就可以。我这里设置的是“Ctrl+alt+t”。设置好之后点击添加即可。
2. 关闭屏幕锁定
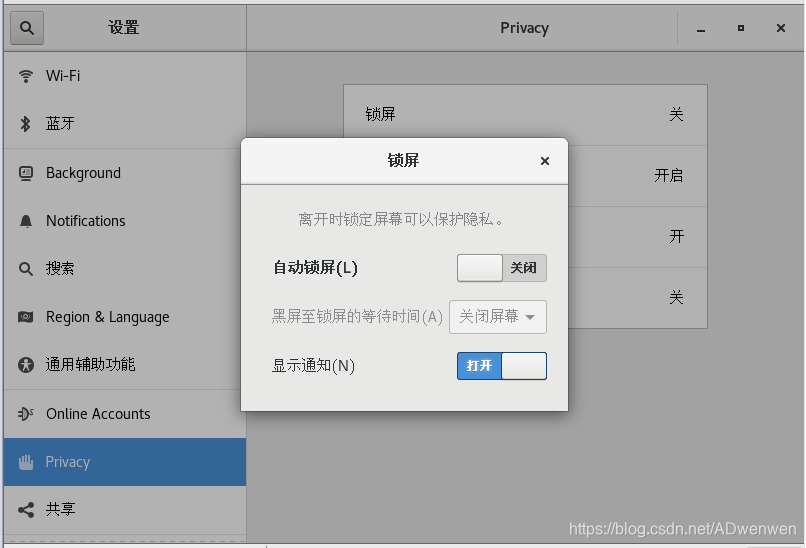
这个是由于默认的锁屏时间很短。因此直接关掉了。也是在设置中,找到“privacy”,右侧的锁屏打开,关掉自动锁屏即可。
三、SSH无密码登录
(一)、登录
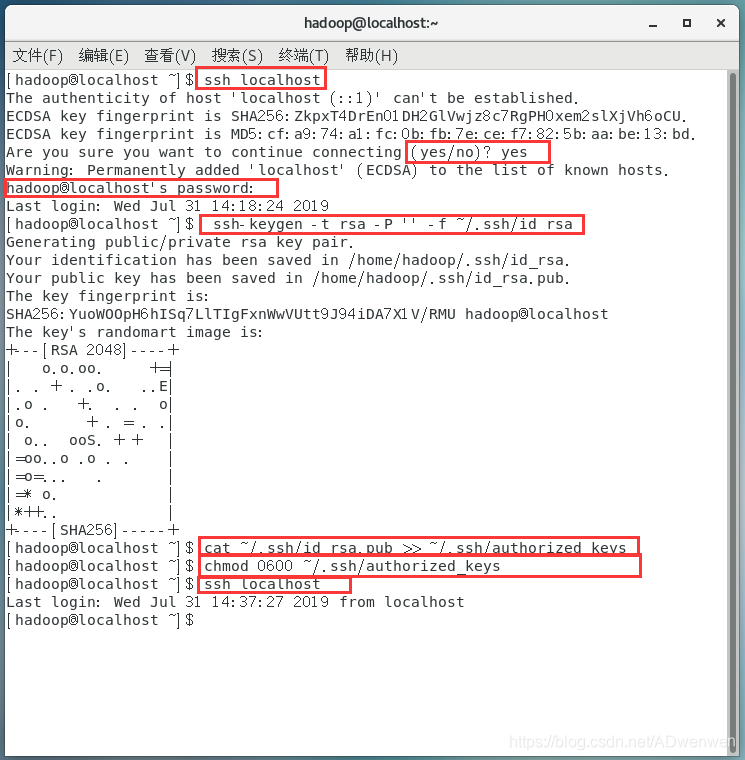
尝试ssh登录(需要输入yes 的地方输入yes即可)
$ ssh localhost(二)、设置无密码登录
若第一步需要密码,则需要设置无密码登录,连续输入如下三条命令(原理我也不是很懂,就不解释了):
$ ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
$ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
$ chmod 0600 ~/.ssh/authorized_keys(三)、验证无密码登录
之后再次尝试ssh登录
$ ssh localhost如果不再需要密码则表示设置无密码登录成功,整个过程图如下:
四、Java安装及环境配置
终于开始正题之一了,由于hadoop是用java写的,所以java环境的配置是极其重要的。
(一)、卸载预装OpenJDK
这个系统本身自带了很多个openJdk环境,因此为了不影响后续的hadoop安装最好将其卸载。经过我多次的安装,卸载预装OpenJDK即可以在装jdk1.7之前,也可以在装jdk1.7之后。我比较习惯之前,所以各位怕关联软件被卸载的话可以装好新的jdk1.7之后再卸载。
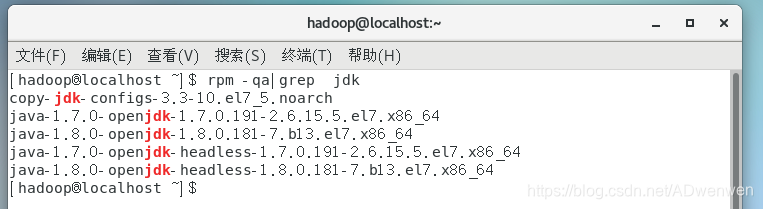
1. 查询预装情况(也可以将jdk改为java)
$ rpm -qa|grep jdk结果如下:
2. 卸载
这里卸载使用yum命令,由于需要root权限,因此命令如下:
sudo yum -y remove java java-1.7.0-openjdk-1.7.0.191-2.6.15.5.el7.x86_64交替使用上面查询、卸载这两个命令,只需要更改最后的文件名。将其他的openjdk卸载掉,直至全部卸载。
(二)、JDK1.7安装
1. 这里的安装过程就是解压的过程,首先将jdk压缩包复制至虚拟机中(这里所用的版本都可以直接复制),我们把jdk 的压缩包复制至文档目录下
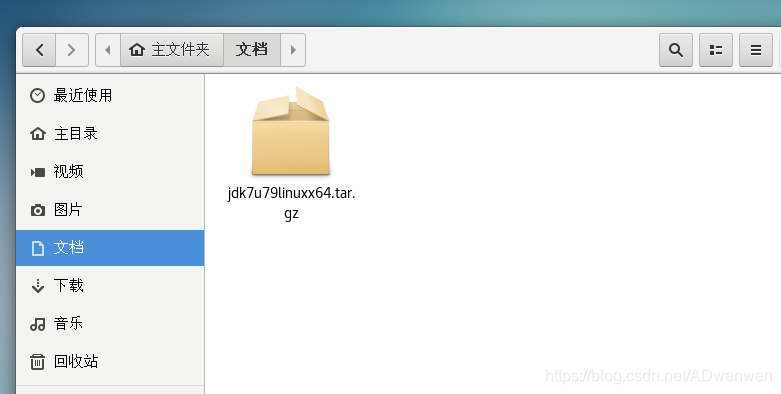
2. 解压。在文档目录界面右键,打开终端。进行如下第一条命令即可解压。解压之后出现一个文件夹。第二条命令是,对出现的文件夹赋予操作权限(为了保证后续操作)。
$ tar -zxvf jdk7u79linuxx64.tar.gz
$ sudo chmod -R 777 jdk1.7.0_79 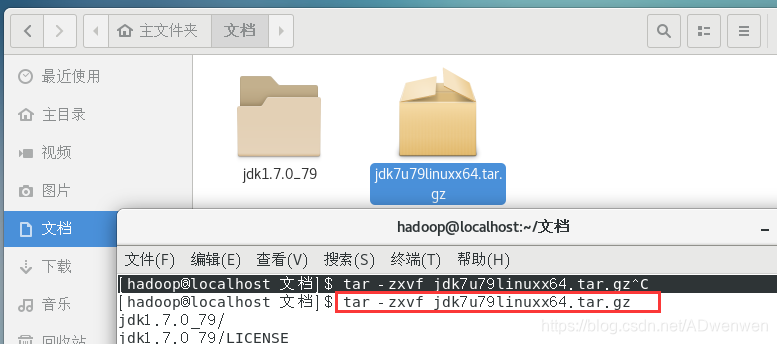
3. 移动。将解压得的jdk文件夹移动至/usr/local/目录下的java文件夹。执行完该步骤之后我们可以依次打开磁盘根目录下usr文件夹、local文件夹,即可找到java文件夹。
$ sudo mv jdk1.7.0_79 /usr/local/java(三)、java环境变量设置
对于Java环境变量的安装,基本同Windows下类似。只是操作方法同上面改变配置文件的操作相同。
1. 打开环境变量配置文件
$ sudo vim /etc/profile2. 在文本末尾添加如下字符(注:jdk12开始jdk和jar合并了,不再像下面这样配置环境变量。):
#JAVA
export JAVA_HOME=/usr/local/java
export CLASSPATH=.:$JAVA_HOME/lib:$JAVA_HOME/jar/lib
export PATH=$PATH:$JAVA_HOME/bin:$JAVA_HOME/jar/bin

3.退出后,输入如下命令使环境变量更改生效:
$ source /etc/profile4. 验证java安装完成:输入如下命令,若出现jdk版本为1.7.0则表示java安装配置完成:
$ java -version 
五、Hadoop0.20.0伪分布环境安装
(一)、Hadoop安装
hadoop安装与java安装基本流程是一样的
1. 将文件复制至文档文件夹下。(尽量在电脑上下好后复制,再在虚拟机内粘贴。或者直接在虚拟机内下载,直接拖拽容易损坏)。
2. 解压并改变权限
$ tar -zxvf hadoop-0.20.0.tar.gz
$ sudu chmod -R 777 hadoop-0.20.0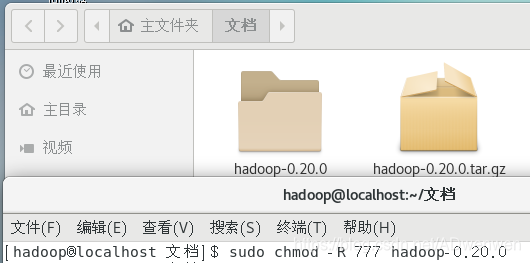
3. 移动至local文件夹下。执行完命令后可以看到,在local文件夹下有java和hadoop两个文件夹。
$ sudo mv hadoop-0.20.0 /usr/local/hadoop 
(二)、hadoop环境变量设置
hadoop的环境变量也和java的环境变量设置基本类似,以后熟悉了可以这两个一起进行。
1. 打开环境变量配置文件
$ sudo vim /etc/profile2. 在末尾添加如下内容
#HADOOP
export HADOOP_HOME=/usr/local/hadoop
export PATH=$PATH:$HADOOP_HOME/bin3. 刷新环境变量配置,使更改生效
$ source /etc/profile(三)、伪分布文件配置
hadoop的配置有三种,单机模式、伪分布模式和完全分布模式。这三种配置的主要不同就是在这一步,对不同配置文件的配置不同,我们这里进行的是伪分布的配置。
我们打开hadoop安装目录下的conf文件夹,这个文件夹内容如下,配置文件有下面图中四个,我们依照图中标记的顺序进行配置。
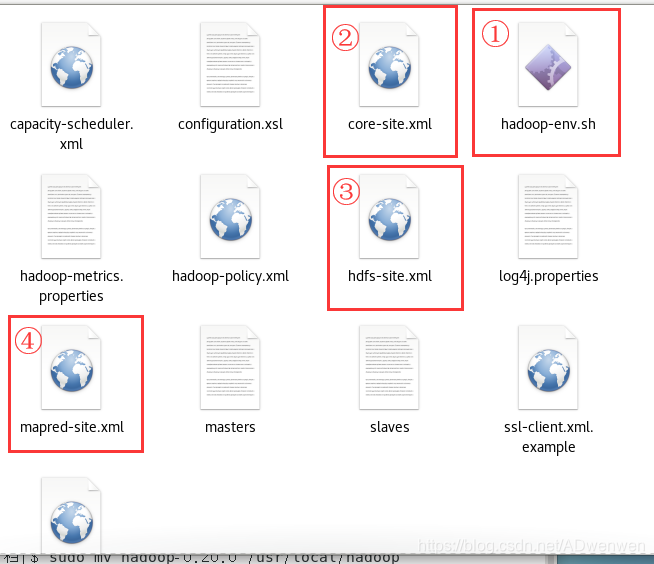
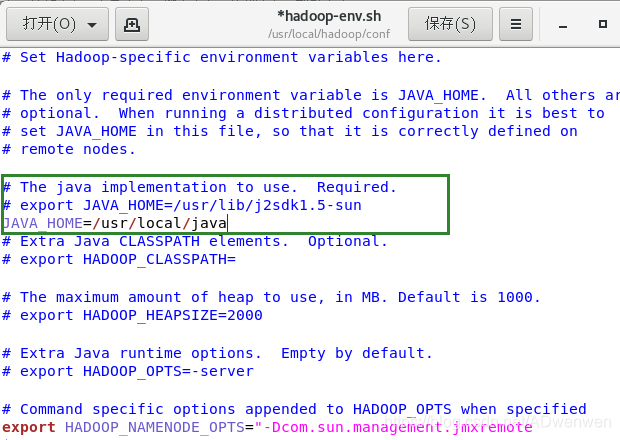
1. 配置hadoop-env.sh文件
打开该文件,这个文件的配置只需要填写java的路径,我们在对应位置输入JAVA_HOME=/usr/local/java,即下图绿框即可。
2. 配置core-site.xml文件
打开改文件采用右键→用其他方式打开→选择gedit。这是由于xml文件默认用的是浏览器打开,无法编辑。
将内容添加如下:
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
3. 配置hdfs-site.xml文件
打开方式如上,添加内容如下:
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.name.dir</name>
<value>/usr/local/hadoop/tmp/name</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>/usr/local/hadoop/tmp/data</value>
</property>
</configuration>
4. 配置mapred-site.xml文件(注在hadoop2.x.y中,该步完全不相同,请参考他处)
打开方式如上,添加内容如下:
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>localhost:9001</value>
</property>
</configuration>
5. 系统初始化及安装成功检测
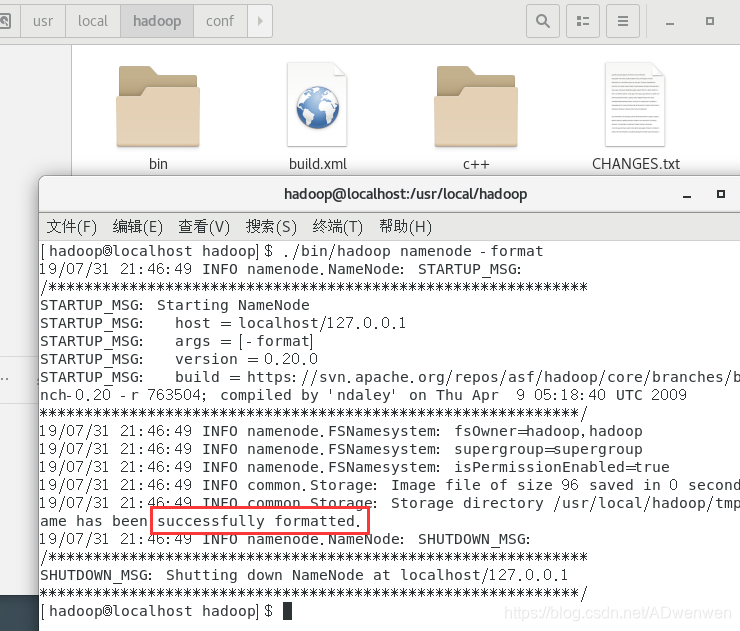
①. 此时系统已经安装完毕,我们在hadoop安装文件打开命令终端,首先进行hdfs系统数据格式化
$ ./bin/hadoop namenode -format出现如下红框中的successfully formatted表示初始化成功
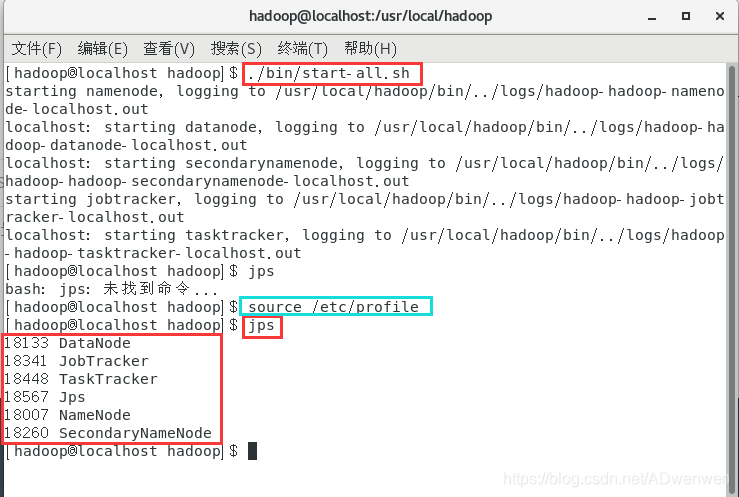
②. 接下来我们启动hadoop环境
$ ./bin/start-all.sh证明启动成功的方式是,运行jps命令查看正在运行的进程。若出现jps未找倒命令的情况下,可以刷新一遍环境变量。
出现最下面红框所示的六个进程表示配置完成。集齐六颗龙珠可以召唤神龙了~~~~。
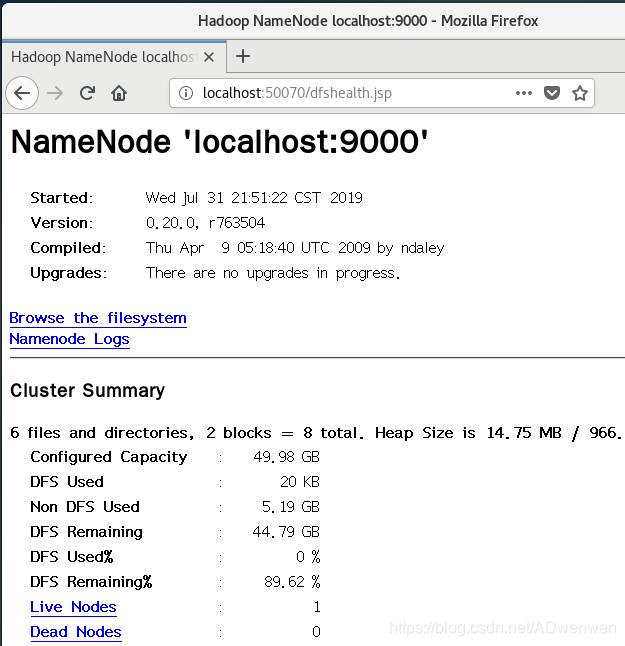
③. 此时另一个检测方法是打开浏览器查看hadoop服务的运行情况
(1).浏览器打开localhost:50070
④. 发现缺少进程的解决方式
在日常使用中,格式化不需要每次都进行,若启动后发现缺少进程可以进行如下操作:
(1).$ ./bin/stop-all.sh #这步是停止hadoop服务
(2). 将hadoop目录下tmp文件夹 删除
(3). $ ./bin/hadoop namenode -format #执行格式化文件命令
(4). $ ./bin/start-all.sh #再次启动服务。
日常中需要正常开启和关闭就可以了。但这个办法也不是万能的,如果有其他情况就问一下度娘吧。~
六、运行示例
简单的运行一下word count这个实例,本质上就是计数一下输入文件中的各种单词数量。在hadoop中这个程序就像是C语言中的“hello world”,java中的“hello Java”一样,作为新手测试使用。(当然,,,我也还是菜鸟一枚)。
在这个示例的演示中,除了简历文件时会进入下级文件夹,其余均在hadoop安装目录执行命令终端操作。
(一)、启动
$ ./bin/start-all.sh
$ jps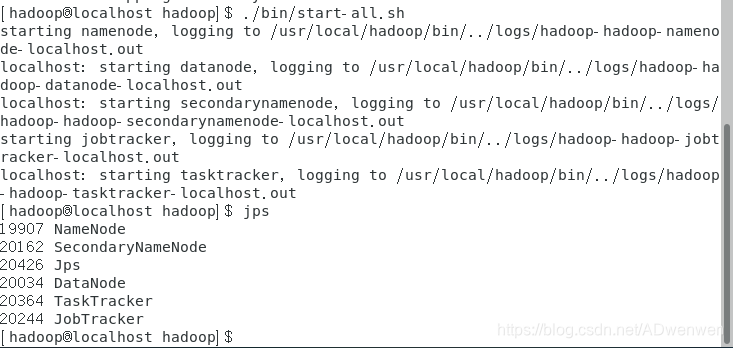
(二)、建立及上传文件
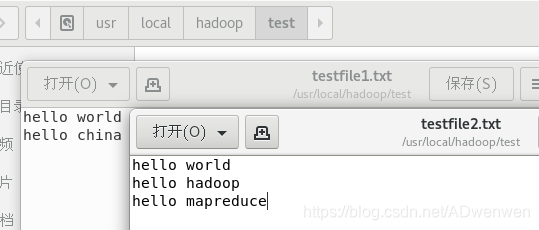
1. 建立测试文件夹及文件,并向其中添加内容。
$ mkdir test #建立test文件夹
$ cd test #进入test文件夹
$ echo "hello world" >> testfile1.txt #添加数据到testfile1.txt
$ echo "hello china" >> testfile1.txt
$ echo "hello world" >> testfile2.txt #添加数据到testfile2.txt
$ echo "hello hadoop" >> testfile2.txt
$ echo "hello mapreduce" >> testfile2.txt
$ cd .. #返回上级目录,即hadoop目录
下面为testfile1.txt 和testfile2.txt的内容:
2. 上传至hdfs系统
$ ./bin/hadoop fs -mkdir -p -user/hadoop #建立用户目录
$ ./bin/hadoop fs -mkdir input #建立输入目录
$ ./bin/hadoop fs -put ./test/*.txt input #将文件传至输入目录(三)、运行
$ ./bin/hadoop jar ./hadoop-0.20.0-examples.jar wordcount input output
input为之前在hdfs中建立的文件夹,output会在运行中自动建立。之后开始运行

(四)、输出结果
./bin/hadoop fs -ls
./bin/hadoop fs -ls output
./bin/hadoop fs -cat output/part-r-00000依次输入上面命令,第一个命令是查看output文件夹是否建立,第二个是查看output文件夹下生成的文件,可以看到part-r-00000即为最后的结果保存文件,第三个命令用于查看生成结果。由下图可以看到,结果计数是没问题的。

执行下面命令可以将结果保存至本地,本地会生成output目录保存结果文件。
$ ./bin/hadoop fs -get output ./output最终结果如下图:
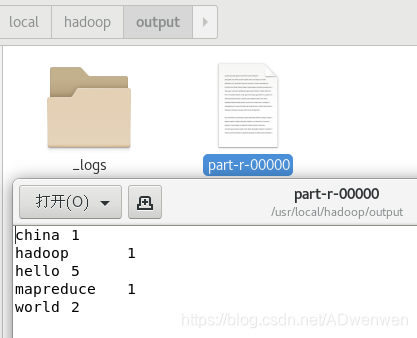
(五)、停止运行
$ ./bin/stop-all.sh输入上面命令,结束hadoop服务。
七、参考与感谢
在安装过程中看了很多教程,也遇到了很多突发问题,感谢下面的博主的宝贵经验。十分感谢。在看这篇帖子的伙伴们如果遇到不明白的问题也可以直接留言,也可以看一下我下面提供的参考,很多经验从中得来。后面其实还遇到了很多问题再慢慢更新吧。
解决上网问题。https://blog.youkuaiyun.com/zhuzj12345/article/details/80747862
设置快捷键。https://blog.youkuaiyun.com/wu_wxc/article/details/48464543
jdk安装:https://www.jianshu.com/p/1d96058e6b20
中文输入法。https://jingyan.baidu.com/article/86f4a73eaa0a6337d6526985.html
修改文件权限:https://www.cnblogs.com/seven4027/p/3512780.html
移动文件:http://www.3qphp.com/linux/command/87.html
用户对安装目录的权限:https://blog.youkuaiyun.com/chen30924190/article/details/82762351
ubuntu安装加例子:https://www.cnblogs.com/acSzz/p/5622627.html
安装教程1:https://www.jianshu.com/p/f82e90d4bd9a
安装教程2:https://www.jianshu.com/p/e925137b2aa2
安装教程3:https://blog.youkuaiyun.com/zolalad/article/details/11472207
安装ant:https://blog.youkuaiyun.com/m0_37039484/article/details/80798139
例子:https://blog.youkuaiyun.com/u010414589/article/details/51254218
有疑问欢迎讨论!不过我也是菜鸟,就是多装了几遍环境。感谢阅读!

















 3604
3604

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









