




目录
(四)、N to M结构RNN模型(encoder-decoder模型、seq2seq模型)
一、RNN简介
(一)、简介
循环神经网络(Recurrent Neural Network, RNN),指的是一类以序列数据为输入的神经网络模型。与经典的前馈网络不同之处在于,RNN模型处理序列数据能够获取到更多的语义信息、时序信息等。通常,序列数据指的是一条数据内部的元素有顺序关系的数据,如文本、如文章、语句;时序数据,如一周的天气、三个月的股市指数等。通常可用于语音识别、语言模型、机器翻译及时序分析等。
(二)、RNN处理任务示例——以NER为例
NER(Named Entity Recognize,命名实体识别)任务,表示从自然语言文本中,识别出表示真实世界实体的实体名及其类别,如:
句子(1): I like eating apple! 中的 apple 指的是 苹果(食物)
句子(2): The Apple is a great company! 中的 Apple 指的是 苹果(公司)
一般的DNN网络中,输入方式为逐元素输入,即句子内的词单独独立地输入模型进行处理,这将导致上下文信息丢失,这样的结果会导致每个词的输入仅会输出单一结果,与上下文语义无关。如上图示例,若训练集中的苹果一词大部分标记为苹果(食物),则测试阶段所有的苹果也将标记为食物;反之则测试阶段将都标记为公司。
二、模型提出
(一)、基本RNN结构
为了解决普通DNN无法有效获取上下文信息的缺点,RNN最基本的改良点在于增加一个“模块”用于存储上下文信息。以下图(a)为一个典型RNN的结构示意图:
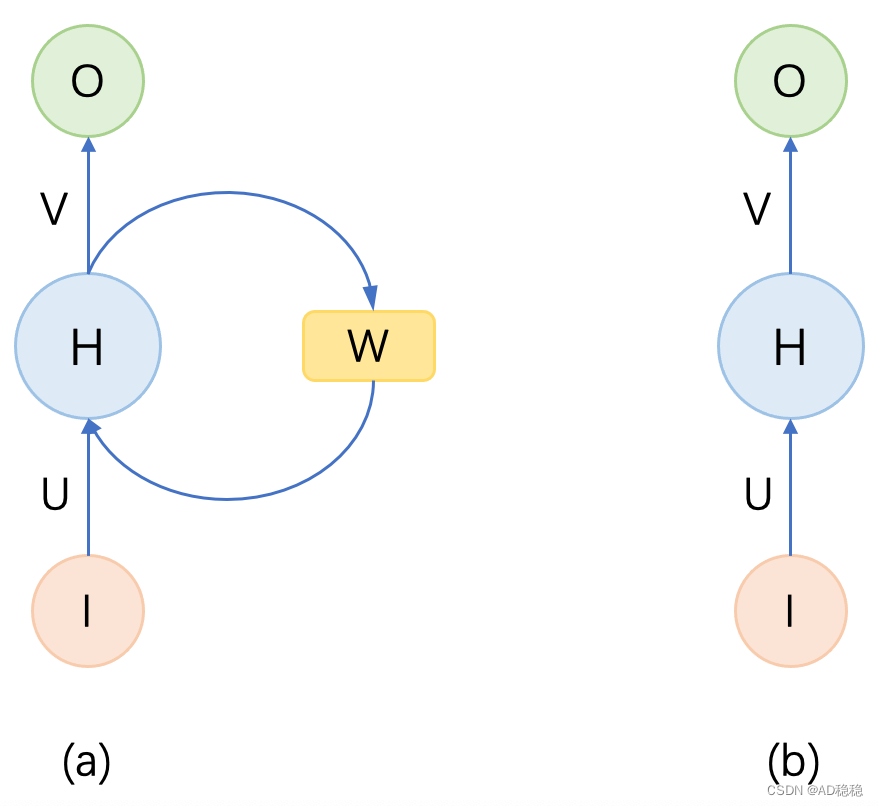
图(a)是一个典型的RNN结构图,初看可能会不太理解。理解首先不看右侧的矩阵,只看左侧的顺序网络,即图(b),表示的就是一个普通的前馈神经网络。 接下来回头看图(a),RNN相比于一般前馈网络,增加了一个保存上下文信息的权重矩阵
,也即每次计算输出不仅要考虑当前输入数据,还要考虑序列数据的上下文信息。
(二)、RNN展开结构
我们知道了RNN模型增加了一个权重矩阵用于存储输入序列的上下文信息,接下来我们来介绍RNN结构如何进行模型计算以及上下文信息如何应用到RNN结构。为了更好地理解RNN计算方式,下图是一个序列展开的RNN示意图(即上图a的时序展开图):
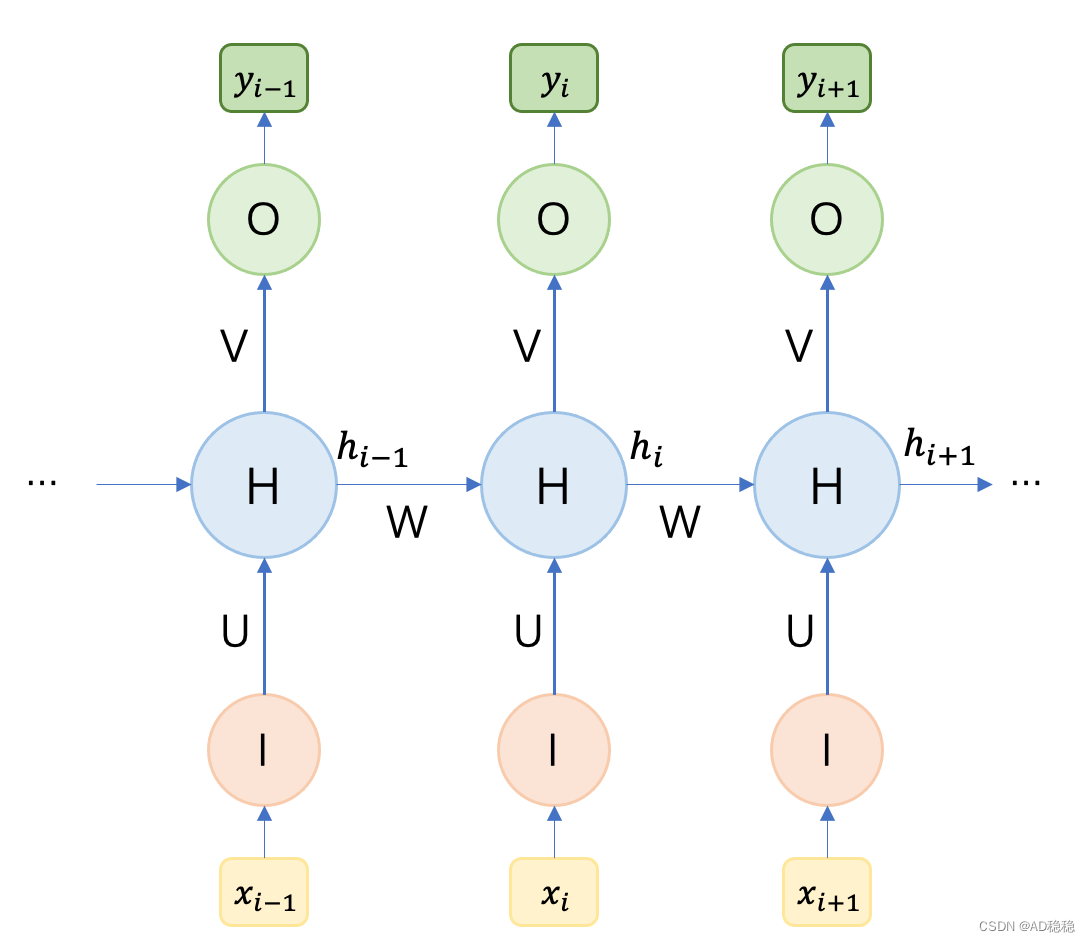
其中表示
时刻的模型输入,
表示
对应的输入结果。RNN模型计算公式如下:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2938
2938

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









