







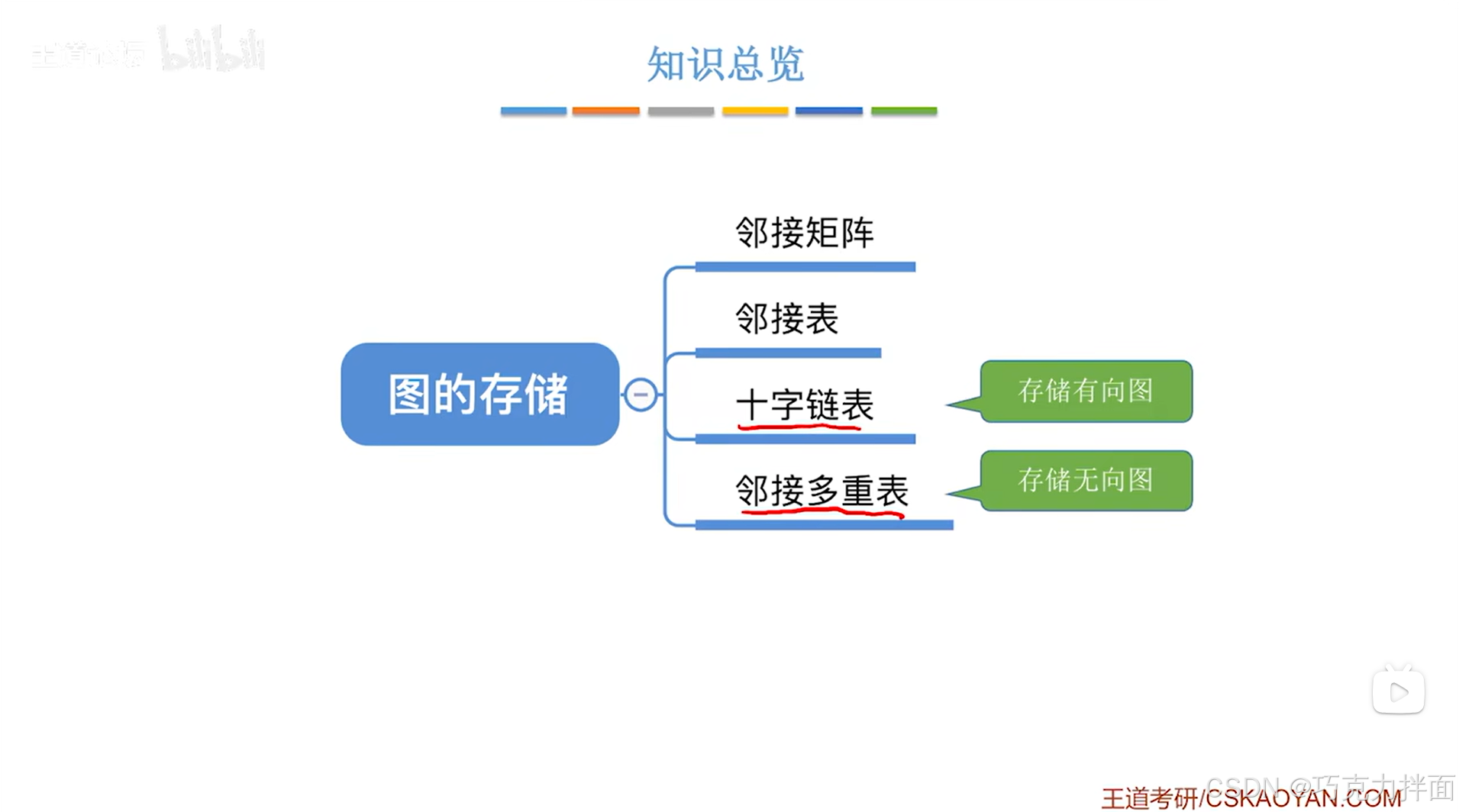
一.十字链表存储有向图:
1.存储原理:
-
顺序表中存储顶点结点
-
用十字链表存储有向图时,就需要定义两个结构体:弧结点(表示弧),顶点结点(表示顶点)
-
顶点结点中,firstout指针指向的是从当前顶点往外射的弧,firstin指针指向的是以当前顶点为尾的弧
-
有向图如果采用十字链表法,想要找到和某个顶点相连的所有弧是很方便的,同时十字链表法解决了邻接表法中难以找有向图的入边的难题
-
弧结点中权值指的是弧的某种含义的数值,如距离,带权图中要用到权值
2.实例:
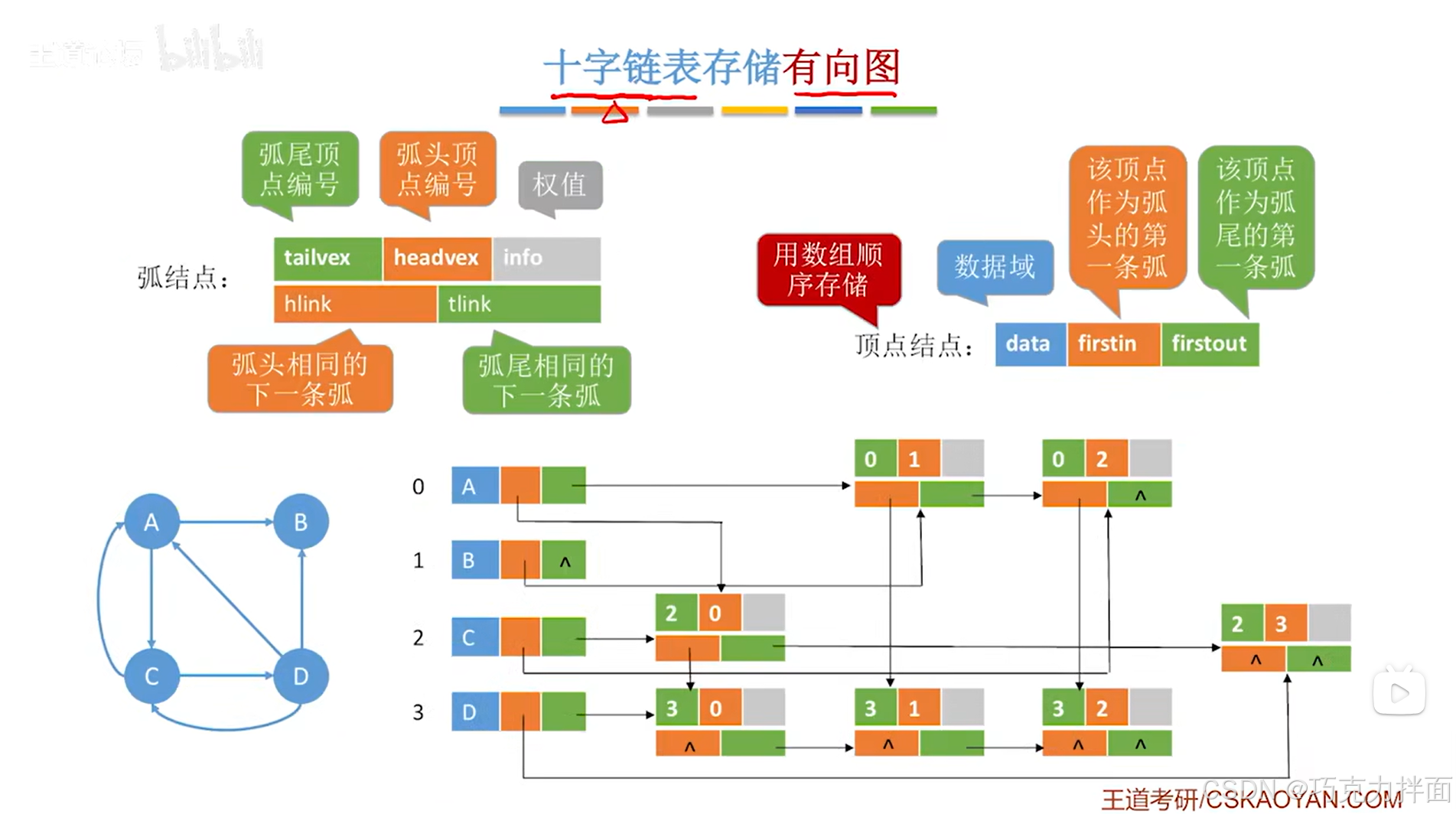
以上述图片为例,有向图中有4个顶点,分别为A、B、C、D,依次存储在顺序表的0、1、2、3索引上,
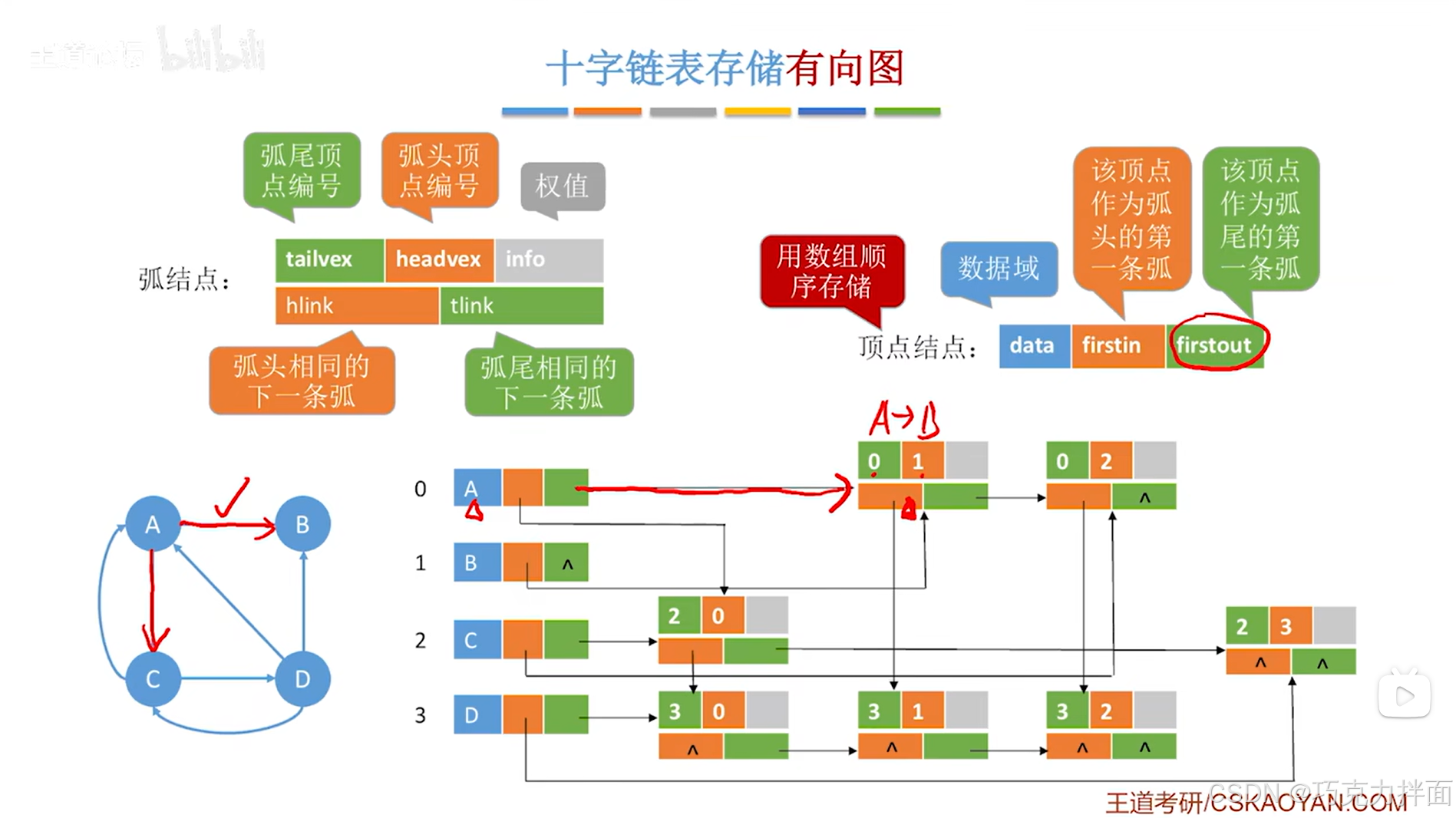
对于顶点A,
顶点A有一条弧指向顶点B,所以在顶点结点中的firstout指针指向的第一条弧的信息是从顺序表中0索引上的A顶点指向顺序表中1索引上的B顶点(此时用到的是弧结点,tailvex指向顺序表中0索引的顶点即A顶点,headvex指向顺序表中1索引的顶点即B顶点),
顶点A还有一条弧指向顶点C,因此之前的弧结点中的tlink指针指向A顶点指向C顶点的弧,其中第二条弧的信息是从顺序表中0索引上的A顶点指向顺序表中2索引上的C顶点(此时用到的是弧结点,tailvex指向顺序表中0索引的顶点即A顶点,headvex指向顺序表中2索引的顶点即C顶点),
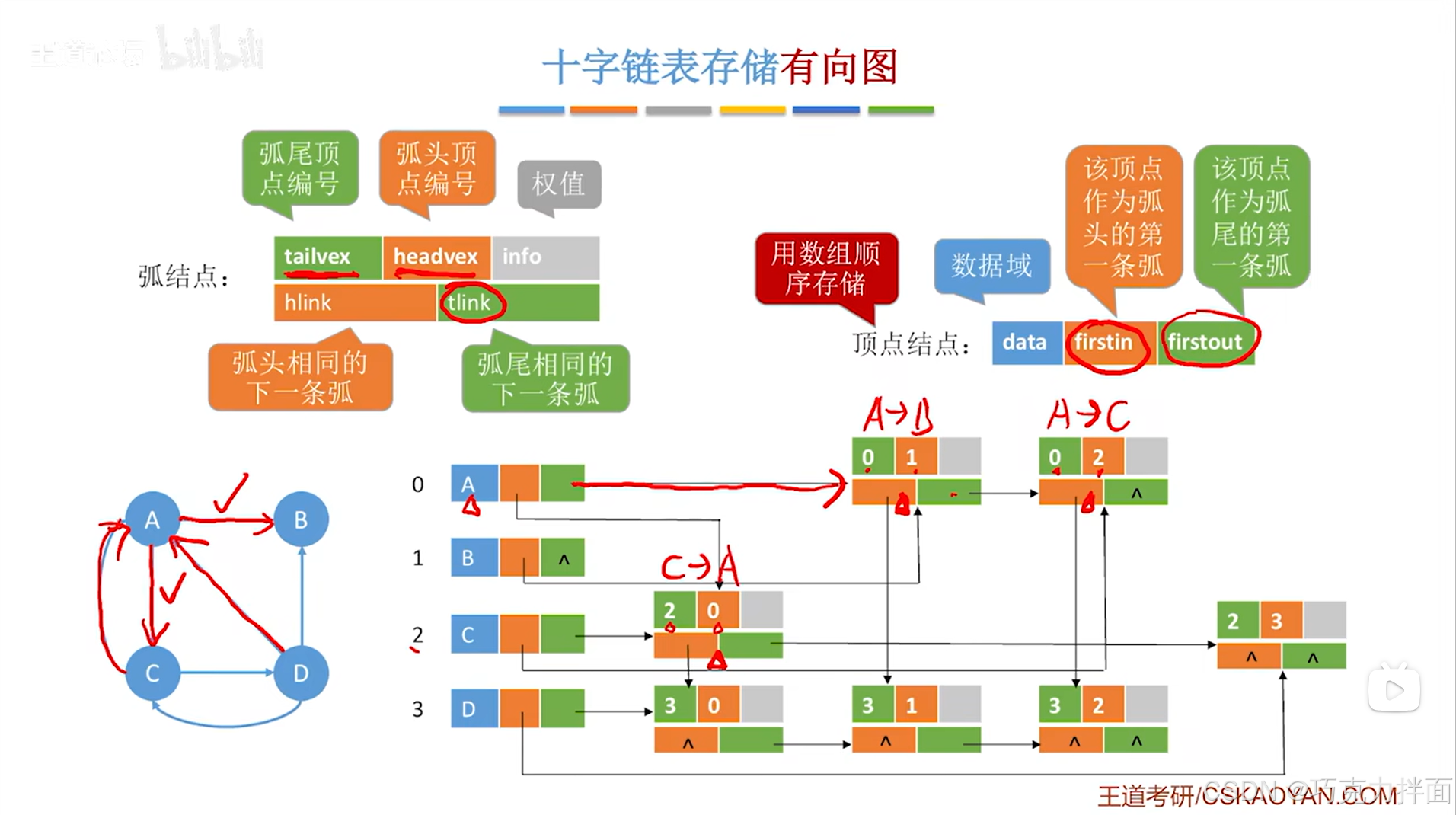
还有两条弧是指向顶点A,分别是顶点D指向顶点A和顶点C指向顶点A,这两条弧的信息,要顺着顶点A的firstin指针(firstin指针代表该顶点作为弧头的第一条弧)往后找,
顶点A的firstin指针指向了顺序表中2索引上的C顶点指向顺序表中0索引上的A顶点的这条弧,
继续顺着这个弧结点的hlink指针往后找,
此时指向的是顺序表中3索引上的D顶点指向顺序表中0索引上的A顶点的这条弧:
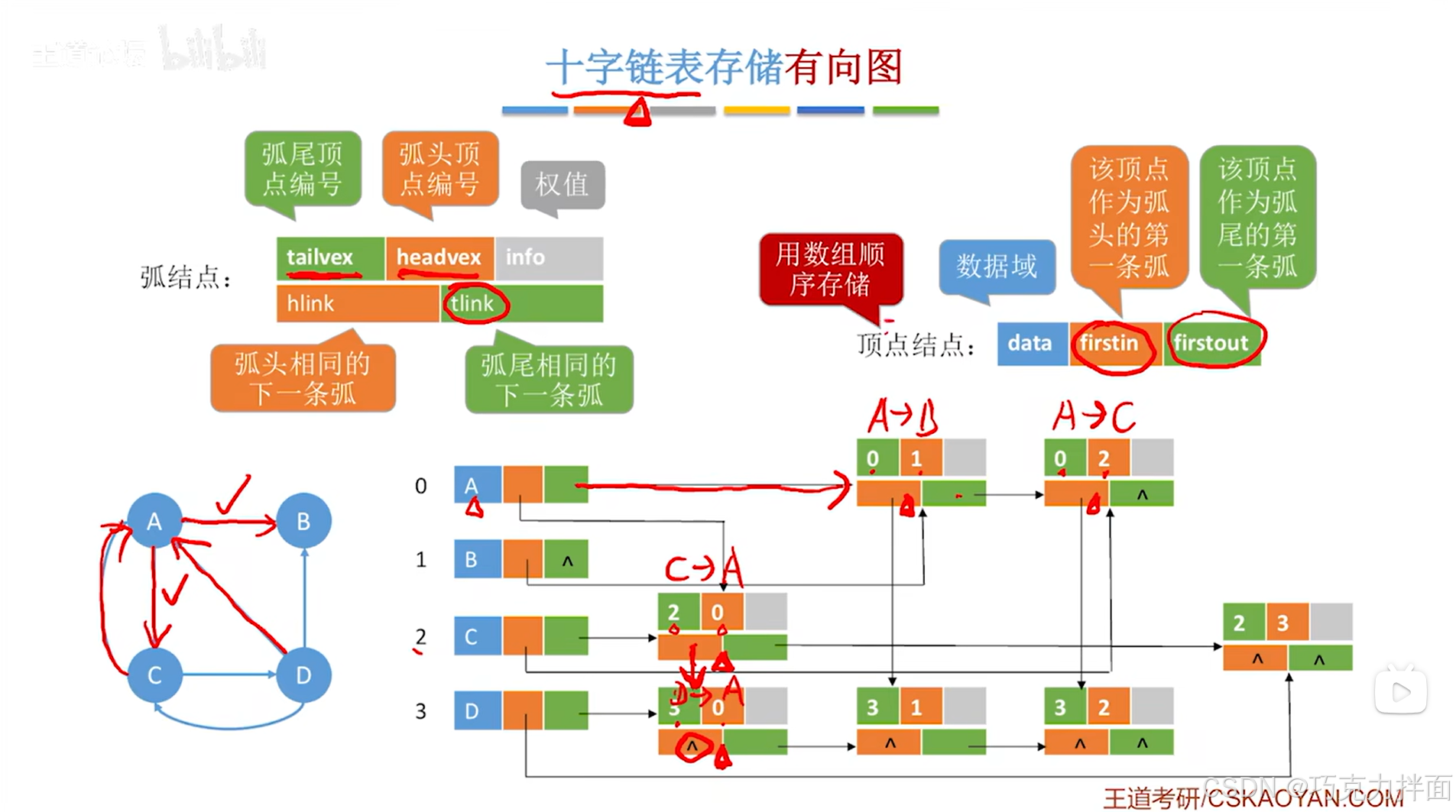
这时就没有指向A顶点的弧了,那么此时对应的弧结点中的hlink指针就不会再指向任何弧了即hlink指针指向NULL。
3.十字链表法性能分析:
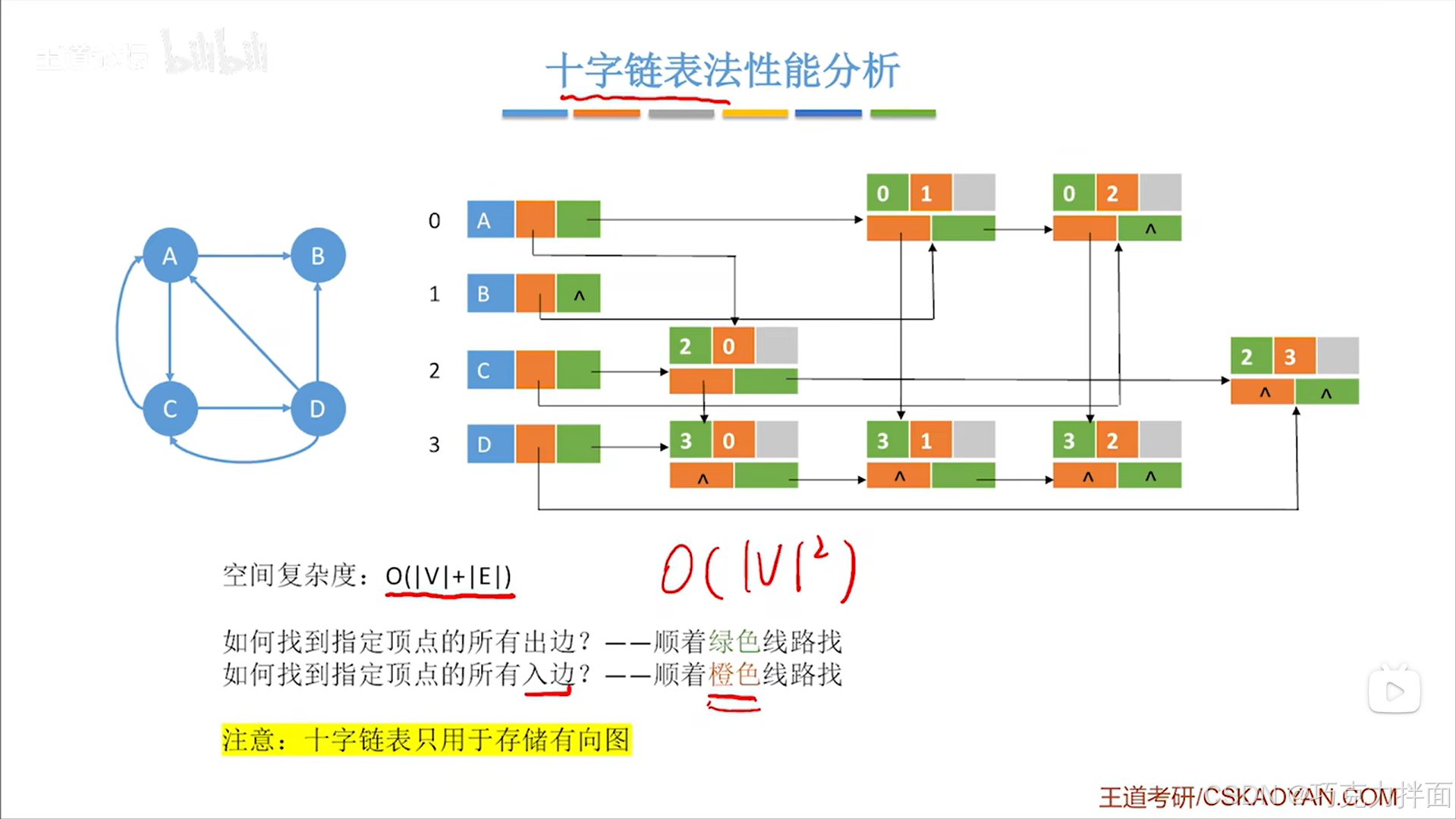
-
V表示顶点个数,E表示弧的条数
-
指定某个顶点,该顶点的出边表示弧的尾为该顶点,该顶点的入边表示弧的头为该顶点
二.邻接多重表存储无向图:(解决了邻接矩阵、邻接表存储无向图的某些问题)
1.邻接矩阵、邻接表存储无向图的某些问题:
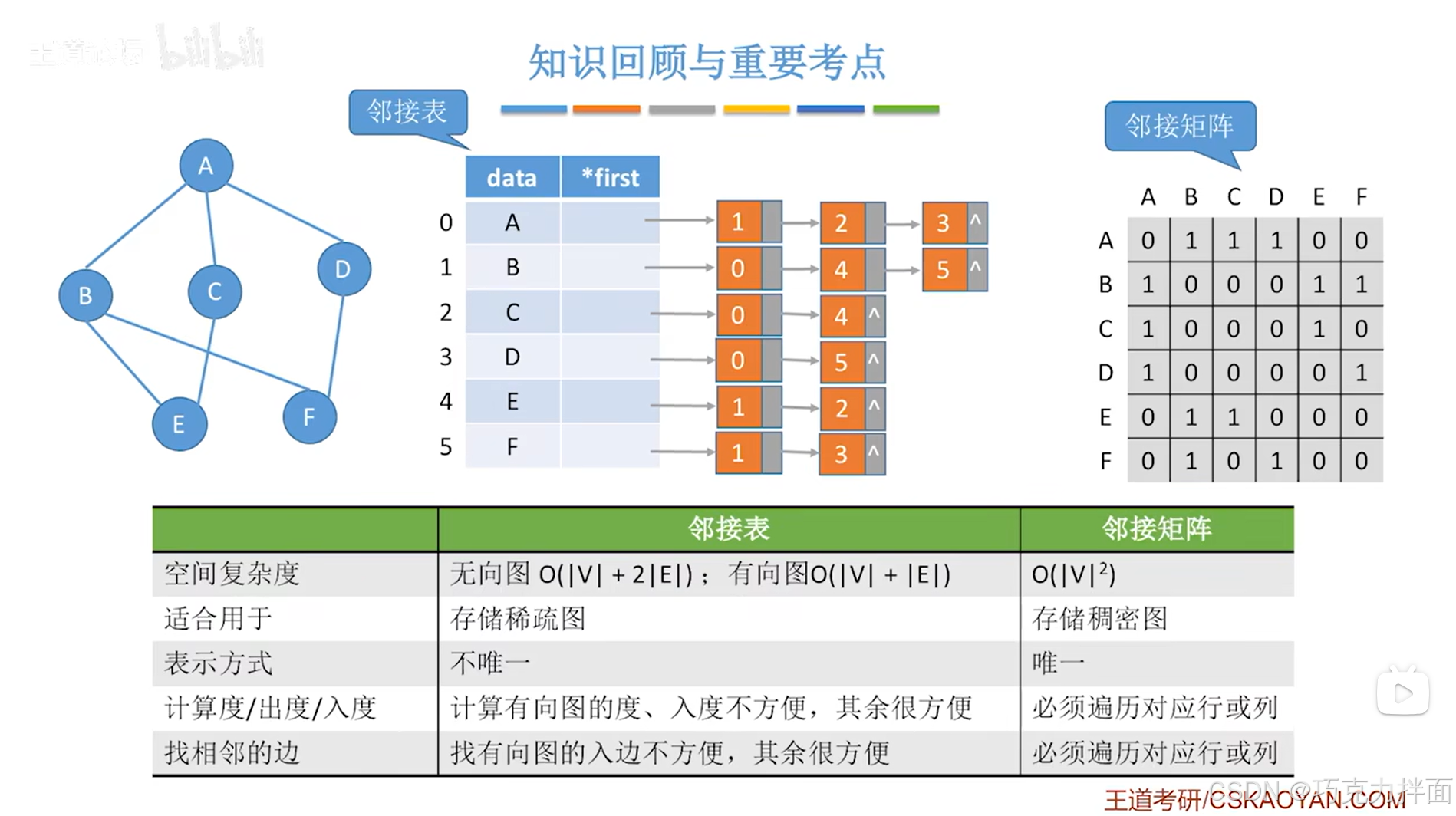
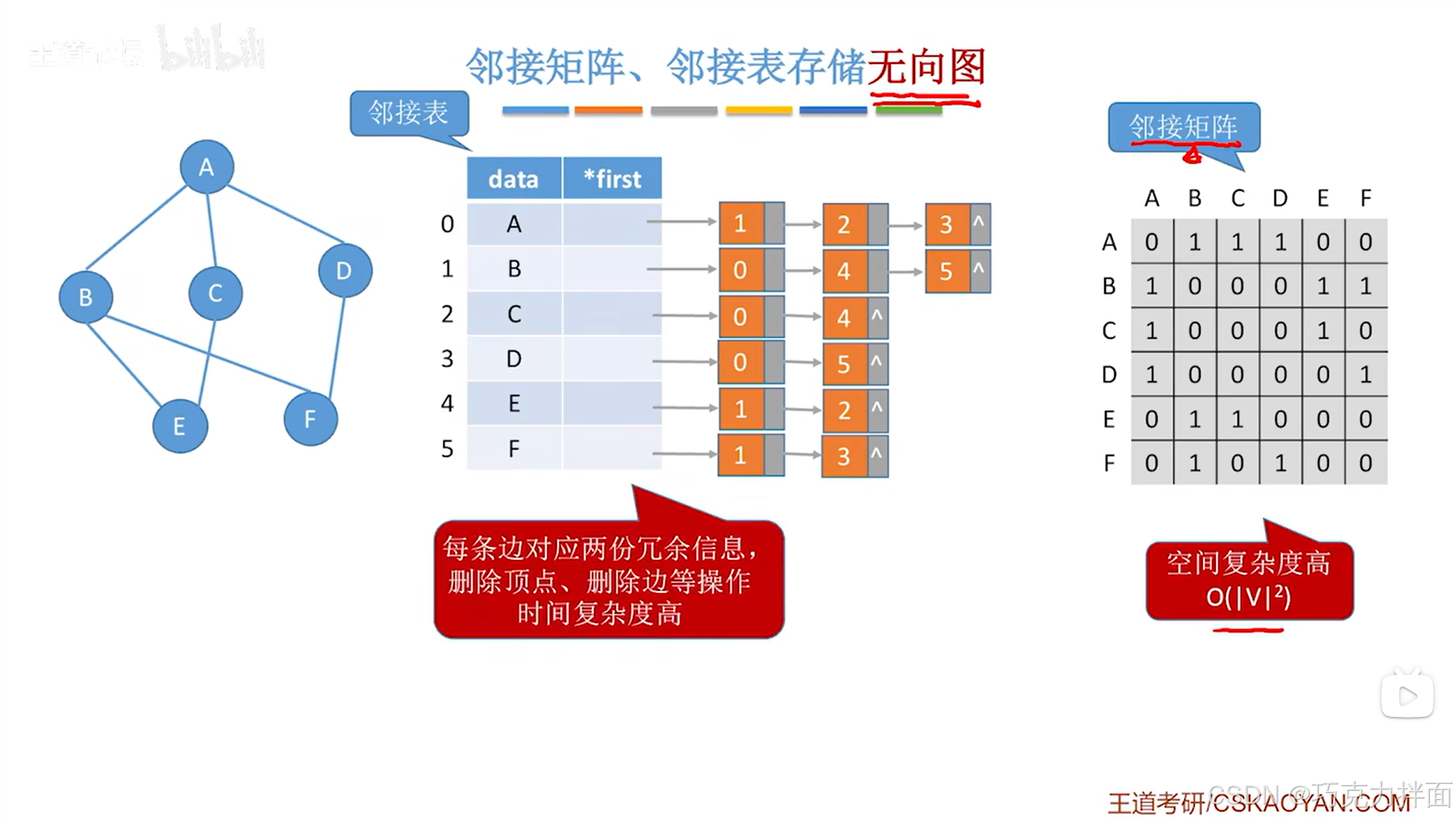
以上述图片为例:
-
邻接矩阵存储无向图时主要的问题是空间复杂度太高即O( |V*V| ),V为图的顶点个数
-
邻接表存储无向图时主要的问题是每一条边会对应两份冗余信息,比如顶点A和B之间仅有一条边,但在顺序表中0索引上的A顶点和1索引上的B顶点各自表示了一次A和B之间的边,总共表示了两次A和B之间的边,所以要在无向图中删除A和B之间的边的话,就需要删除两次->导致删除边的时间复杂度较高:
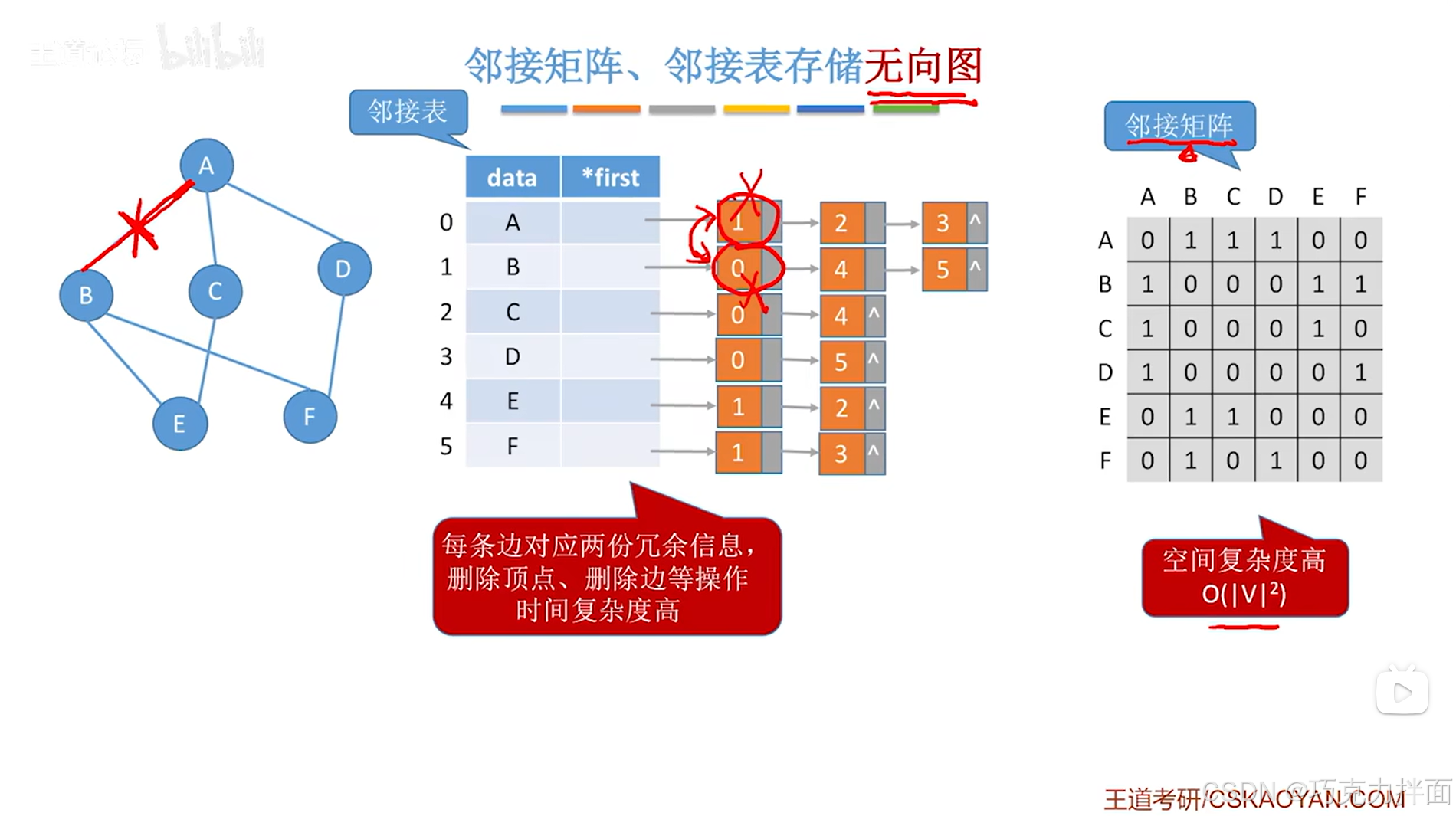
-
邻接表存储无向图时如果要删除某个顶点,例如A顶点,除了要删除顺序表中A顶点和A顶点对应的链表外,如果A顶点外的其他顶点对应的链表中包含了A顶点的索引即0索引,此时就需要把这些链表中A顶点的索引即0索引都删除->导致删除顶点的时间复杂度较高:
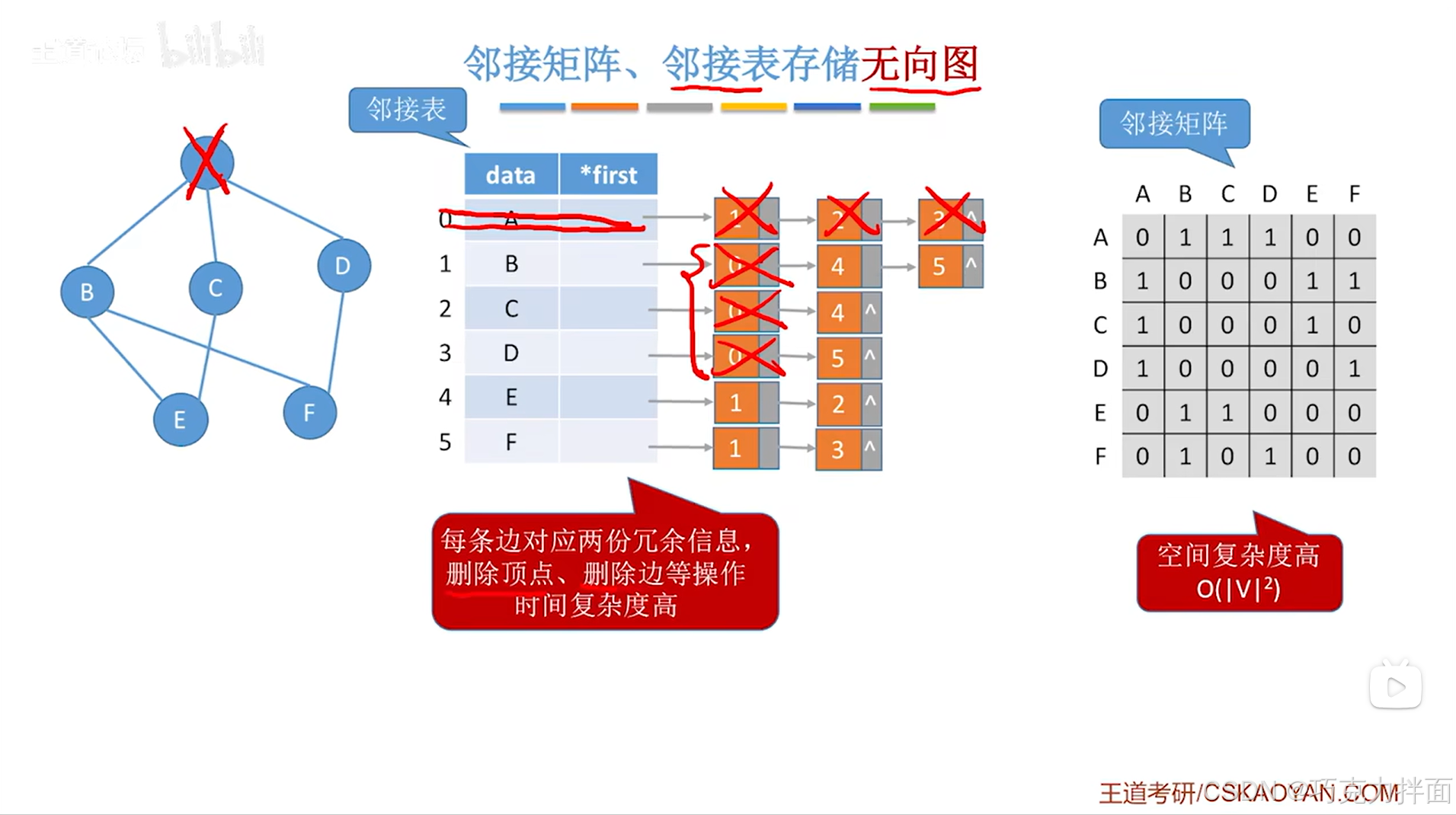
因此,上述提到的问题可以通过邻接多重表解决。
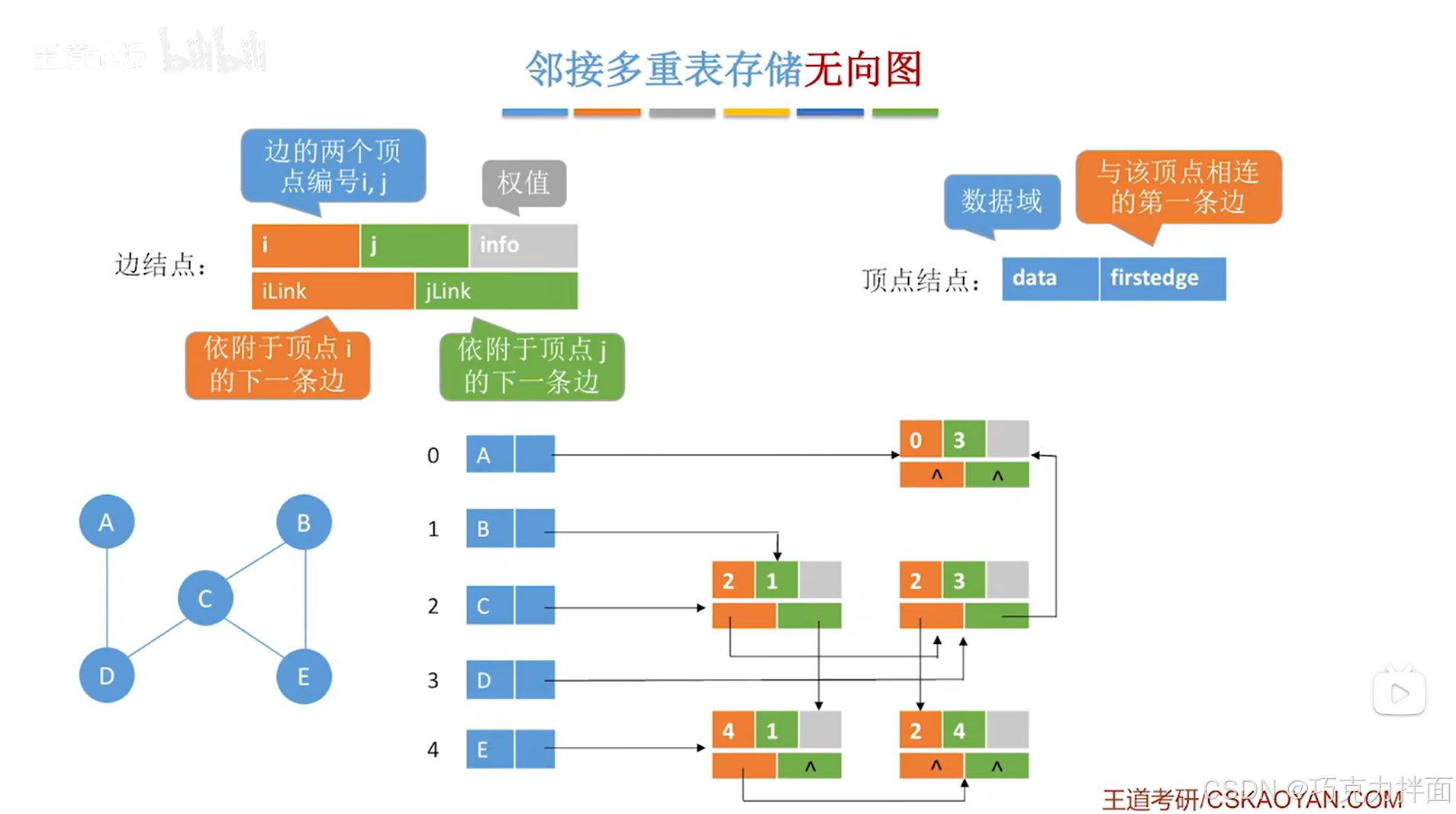
2.邻接多重表存储无向图:
a.存储原理:
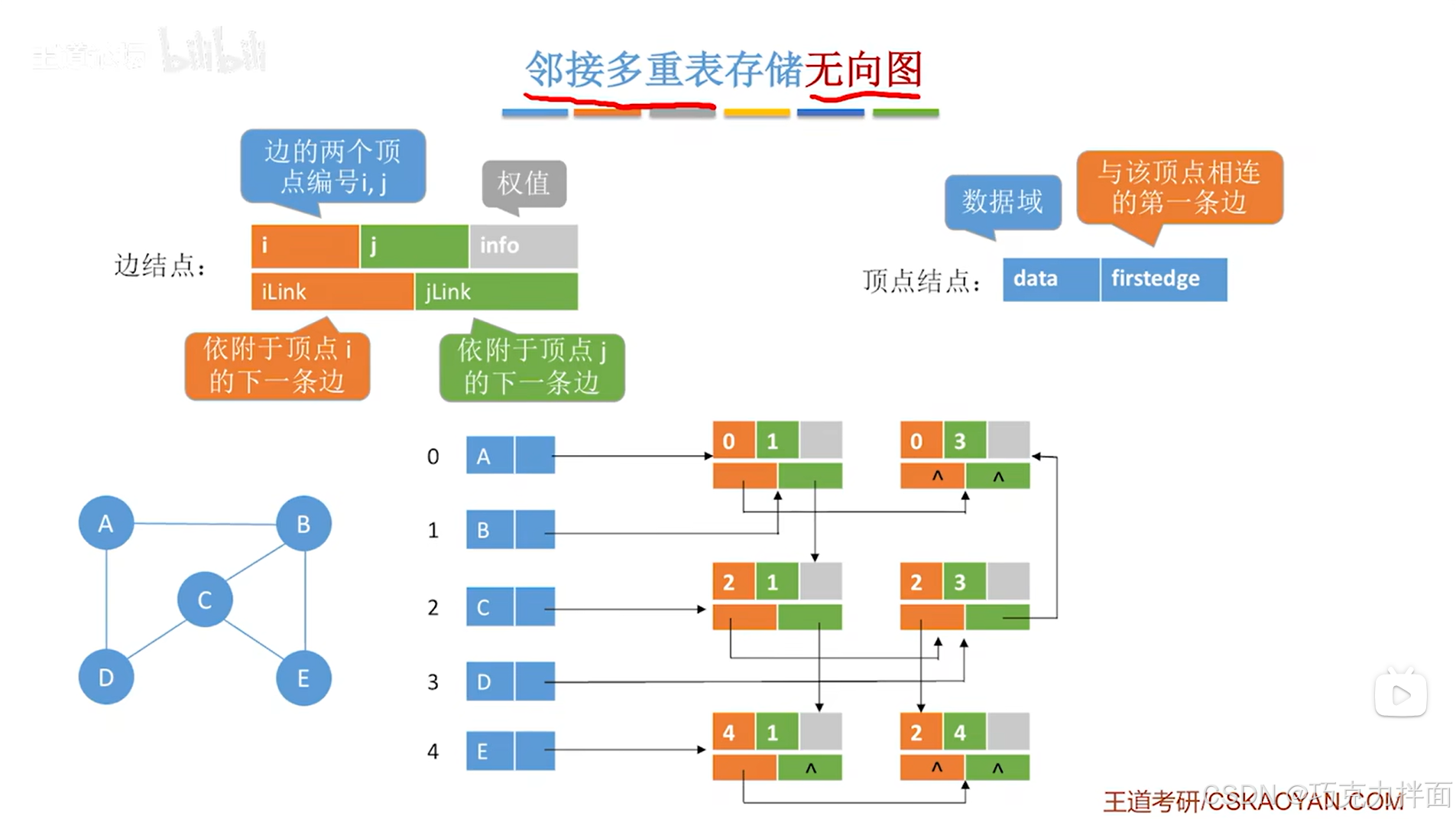
以上述图片为例:
-
边结点中权值指的是边的某种含义的数值,如距离,带权图中要用到权值
-
由于是无向图,所以边结点中编号i表示的顶点和编号j表示的顶点并没有先后顺序
-
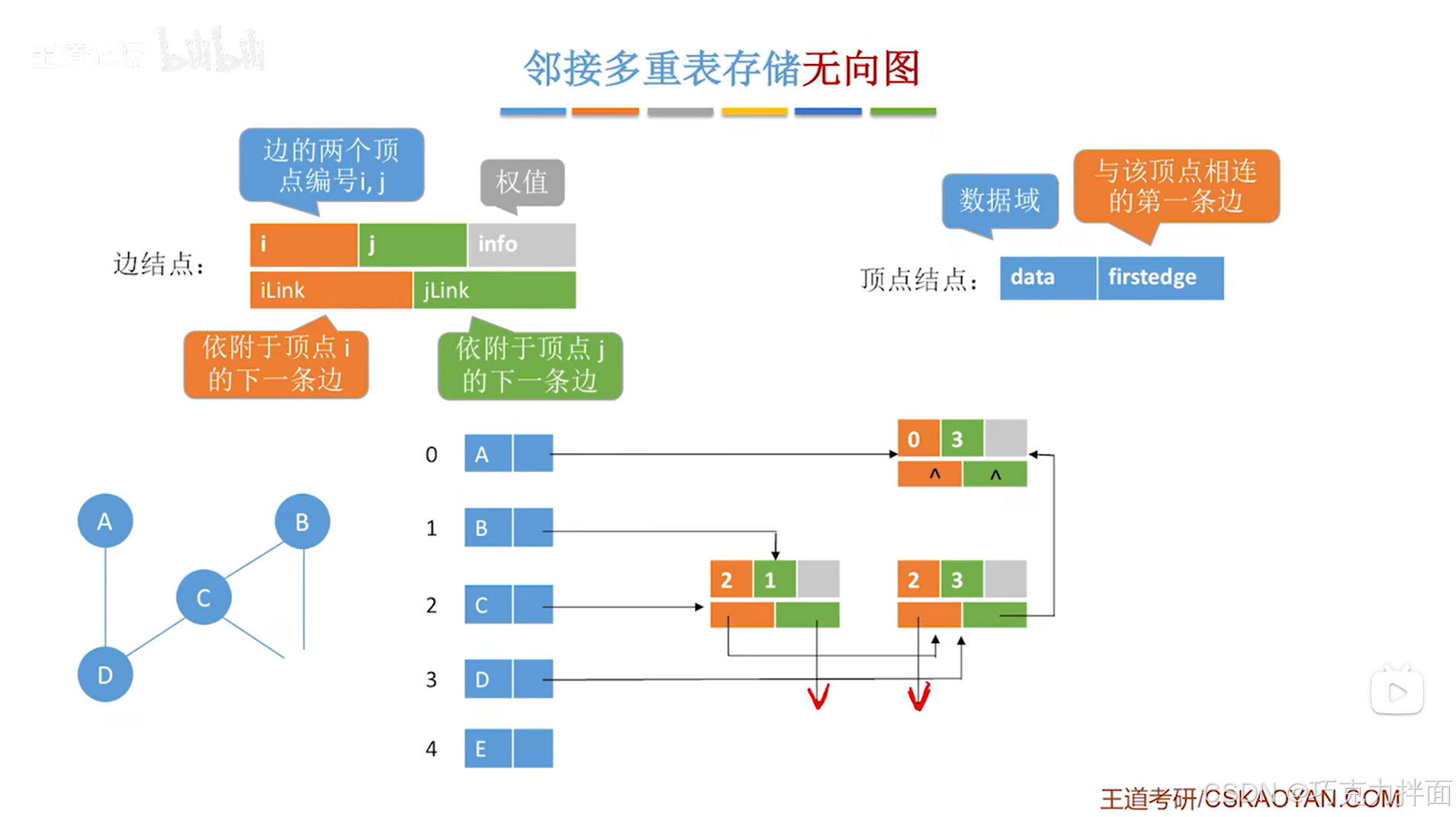
边结点和顶点结点都可以定义为结构体,有五个顶点A、B、C、D、E,分别存储在线性表的0、1、2、3、4索引上
-
以顶点A为例,顶点A分别连接顶点B和顶点D,因此顺着顺序表中0索引上的顶点A的firstedge指针往后找,首先找到的是顺序表中0索引对应的A顶点和1索引对应的B顶点的边结点即A和B之间的边,在当前边结点中,顺着iLink指针往后找,就可以找到顺序表中0索引对应的A顶点和3索引对应的D顶点的边结点即A和D之间的边,此外,已经没有其他的边和顶点A相连,所以当前边结点的iLink指针指向NULL,表示已经没有其他的边和顶点A相连:
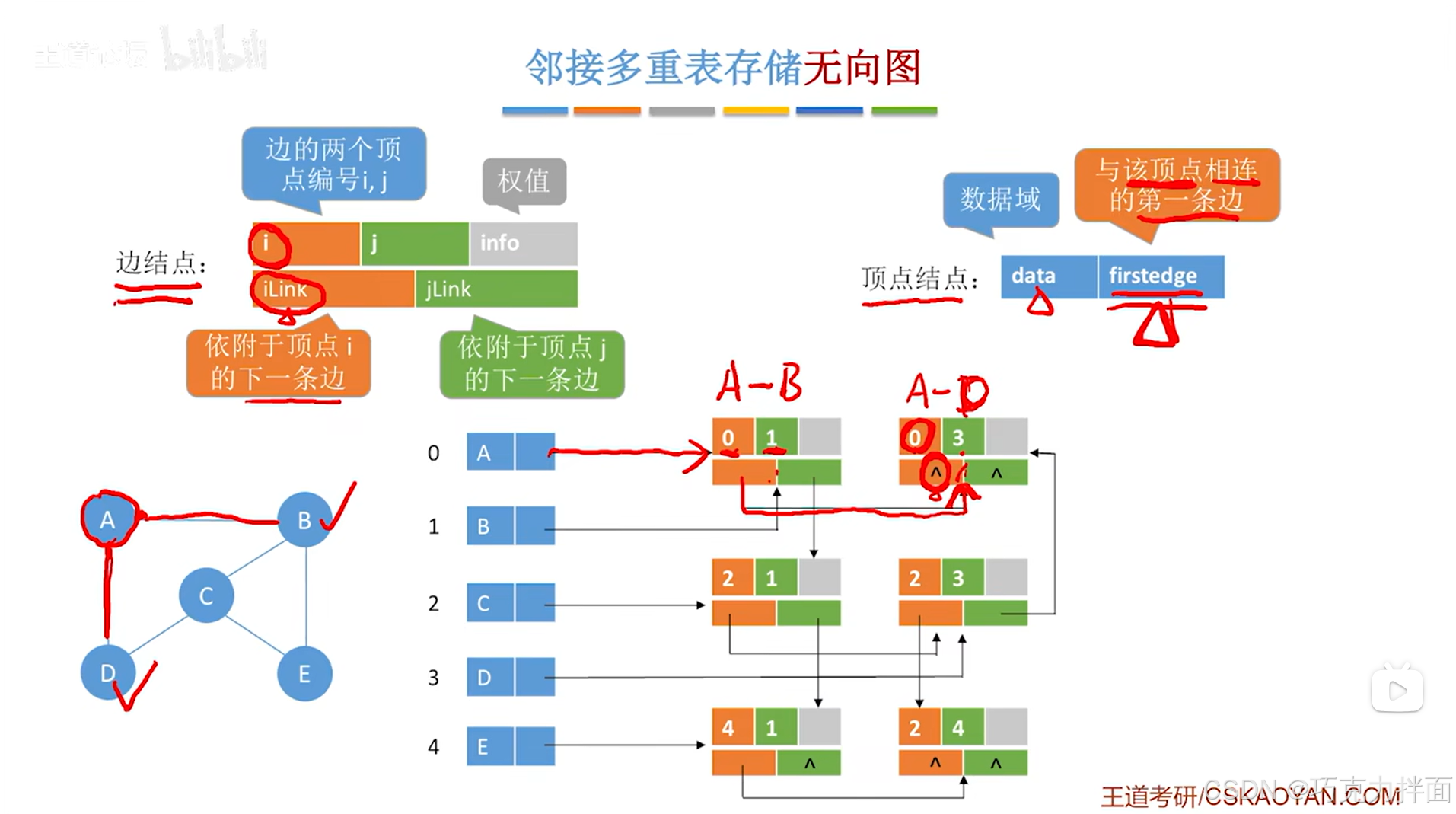
-
以顶点B为例,顶点B依次连接顶点A、C、E,因此顺着顺序表中1索引上的顶点B的firstedge指针往后找,首先找到的是顺序表中0索引对应的A顶点和1索引对应的B顶点的边结点即A和B之间的边,在当前边结点中,B顶点在编号j上(因为B顶点在顺序表中1索引的位置上),因此要想继续找到下一条和顶点B相连的边,就需要顺着jLink指针往后找,就可以找到顺序表中2索引对应的C顶点和1索引对应的B顶点的边结点即C和B之间的边,同理,在当前边结点中,B顶点在编号j上(因为B顶点在顺序表中1索引的位置上),因此要想继续找到下一条和顶点B相连的边,就需要顺着jLink指针往后找,就可以找到顺序表中4索引对应的E顶点和1索引对应的B顶点的边结点即E和B之间的边,至此,就找到了所有和顶点B相连的边,在当前边结点中,B顶点在编号j上(因为B顶点在顺序表中1索引的位置上),所以当前边结点的jLink指针指向NULL
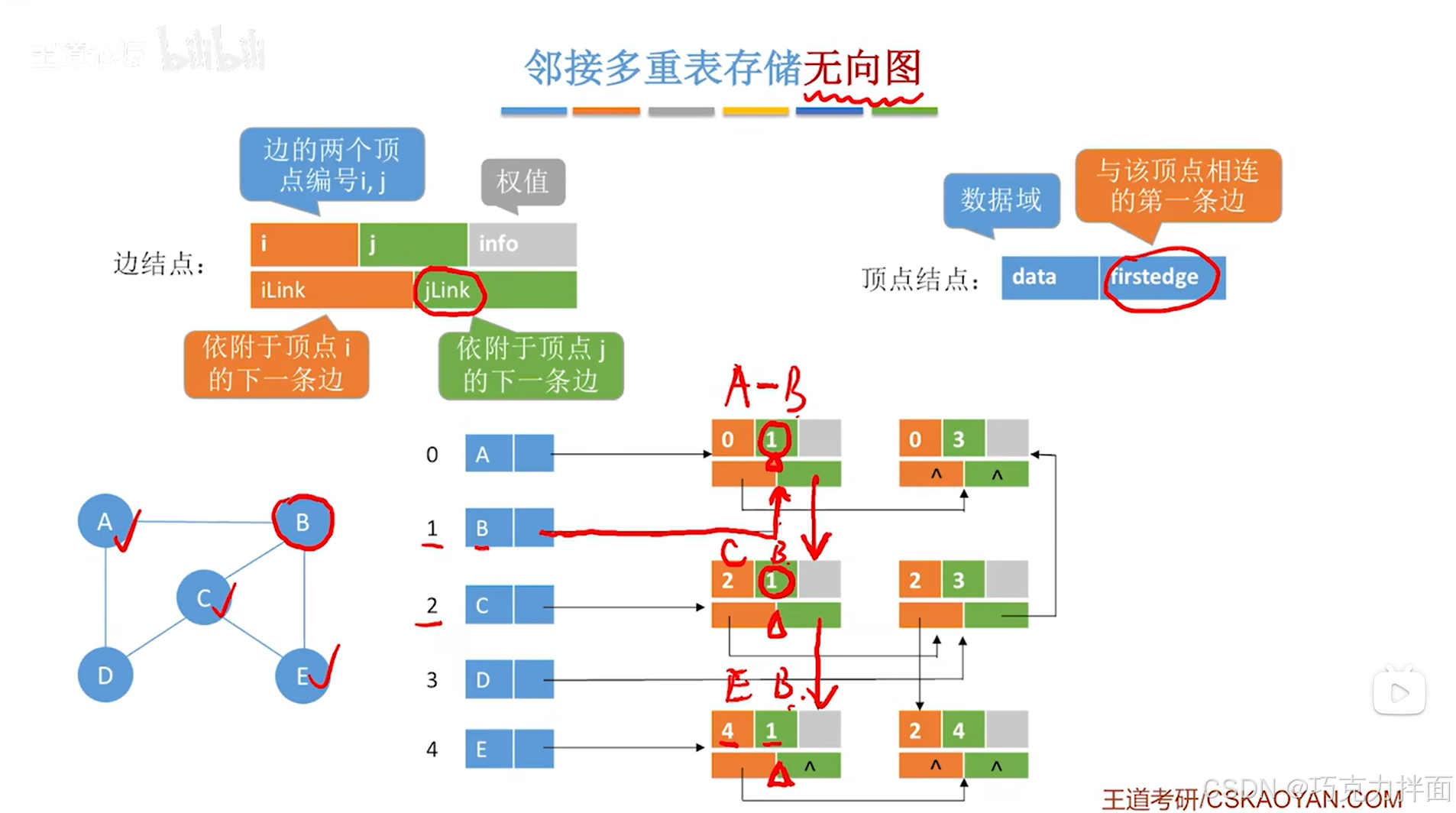
-
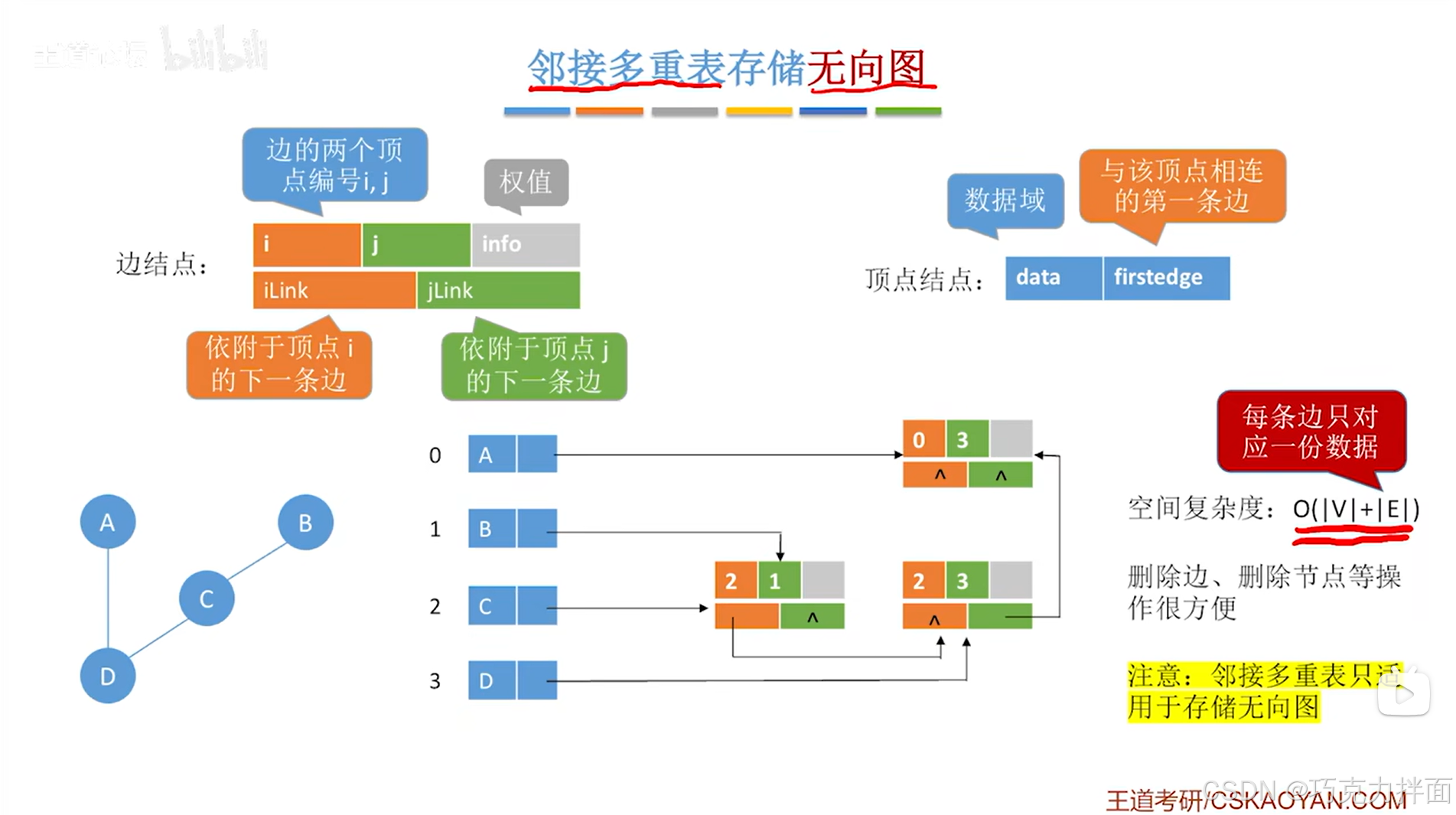
基于以上的案例,如果使用邻接多重表来存储无向图,找到和某一个顶点相连的所有的边是很容易的(例如要找和某一个顶点相连的所有的边,先在顺序表中找到该顶点,然后顺着firstedge指针就可以找到所有和该顶点相连的边),同时每一个边结点只会对应一条边,只有一份数据,因此,就不需要像邻接表那样同时维护了两份冗余的数据,邻接多重表的这一特性,在实现删除边和顶点的操作上就方便很多
-
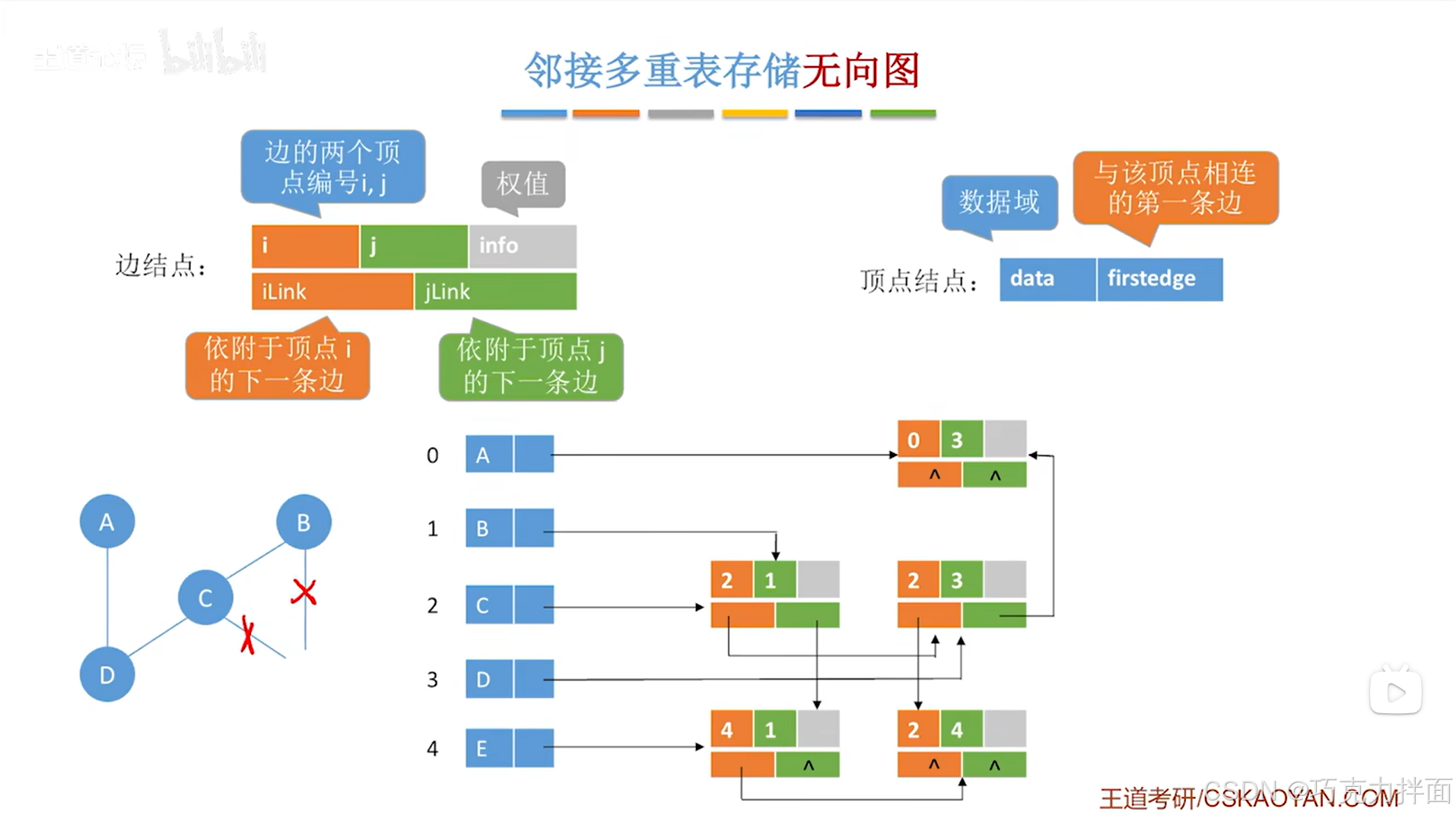
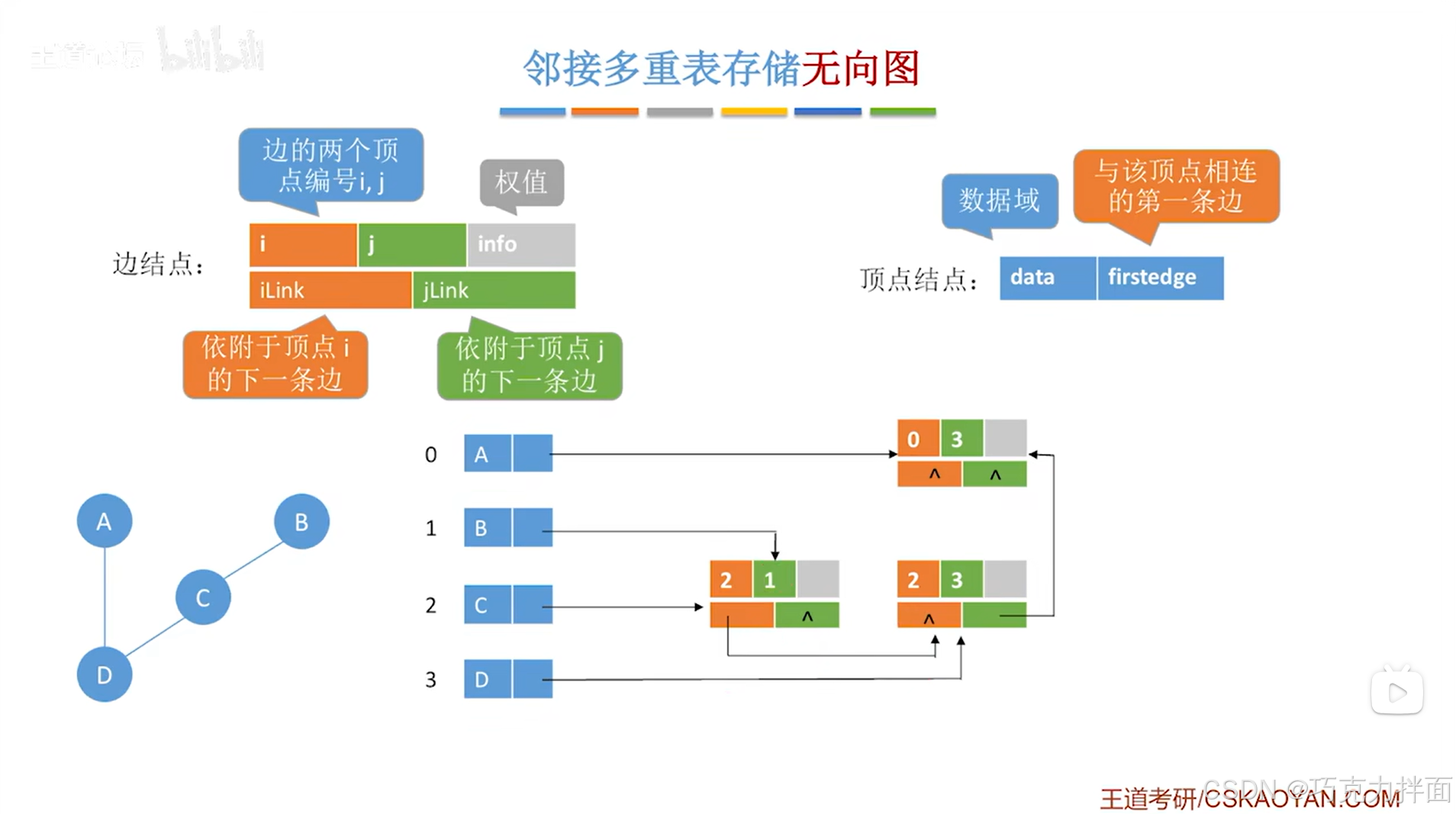
例如要删除顶点A和顶点B之间的边,这条边对应的边结点是顺序表中0索引对应的A顶点和1索引对应的B顶点即A和B之间的边,这个边结点被删除后就需要修改顺序表中顶点A和顶点B的firstedge指针,此时顶点A只和顶点D相连了,由于顶点A在顺序表的0索引位置上即在当前要删除的边结点的编号i上,所以在删除该边结点之前,只需要顺着该边结点的iLink指针,来找到i索引对应的顶点连着的下一条边对应的边结点,然后让firstedge指针指向该边结点,顶点B同理:
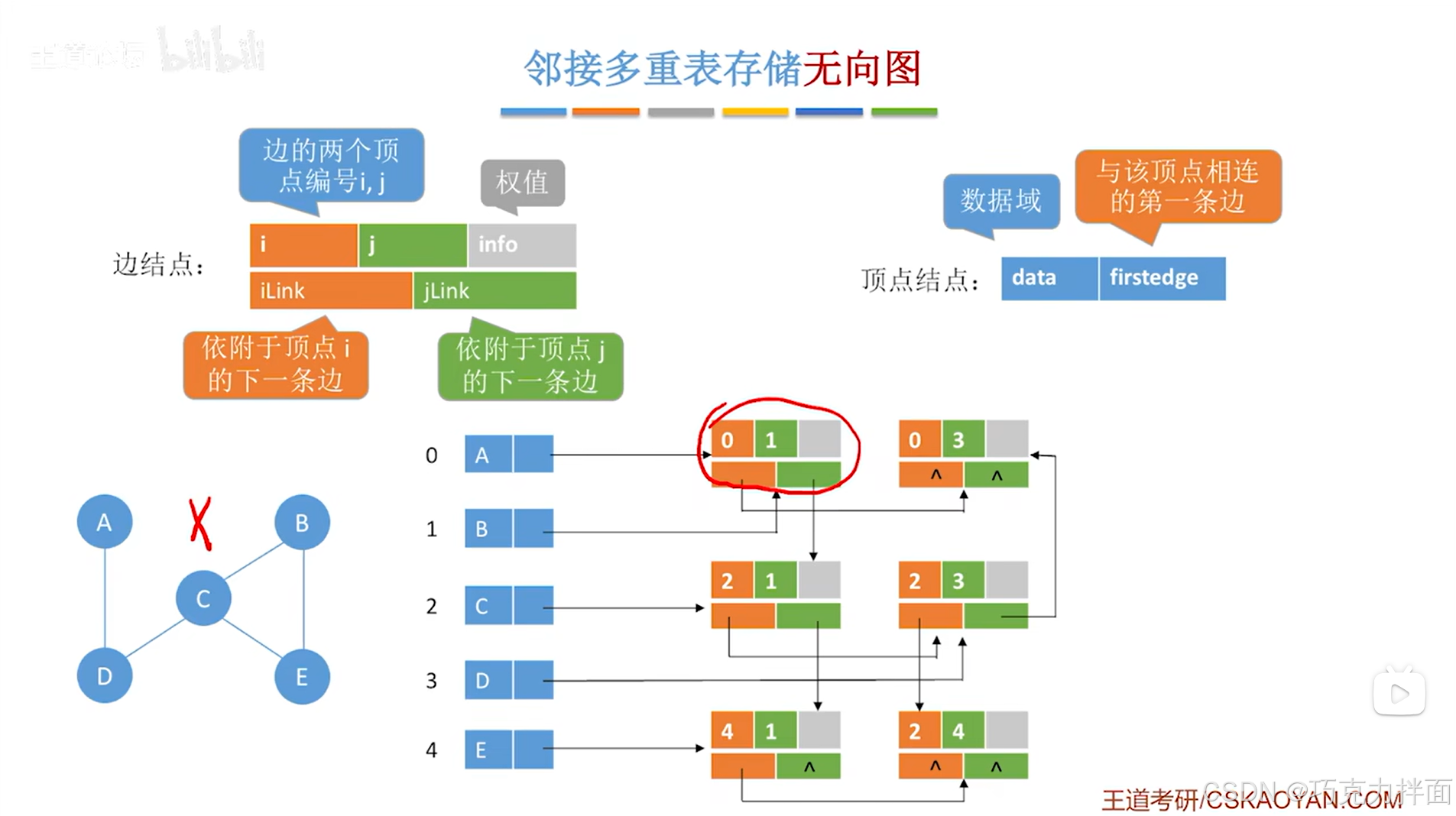
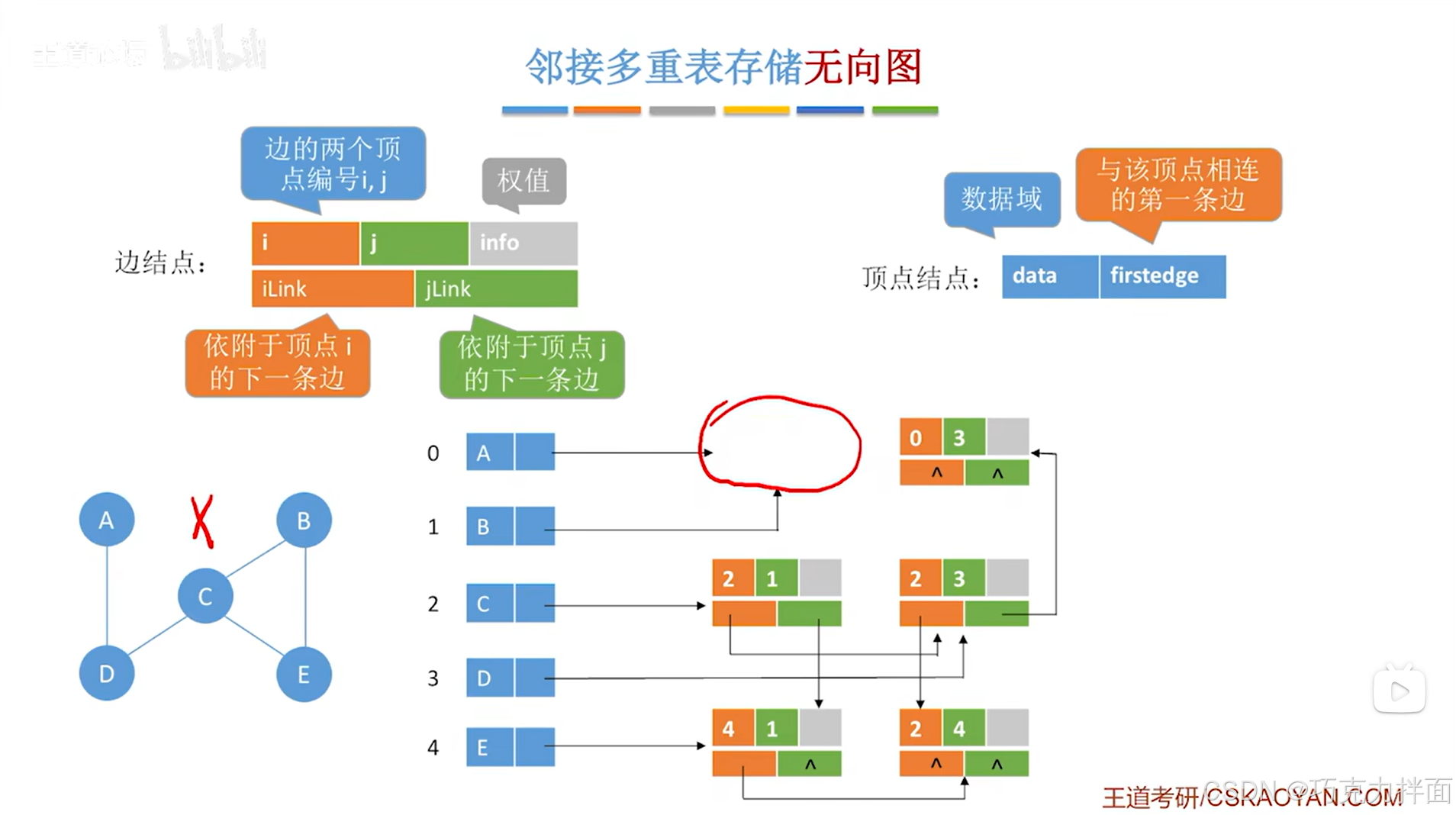
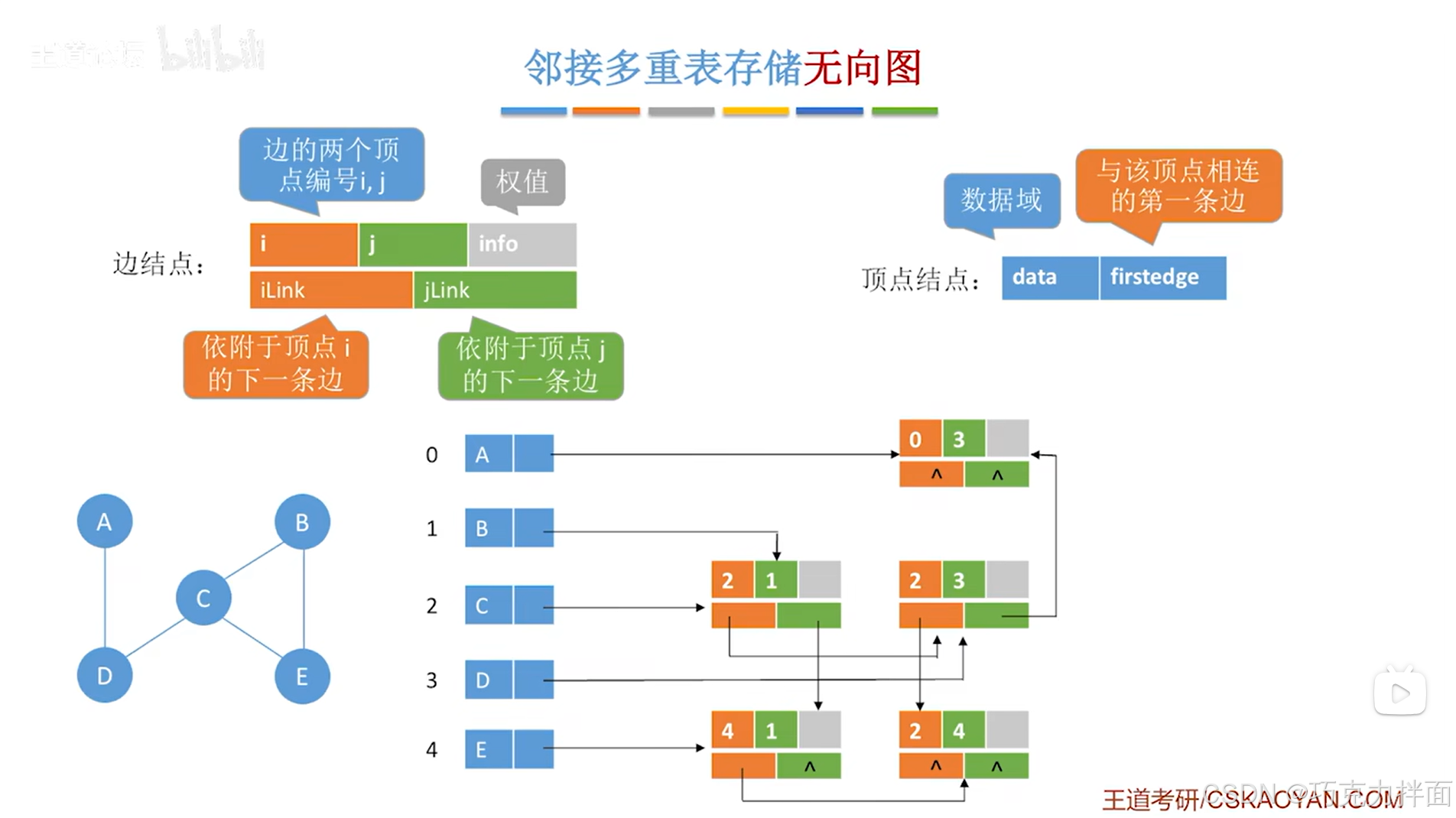
-
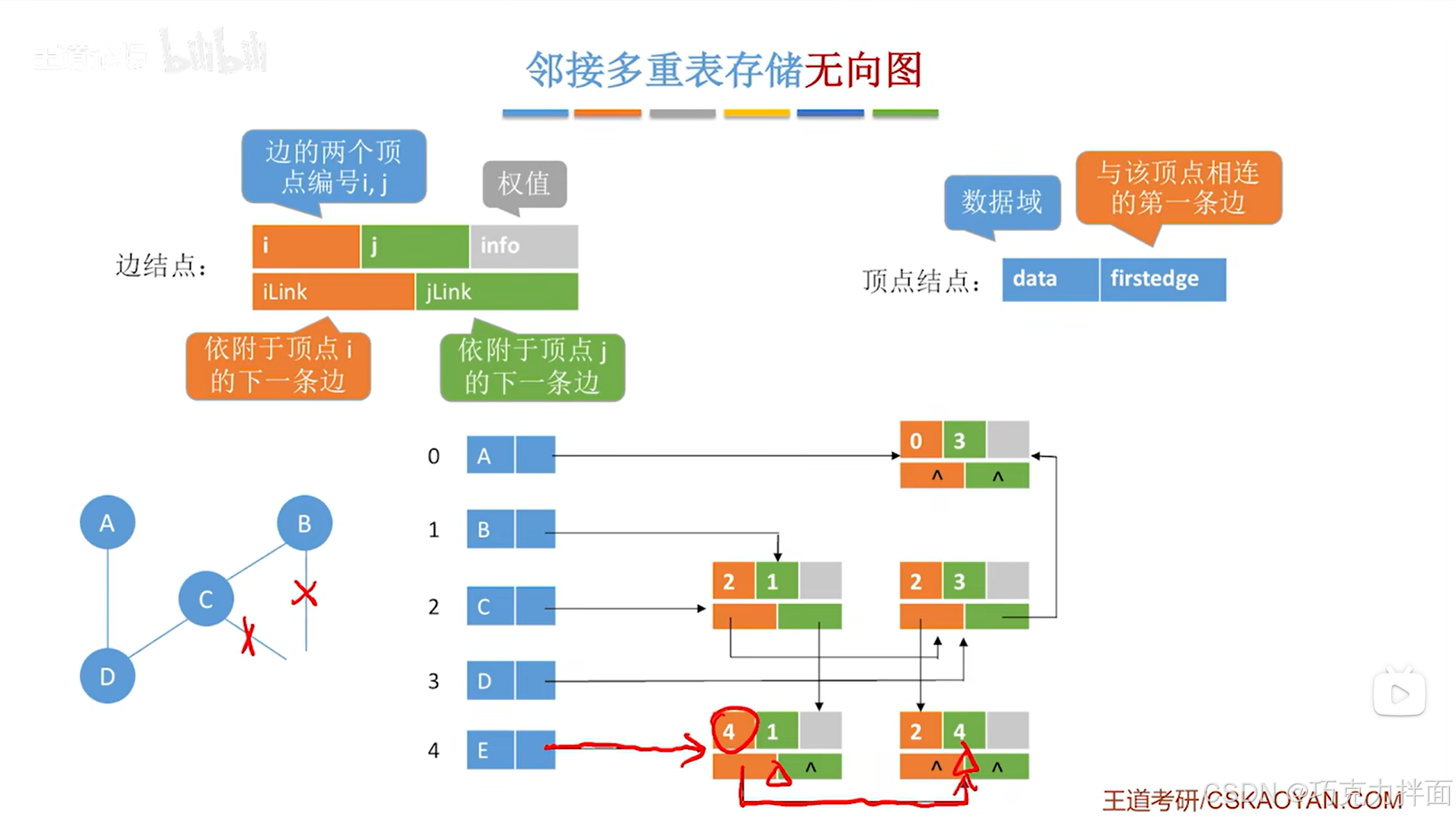
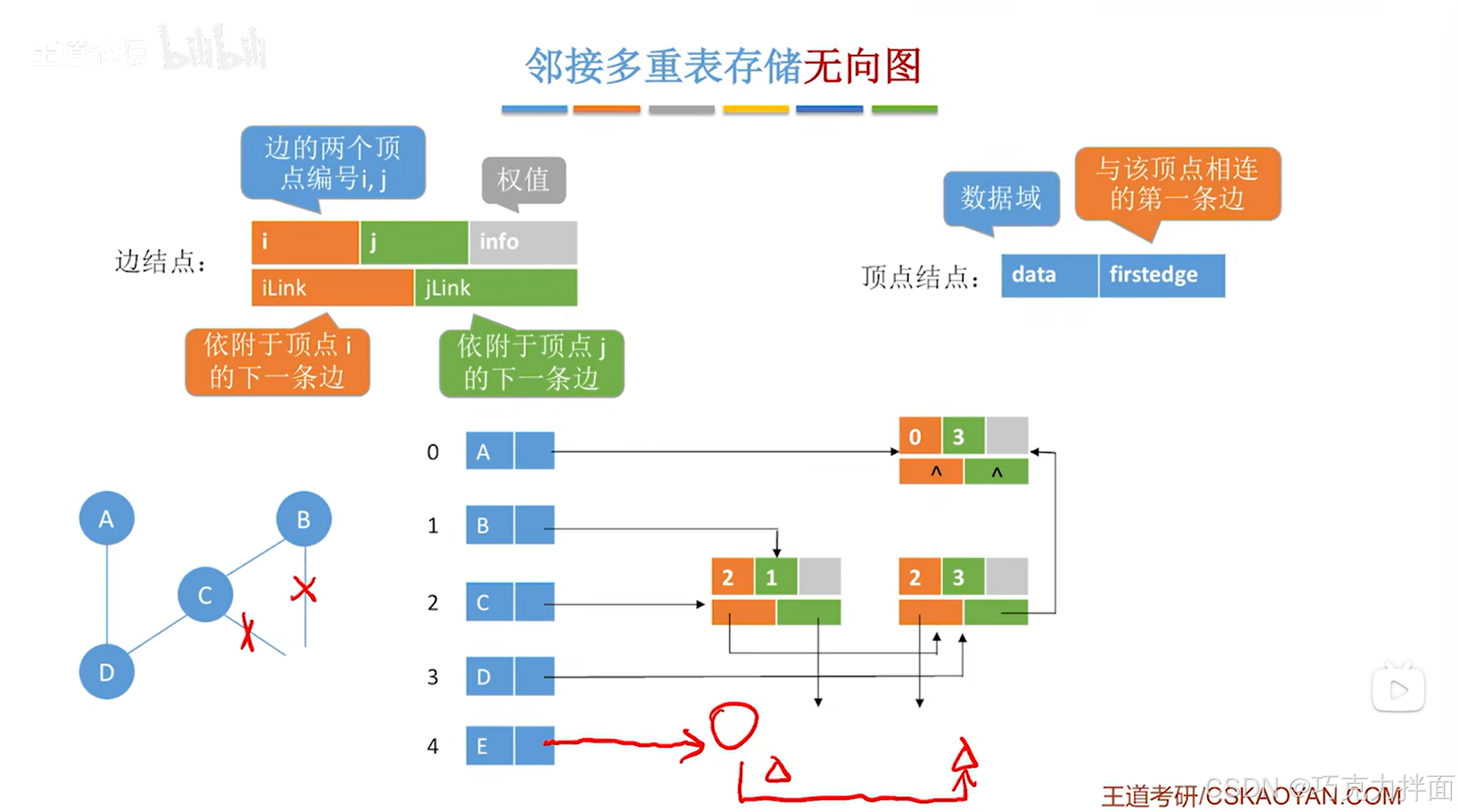
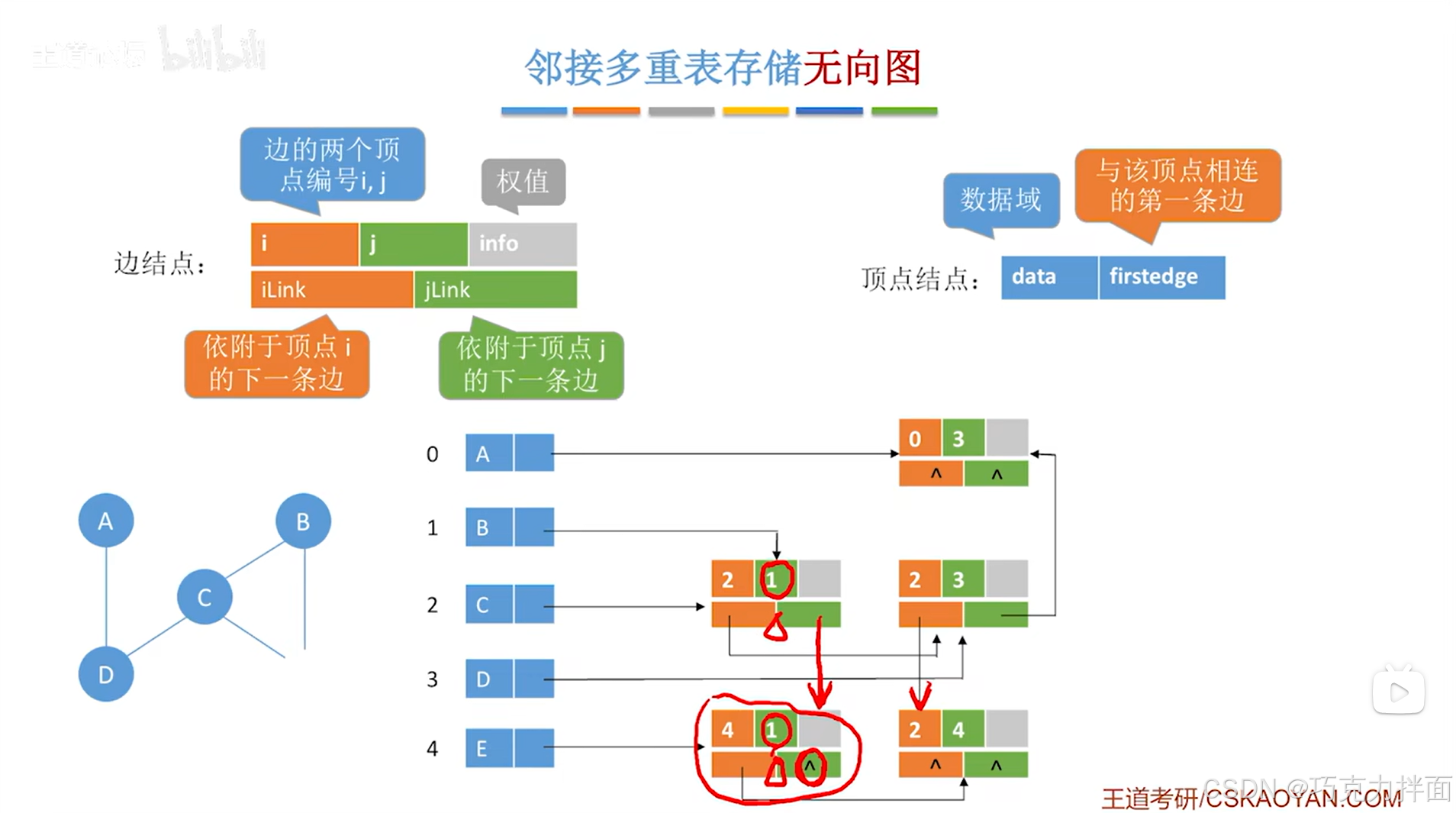
例如此时要删除顶点E,不仅要删除顶点E,还要删除和顶点E相连的所有边,顶点E在顺序表的4索引上,通过顶点E的firstedge指针可以找到和顶点E相连的所有的边,因此把这些边对应的边结点都删除,删除这些边结点会导致某些指针的指向出现问题,本例中出问题的指针分别是顺序表中2索引对应的C顶点和1索引对应的B顶点的边结点的jLink指针,顺序表中2索引对应的C顶点和3索引对应的D顶点的边结点的iLink指针->对于顺序表中2索引对应的C顶点和1索引对应的B顶点的边结点的jLink指针,jLink指针指的是依附于顶点j的下一条边,此时顶点j是B顶点,因此jLink指针指向和顶点B相连的下一条边,而此时和顶点B相连的下一条边已经没有了(这个可以通过被删除的边结点得知),所以jLink指针指向NULL,另外出问题的iLink指针同理:
b.总结:
-
邻接多重表的空间复杂度优于邻接表,因为邻接多重表中不需要存储冗余的边
-
和邻接表相比,在邻接多重表中进行边或顶点的删除等操作都会很方便
-
邻接多重表存储无向图是非常优秀的
-
邻接多重表只适用于存储无向图
三.总结:

-
十字链表法只能存储有向图,解决了邻接矩阵法存储有向图时空间复杂度高的问题,同时解决了用邻接表存储有向图时找入边不方便的问题
-
邻接多重表只能存储无向图,解决了邻接矩阵法存储无向图时空间复杂度高的问题,同时解决了邻接表中进行无向图的边或顶点的删除等操作繁琐的问题,也解决了邻接表中在存储无向图时存储冗余的边的问题

















 1342
1342

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









