




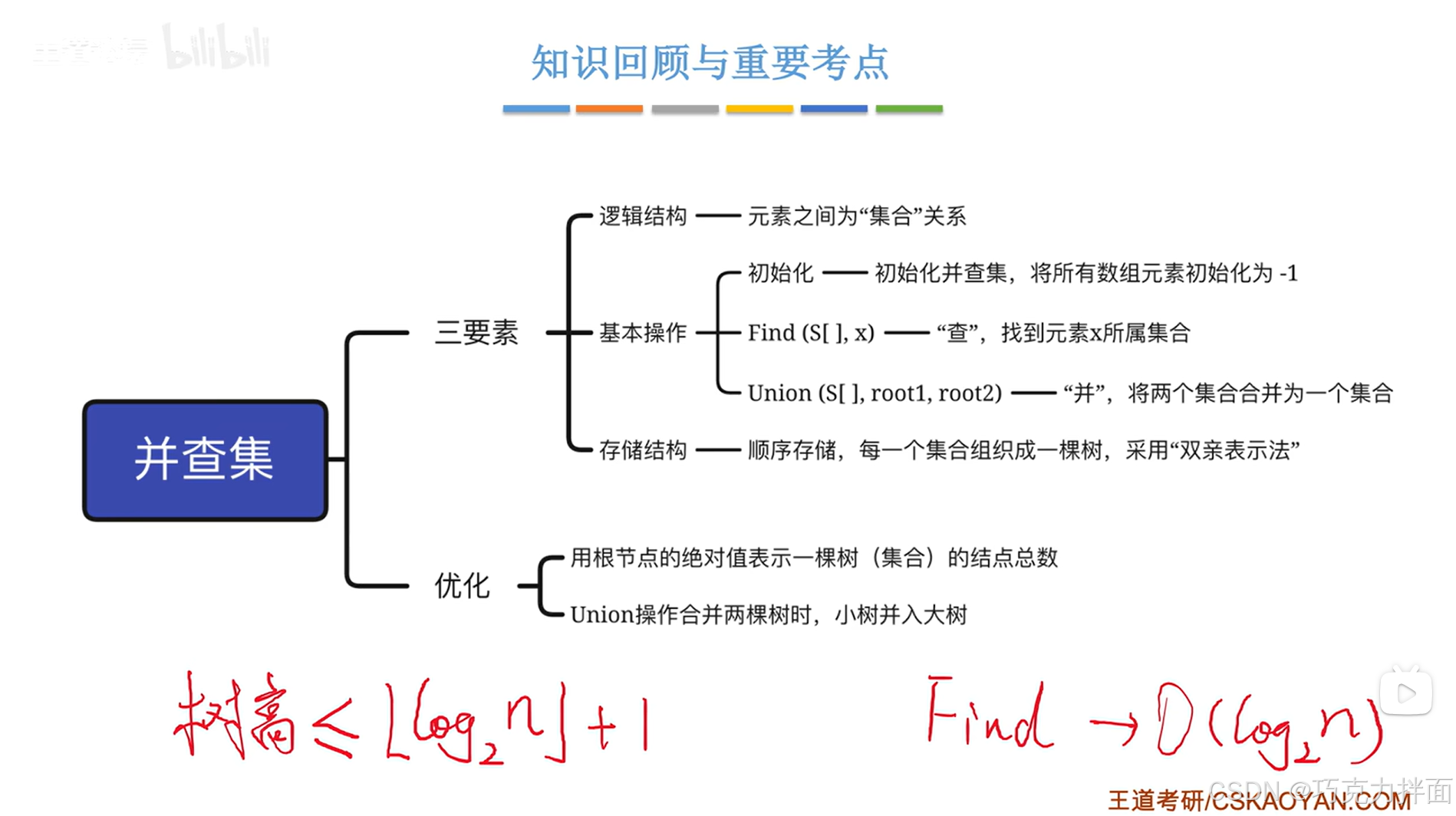
一.并查集概述:
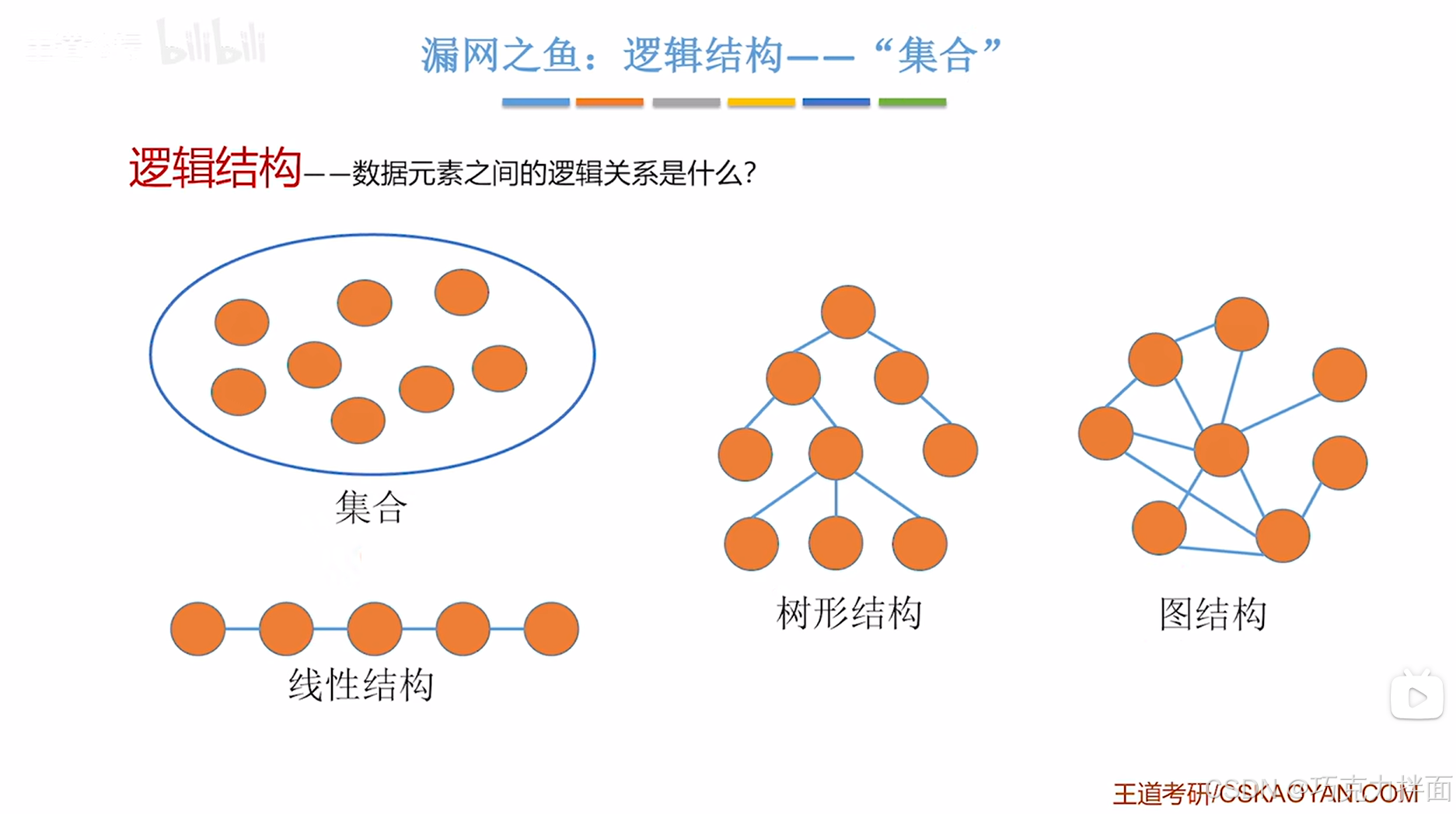
1.并查集本质上是一个表示集合的逻辑关系:
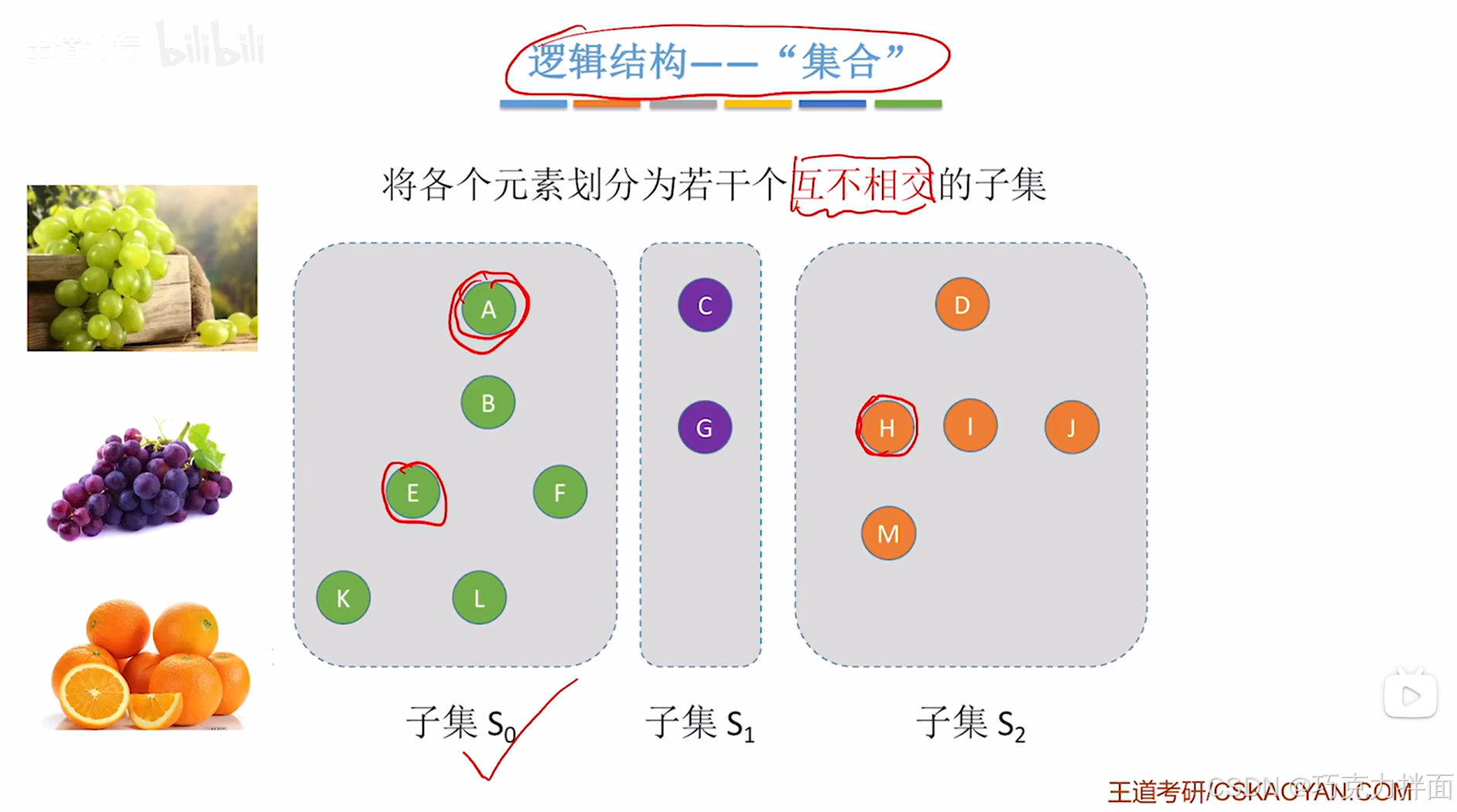
假设集合S代表同学的集合:
可以根据不同的规则如每个同学喜爱吃的水果对集合S进行划分为多个子集:
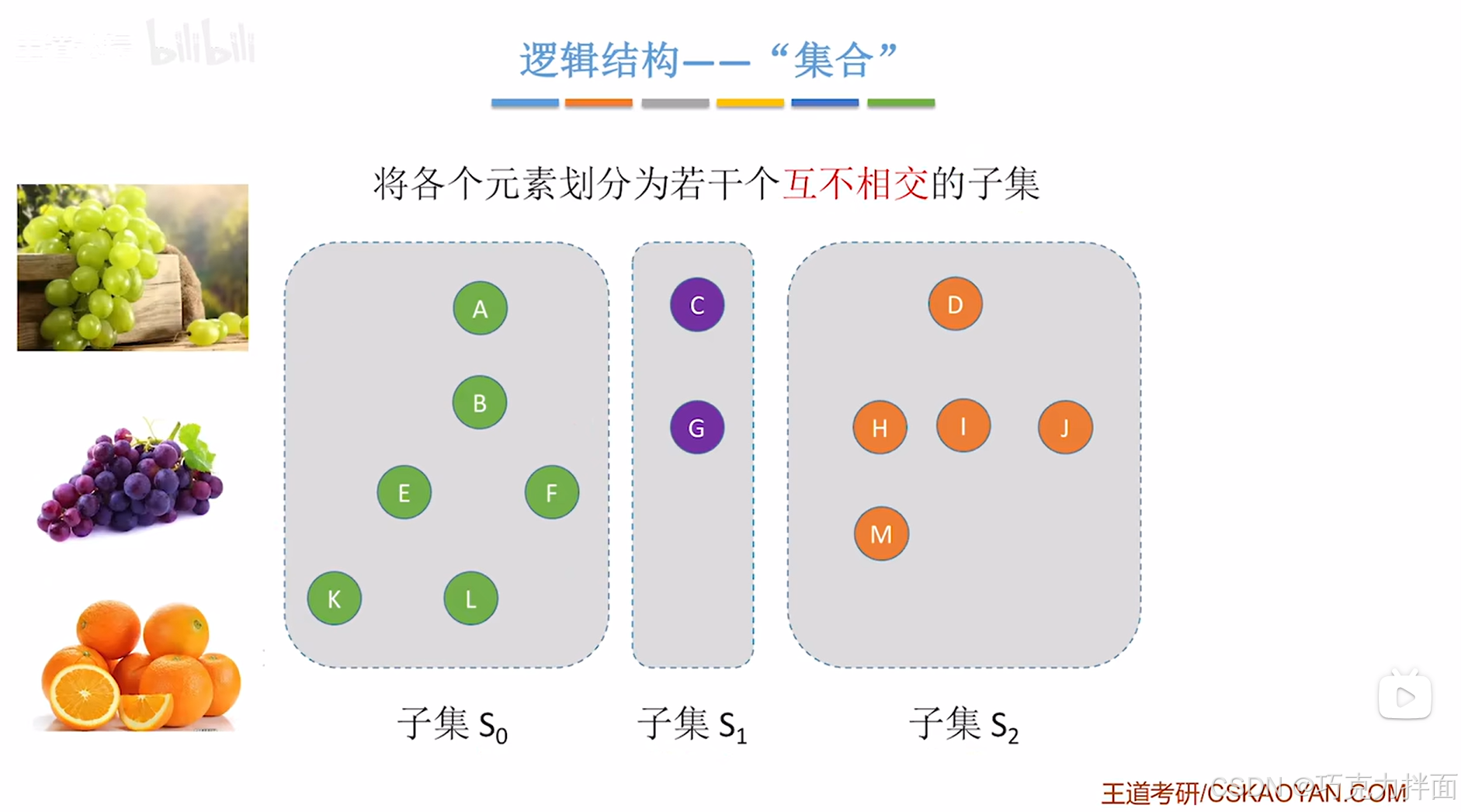
各个子集间互不相交,如果从第一个子集中挑出A和E,第三个子集中挑出H,A和H之间的关系就是不属于同一个集合,A和E的关系是属于同一个集合,所以在集合这个逻辑结构下,两个元素之间的关系要么属于同一个集合,要么属于不同的集合:
关键是集合如何使用代码实现呢?注:集合的子集是互不相交的,这个可以利用"森林"来实现,"森林"里的树就是互不相交的:
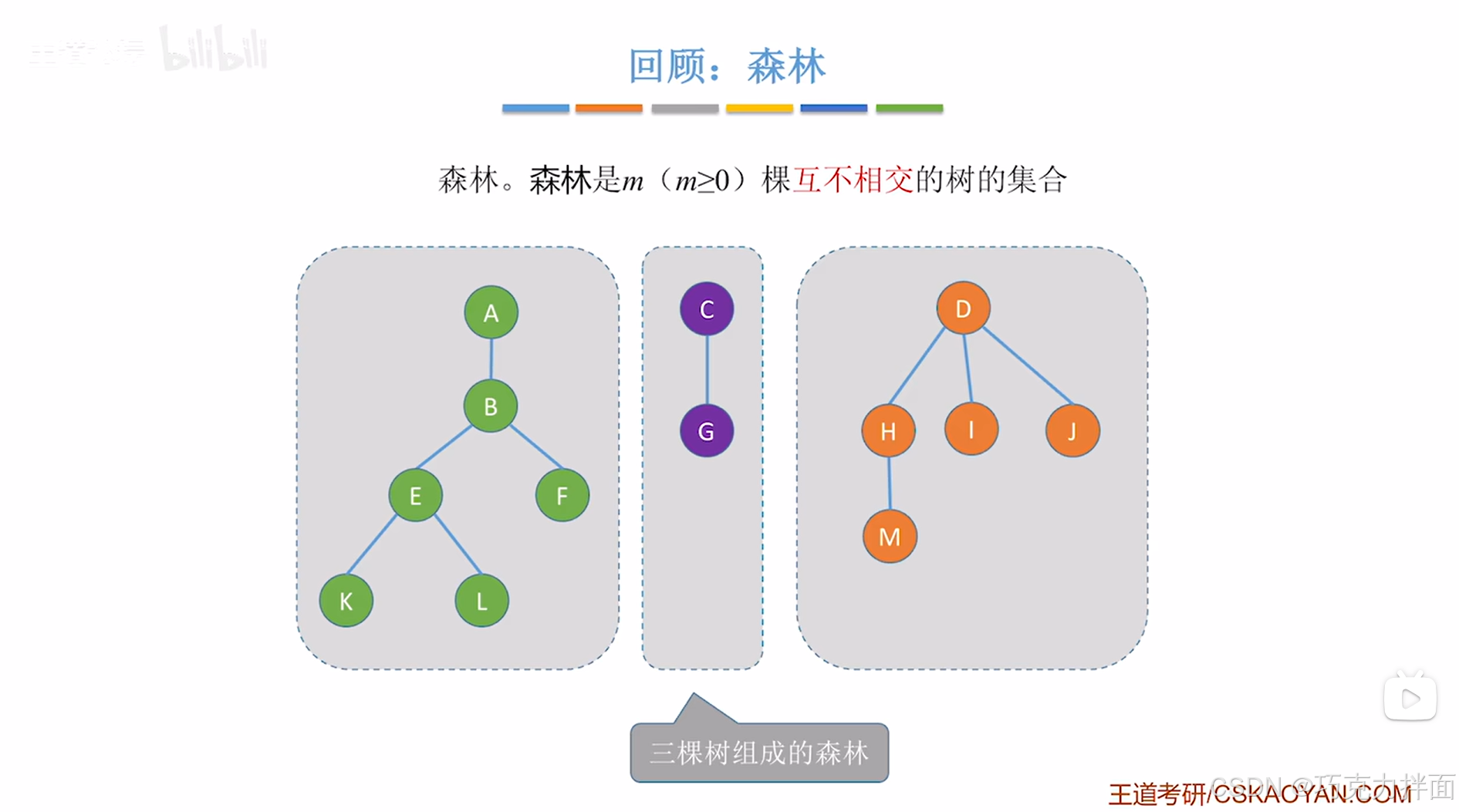
2."森林"该数据结构可以实现并查集:
利用"森林"来表达各个元素是否属于同一个集合,如果某些元素属于同一个集合,在物理结构上可以组织成树状结构,不同集合的元素放到不同的树即可:核心就是把同一个集合里的各个元素组织成一棵树
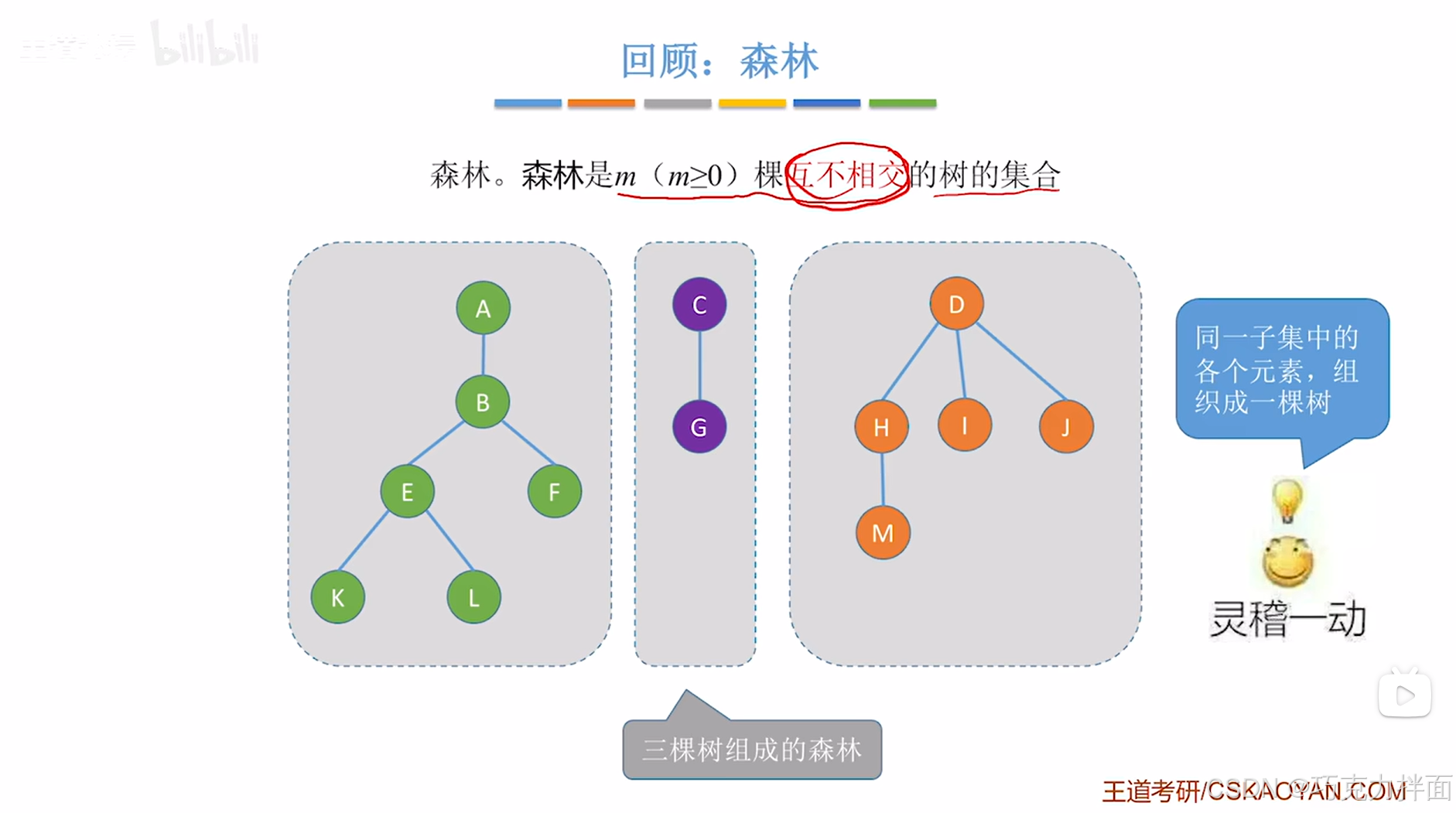
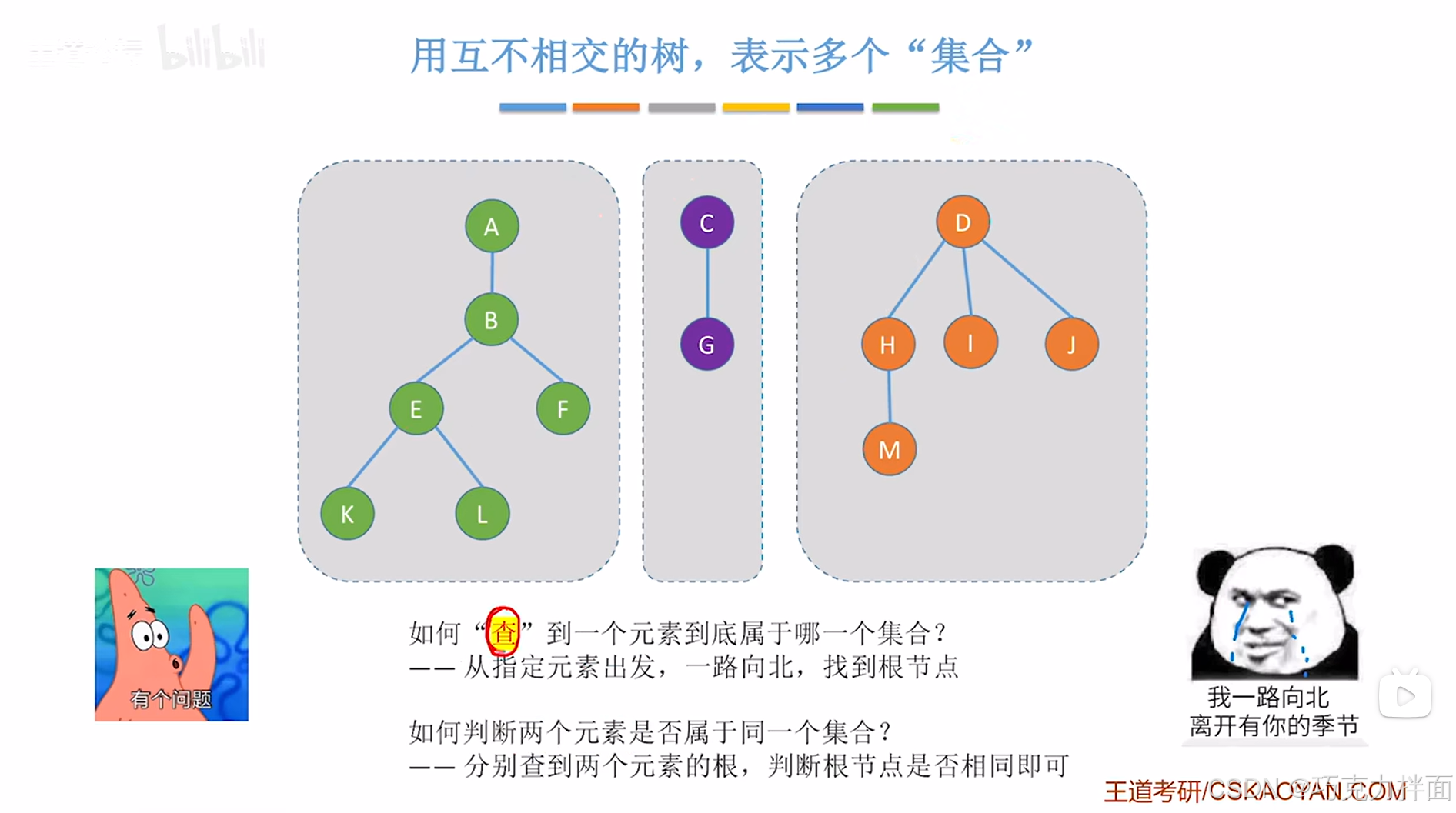
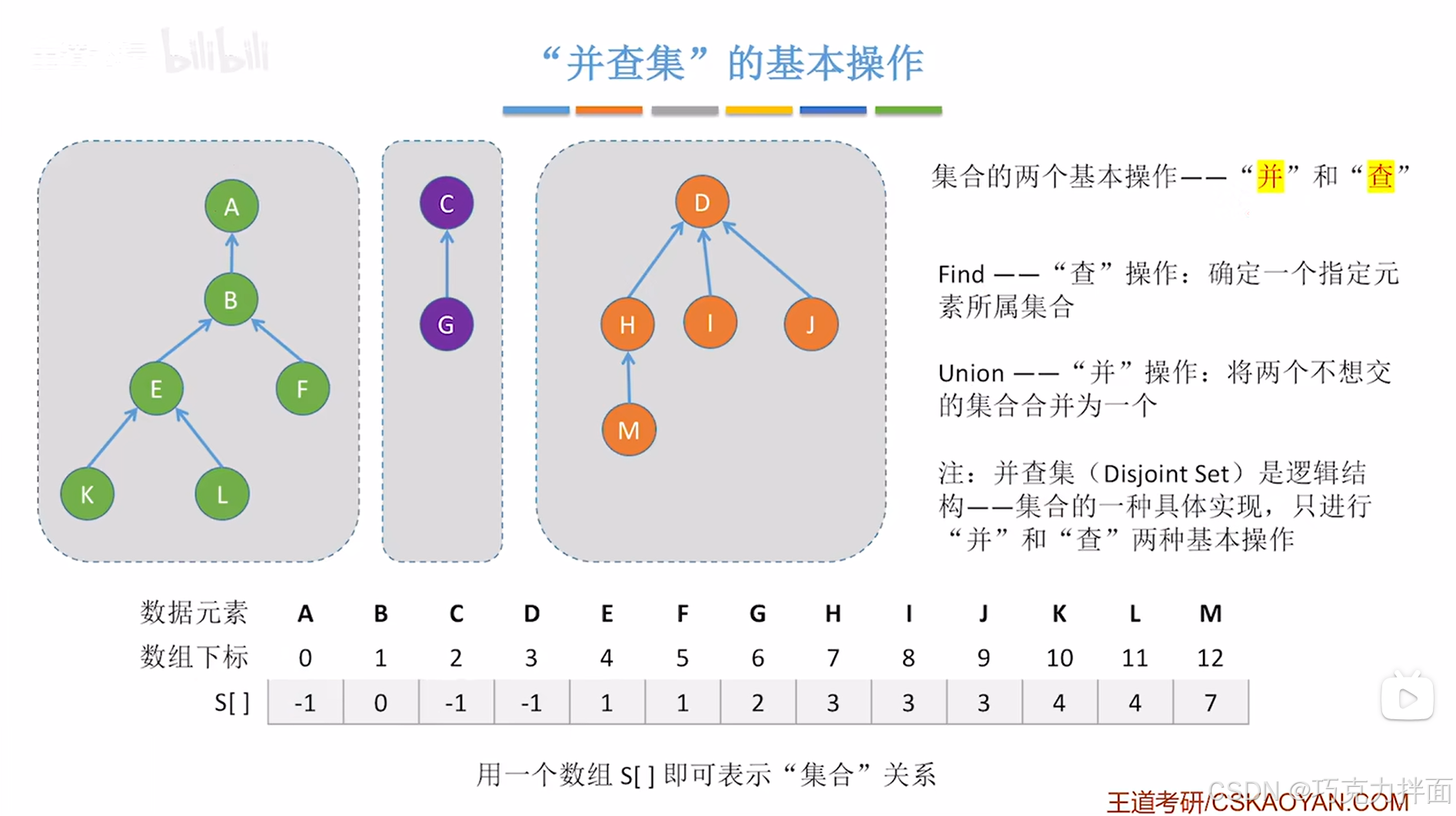
常见需求:比如指定一个元素,判断该元素属于哪个集合;指定两个元素,判断这两个元素是否属于同一个集合->这类操作称为"查"到一个元素到底属于哪一个集合,这类操作的实现并不难,其中所有的元素都被组织成若干棵互不相交的树。
3.常见问题:"查"与"并"
问题一:指定一个元素,判断该元素属于哪个集合
要判断某个元素属于哪个集合,是否可以尝试先找到该元素所在树的根结点,只要找到该根结点,就可以指定该元素属于哪一个集合了(有几个根结点,就有几棵树,就有几个互不相交的集合):
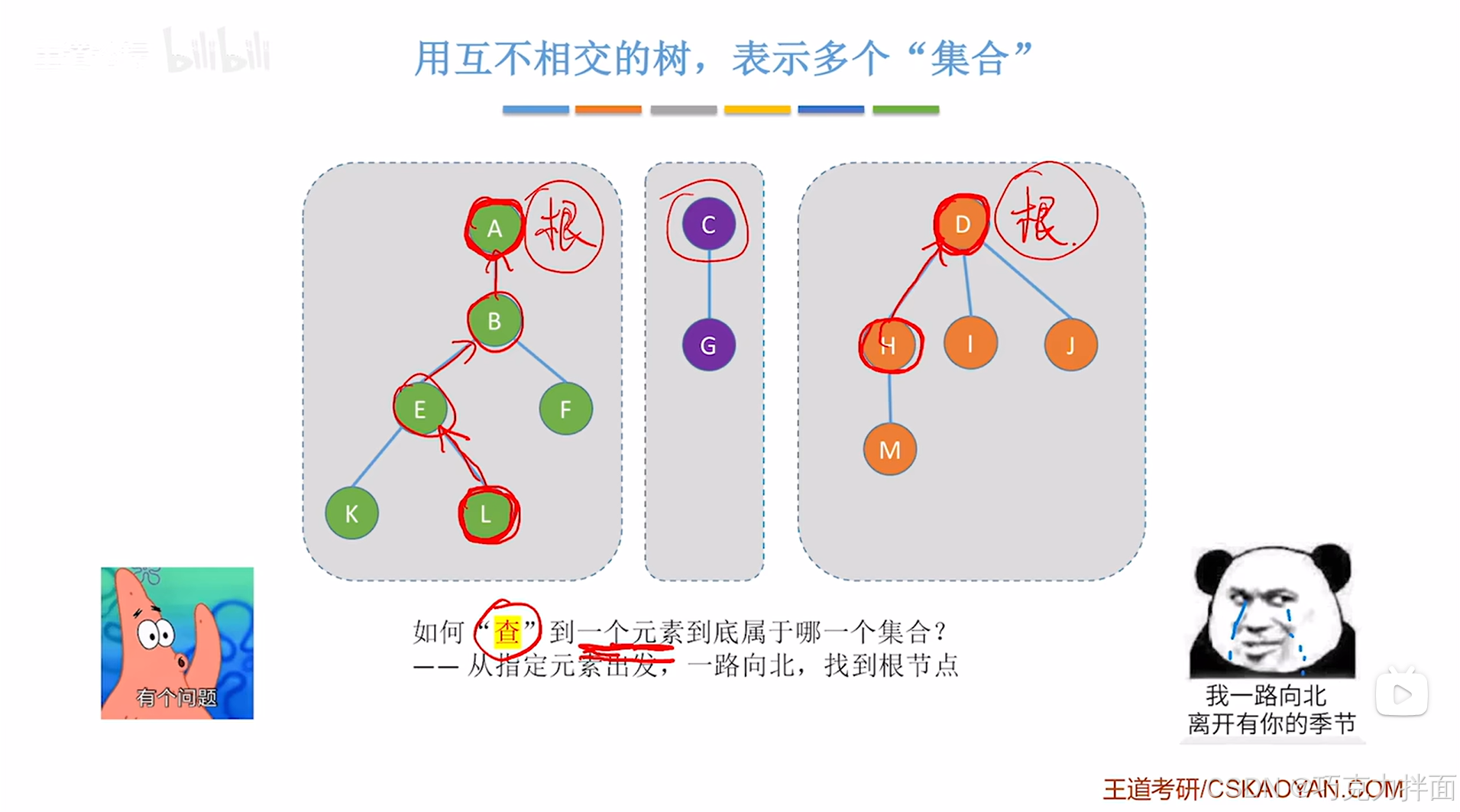
问题二:指定两个元素,判断这两个元素是否属于同一个集合
判断两个元素是否属于同一个集合的思路:分别查找两个元素所在树的根结点,对比这两个根结点是否相等,如果相等,那么这两个元素属于同一个集合,如果不相等,那么这两个元素就不属于同一个集合
问题三:何如把两个集合"并"为一个集合
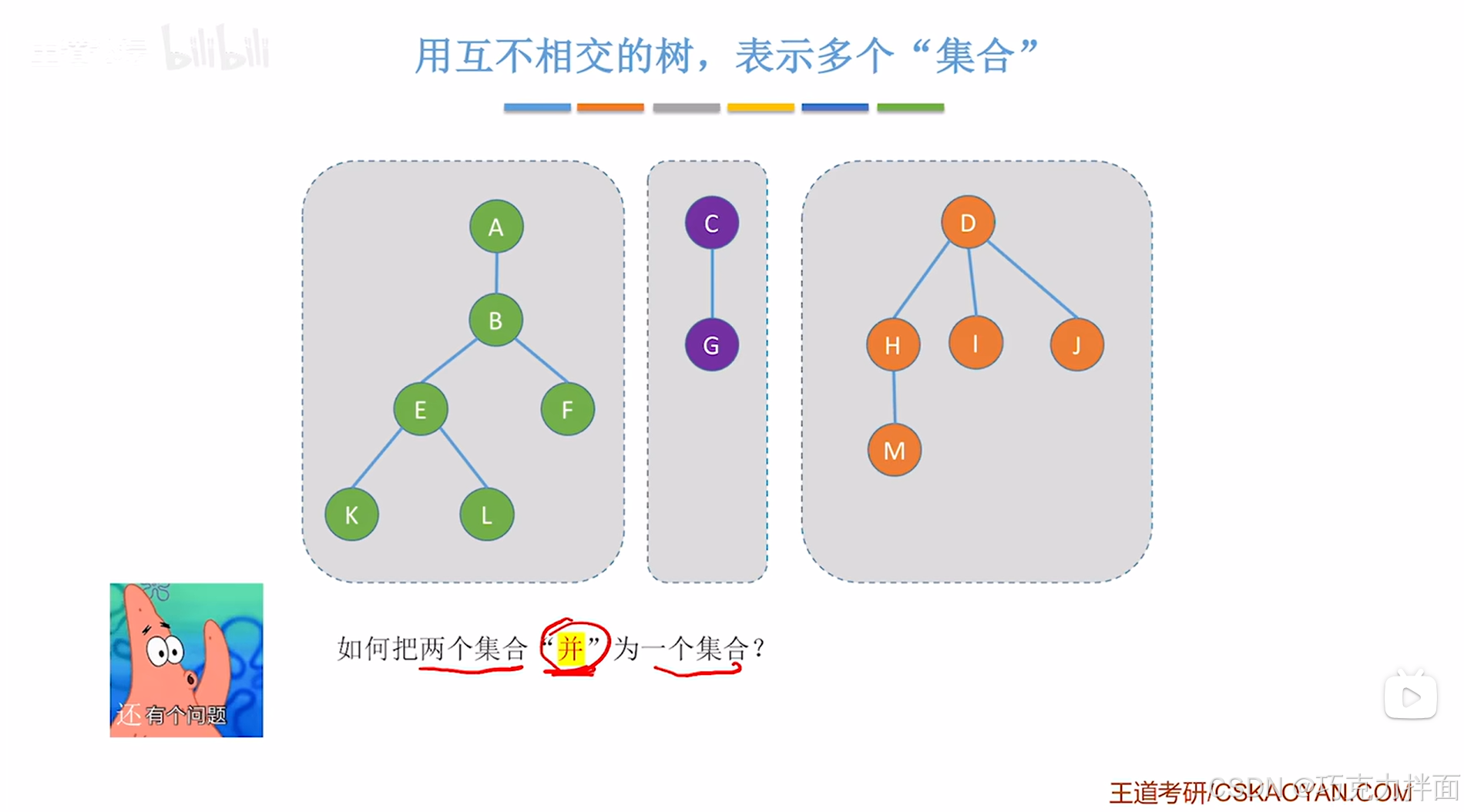
只需要把一棵树成为另一棵树的孩子即可:
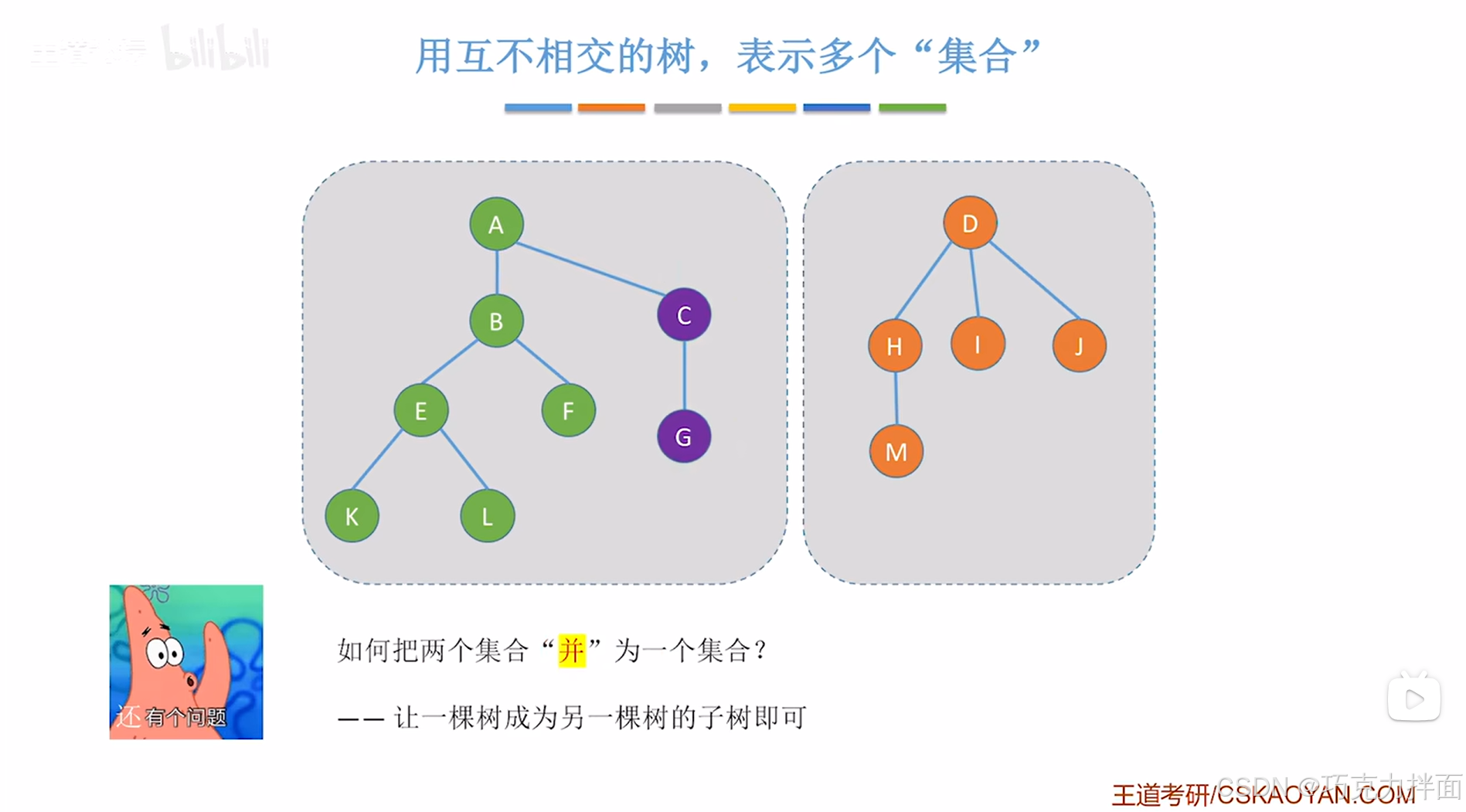
"树"可以利用双亲表示法(即孩子结点指向父结点)和孩子表示法(即一个结点后面会连接链表,链表会包含该结点的孩子结点)以及孩子兄弟表示法(即对应为一棵二叉树)来存储,并查集包含了若干棵树,那么并查集里的树应该用双亲表示法,孩子表示法还是孩子兄弟表示法来存储呢?
显然双亲表示法会更好一些,因为在"查"操作中,要多次找父结点直至根结点,在"并"操作中,只需要修改一棵树的根结点的父结点指针即可和另一棵树"并"为一个树即集合,所以双亲表示法更合适。
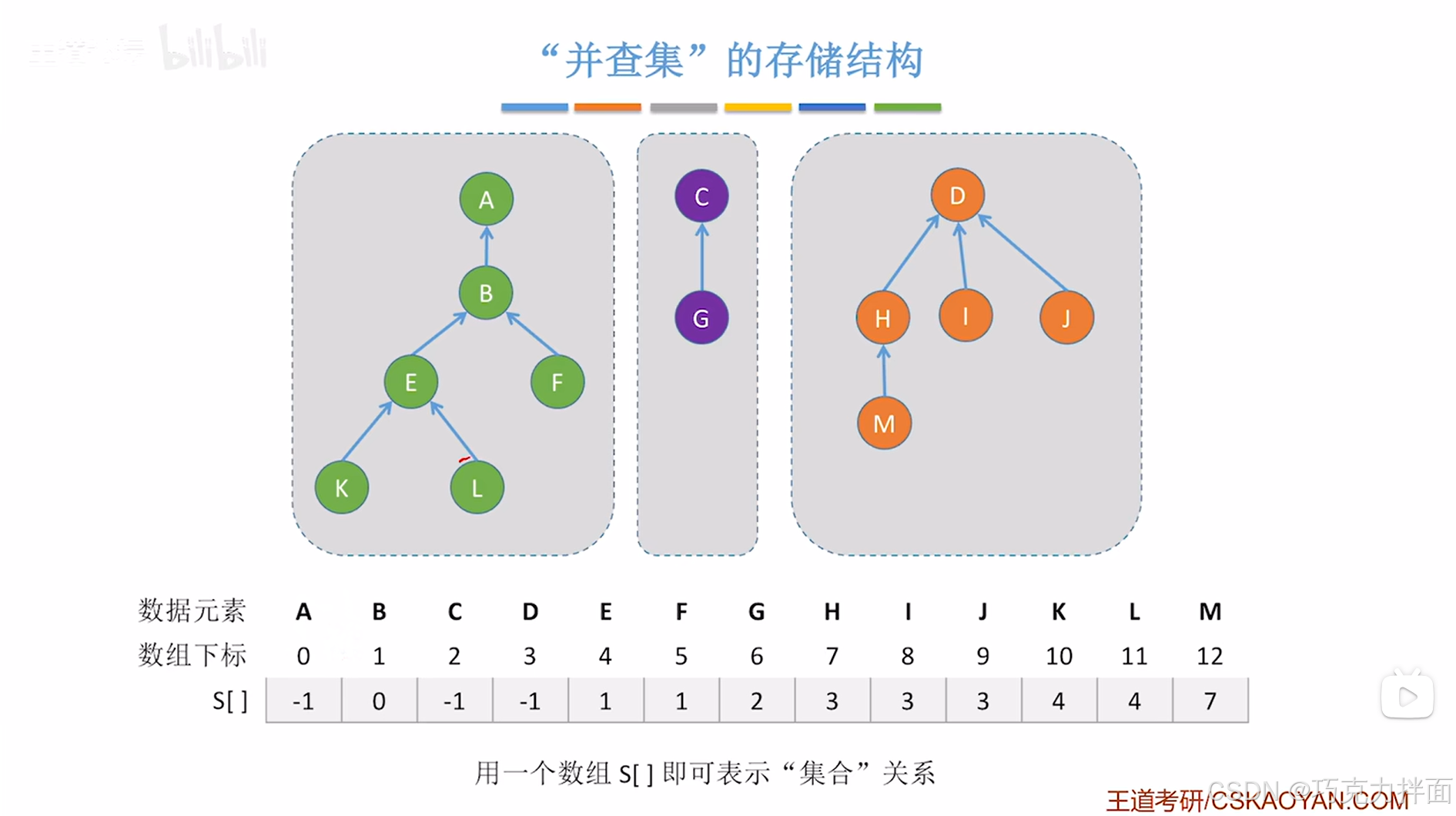
4.并查集使用双亲表示法更合适:
复习双亲表示法:A结点没有父结点,所以parent小于0,可以用-1,B的父结点为A结点,A结点的索引为0,所以B的parent为0,以此类推
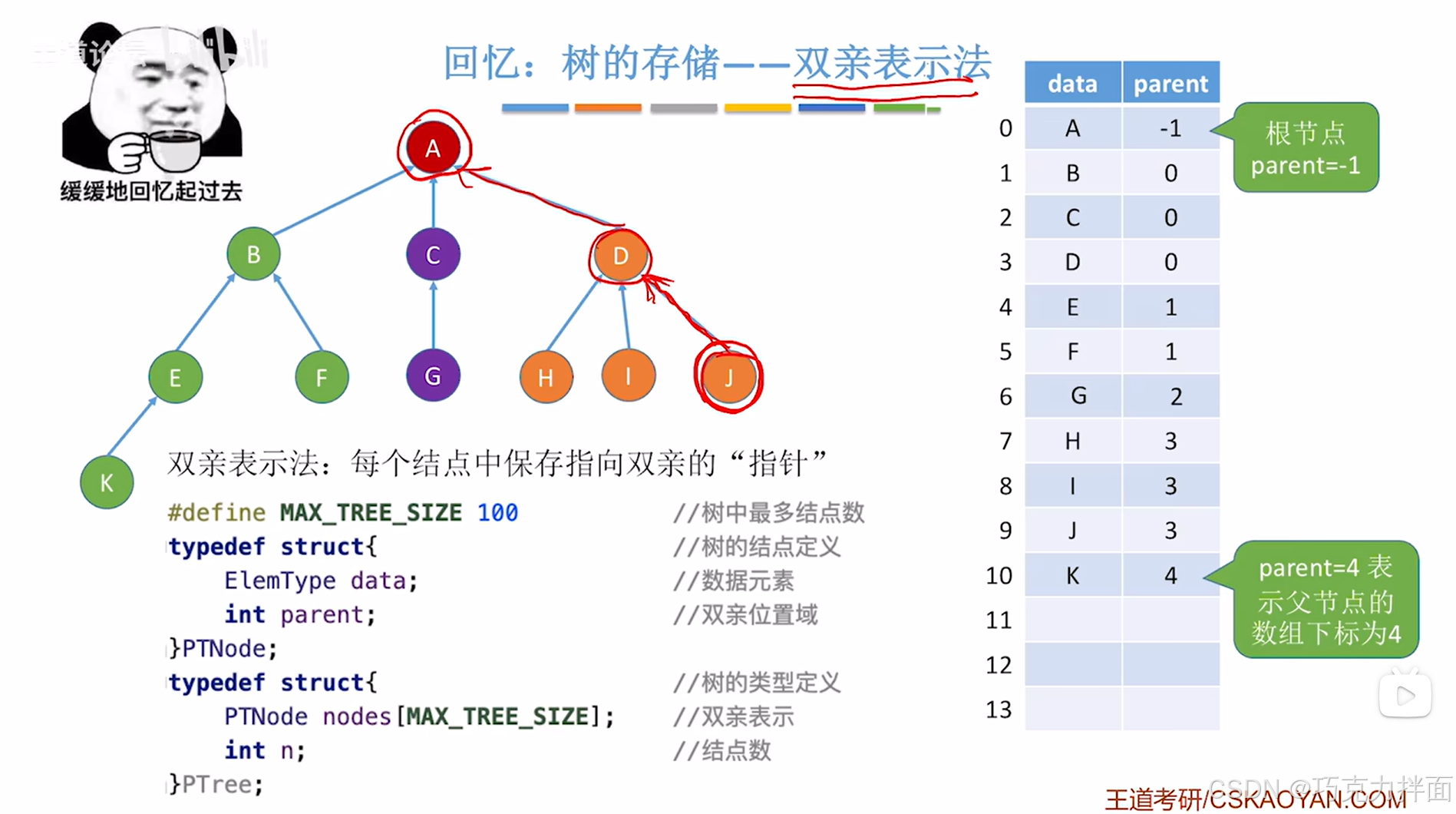
实例:
-
S数组存储的是当前数据元素的父结点在S数组的索引
-
L结点的父结点为E结点,由于E结点在S数组中的索引为4,所以L结点在S数组中对应的数据为4
-
对于n个数据元素,只需要申明一个长度为n的整型数组,用该数组可表示出集合关系,本质就是树的双亲表示法
5."并查集"的基本操作:
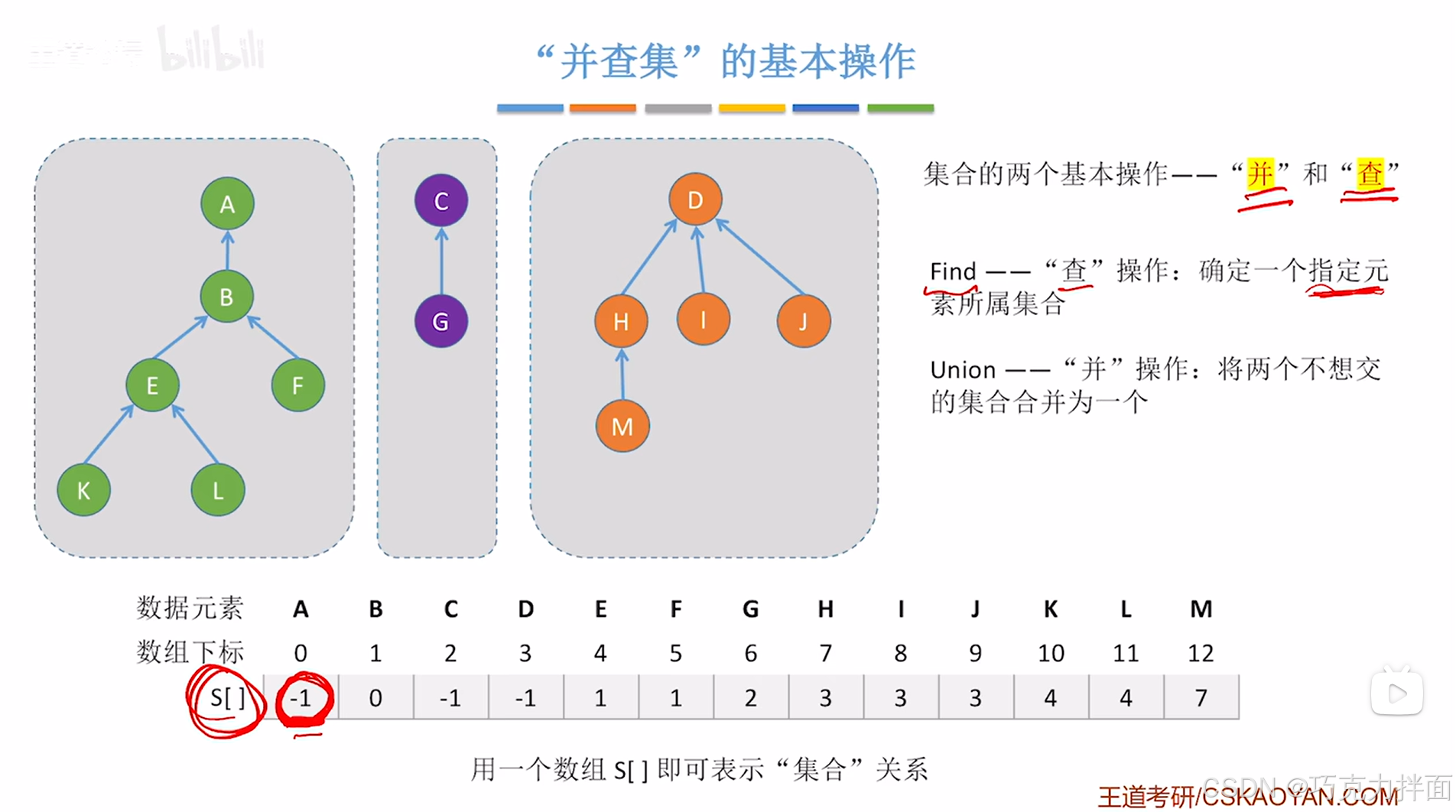
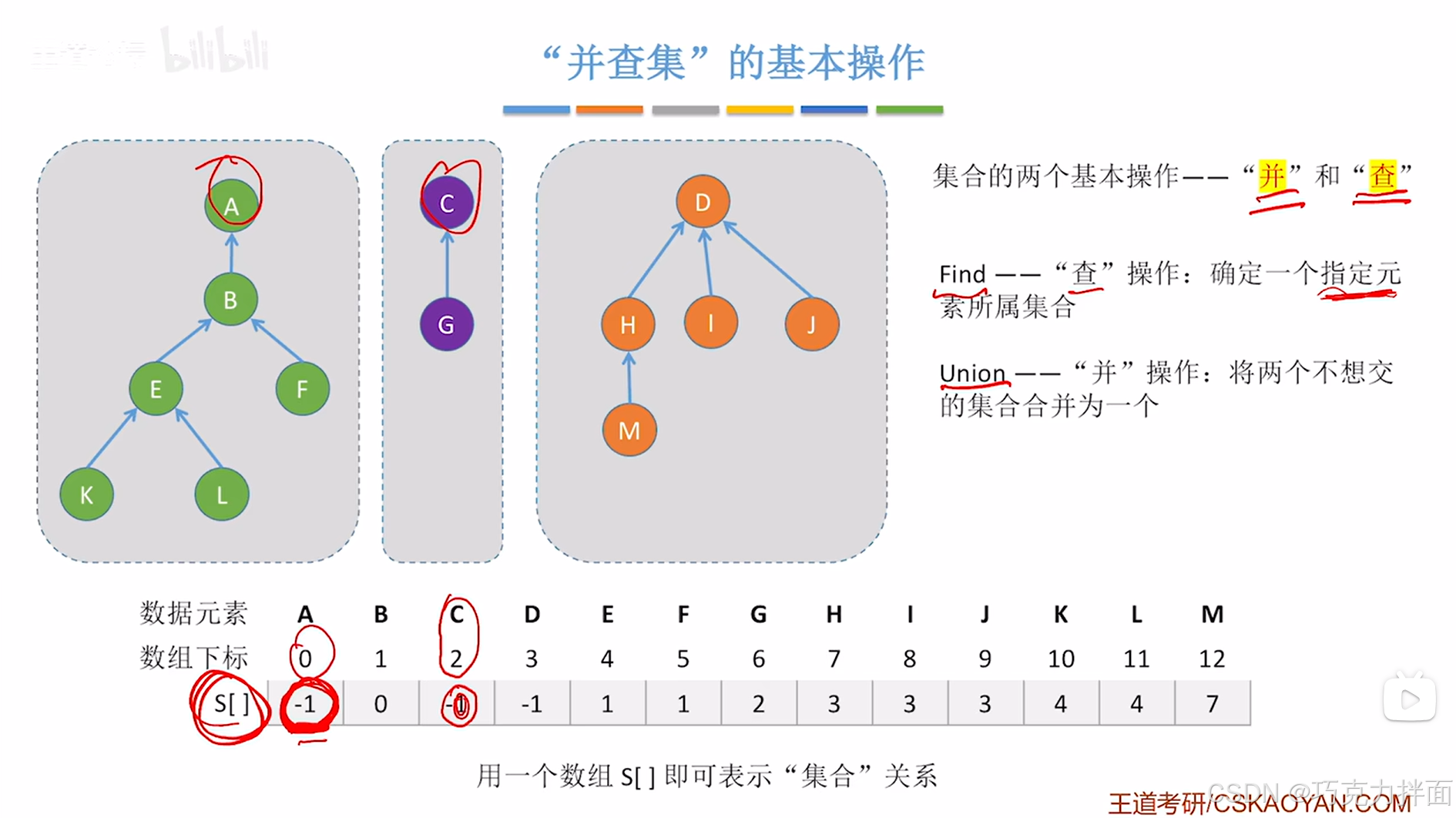
"查"操作:只需要利用上述图片中的S数组(S数组是自己定义的,用来表示出集合关系)从要查找的结点开始一直往上找父结点,直至找到根结点即该结点在数组S中存储的值小于0,就可以确定指定结点所属集合
"并"操作:比如要把根结点为A结点的树和根结点为C结点的树合并为一棵树,只需要把C结点在S数组中的值修改为A结点在S数组中的索引即可,也就是把A结点当作C结点的父结点,此时C结点在S数组中的值为0
6.总结:
二."并查集"的代码实现:
1."并查集"的初始化:
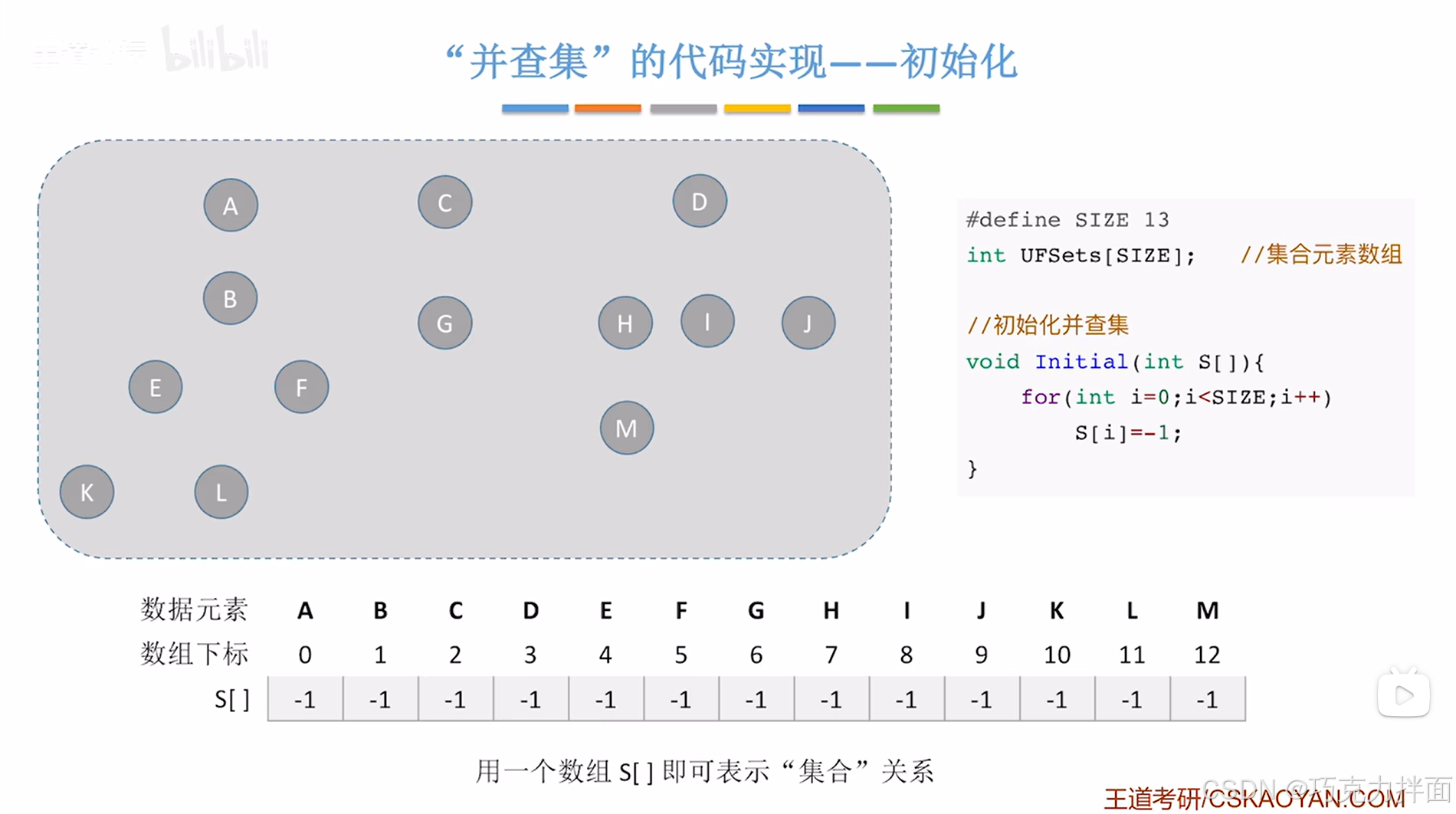
-
存储集合元素的父结点的索引的数组,定义为整型即可
-
因为一开始无法得知各个结点是否属于同一个集合,也就无法找到父结点,所以可以把各个结点初始化为各自独立的多个子集,因此可以把各个结点在S集合中的值设为-1(小于0),表示各个结点之间互相独立
#include<stdio.h>
#define SIZE 13
int UFSets[SIZE]; //存储集合元素的父结点的索引的数组,定义为整型即可
//初始化并查集
void Initial(int S[])
{
for(int i=0;i<SIZE;i++)
{
S[i]=-1;
/*因为一开始无法得知各个结点是否属于同一个集合,
也就无法找到父结点,所以可以把各个结点初始化为各自独立的多个子集,
因此可以把各个结点在S集合中的值设为-1(小于0),表示各个结点之间互相独立*/
}
}
int main()
{
return 0;
}
2."并查集"的基本操作——并,查:
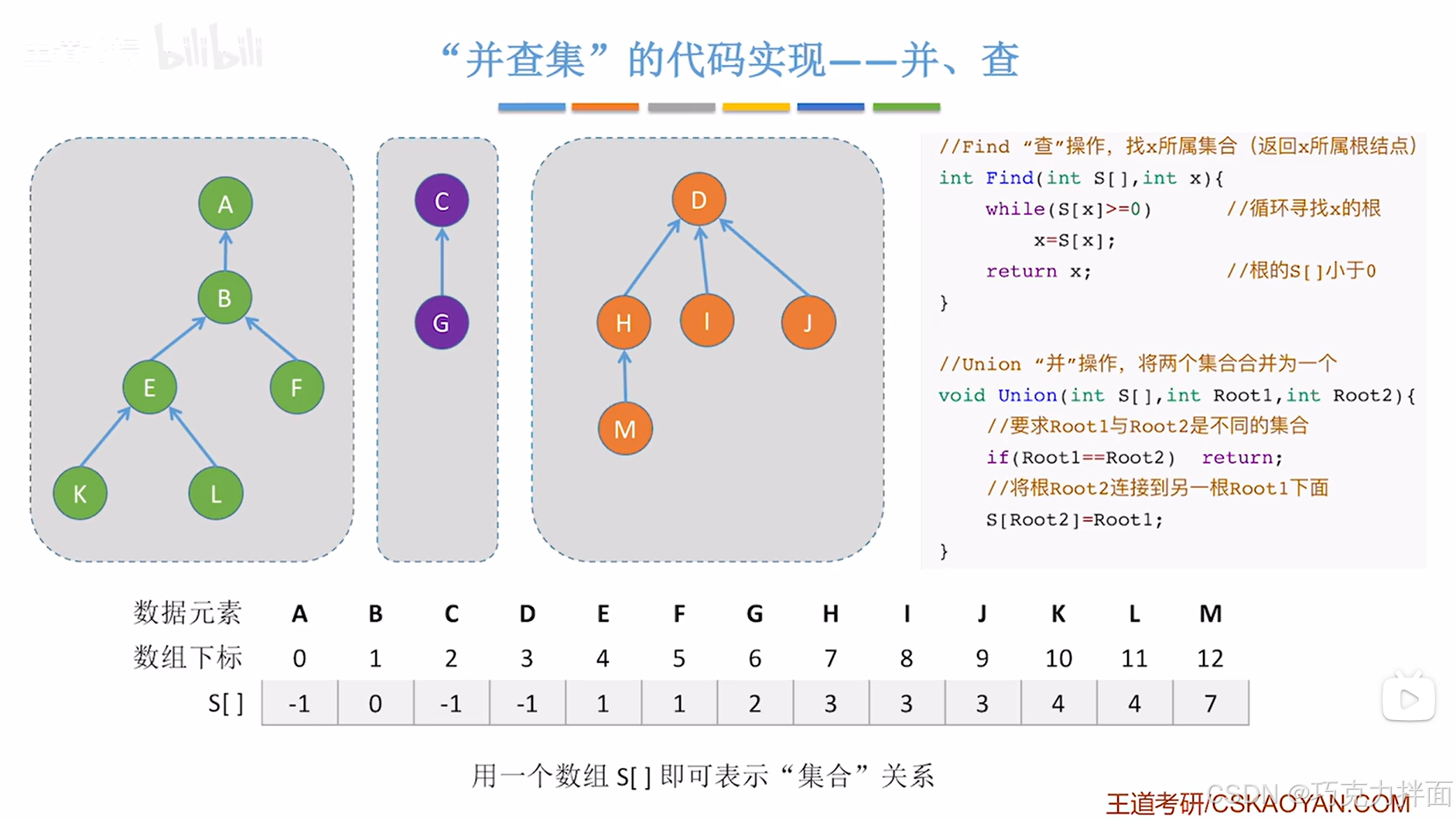
例1:找结点L即S数组中索引为11的元素所在树的根结点的索引,L结点对应的
S[11]为4,4是大于等于0的,根据x=S[x],就要检查索引4上的元素,
s[4]为1,1是大于等于0的,根据x=S[x],就要检查索引1上的元素,.
s[1]为0,0是大于等于0的,根据x=S[x],就要检查索引0上的元素,
s[0]为-1,-1小于0,此时找到了根结点,返回根结点的索引0,所以结点L就所属S[0]对应的结点即A所统领的树
例2:将根结点为A结点的树和根结点为C结点的树"并"为一棵树(核心:只需要把一个集合的根结点它所对应的数组的指针指向另一个集合的根结点即可),
可以将根结点为C结点的树看作是根结点为A结点的树的子树,
此时Root2为C结点在数组S中对应的索引即2,Root1为A结点在数组S中对应的索引即0,
执行S[Root2]=Root1即S[2]=0,这时S[2]的值为0,s[2]对应C结点,就代表C结点的父结点为S[0]即A结点
如果在两棵不同的树分别指定了一个结点,而且这两个结点都不是根结点,要想和"并"这两棵树,就需要先通过这两个结点分别"查"找到两棵树的根结点,在进行和"并"这两棵树。
#include<stdio.h>
//Find"查"操作,找结点所属树即集合(返回该结点所属树的根结点的索引)
int Find(int S[],int x)
{
/*此时要操作的结点在数组S中对应的索引为x,S[x]就是要操作的结点的父结点在数组S中的索引,
利用while循环寻找要操作的结点所在树的根结点的索引 */
while(S[x]>=0) //S[x]就是要操作的结点的父结点在数组S中的索引
{
/*当S[x]>=0时,因为根结点在S数组中的值小于0,代表此时没有找到根结点,
由于没有找到根结点,就需要把此时所对应的结点的父结点在数组S的索引赋值给x,
S[x]就是要操作的结点的父结点在数组S中的索引,即向上找父结点*/
x=S[x];
}
/*跳出while循环时说明S[x]小于0,由于根结点在S数组中的值小于0,
说明此时找到了根结点,返回根结点的索引x*/
return x;
}
//Union"并"操作,将两个集合合并为一个集合
void Union(int S[],int Root1,int Root2)
{
//要求Root1与Root2是不同的集合
/*注:Root1与Root2分别代表两个集合的根结点在数组S中的索引*/
if(Root1==Root2) return; //根结点相等的树说明是同一棵树,无需合并,直接结束循环
//将根Root2连接到另一根Root1下面
/*将根Root2连接到另一根Root1下面,说明索引Root2对应的结点的父结点为索引Root1对应的结点,
由于除了第一次外S[]是某结点的父结点在数组S中的索引,所以S[Root2]=Root1*/
S[Root2]=Root1;
}
int main()
{
return 0;
}
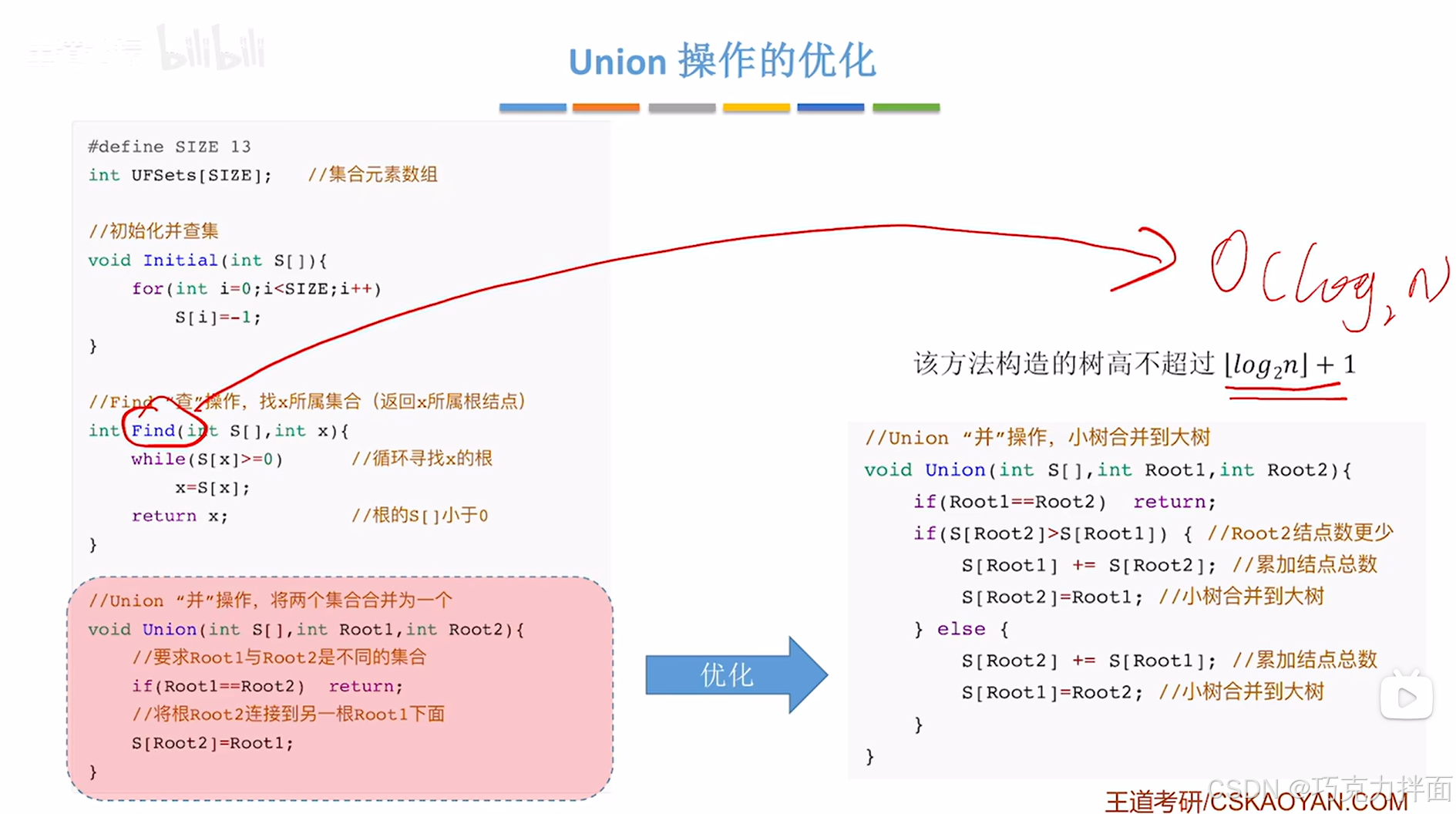
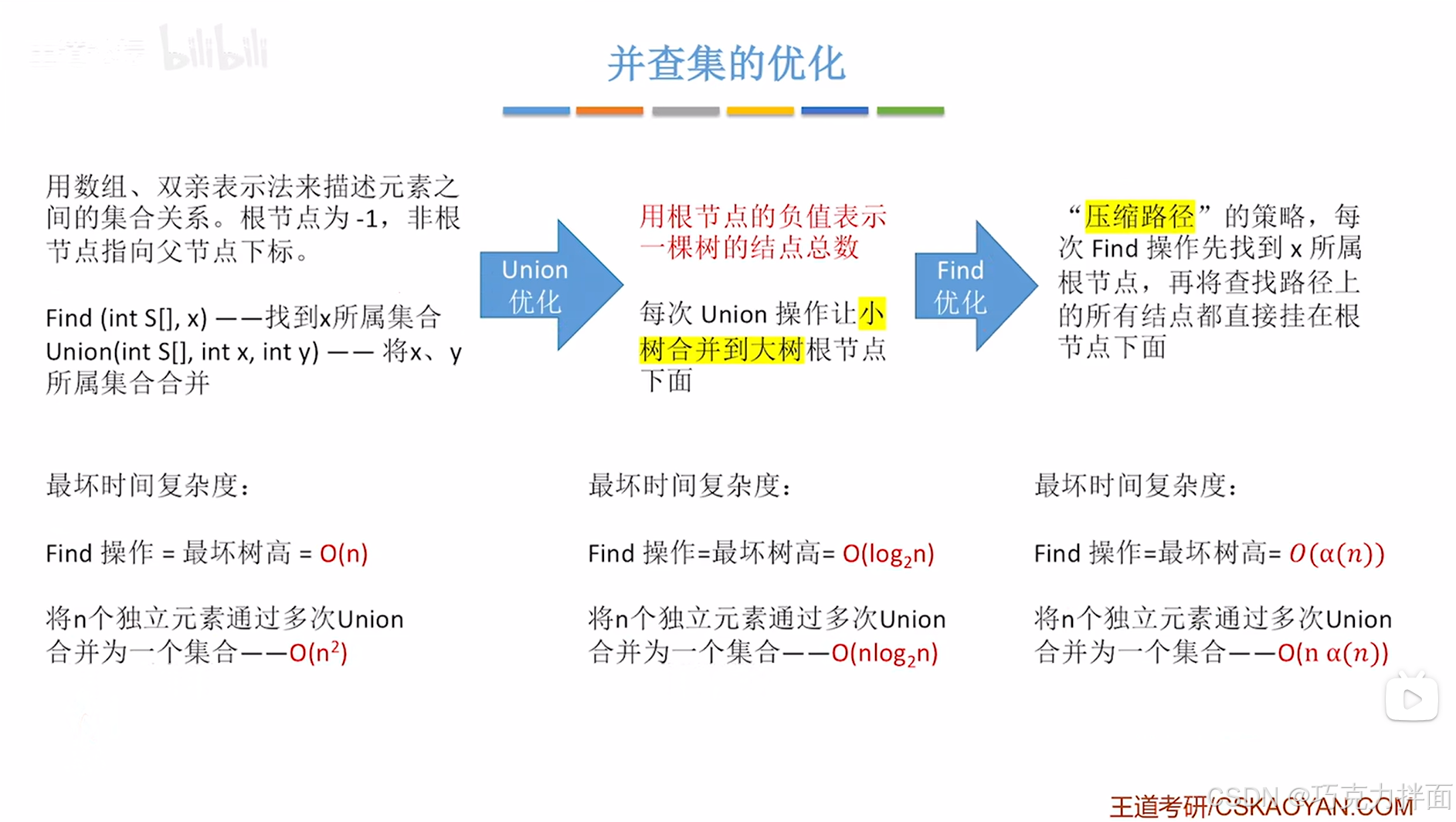
三."并查集"的时间复杂度分析:
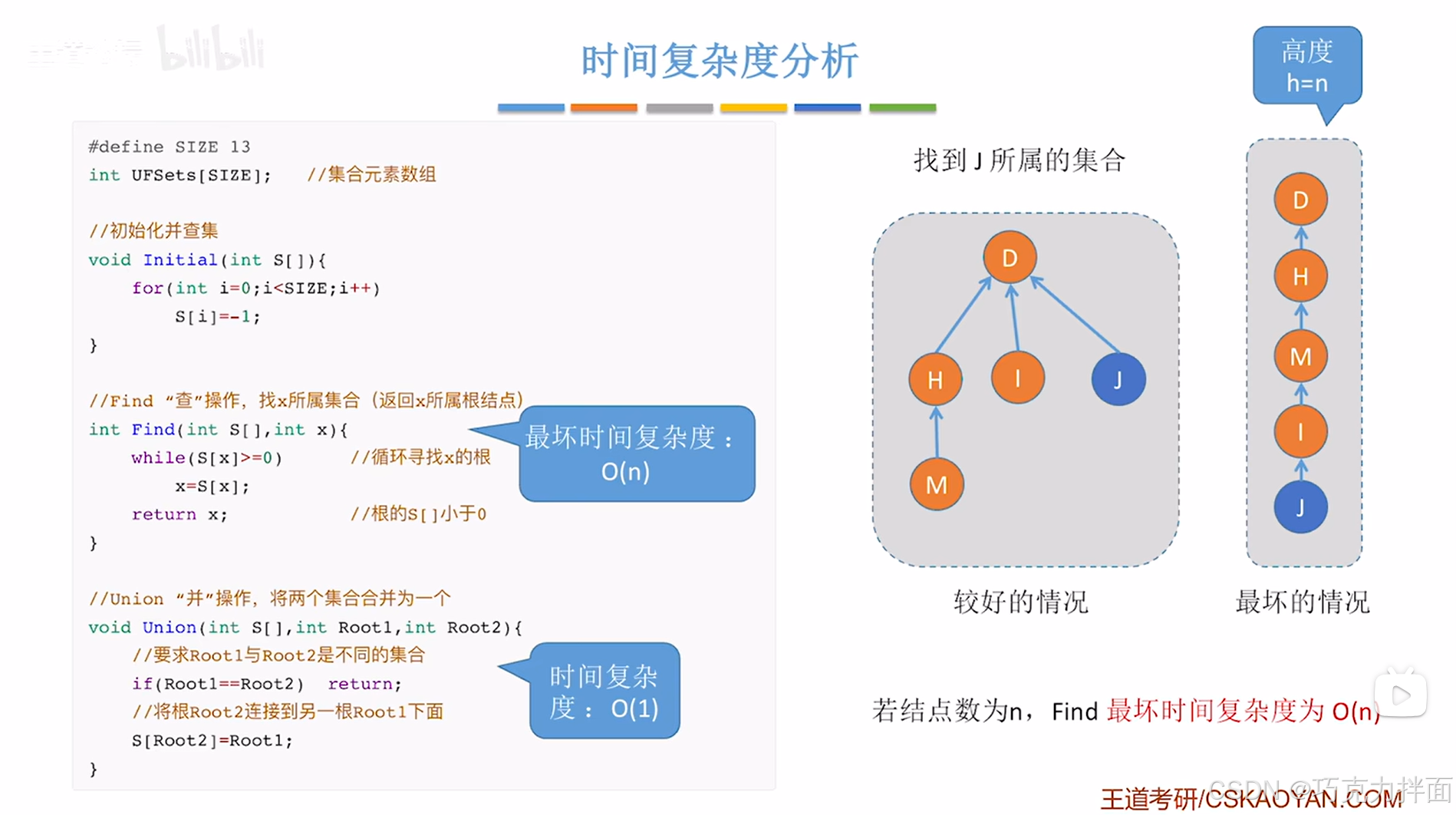
"并"操作没有循环,所以时间复杂度为O(1);
"查"操作中用到了while循环,
最好的情况是找0次即此时的结点就是根结点,直接得出所属集合,此时时间复杂度为O(1),
最坏的情况是把所有结点都找了一遍才找到根结点(见上述图片),如果有n个结点,就需要找n次,此时时间复杂度为O(n),
由此可知"查"操作最坏时间复杂度为O(n),
而达到最坏时间复杂度,就意味着树的高度为n,因此可得出最坏时间复杂度的开销和树的高度相关,由此可知,如果想要优化"并查集"的效率,能否在构造树时,让这棵树的高度尽可能矮一些,这样就可以降低"查"操作的最坏时间复杂度
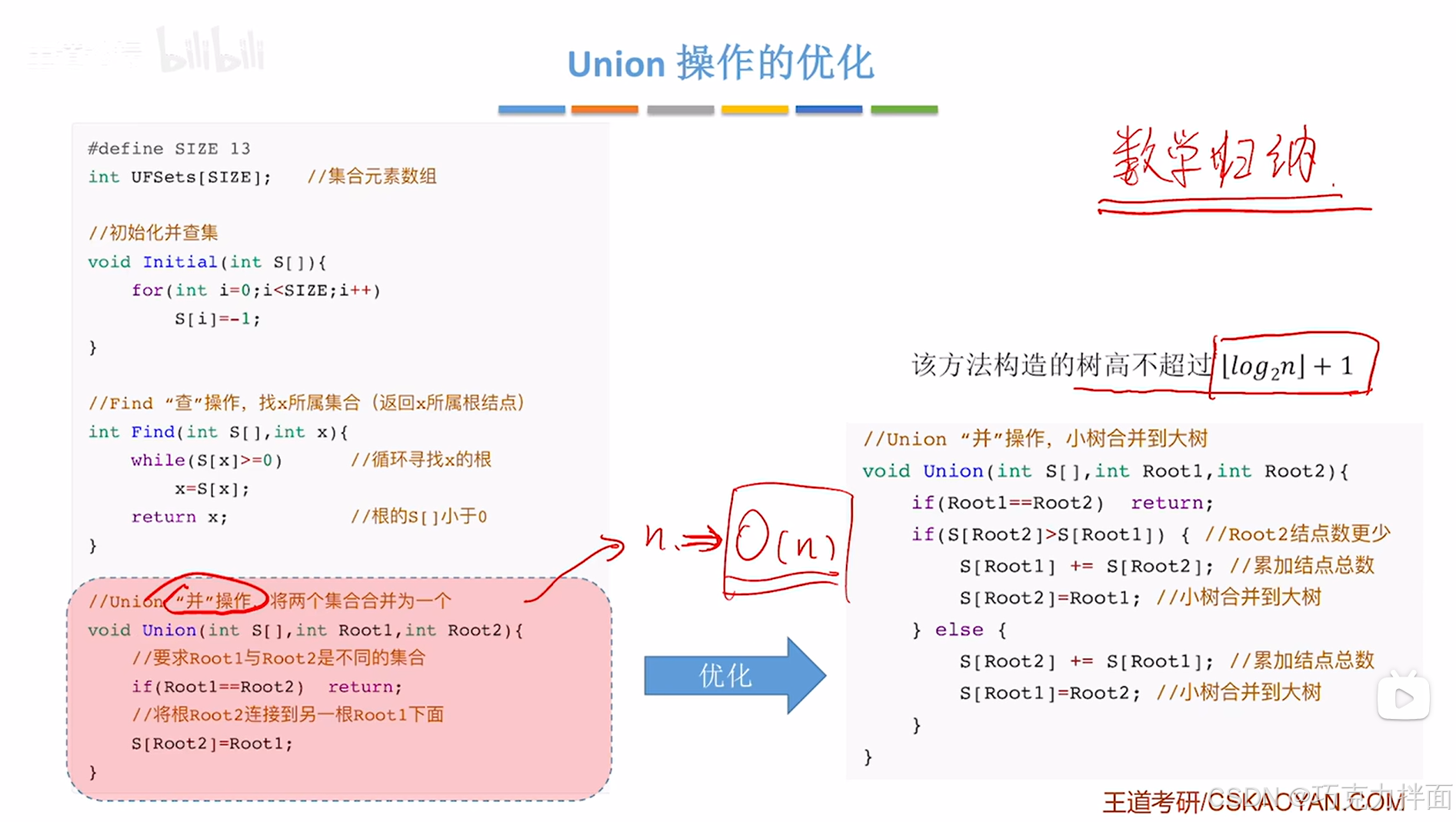
四."并查集"中"并"操作的优化:
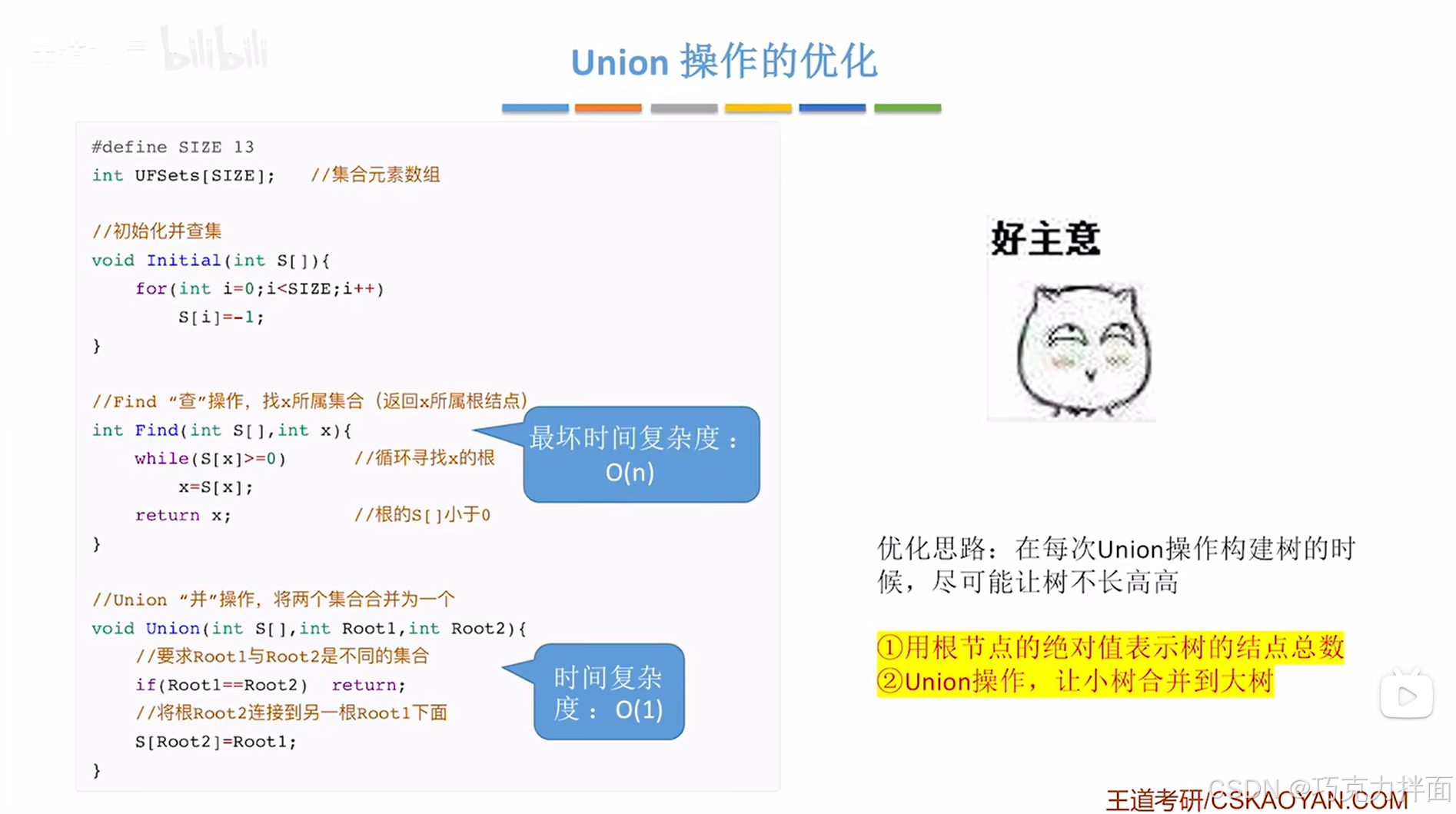
1."并"操作:让小树合并到大树:
尽可能和"并"两棵树后高度不要增加。
例如:
左边的大树高度为3,右边的小树高度为2:
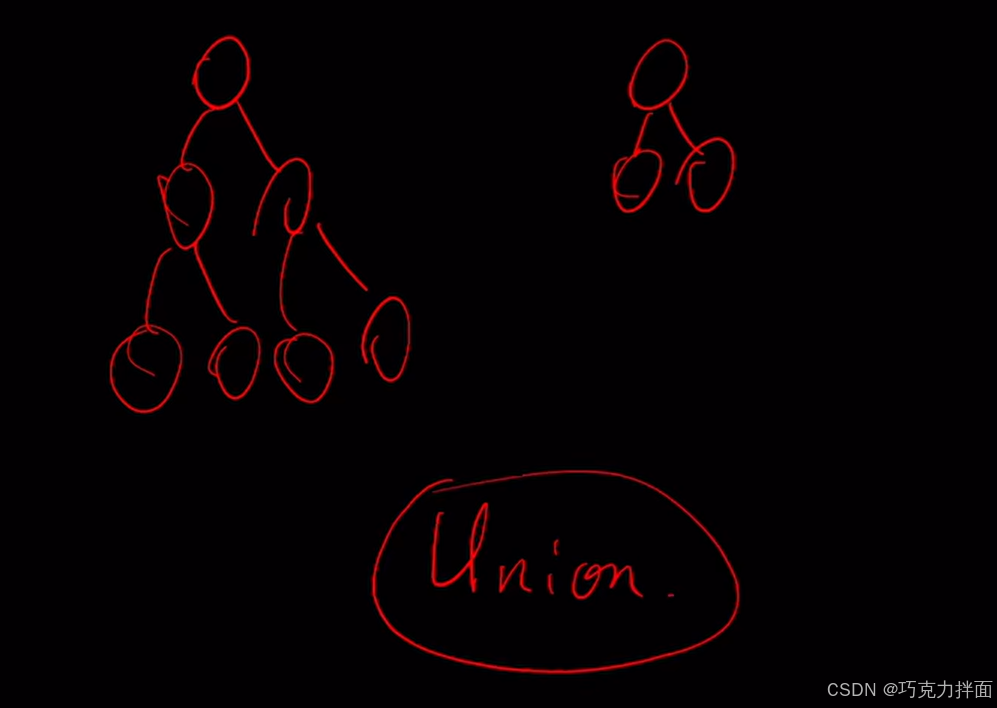
如果左边的大树"并"到右边的小树,此时的高度为4->高度比左边的大树增加了1,比右边的小树增加了2:
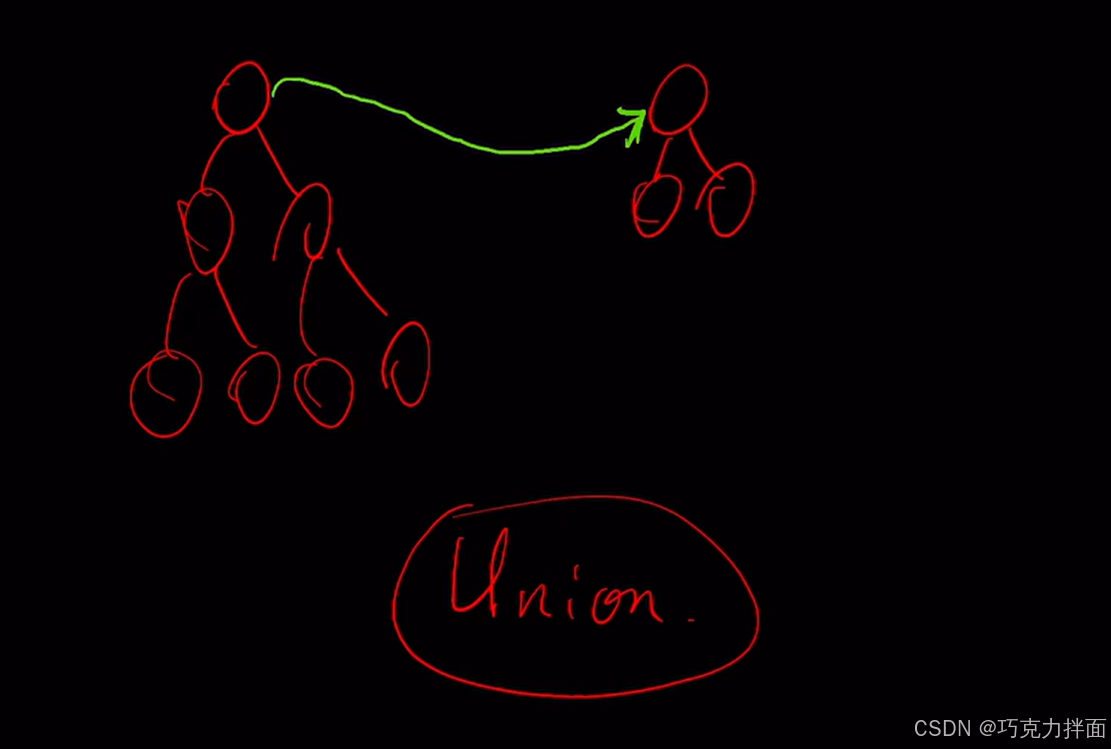
如果右边的小树"并"到左边的大树,此时的高度为3->高度相比于左边的大树没有增加,比右边的小树增加了1:
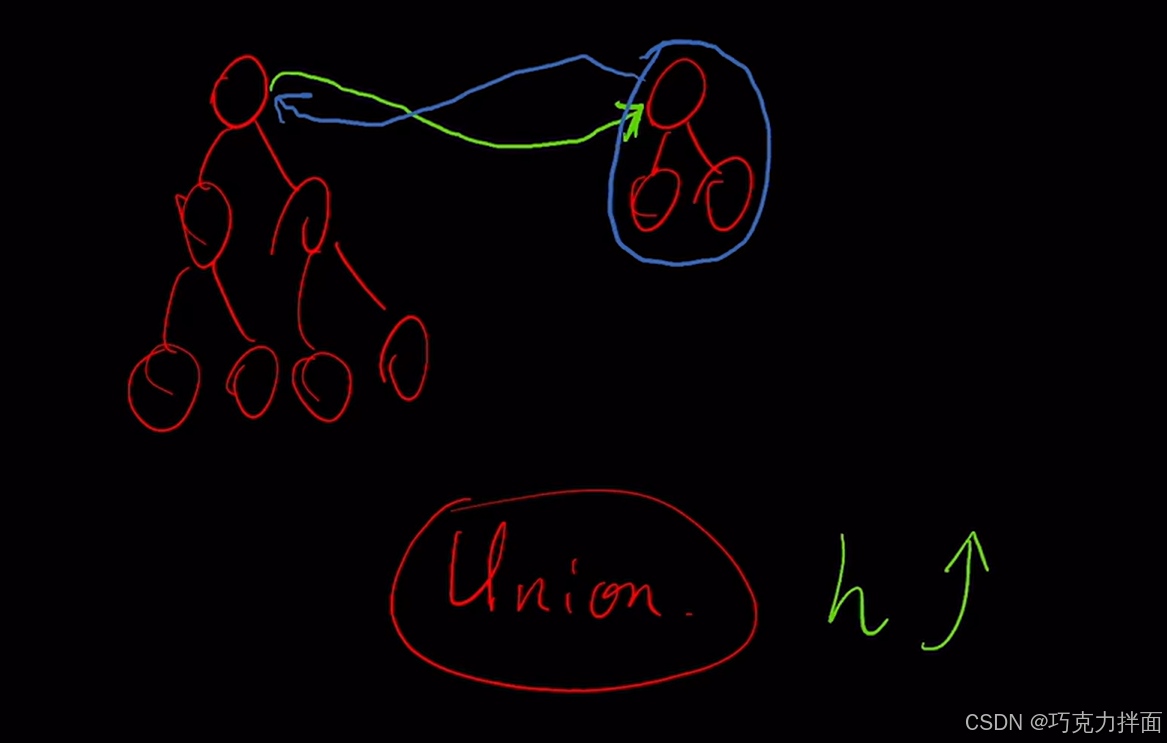
所以每一次合"并"两棵树时,都是小树"并"到大树,这样就可以使得树的高度增加没那么快。
2.如何表示一棵树的大小呢?答案是可以用根结点在数组中的绝对值表示树的结点总数:
例如:A结点在S数组中对应的值为-6,代表以A为根结点的这棵树总共有6个结点
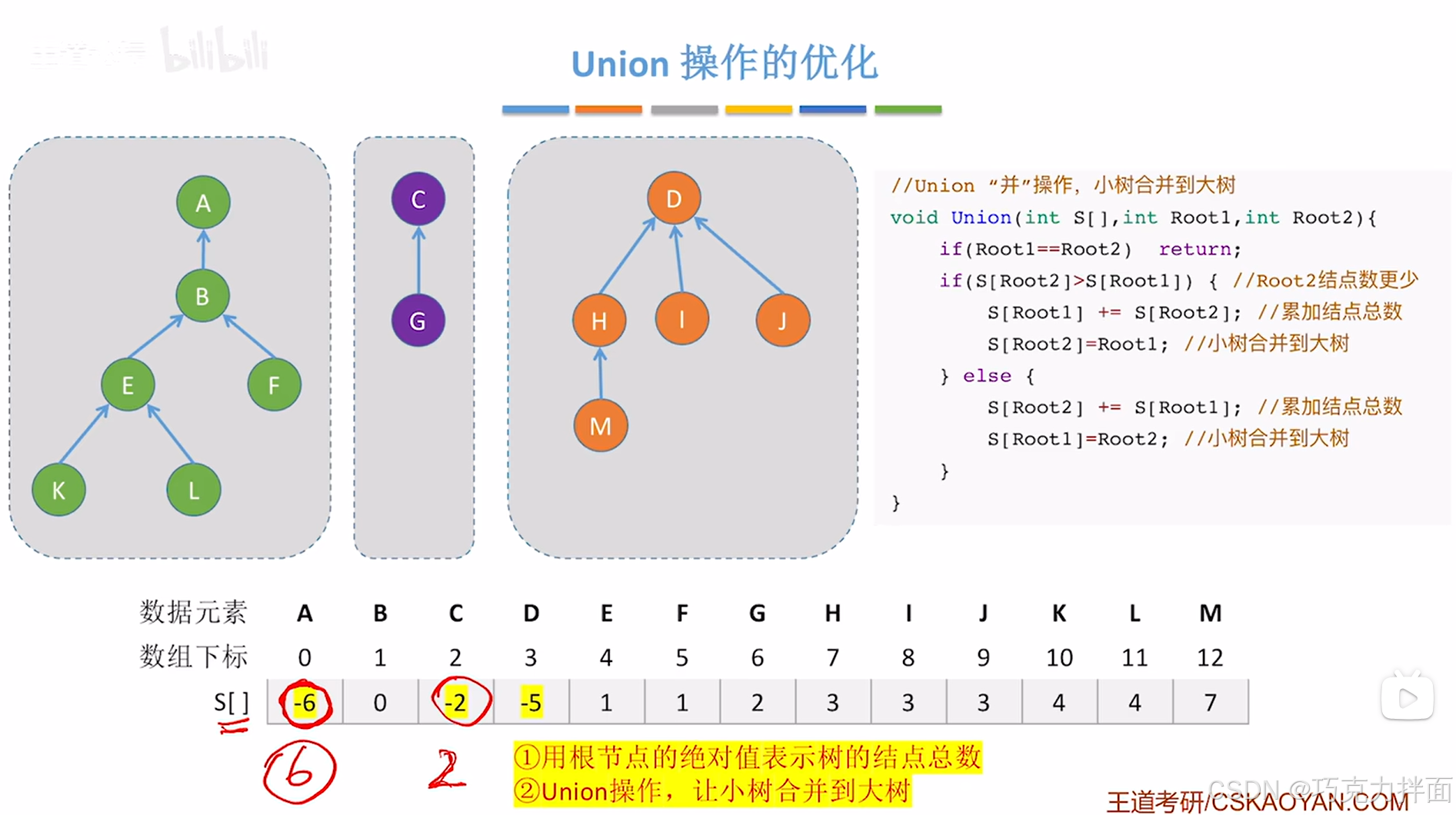
得出结点数谁多谁少,就可以得知树谁高谁低,此时就可以明确谁合"并"到谁,
就比如将根结点为A结点的树和根结点为C结点的树"并"为一棵树时,由于
A结点在S数组中对应的值为-6,代表以A为根结点的这棵树总共有6个结点,
C结点在S数组中对应的值为-2,代表以C为根结点的这棵树总共有2个结点,
所以根结点为A结点的树要比根结点为C结点的树大,此时就需要根结点为C结点的树"并"到根结点为A结点的树,
此时C结点的父结点为A结点,C结点在S数组中的值就要改为0,那么根结点为A结点的树多了两个结点,A结点在S数组中的值就要改为-8,代表根结点为A结点的树总共有8个结点:
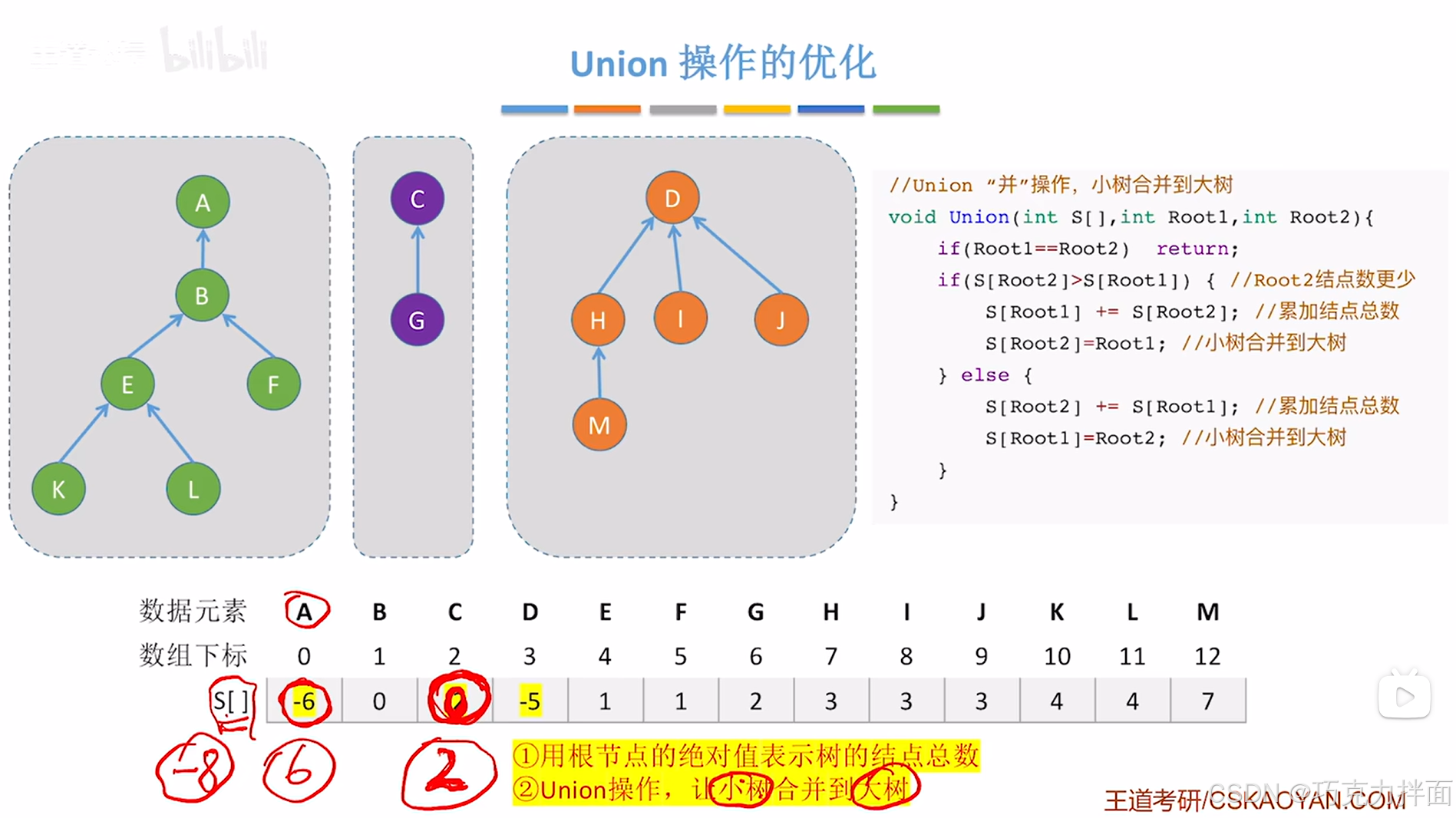
3.实例:
上述代码以A结点为根结点的树和以C结点为根结点的树为例:
此时Root1代表A结点,那么Root1为0,在数组S中的值为-6即S[0](或S[Root1])为-6,
Root2代表C结点,那么Root2为2,在数组S中的值为-2即S[2](或S[Root2])为-2,
显然Root1不等于Root2,S[Root1]小于S[Root2],意味着
以A结点为根结点的树的结点数大于以C结点为根结点的树的结点数(因为是负值,越小绝对值越大),
因此以C结点为根结点的树"并"入以A结点为根结点的树,总结点数就是
以A结点为根结点的树的结点数加上以C结点为根结点的树的结点数:
(注:结点数一样的两棵树谁"并"谁都一样)
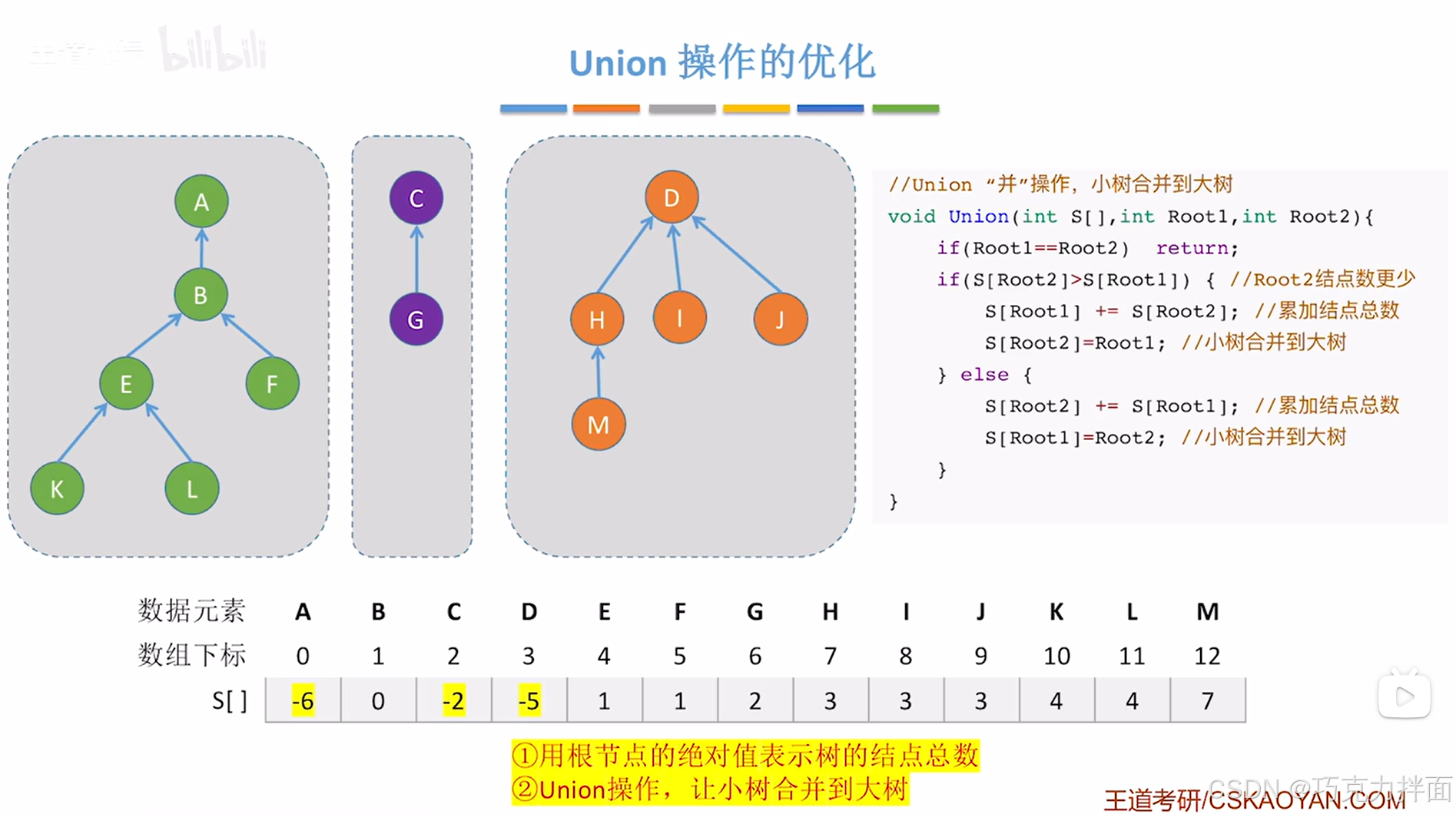
如果以A结点为根结点的树要合"并"以D结点为根结点的树,显然以A结点为根结点的树的结点数比以D结点为根结点的树的结点数多,那么以D结点为根结点的树"并"入以A结点为根结点的树:
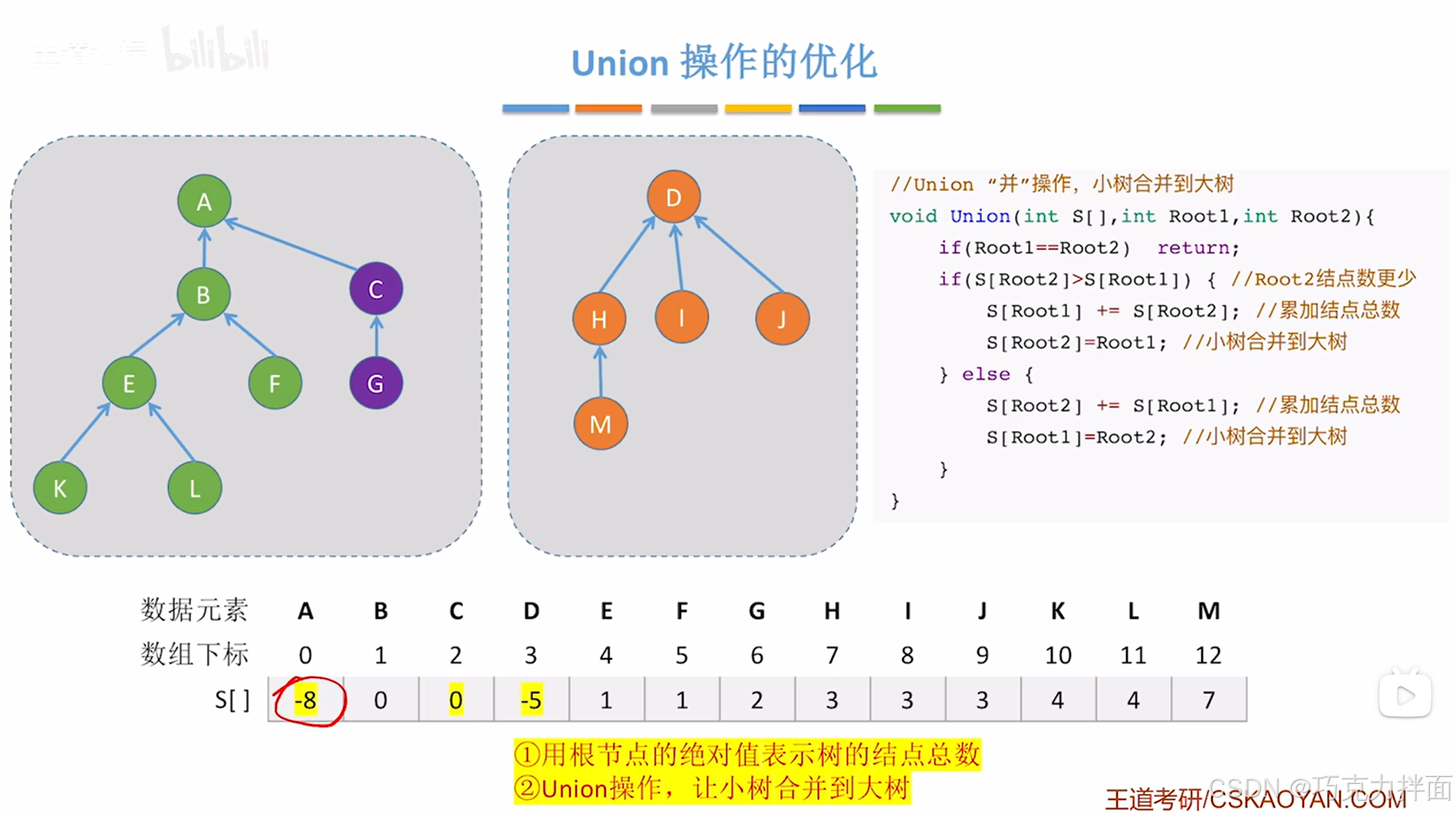
经过两次的"并"操作,树的高度没有发生变化,都是小树合"并"到大树,因此对树的大小判断至关重要,如果不进行该判断,可能大树"并"到小树,导致高度增加,使得"查"操作效率变低。
4.总结:
"并"操作未优化前,并没有限制谁"并"入谁,这可能大树"并"到小树,导致高度增加,n个结点"并"入一棵树,最大有可能使得树的高度变成n+1的高度,树高为n+1,这样以来"查"操作的最坏时间复杂度为O(n+1),等价于O(n)->最坏的情况:
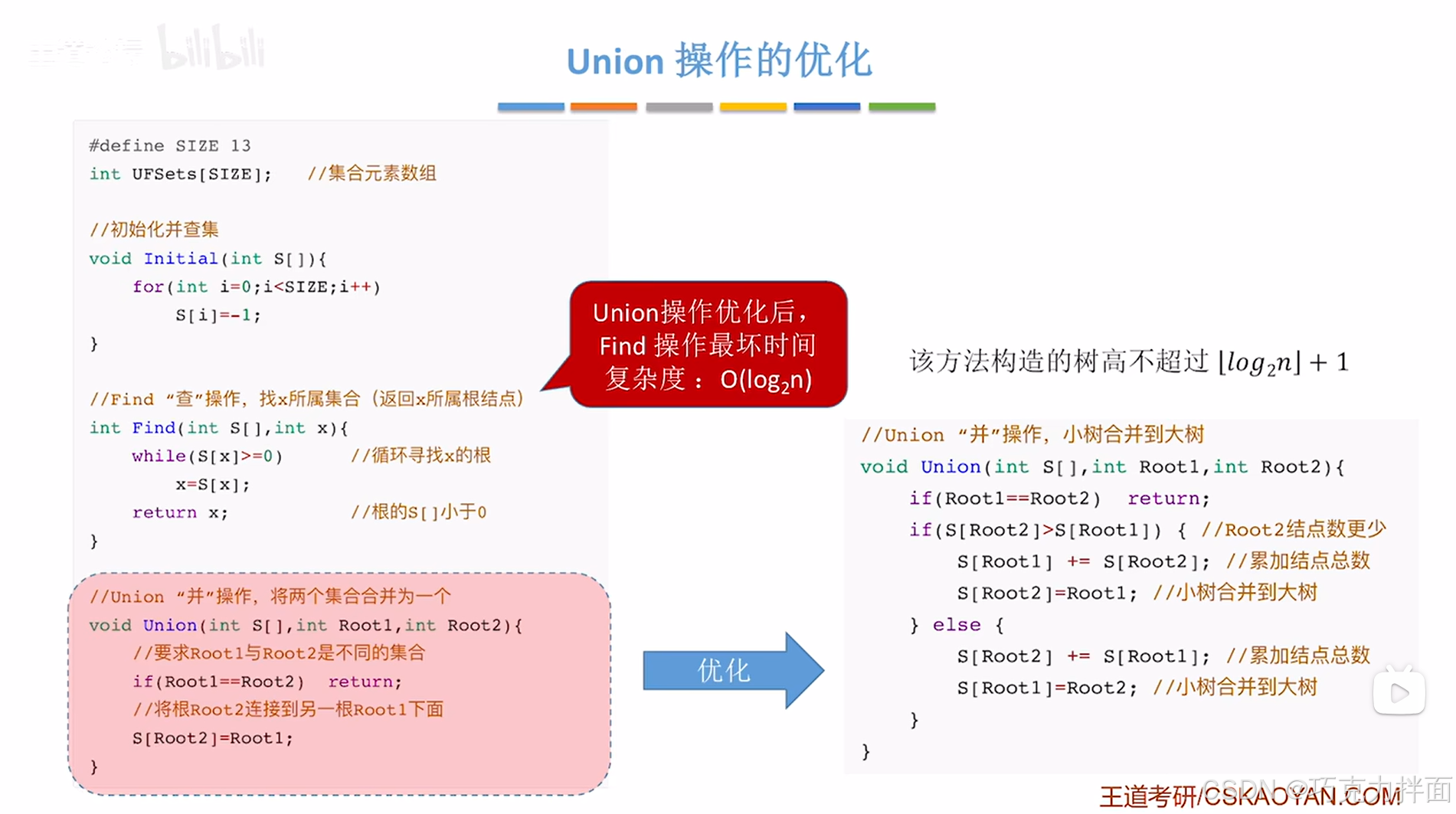
但如果优化后进行判断树的大小再进行"并"操作,实现小树合"并"到大树,使得树的高度增加减慢,最终"查"操作的最坏时间复杂度降低(由幂降为对数):
因为没有循环,并"操作的时间复杂度为O(1),"并"操作优化后,"查"操作的最坏时间复杂度降低(由幂降为对数):
五.总结:
-
"并查集"在逻辑上就是一种集合,元素之间呈现出集合的关系,两个元素要么属于同一个集合,要么不属于同一个集合
六."并查集"中"查"操作的优化:
1.实例:
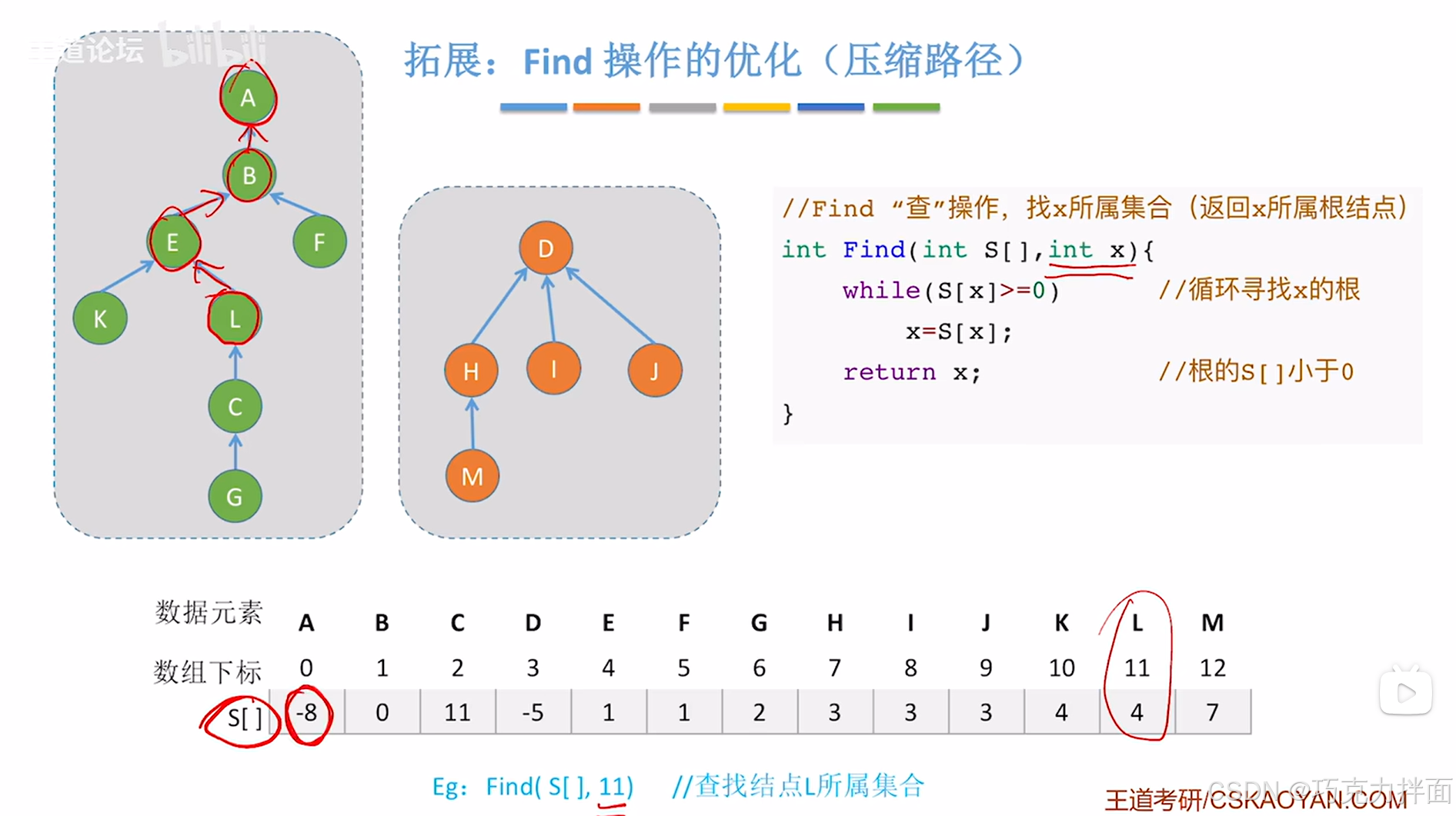
比如要找L结点所属集合,L在S数组中11索引处,
S[11]为4,4大于等于0,此时要检查4索引上的值,
S[4]为1,1大于等于0,此时要检查1索引上的值,
S[1]为0,0大于等于0,此时要检查0索引上的值,
S[0]为-8,-8小于0,此时找到了根结点,即S[0]对应的结点A,
那么L结点所属以A结点为根结点的树,
从L结点一直向上找到根结点A的路程称为查找路径,
实际上,可以通过压缩路径来提高查找的效率:

查找过程中经历了L结点、E结点、B结点和A结点,接下来要做的就是把L结点、E结点、B结点(不包括根结点A)都挂到根结点A的下面,同时修改S数组中的值,使得L结点、E结点、B结点的父结点都为A结点:核心就是把查找过程中经历的除了根结点外的结点都挂到根结点下
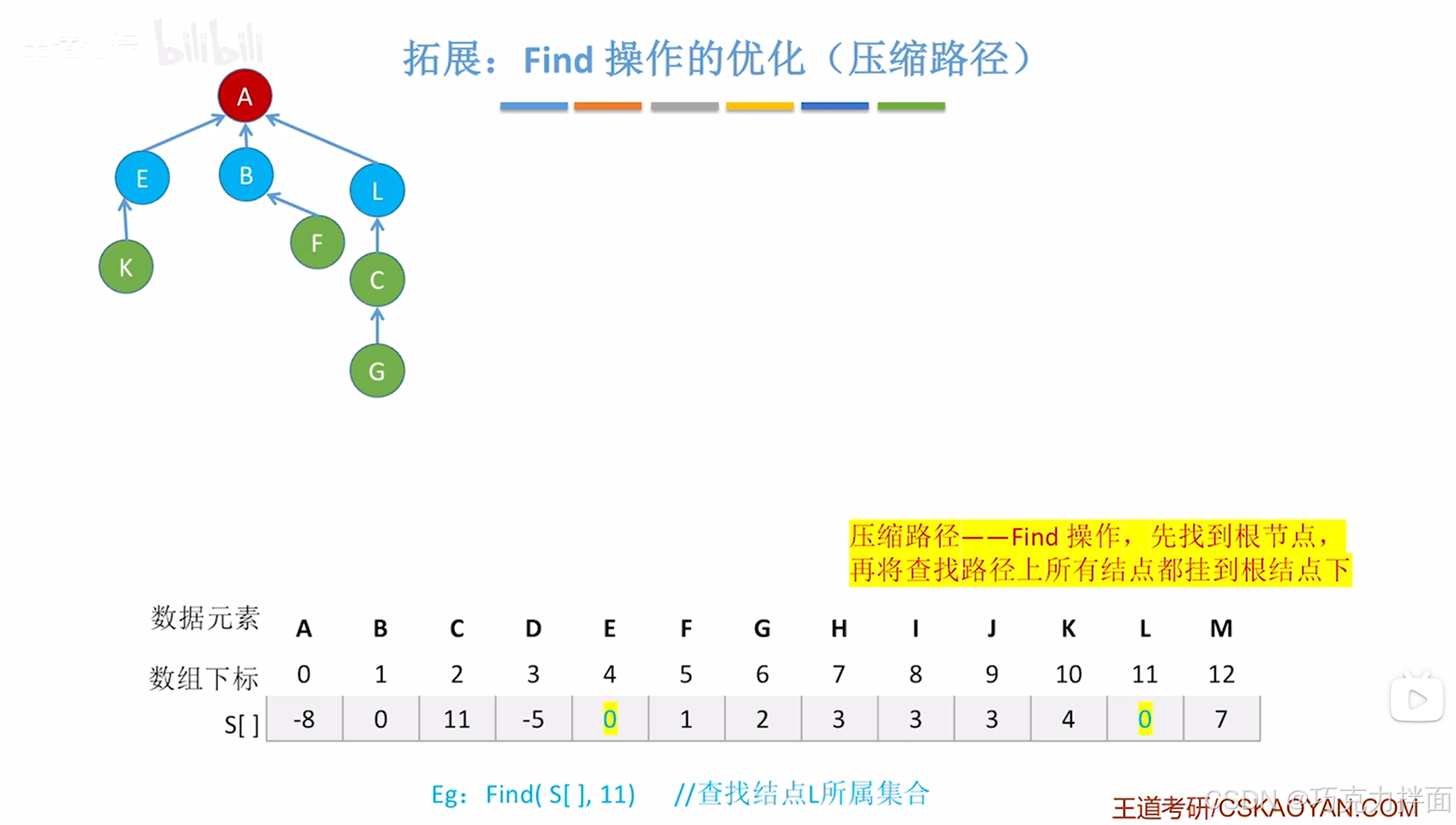
"查"操作后,确定了根结点,再经过第二轮的处理,把查找过程中经历的除了根结点外的结点都挂到根结点下,这样的话,下次再想要确定L结点所属的树即集合,只需要向上找一次就可以找到根结点,也就可以确定所属的树即集合了,此时查找路径被压缩了,"查"的效率大大提高->本例中所经历的除根结点A以外的结点L结点、E结点、B结点全部挂在了根结点A下面,下次再查找就会方便很多。
2.代码:
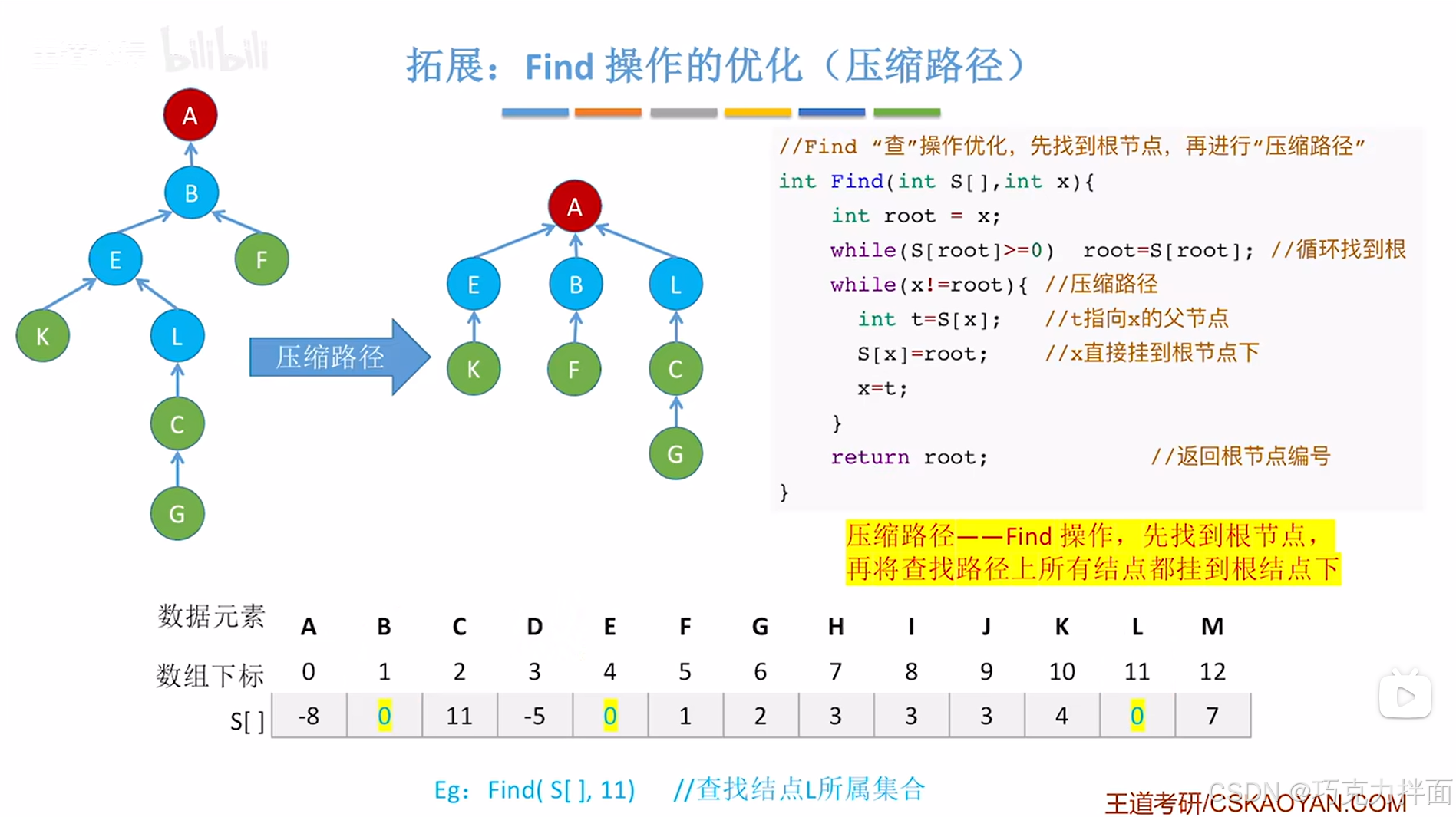
#include<stdio.h>
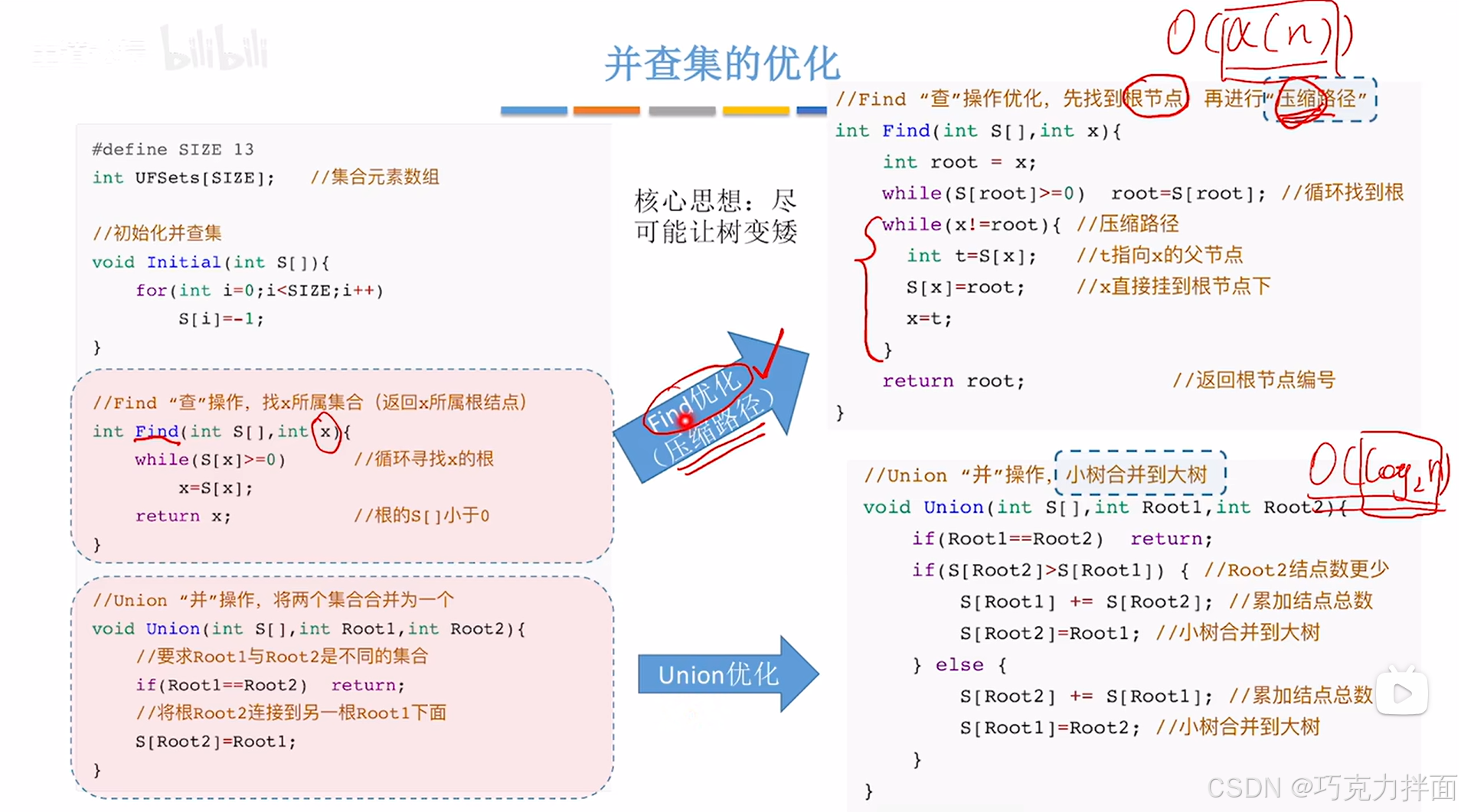
//Find "查"操作优化,先找到根结点,再进行"压缩路径"
int Find(int S[],int x) //x代表要操作的结点在S数组中的索引
{
/*定义一个变量root记录索引x,root用来记录根结点在数组S中的索引,
先把x的值赋值给root,意味着root此时也代表要操作的结点在S数组中的索引,
之后通过循环不断地想上找可以得出根结点的索引 */
int root = x;
//1.循环找x索引上的结点所在树的根结点 ->循环结束后root记录的就是根结点的索引
while(S[root]>=0)
{
root = S[root];
}
//2.压缩路径
/*思路:压缩路径本质就是把查找过程中经历的除了根结点外的结点都挂到根结点下,
因此就需要修改查找过程中经历的除了根结点外的结点在S数组中的值,先从x索引上的结点开始,
直到把把查找过程中经历的除了根结点外的结点都处理完为止*/
while(x!=root) //root记录的就是根结点的索引
{
/*先处理x索引上的结点,之后不断向上处理即处理父结点,根结点除外*/
/*首先需要用一个中间变量t来记录x索引上的结点的父结点的索引即t=S[x],
因为x索引上的结点的父结点的索引既要被修改为根结点的索引,还要进行下一轮循环的使用*/
//2.1.t指向x的父结点,S[x]记录的是x索引上的结点的父结点的在数组S中的索引
int t=S[x];
/*2.2.x就代表此时要操作的结点在数组S中的索引,把x索引上对应的结点直接挂到根结点下,
即x索引上的结点的父结点为根结点*/
S[x]=root;
/*2.3.操作完x索引对应的结点,由于"查"操作的方向是想上查找,
因此下一步就要操作x索引对应的结点的父结点,因此修改索引 */
x=t;
}
//3.返回根结点编号
return root;
}
int main()
{
return 0;
}
压缩路径后,"查"操作的效率就会提高。
3.时间复杂度分析:
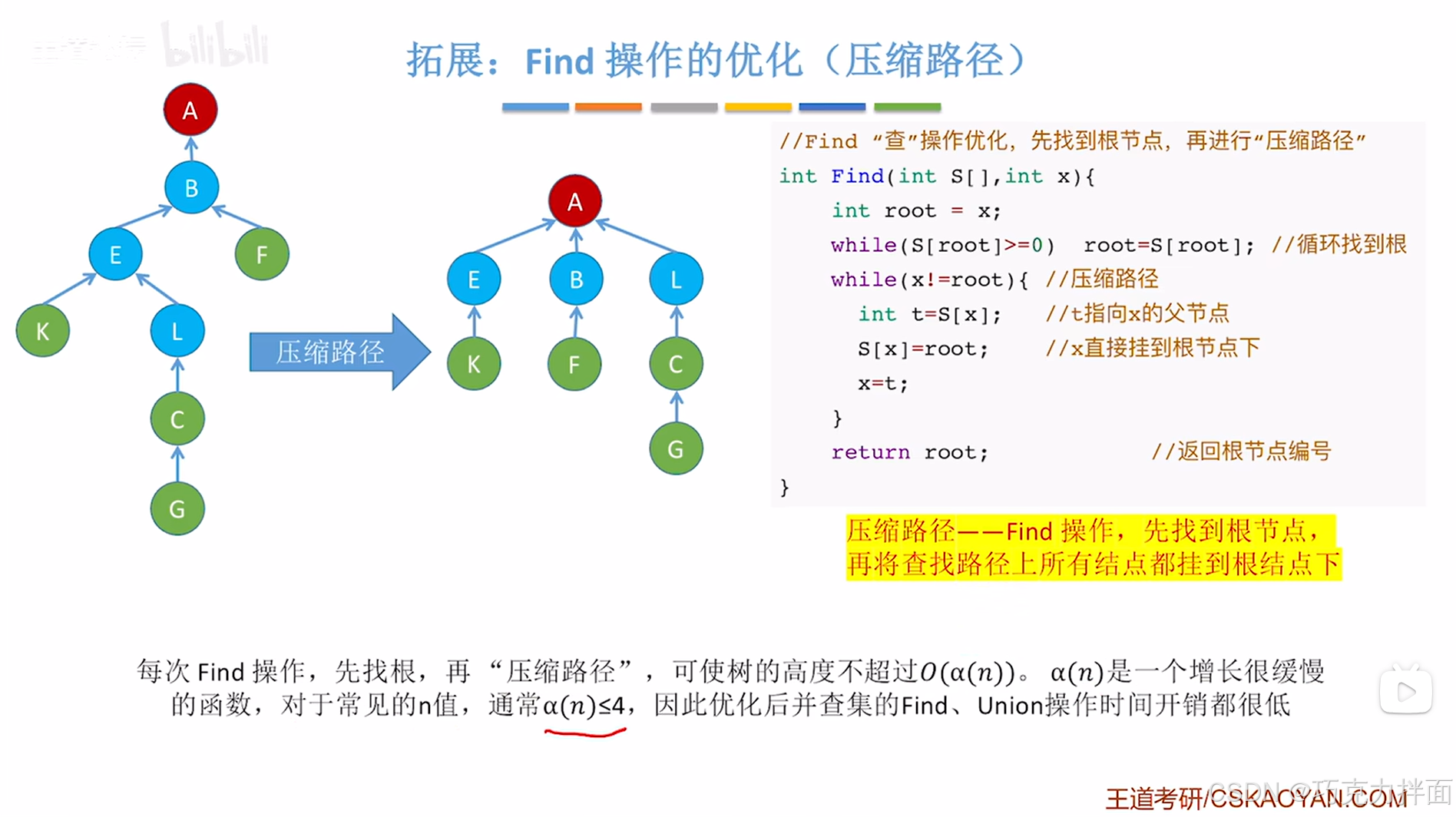
a(n)不需要管,只知道它是一个增长很缓慢的函数即可,O( a(n) )<=O( 4 )=O(1),相当于常数级的时间复杂度(比对数级的时间复杂度高效)就可以完成"查"操作。
七."并查集"优化总结:
1.全部代码:
-
尽量使树变矮,树越矮,"查"操作越高效
2.时间复杂度对比:
-
在没有做任何优化时,将n个独立元素通过多次合并为一棵树即集合,最坏的时间复杂度为O(n * n),因为要合并n个独立的元素,就需要n-1次合并,相当于循环了n-1次,时间复杂度为O(n-1),每次合并两个集合时,首先要同时从两个指定的元素出发,分别找到这两个元素所在树的根结点,每一次合并前都需要进行"查"找根结点,"查"操作最坏时间复杂度为O(n),"查"操作后就要合并,最坏时间复杂度就是O(n) * O(n-1)=O(n * n - n),等价于O(n * n)
3."并查集"快乐站:登入下面的网址可以观看更详细的"并查集"演示

















 4736
4736

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









