




【李宏毅深度强化学习笔记】1、策略梯度方法(Policy Gradient)
【李宏毅深度强化学习笔记】2、Proximal Policy Optimization (PPO) 算法
【李宏毅深度强化学习笔记】3、Q-learning(Basic Idea)
【李宏毅深度强化学习笔记】4、Q-learning更高阶的算法(本文)
【李宏毅深度强化学习笔记】5、Q-learning用于连续动作 (NAF算法)
【李宏毅深度强化学习笔记】6、Actor-Critic、A2C、A3C、Pathwise Derivative Policy Gradient
【李宏毅深度强化学习笔记】8、Imitation Learning
-------------------------------------------------------------------------------------------------------
【李宏毅深度强化学习】视频地址:https://www.bilibili.com/video/av63546968?p=4
课件地址:http://speech.ee.ntu.edu.tw/~tlkagk/courses_MLDS18.html
-------------------------------------------------------------------------------------------------------
Double DQN(DDQN)
DQN的Q-value往往是被高估的,如下图
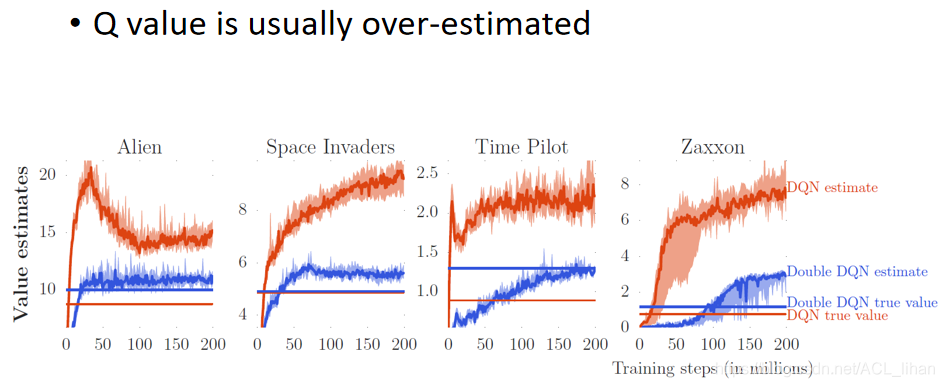
上图为四个游戏的训练结果的对比。
橙色的曲线代表DQN估测的Q-value,橙色的直线代表DQN训练出来的policy实际中获得的Q-value
蓝色的曲线代表Double DQN估测的Q-value,蓝色的直线代表Double DQN训练出来的policy实际中获得的Q-value
由图可以看出两点:
- 从橙色的曲线和橙色的直线可以看出,DQN估测出来的Q-value,往往会高于实际中的Q-value
- 从橙色的直线和蓝色的直线可以看出,Double DQN训练出来的policy,一般会好过DQN训练出来的policy
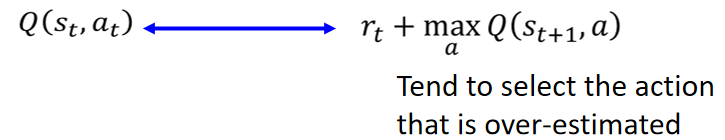
从第三篇笔记(https://blog.youkuaiyun.com/ACL_lihan/article/details/104041905)中Q-function的概念可以得出,的结果会接近于
![]() 。但是
。但是往往容易会得到高估的结果,以下图为例子:

4个柱子代表4个action得到的Q-value,实际上都是相同的;右图绿色的部分表示高估的部分。
因为Q-function本身就是一个network,估测出来的值本身是有误差的,所以原本4个action都相等的Q-value就变成右图的样子。而因为,所以又往往会选择Q-value最大的那个结果。所以就会导致
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 389
389




 到【灌水乐园】发言
到【灌水乐园】发言







