



11 – 12. Java学习 – 实用类介绍、异常、单列集合Collection、常见的数据结构
一、实用类
1. Array类
位于java.util包下,是java提供用于数组操作的一个工具类。
sort(int[ ] arr):对指定数组进行升序排序
public class ArrayDemo01 {
public static void main(String[] args) {
Integer[] arrII = {99, 98, 76, 64, 44, 12, 9};
// 数组的排序
Arrays.sort(arrI);
arrayPrint(arrI); // 自定义数组输出函数不用在意
}
}
sort()函数底层是靠冒泡排序实现的,我们当然也可以自己实现冒泡排序:
// 冒泡排序
/*
* 轮次:数组长度-1
* 每轮的比较次数:相较上一次比较数-1,最开始比较次数为数组长度-1
*
* 比较次数和轮次的关系:数组长度-1-轮次
* */
// 升序
public static void bubbleSortUp(Integer[] ints) {
int max = ints.length - 1;
for (int i = 0; i < ints.length - 1; i++) {
for (int j = 0; j < max; j++) {
if (ints[j] > ints[j + 1]) {
int tmp = ints[j];
ints[j] = ints[j + 1];
ints[j + 1] = tmp;
}
}
max--;
}
arrayPrint(ints);
}
// 降序
public static void bubbleSortDown(Integer[] ints) {
for (int i = 0; i < ints.length; i++) {
for (int j = 0; j < ints.length - 1 - i; j++) {
if (ints[j] < ints[j + 1]) {
int tmp = ints[j];
ints[j] = ints[j + 1];
ints[j + 1] = tmp;
}
}
}
arrayPrint(ints);
}
binarySearch(int[ ] a,int key):在指定的数组中快速定位到某个位置上的元素
public class ArrayDemo01 {
public static void main(String[] args) {
int[] arrI = {1, 11, 34, 54, 66, 87, 99};
// 在指定数组中,快速定位到某个位置的元素
System.out.println(Arrays.binarySearch(arrI, 66));
}
}
binarySearch()函数必须在有序数组中使用,且binarySearch()函数是针对基本类型数据进行二分查找的,不能用来查找包装类型。如果需要查找包装类型可能需要自定义Comparator。
binarySearch()函数底层使用了二分查找,我们也可以尝试自己实现二分查找:
// 二分查找
public static int binarySearch(int[] ints, int bb) {
int low = 0;
int height = ints.length - 1;
int middle = 0;
while (low <= height) {
middle = (low + height) / 2;
if (bb < ints[middle]) {
height = middle - 1;
} else if (bb > ints[middle]) {
low = middle + 1;
} else {
return middle;
}
}
return -1;
}
copyOf(T[ ] original,int newLength):拷贝数组中的元素到新的数组中
public class ArrayDemo01 {
public static void main(String[] args) {
Integer[] arrI = {1, 11, 34, 54, 66, 87, 99};
Integer[] arrII = {99, 98, 76, 64, 44, 12, 9};
int[] arrIII = {1, 11, 34, 54, 66, 87, 99};
// 拷贝数组中的元素到新数组
Integer[] arr = Arrays.copyOf(arrI, 7);
arrayPrint(arr);
// 拷贝指定区间数据到新数组中
Integer[] arr2=Arrays.copyOfRange(arrI, 2, 4);
arrayPrint(arr2);
}
}
2. Math类
Math类是用来操作数字,进行一些数学运算的类
public class MathDemo {
public static void main(String[] args) {
// 求0到1之间的随机数
double random = Math.random();
System.out.println(random);
// 求绝对值
int abs1 = Math.abs(-1);
System.out.println(abs1);
int abs2 = Math.abs(2);
System.out.println(abs2);
// 向上取整
double ceil = Math.ceil(3.000001);
System.out.println(ceil);
// 向下取整
double floor = Math.floor(4.9999999);
System.out.println(floor);
// 四舍五入
long round = Math.round(3.1415);
System.out.println(round);
// 求两者之间最大值
int max = Math.max(22, 1);
System.out.println(max);
// 求两者之间最小值
int min = Math.min(22, 1);
System.out.println(min);
// 求某数的n次方
double pow = Math.pow(3, 3);
System.out.println(pow);
}
}
3. BigDecimal类
BigDecimal 是用于处理任意精度的十进制数的类。它提供了高精度的算术运算,并且不会丢失精度。
public class BigDecimalDemo {
public static void main(String[] args) {
BigDecimal bigDecimal1 = new BigDecimal(100);
BigDecimal bigDecimal2 = new BigDecimal(20);
// 加法
BigDecimal add = bigDecimal1.add(bigDecimal2);
System.out.println(add);
// 减法
BigDecimal subtract = bigDecimal1.subtract(bigDecimal2);
System.out.println(subtract);
// 乘法
BigDecimal multiply = bigDecimal1.multiply(bigDecimal2);
System.out.println(multiply);
// 除法
BigDecimal divide1 = bigDecimal1.divide(bigDecimal2);
System.out.println(divide1);
BigDecimal divide2 = bigDecimal1.divide(bigDecimal2, BigDecimal.ROUND_HALF_UP);
System.out.println(divide2);
BigDecimal divide3 = bigDecimal1.divide(bigDecimal2, BigDecimal.ROUND_UP);
System.out.println(divide3);
}
}
其中,BigDecimal.ROUND_UP 和 BigDecimal.ROUND_HALF_UP 都代表结果的取值方式。
BigDecimal.ROUND_HALF_UP :最常见的四舍五入
BigDecimal.ROUND_UP :向远离0的方向取整
- e.g:
1.1->2
1.5->2
1.8->2
-1.1->-2
-1.5->-2
-1.8->-2
二、异常
1. 什么是异常
程序在执行过程中出现意外的情况,如果不处理程序就会卡住,而不再向下执行。
Java中异常类的体系结构:
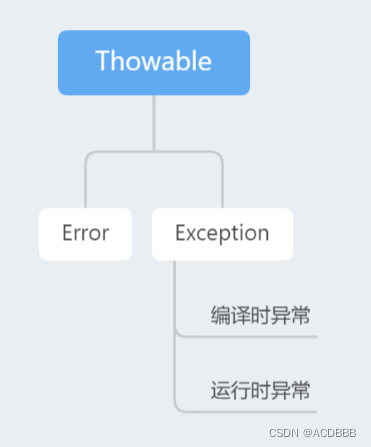
Throwable类中的常用方法:
- Throwable():创建一个描述信息为空的Throwable对象
- Throwable(String message):创建一个指定描述信息Throwable对象
- toString():获取Throwable对象的全限定名
- getMessage():获取Throwable对象的描述信息
- printStackTrace():在控制台打印异常的信息
public class ThrowableTest {
public static void main(String[] args) {
Throwable throwable = new Throwable();
System.out.println(throwable.toString());
Throwable throwable1 = new Throwable("这是一个异常类");
System.out.println(throwable1.getMessage());
throwable1.printStackTrace();
}
}
有时候我们运行代码时会看到红色的异常信息,这种异常信息的出现的原因是:由于我们没有做异常处理,因此在程序执行时出现不正常的情况时,JVM就会亲自处理异常,其处理方式是调用Throwable类里面的printStackTrace方法,将异常信息在控制台打印输出。
想要避免这种情况,我们可以在可能出现异常的代码上,进行异常处理。
异常处理的方式有三种:
- 捕获异常处理
- 抛出异常处理
- 自定义异常处理
2. 捕获异常处理
**捕获异常:**
try{
可能会出现异常的代码
}catch(异常类型 变量名){
异常处理的代码
}
try-catch的使用细节:
- 如果在try块中出现了多行代码,如果某一行代码出现了问题,那么在try块中该行代码后面的代码是不会执行的
@Test
public void test(){
int a=0;
int b=3;
int c=0;
try {
System.out.println("语句1");
c=b/a;
System.out.println("语句2"); // 该行代码不会执行
}catch (ArithmeticException e){
System.out.println("除数不能为0");
}
System.out.println(c);
System.out.println("语句3");
}
执行结果:

- 在程序中,有可能会出现多种类型的异常。这些不同类型的异常,我们都需要处理。我们可以使用多重catch语句来进行处理
**多重catch格式:**
try{
// 可能会出现的异常代码
}catch(异常类型1 变量名){
// 针对异常类型1的异常处理代码
}catch(异常类型2 变量名){
// 针对异常类型2的异常处理代码
}catch(异常类型3 变量名){
// 针对异常类型3的异常处理代码
}
... ...
@Test
public void test02() {
int[] arr = {1, 2, 3, 4};
int c = 0, a = 0;
int b = 5;
try {
System.out.println("语句1");
c = b / a;
System.out.println(arr[5]);
System.out.println("语句2");
} catch (ArithmeticException e) {
System.out.println("除数不能为0");
} catch (ArrayIndexOutOfBoundsException e) {
System.out.println("数组下标越界");
}
System.out.println(c);
System.out.println("语句3");
}
运行结果:

多重catch语句中,一旦有一个异常被捕获,后面的代码不会执行,即便后面的语句还存在异常,也不会被捕获了。
如果我们要定义多重catch语句。catch中描述的大异常类型应该放在所有catch语句中的最后。否则出现编译报错:
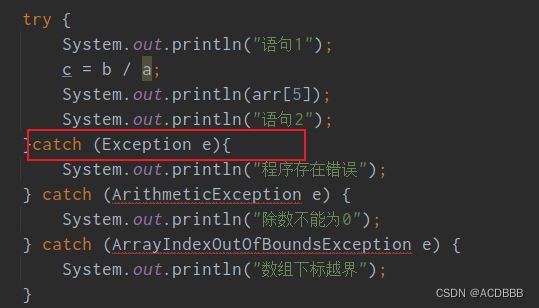
如果有多重类型的异常需要处理,我们也可以不用写那么多catch语句块。直接通过一个大的Exception进行统一处理。
@Test
public void test03(){
int[] arr = {1, 2, 3, 4};
int c = 0, a = 0;
int b = 5;
try {
System.out.println("语句1");
c = b / a;
System.out.println(arr[5]);
System.out.println("语句2");
} catch (Exception e){
System.out.println("捕获所有错误");
}
System.out.println(c);
System.out.println("语句3");
}
运行结果:

3. 抛出异常处理
抛出异常的关键字: throw、throws
- throw 在方法的内部使用,throw后面跟的是一个异常对象
- throw new NullPointerException
- throws 声明在方法的名称后面。throws 后面跟的是异常的类名
- throws NullPointerException
@Test
public void test04() {
try {
getNum(0, 5);
} catch (Exception e) {
System.out.println("调用者处理了异常");
e.printStackTrace();
}
}
public void getNum(int a, int b) throws Exception {
if (a == 0) {
throw new Exception("除数不能为0");
}
int c = b / a;
System.out.println(c);
}
运行结果:

使用抛出异常处理需要注意的事项:
- 在方法内部使用throw抛出了Exception类型的异常,在方法上必须使用throws关键字声明抛出
- 如果一个方法使用throws声明抛出Exception类型的异常,那么在调用这个方法的时候,必须要对该方法进行异常处理。处理的方式有两种:
- 要么使用try-catch进行捕获处理
- 要么继续throws声明异常的抛出
- 方法在执行的时候,如果遇到了throw关键字,那么throw关键字后面的代码是不会执行了
- 在一个方法内部,可以使用throw关键字抛出多个异常类型的对象的
public void getNum(int a,int b,int[] arr) throws ArithmeticException,NullPointerException{
if(b == 0){
throw new ArithmeticException("除数不能为0!");
}
if(arr == null){
throw new NullPointerException("数组对象不能为空!");
}
int c = a / b;
System.out.println(arr[0]);
System.out.println(c);
}
总结:
- throw关键字用于方法的内部,用于异常对象的抛出。thorw后面只能跟一个异常对象
- throws关键字用于方法名称上面,用于异常抛出声明,throws后面可以跟多个异常类型,多个异常类型使用逗号分隔
4. finally关键字
finally关键字不能单独使用,只能和try语句块一起使用。
- try -catch-finally
- try-finally
@Test
public void test05(){
getSum(10, 0);
}
public void getSum(int a,int b){
try {
int c=a/b;
System.out.println(c);
throw new Exception("抛出了异常");
}catch (Exception e){
System.out.println("处理了异常");
}finally {
System.out.println("finally代码块的内容执行了");
}
}
运行结果:

@Test
public void test05(){
getSum(10, 2);
}
public void getSum(int a,int b){
try {
int c=a/b;
System.out.println(c);
return;
}catch (Exception e){
System.out.println("处理了异常");
}finally {
System.out.println("finally代码块的内容执行了");
}
}
运行结果:

即使在程序中出现了throw或者return关键字,那么finally块中的代码依旧会被执行。
注意:在有return的场景下,先走finally,再走return。
一般来说,finally是一定会执行的,但是如果JVM虚拟机被关闭,那运行环境都没有了,finally也就不会执行了。
@Test
public void test05(){
getSum(10, 2);
}
public void getSum(int a,int b){
try{
int c = a + b;
System.exit(0); // JVM退出 finally代码块是不会执行的
}finally {
System.out.println("finally代码块的内容");
}
}
5. 自定义异常
假设:模拟注册。若注册用户名和已存在用户名相同,则认为出现异常,需进行异常处理。
// 定义一个异常类,继承Exception
class RegisterException extends Exception{
public RegisterException(){}
public RegisterException(String message) {
super(message);
}
}
// 异常处理
public static String[] names = {"大橘", "三花", "英短"};
@Test
public void test06() {
try {
register("美短");
register("英短");
} catch (RegisterException e) {
e.printStackTrace();
}
}
public void register(String name) throws RegisterException {
for (int i = 0; i < names.length; i++) {
if (names[i].equals(name)) {
throw new RegisterException("用户名已存在");
}
}
System.out.println("注册成功");
}
运行结果:

三、单列集合Collection
其实在前面介绍ArrayList的时候,简单介绍过单列集合Collection。这里可以再稍微回顾一下。
Collection及其实现类,只存储元素值,需要存储键值对,可以使用Map接口实现。
Collection接口下的两大接口,List和Set。List接口及其实现类元素有序且可重复;Set接口及其实现类元素无序且不重复。
1. Collection接口下的方法
下面直接通过例子来了解Collection下的方法:
public class CollectionDemo01 {
public static void main(String[] args) {
Collection<String> collection= new ArrayList<>();
// add(): 添加元素
collection.add("a");
collection.add("b");
collection.add("c");
collection.add("a");
collection.add("b");
collection.add("c");
System.out.println(collection); // [a, b, c, a, b, c]
// remove(): 移除元素,移除找到的第一个
collection.remove("a");
System.out.println(collection); // [b, c, a, b, c]
// addAll(): 将一个集合的元素追加到另一个
Collection<String> list=new ArrayList<>();
list.add("A");
list.add("B");
list.add("C");
collection.addAll(list);
System.out.println(collection); // [b, c, a, b, c, A, B, C]
// removeAll(): 移除集合中另一个集合的所有元素
collection.removeAll(list);
System.out.println(collection); // [b, c, a, b, c]
// contains(): 判断集合中,是否包含指定内容
System.out.println(collection.contains("b")); // true
System.out.println(collection.contains("C")); // false
// containsAll(): 判断集合是否包含另一个集合中的所有元素
System.out.println(collection.containsAll(list)); // false
// toArray(): 集合转数组
Object[] objects = collection.toArray();
System.out.println(Arrays.toString(objects)); // [b, c, a, b, c]
// size(): 集合长度
System.out.println(collection.size()); // 5
// clear(): 清空集合
collection.clear();
System.out.println(collection); // []
// isEmpty(): 判断集合是否为空
System.out.println(collection.isEmpty()); // true
System.out.println(list.isEmpty()); // false
}
}
案例:判断集合中是否包含指定的Person对象。如果一个人的身份证id和姓名和另外一个人一样,那么我们就认为这是同一个对象。
思路:重写equals方法
// Person类
class Person {
private String name;
private int cardId;
// region Get And Set
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getCardId() {
return cardId;
}
public void setCardId(int cardId) {
this.cardId = cardId;
}
// endregion
// region Constructor
public Person() {
}
public Person(String name, int cardId) {
this.name = name;
this.cardId = cardId;
}
// endregion
// region ToString
@Override
public String toString() {
return "Person{" +
"name='" + name + '\'' +
", cardId=" + cardId +
'}';
}
// endregion
@Override
public boolean equals(Object obj) {
if (obj instanceof Person) {
Person p = (Person) obj;
return this.name.equals(p.name) && this.cardId == p.cardId;
}
return false;
}
}
// 测试类
@Test
public void test(){
Collection<Person> collection=new ArrayList<>();
collection.add(new Person("AAA",1001));
collection.add(new Person("BBB",1002));
collection.add(new Person("CCC",1003));
System.out.println(collection.contains(new Person("CCC", 1002))); // false
System.out.println(collection.contains(new Person("BBB", 1002))); // true
}
2. List接口下的方法
依旧直接通过例子来了解List下的方法:
public class ListDemo01 {
public static void main(String[] args) {
List<String> list = new ArrayList<>(Arrays.asList("a","b","c","d","d"));
List<String> list2 = new ArrayList<>(Arrays.asList("A","B","C"));
// add(): 指定位置增加元素
list.add(2,"D");
System.out.println(list); // [a, b, D, c, d, d]
// addAll(): 指定位置添加新集合
list.addAll(3,list2);
System.out.println(list); // [a, b, D, A, B, C, c, d, d]
// remove(): 删除指定位置元素并将其返回
System.out.println(list.remove(2)); // D
// 根据下标获取元素
System.out.println(list.get(2)); // A
// set(): 替换集合中的元素
list.set(2, "AA");
System.out.println(list); // [a, b, AA, B, C, c, d, d]
// indexOf(): 获取元素第一次出现位置的索引
System.out.println(list.indexOf("AA")); // 2
// lastIndexOf(): 获取元素最后一次出现的索引
System.out.println(list.lastIndexOf("d")); // 7
// subList(): 截取子集合
System.out.println(list.subList(2, 5)); // [AA, B, C]
// sort(): 集合排序
List<Integer> list3 = new ArrayList<>(Arrays.asList(23, 43, 5, 11, 34, 1));
list3.sort(null); // 默认排序
System.out.println(list3); // [1, 5, 11, 23, 34, 43]
list3.sort(new MyComparator()); // 自定义比较器
System.out.println(list3); // [1, 5, 11, 23, 34, 43]
}
}
最后一个 sort() 方法使用时可以使用默认排序,也可以根据需要自己定义比较器
// 定义比较器
public class MyComparator implements Comparator<Integer>{
@Override
public int compare(Integer o1, Integer o2) {
return o1 - o2;
}
}
3. ArrayList集合和LinkedList集合
3.1. ArrayList集合
ArrayList集合的方法前面介绍的已经比较多了,这里就不重复介绍了。ArrayList集合方法
这里就简单介绍一下两个集合的特点。
ArrayList集合特性:
- 基于数组实现
- 元素查找块
- 增删性能慢
因为ArrayList集合基于数组实现,存储元素的内存地址之间是连续的,因此查询数据效率比较快。
ArrayList集合底层默认数组长度为10,当存储元素,而长度不够用时,就会重新创建一个新数组,并将原来数组的元素拷贝到新数组中。新数组长度是原来的1.5倍。
增删性能低的原因也正是如此,增删元素后,ArrayList集合为了保持元素地址的连贯性,就会将元素依次后移或是前移,并且长度不够还要进行新建数组和拷贝的操作,这个过程性能低下。
3.1.1. 案例:按照斗地主的规则,完成洗牌发牌的动作。
需求分析:
- 准备牌:
- 牌可以设计为一个ArrayList,每个字符串为一张牌。
每张牌由花色数字两部分组成,我们可以使用花色集合与数字集合嵌套迭代完成每张牌的组装。
牌由Collections类的shuffle方法进行随机排序。
- 牌可以设计为一个ArrayList,每个字符串为一张牌。
- 发牌
- 将每个人以及底牌设计为ArrayList,将最后3张牌直接存放于底牌,剩余牌通过对3取模依次发牌。
- 看牌
- 直接打印每个集合
// Poker类
class Poker {
// 创建扑克牌盒,并洗牌
public ArrayList<String> pokerContainer() {
// 创建集合保存牌信息
ArrayList<String> pokers = new ArrayList<String>();
// 保存花色
ArrayList<String> colors = new ArrayList<>(Arrays.asList("♥", "♣", "♦", "♠"));
// 保存数字
ArrayList<String> nums = new ArrayList<>(Arrays.asList("2", "3", "4", "5",
"6", "7", "8", "9", "10", "J", "Q", "K", "A"));
for (int i = 0; i < colors.size(); i++) {
for (int j = 0; j < nums.size(); j++) {
String s = colors.get(1) + nums.get(j);
pokers.add(s);
}
}
pokers.add("小☺");
pokers.add("大☹");
// System.out.println(pokers.size());
// System.out.println(pokers);
// 洗牌
// shuffle方法:随机排列. 注意:只能在有排列顺序的List接口中使用
Collections.shuffle(pokers);
// System.out.println(pokers);
return pokers;
}
// 发牌,留底牌
public void licensingPoker(ArrayList<String> list) {
ArrayList<String> first = new ArrayList<>();
ArrayList<String> second = new ArrayList<>();
ArrayList<String> third = new ArrayList<>();
ArrayList<String> down = new ArrayList<>();
for (int i = 0; i < list.size(); i++) {
String card = list.get(i);
if (i < 51 && i % 3 == 0) {
first.add(card);
} else if (i < 51 && i % 3 == 1) {
second.add(card);
} else if (i < 51 && i % 3 == 2) {
third.add(card);
} else {
down.add(card);
}
}
System.out.println("第一个玩家的牌:" + first);
System.out.println("第二个玩家的牌:" + second);
System.out.println("第三个玩家的牌:" + third);
System.out.println("底牌:" + down);
}
}
// 测试类
public class FightAgainstLandlords {
public static void main(String[] args) {
Poker poker = new Poker();
poker.licensingPoker(poker.pokerContainer());
}
}
3.2. LinkedList集合
LinkedList集合特性:
- 基于链表数据结构实现
- 查询效率低
- 增删效率高
链表的结构:
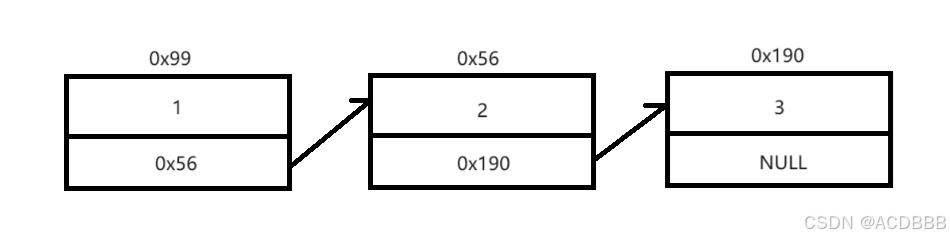
由于链表中的节点内存地址不连续,所以会增加查找元素时的查找时间,因此查找效率比较低。
但是在元素新增或删除时,只需要改变元素的指针指向,因此增删效率高。
3.2.1. LinkedList集合的常用方法
LinkedList集合对象构造方法:
public class LinkedListDemo1 {
public static void main(String[] args) {
// 创建一个LinkedList
List<String> list = new LinkedList<String>();
list.add("a");
list.add("b");
list.add("s");
list.add("d");
list.add("e");
System.out.println(list); // [a, b, s, d, e]
// 将ArrayList转换为LinkedList
List<String> strings = new ArrayList<>();
strings.add("a");
strings.add("g");
strings.add("e");
strings.add("w");
List<String> list1 = new LinkedList<>(strings);
System.out.println(list1); // [a, g, e, w]
}
}
依旧通过举例了解LinkedList集合常见方法:
public class LinkedListDemo1 {
public static void main(String[] args) {
LinkedList<String> strings1 = new LinkedList<>(Arrays.asList(null, "a", "b", "c", "e", "m"));
// 获取集合中第一个元素
System.out.println(strings1.getFirst()); // a
// 获取集合中最后一个元素
System.out.println(strings1.getLast()); // m
// 在集合开始添加
strings1.addFirst("A");
System.out.println(strings1); // [A, a, b, c, e, m]
// 在集合末尾添加
strings1.addLast("Z");
System.out.println(strings1); // [A, a, b, c, e, m, Z]
// 删除头元素
System.out.println(strings1.removeFirst()); // A
System.out.println(strings1); // [a, b, c, e, m, Z]
// 删除末尾元素
System.out.println(strings1.removeLast()); // Z
System.out.println(strings1); // [a, b, c, e, m]
// 删除队列头部元素
System.out.println("remove:" + strings1.remove(0)); // null
System.out.println("poll:" + strings1.poll()); // a
System.out.println(strings1); // [b, c, e, m]
// 出栈方法,删除头部元素
System.out.println(strings1.pop()); // b
System.out.println(strings1); // [c, e, m]
// 添加元素到队列尾部
strings1.offer("HH");
System.out.println(strings1); // [c, e, m, HH]
}
}
在学习LinkedList集合方法的时候,我发现有很多方法的作用是相同的,比如remove、pop和poll。
查找资料的时候看到有人说:poll() 同方法 remove() 的区别为是当头部元素为 null 时,remove() 方法会抛 NoSuchElementException 异常,poll() 方法返回 null。这句话是不对的,我自己尝试的时候发现三个方法都不会抛出异常,且都可以返回null。
那他们的区别到底是什么呢?
后来看到了一个比较靠谱的解释,他们的区别是他们分别继承自不同的接口。
原文在这Java的LinkedList/Deque中add/offer/push,remove/pop/poll的区别
由于LinkedList的继承关系,导致这些方法全部出现在了LinkedList下:
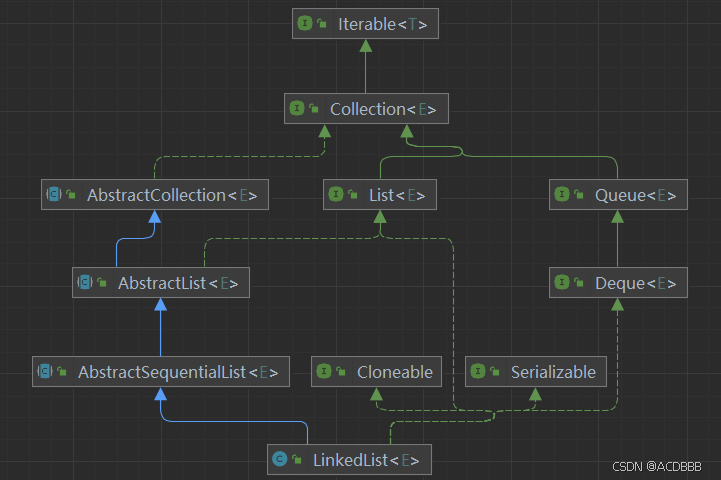
- 从Collection继承了:add 和 remove,源自集合
- 从Queue继承了:offer 和 poll,源自队列
- 从Deque继承了:push 和 pop,源自栈;offerFirst / offerLast 和 pollFirst / pollLast,源自双端队列
- push 和 pop 本来属于Stack,只不过已不再使用,用Deque代替,本质是栈
- offerFirst / offerLast 和 pollFirst / pollLast 源自Deque,是双端队列
这些方法的作用,其实和其出处的数据类型特点有关,总结来说:
- add / offer / offerLast 等价:添加元素到队尾
- push / offerFirst 等价:添加元素到队头
- remove / pop / poll / pollFirst 等价:删除队头元素
- pollLast :删除队尾元素
四、常见数据结构
这里仅对常见的数据结构做初步了解,了解这些数据结构的特点和简单规则即可。
1. 栈
栈的图解:
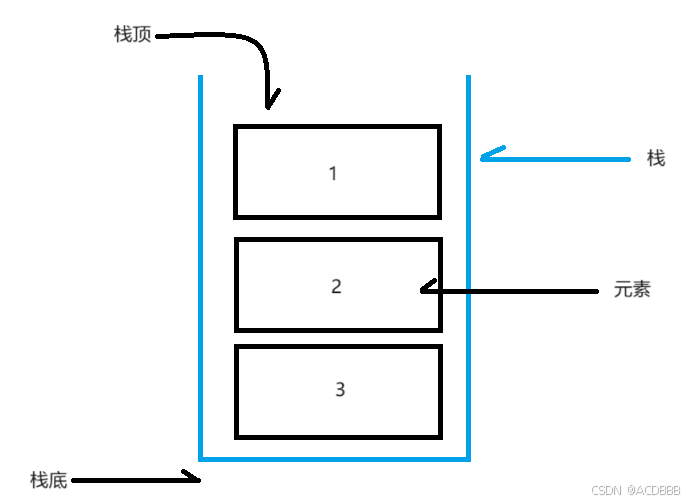
其实从栈的图解就能看出,栈只有一端开口,即栈只允许在栈顶这一头进行增删操作,这就决定了栈的进出规则先进后出(FILO)。
简单的说:采用该结构的集合,对元素的存取有如下的特点:
- 先进后出,即存进去的元素,要在后它后面的元素依次取出后,才能取出该元素
- 栈的入口、出口的都是栈的顶端位置
2. 队列
队列图解:
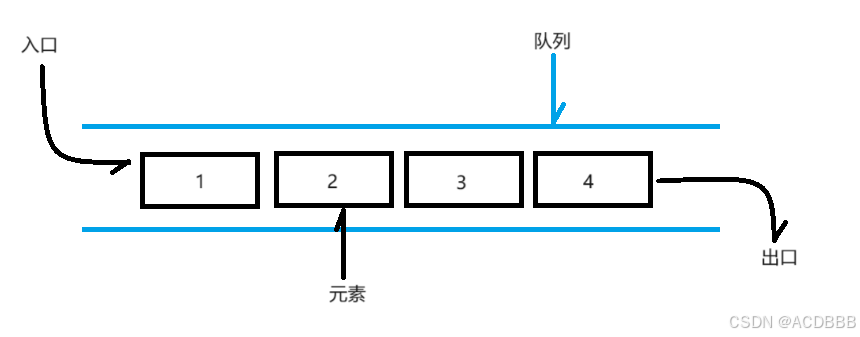
与栈不同,队列的限制是仅允许在表的一端插入,而在另一端进行删除。这决定了队列的进出规则先进先出(FIFO)。
简单的说:采用该结构的集合,对元素的存取有如下的特点:
- 先进先出,即先存进去的元素,也会先取出
- 队列的入口在一端,出口在另一端
3.数组
数组Array,是有序的元素序列,数组是在内存中开辟一段连续的空间,并在此空间存放元素。就像是一排出租屋,有100个房间,从001到100每个房间都有固定编号,通过编号就可以快速找到租房子的人。
简单的说,采用该结构的集合,对元素的存取有如下的特点:
- 查找元素快:通过索引,可以快速访问指定位置的元素
- 增删元素慢:
- 指定索引位置增加元素:需要创建一个新数组,将指定新元素存储在指定索引位置,再把原数组元素根据索引,复制到新数组对应索引的位置
- 指定索引位置删除元素:删除元素之后,为了保证元素的内存地址的连续性,要前移元素
4. 树
树是一种数据结构,它是 n(n>=0)个节点的有限集。n=0 时称为空树。n>0 时,有限集的元素构成一个具有层次感的数据结构。区别于线性表一对一的元素关系,树中的节点是一对多的关系。
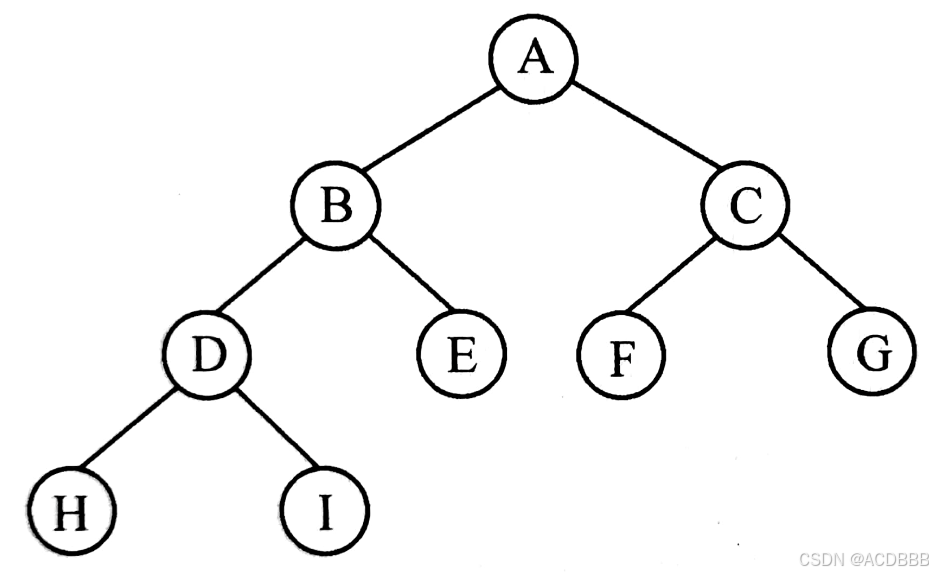
树的相关概念:
- 根节点:对于树来说,根节点是唯一的,不会存在多个根节点
- 子树:除根节点外,每个子节点都可以分为多个不相交的子树
- 孩子与双亲:若一个节点有子树,则该节点为子树根的双亲;子树的根是该节点的孩子。如:上图中,B、C节点是A的孩子,A是B、H的双亲
- 兄弟:具有相同双亲的节点互为兄弟,如:上图中,B、C互为兄弟
- 节点的度:一个节点拥有子树的数目。如:上图中,B的度为2
- 叶子:没有子树,度为0的节点
- 分支节点:除叶子节点外的节点,度不为0。
- 内部节点:除根之外的分支节点
- 层次:根节点为第一层,其余节点的层次为其双亲节点的层次数加1
- 树的高度:也叫树的深度,树中节点最大的层次
- 有序树:树中各节点存在次序,不可随意交换位置
- 无序树:树中各节点次序不重要,可以交换位置
- 森林:0或多颗互不相交的树的集合
了解完基本概念后,加下来我们会来介绍三种树
4.1. 平衡二叉树
平衡二叉树具有以下特点:是一棵空树 或 左右两个子树的高度差的绝对值不超过1,并且左右两个子树都是一棵平衡二叉树。
且平衡二叉树一般是一个有序树,元素在存放的时候,需要和根节点中的元素进行比较,大的放在下一层级的右边,小的放左边。
平衡二叉树具有二叉树的所有性质,遍历方式也相同。但是由于对二叉树施加了额外限制,所以其添加、删除操作都必须保证平衡二叉树的平衡。
这里引入一个概念:平衡二叉树的平衡因子。指的是该节点左右两个子树的高度差。如果该节点某个子树不存在,该子树高度就为0。
平衡二叉树要求左右子树的高度差的绝对值不能超过1,超过就要根据情况调整。
4.1.1. 破坏平衡型的类型
在讲类型前我们需要了解两个概念:
- 麻烦节点:插入这个节点,会导致树的平衡性被破坏,这个节点就是麻烦节点
- 被破坏节点:被麻烦节点破坏平衡性的节点,叫被破坏节点
并且所有型号的判断只从被破坏节点开始判断两次,即不管你第三次新插入节点的位置在左还是在右。
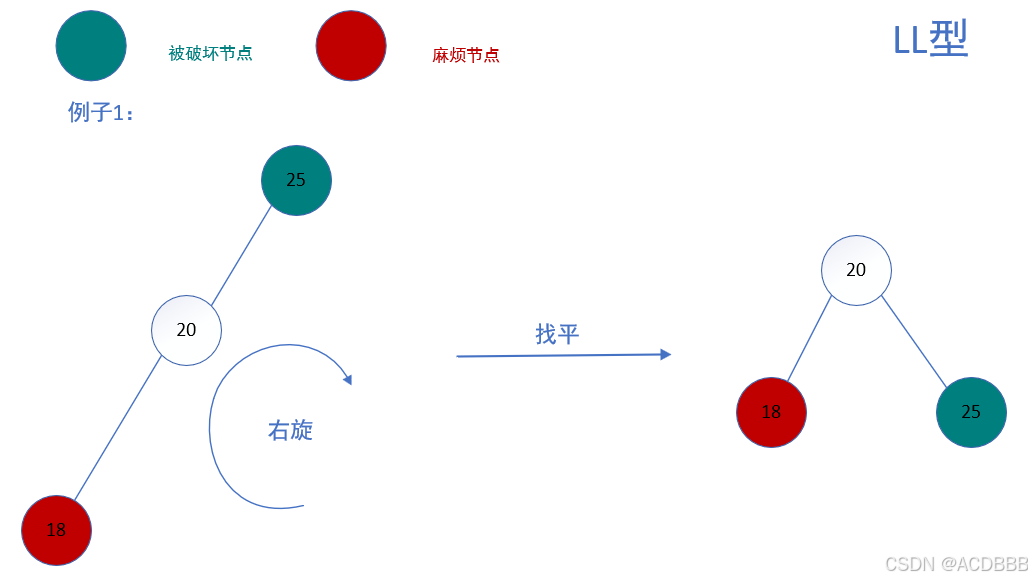
LL型:在被破坏节点的左边的左边插入而导致失衡,也叫左左型
- 解决方法:以被破坏节点为基础进行右旋
右旋的做法:
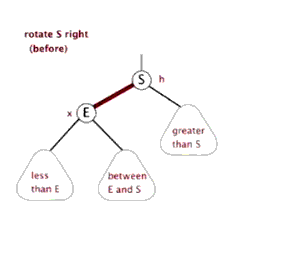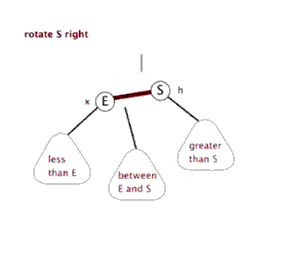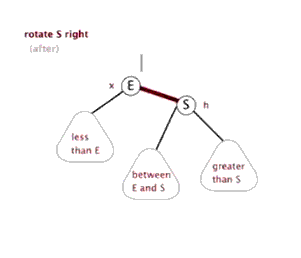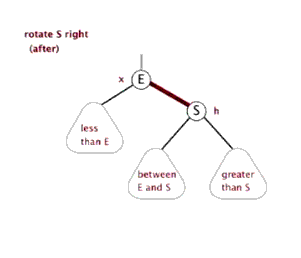
例子1:
例子2:
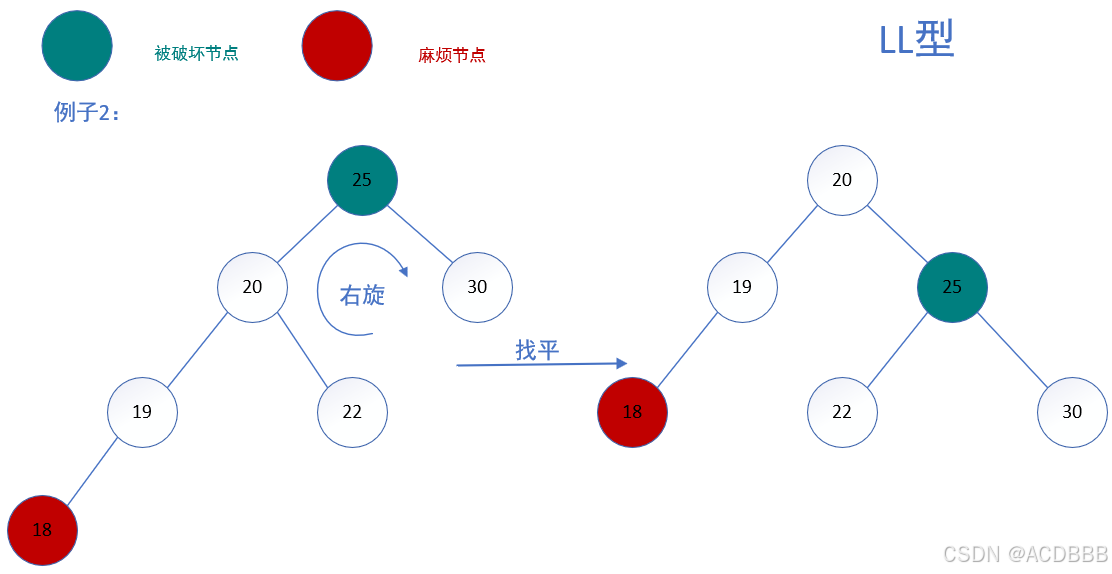
例子3:
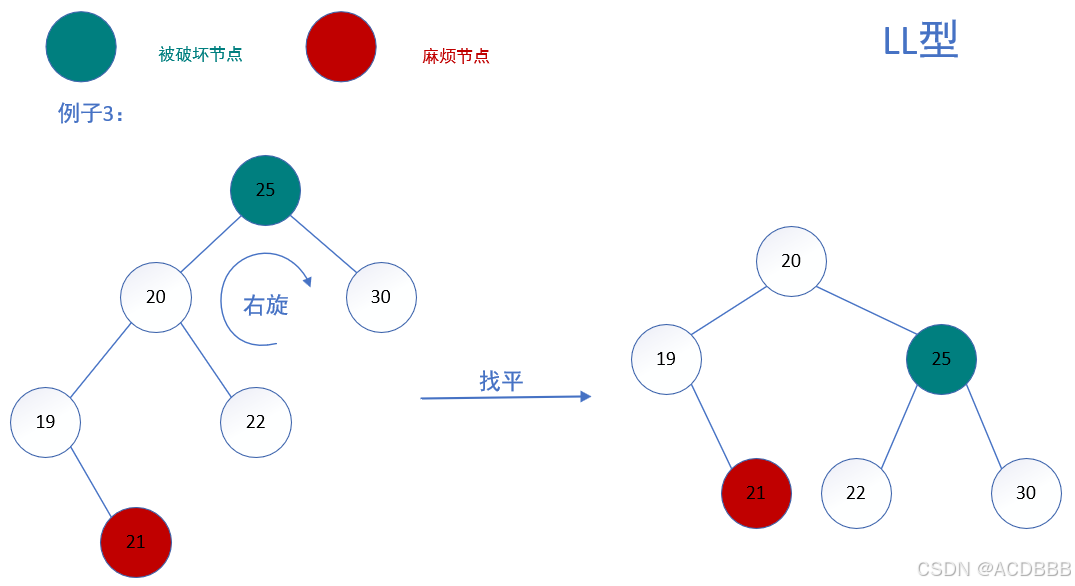
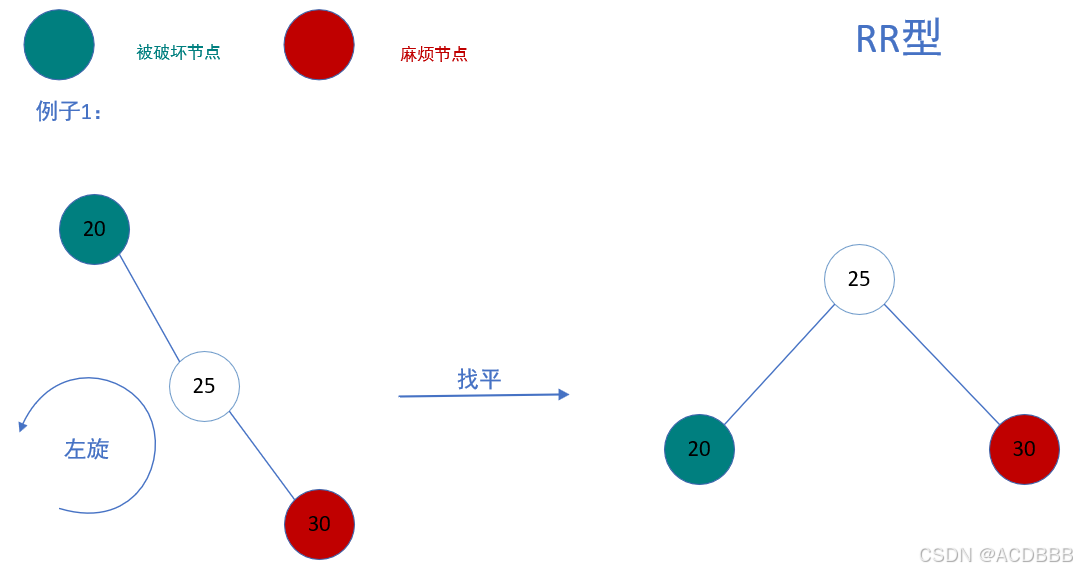
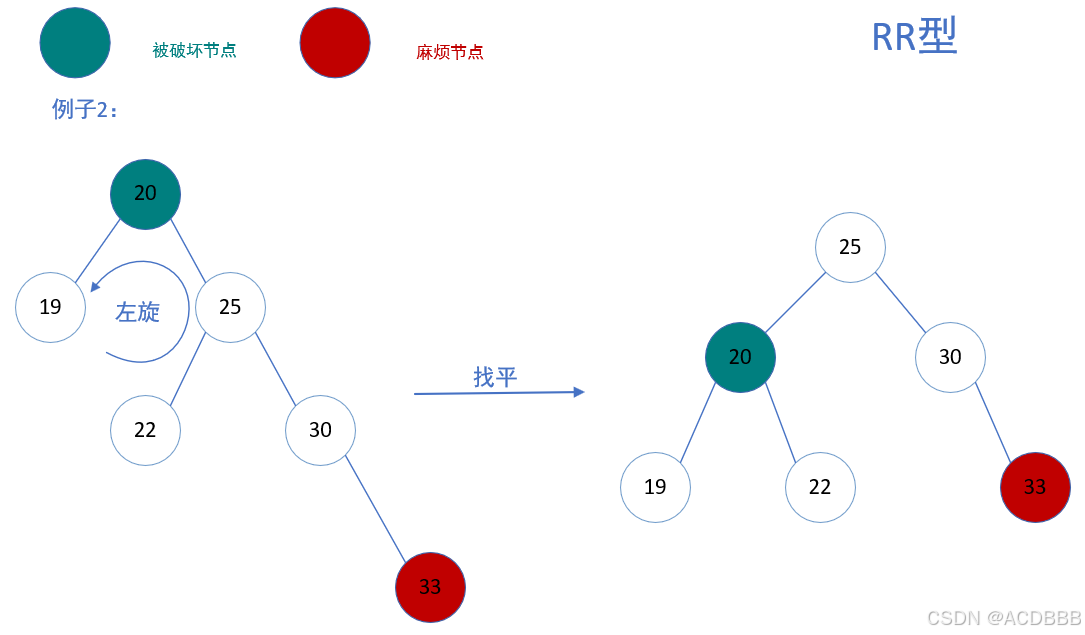
RR型:在被破坏节点的右边的右边插入而导致失衡,也叫右右型
- 解决方案:以被破坏节点为基础进行左旋
左旋的方法:
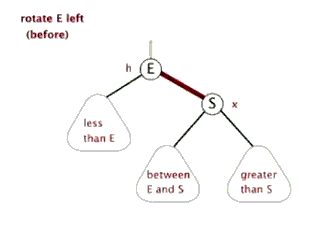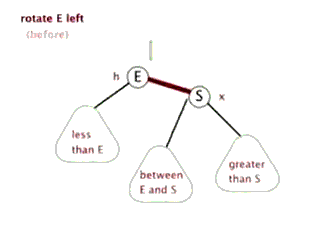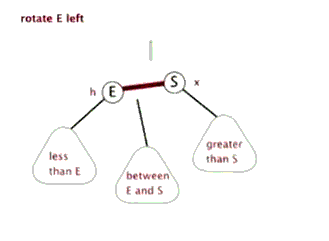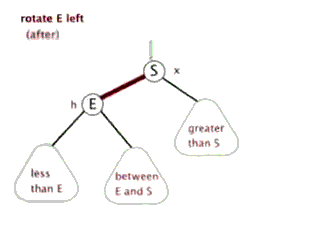
例子1:
例子2:
例子3:
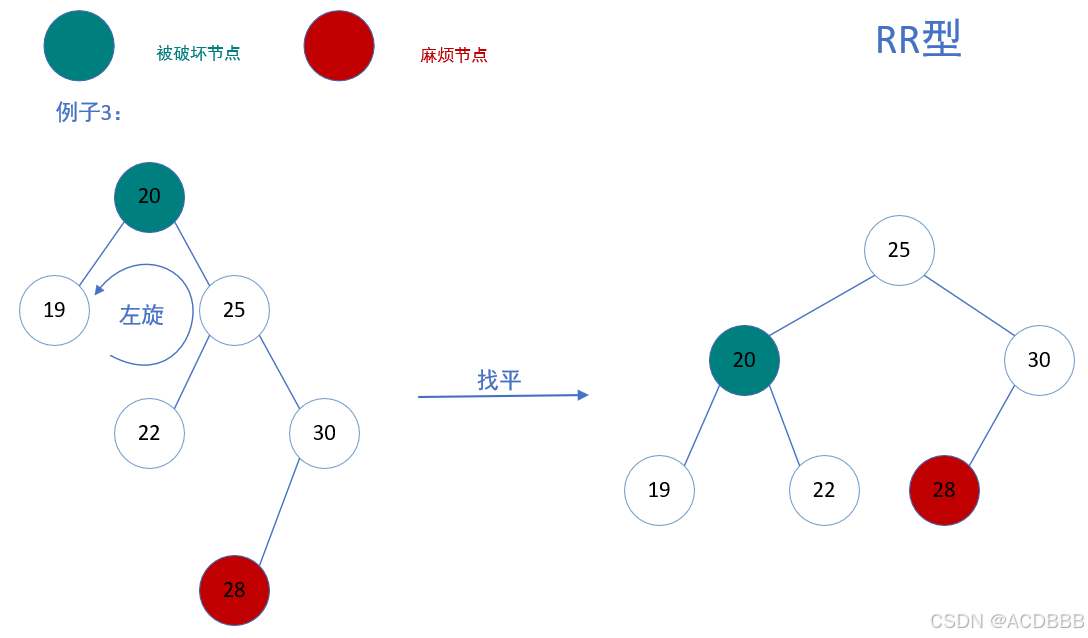
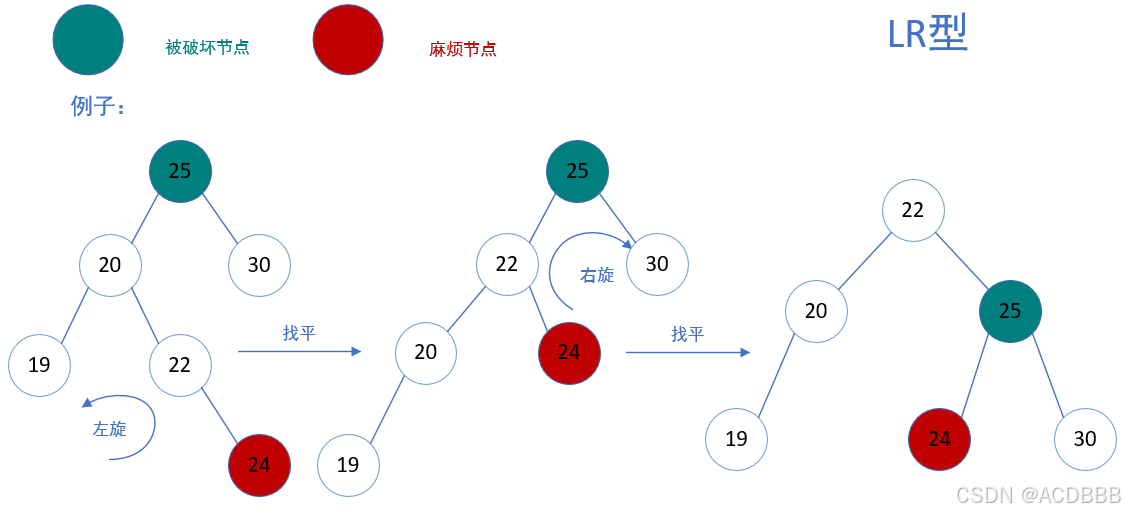
LR型:在被破坏节点的左边的右边插入而导致失衡,也叫左右型
- 解决方案:以被破坏节点左节点为基础先进行一次左旋,再以被破坏节点为基础进行右旋
例子:简单来说,就是将LR型的先转化为LL型的,再找平
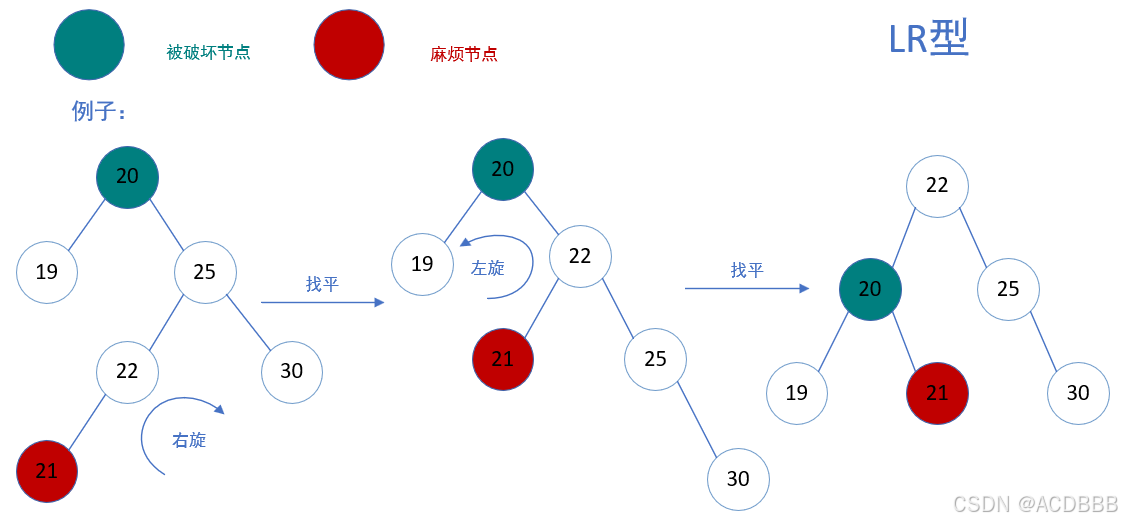
RL型:在被破坏节点的右边的左边插入而导致失衡,也叫右左型
- 解决方案:以被破坏节点右节点为基础先进行一次右旋,再以被破坏节点为基础进行左旋
例子:简单来说,就是将RL型的先转化为RR型的,再找平
总结:
- RR型和LL型:以被破坏节点为基础进行其反向的旋转即可
- RL型:先以被破坏节点的右节点右旋,再以被破坏节点为基础左旋
- LR型:先以被破坏节点的左节点左旋,再以被破坏节点为基础右旋
4.2. B-Tree
BTree又叫多路平衡搜索树,一颗m叉的BTree特性如下:
- 树中每个节点最多包含m个子节点
- 除根节点与叶子节点外,每个节点至少有[ceil(m/2)]个子节点(即m/2向上取整)
- 若根节点不是叶子节点,则至少有两个孩子
- 所有的叶子节点都在同一层
- 每个非叶子节点由n个key与n+1个指针组成,其中[ceil(m/2)-1] <= n <= m-1
以5叉树为例:
- 5叉树中每个节点最多有5个子节点(即5个指针)
- 除根节点和叶子结点外,每个节点至少有3个子节点
- 若根节点不是叶子节点,则至少有两个孩子
- 所有叶子节点都在同一层
- 每个非叶子节点由4个key与5个指针组成,其中2 <= n <= 4
插入 11 2 34 1 4 17 15 18 26 101 55 为例,演变过程如下:
- 插入前四个数字11 2 34 1
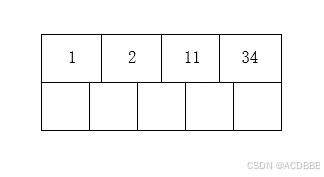
- 插入4,n>4,中间节点4向上分裂
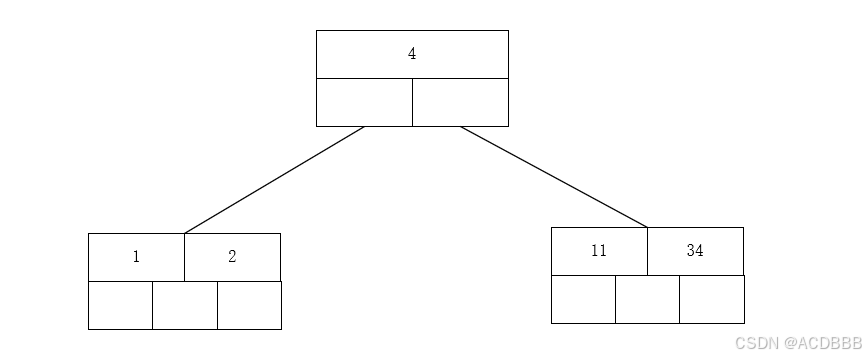
- 插入17 15 不用分裂节点
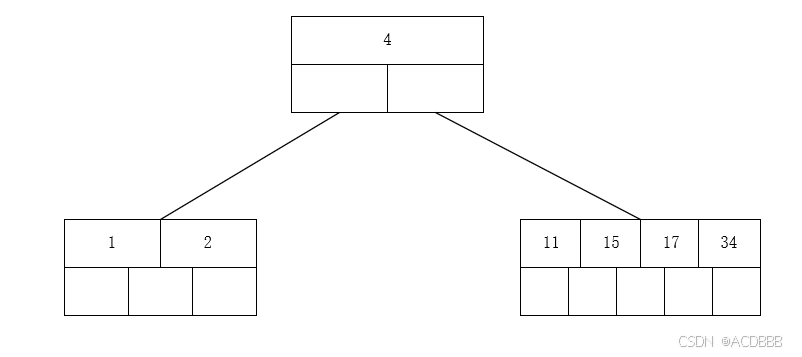
- 插入18,17向上分裂到上一节点
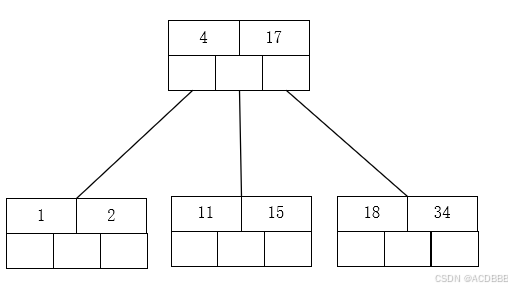
- 插入26 101 不用分裂
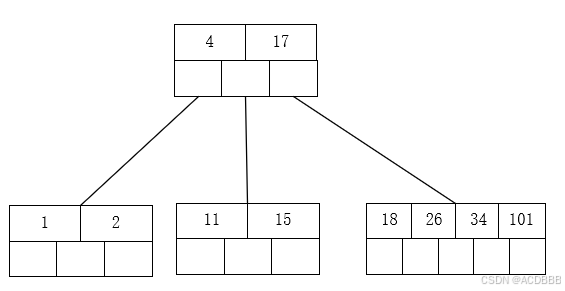
- 插入55,34向上分裂到上一节点
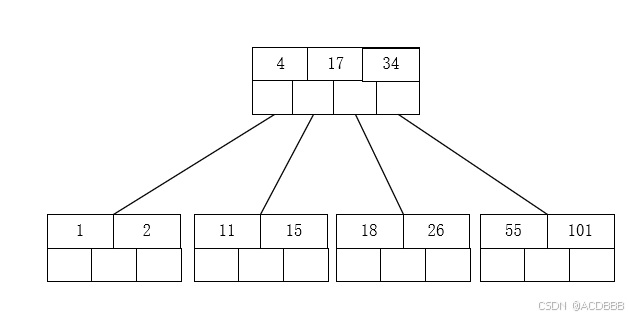
到此分裂完成
BTree树和二叉树相比,查询数据的效率更高,因为对于相同的数据量来说,BTree的层级结构比二叉树小,因此搜索速度快。
4.3. 红黑树
红黑树是一种自平衡的二叉查找树。它是一种特殊的二叉查找树,红黑树的每一个节点上都有存储位表示节点的颜色,可以是红或者黑。
红黑树不是高度平衡的,它的平衡是通过"红黑树的特性"进行实现的;
红黑树的特性:
- 每一个节点或是红色的,或者是黑色的
- 根节点必须是黑色
- 每个叶节点(Nil)是黑色的(如果一个节点没有子节点或者父节点,则该节点相应的指针属性值为Nil,这些Nil视为叶节点)
- 如果某一个节点是红色,那么它的子节点必须是黑色(不能出现两个红色节点相连的情况)
- 对每一个节点,从该节点到其所有后代叶节点的简单路径上,均包含相同数目的黑色节点
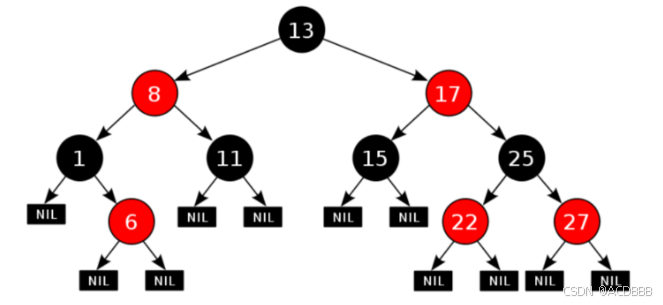
在进行元素插入的时候,和之前一样: 每一次插入完毕以后,使用黑色规则进行校验,如果不满足红黑规则,就需要通过变色,左旋和右旋来调整树,使其满足红黑规则。
红黑树可以通过红色节点和黑色节点尽可能的保证二叉树的平衡,从而来提高效率。

















 1517
1517

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









