






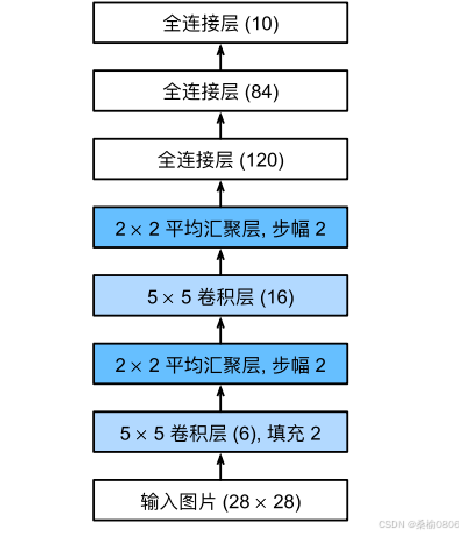
LeNet架构
手写数字识别
数据复杂度:居中缩放
50,000个训练数据
10,000个测试数据图像
大小28*28
10类
总体来看,LeNet(LeNet-5)由两个部分组成:· 卷积编码器:由两个卷积层组成;
· 全连接层密集块:由三个全连接层组成;
每个卷积层使用5×5卷积核和一个sigmoid激活函数。
LeNet简化版
学习表征

浅层学习:不涉及特征学习,其特征主要靠人工经验或特征转换方法
表示学习:如果有一种算法可以自动地学习出有效的表示,并提高最终机器学习模型的性能,那么这种学习就可以叫作表示学习
通常需要从底层特征开始,经过多步非线性转换才能得到
通过构建具有一定“深度”的模型,可以让模型来自动学习好的特征表示(从底层特征,到中层特征,再到高层特征),从而最终提升预测或识别的准确性
视觉分析理论
视觉分析理论,从底层到高层的不断抽象。
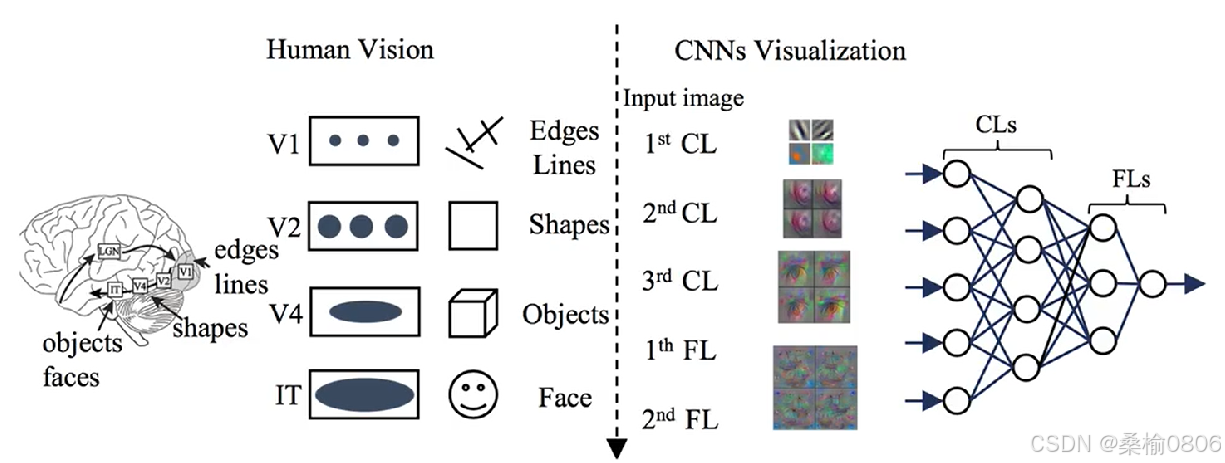
底层:浅层卷积核提取边缘、颜色、斑块等底层像素特征

中层:中层卷积核提取条纹、纹路、形状等中层纹理特征

高层:高层卷积核提取眼睛、轮廓、文字等高层语义特征

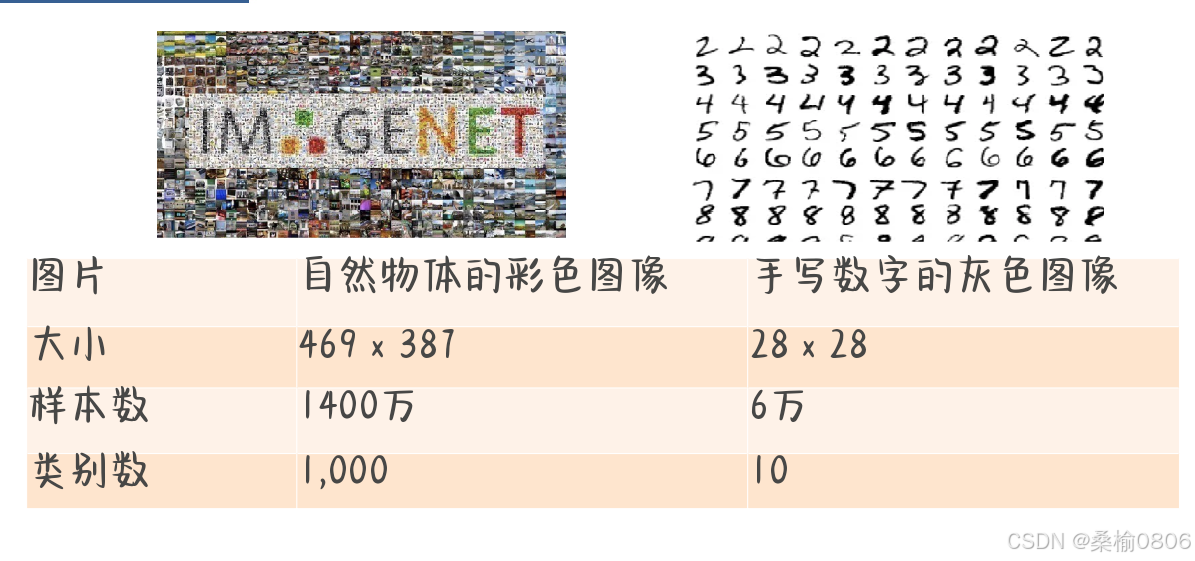
lmageNet数据集(2010)
自然物体的彩色图像:大小469 x 387,样本数300万,类别数1,000
手写数字的灰色图像:大小28 x 28 ,样本数无明确提及,类别数10
AlexNet架构
成就:在2012年赢得了ImageNet竞赛
改进:主要对LeNet
改进包括丢弃法(防止过拟合)
ReLU激活函数(训练)
更大的池化法
计算视觉的范式变化
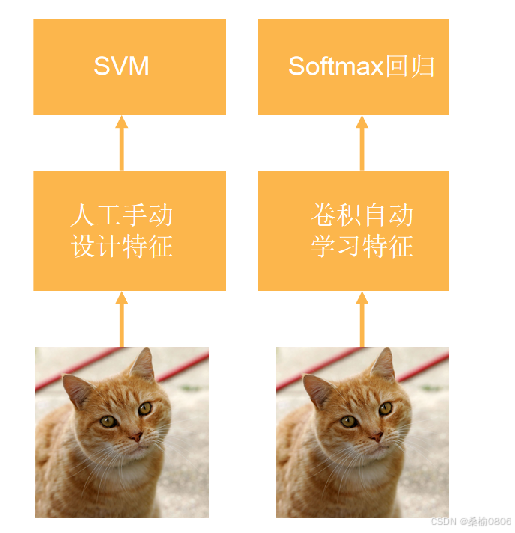
架构对比:比LeNet更深,由八层组成(五个卷积层、两个全连接隐藏层和一个全连接输出层)
使用ReLU而不是sigmoid作为激活函数
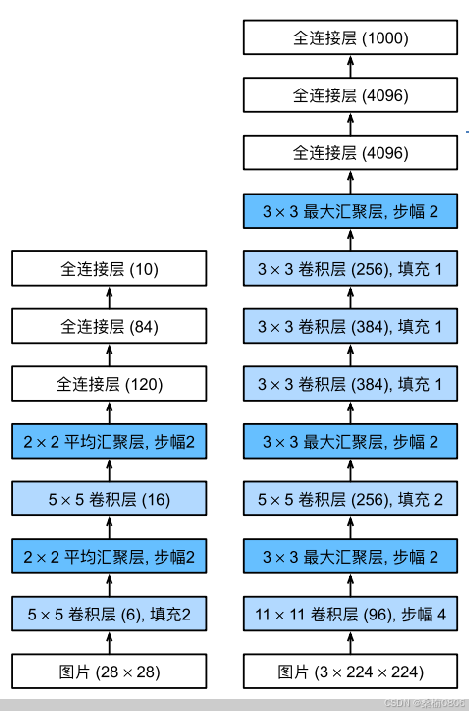
更多细节
细参数更新过小,在每次更新时几乎不会移动,导致模型无法学习
- 将激活函数从sigmoid更改为ReLu(减缓梯度消失)
- 在两个隐含层之后应用丢弃法(更好的稳定性/正则化)
- 数据增强
梯度爆炸:参数更新过大,破坏了模型的稳定收敛。

总结
· AlexNet的架构与LeNet相似,但使用了更多的卷积层和更多的参数来拟合大规模的ImageNet数据集。
· 今天,AlexNet已经被更有效的架构所超越,但它是从浅层网络到深层网络的关键一步。
· 新加入了Dropout、ReLU、最大池化层和数据增强
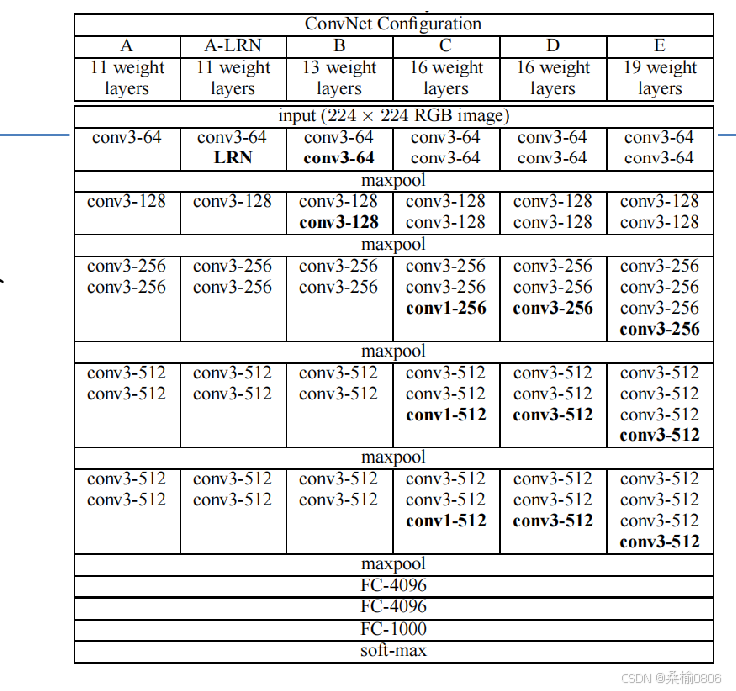
VGG网络
特点:比AlexNet更深更大,以获得更强性能,更多的卷积层,更小的卷积核(3x3),将卷积层组合成块
模块(VGG块):3x3卷积(填充=1,步幅=1),2x2最大池化层(步幅=2),更深和更窄更好
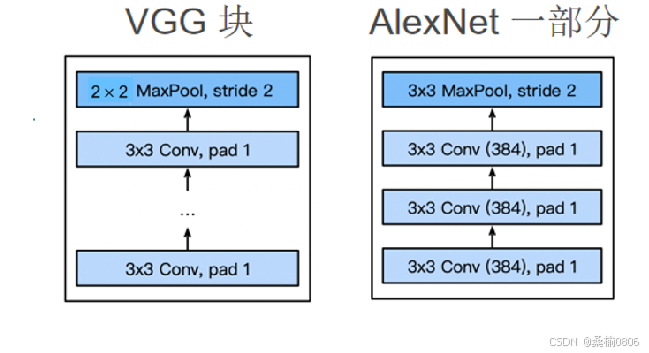
架构构建:多个VGG可重复叠加全连接层,来构建原始的VGG神经网络
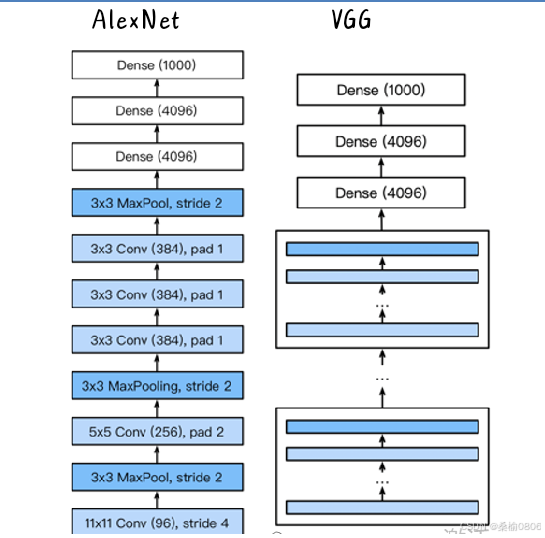
通过不同次数的重复VGG块,可获得不同的架构。
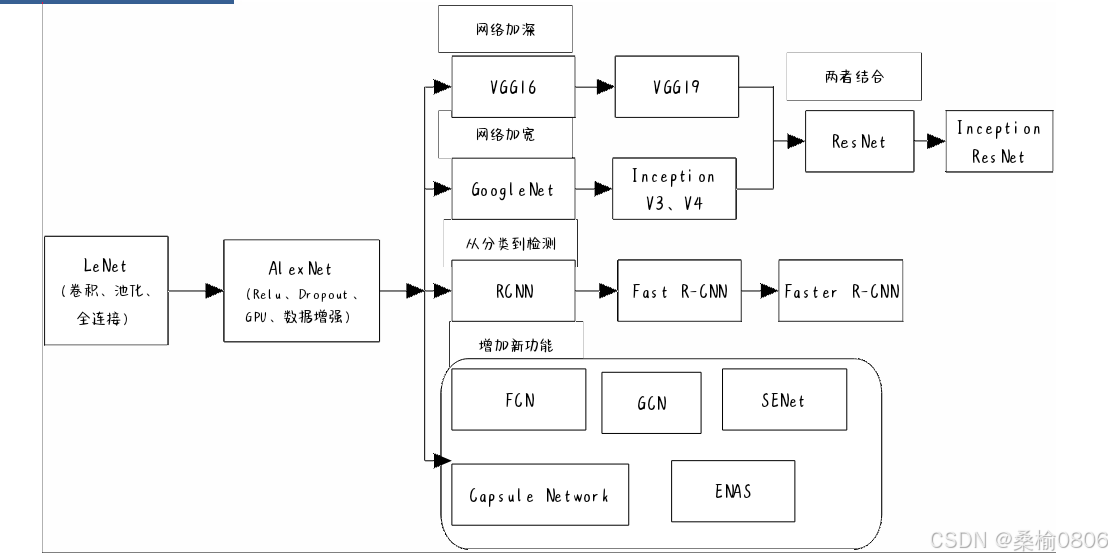
发展
- LeNet(1995)
- 2卷积层+池化层
- 2隐含层
- AlexNet
- 更大更深的LeNet
- ReLu激活,丢弃法,预处理
- VGG
- 更大更深的AlexNet(重复的VGG块)

















 422
422

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









