



**摘要**:本文带你系统梳理华为CANN(Compute Architecture for Neural Networks)的整体架构设计,解析其如何打通芯片、驱动、运行时与上层框架之间的壁垒,实现端到端高效AI计算。适合对昇腾生态感兴趣的开发者、算法工程师和架构师阅读。
一、什么是CANN?为什么它如此重要?
CANN(Compute Architecture for Neural Networks)是华为面向AI计算推出的一套全栈软件栈,专为昇腾(Ascend)系列AI处理器设计。它的核心使命是:让开发者无需关心硬件细节,也能充分发挥昇腾芯片的强大算力。
与CUDA之于NVIDIA类似,CANN是昇腾生态的“灵魂”,但它的设计理念更强调:
-异构计算统一调度
- 自动算子生成
- 跨框架兼容性(支持 TensorFlow/PyTorch /Mind Spore )
CANN vs CUDA:关键差异对比
| 特性 | CANN | CUDA |
|------|------|-------|
| 支持框架 | 多框架适配(通过Adapter) | 主要服务PyTorch/TensorFlow |
| 算子开发方式 | TBE(Tensor Boost Engine)+ AICPU | CUDA Kernel 手写 |
| 自动优化 | 支持自动Buffer融合、流水调度 | 需手动优化 |
| 开发生态 | 国产自主可控,强政策支持 | 成熟但受制于国外 |
二、CANN整体架构分层详解
CANN采用典型的“五层架构”模型:
| 应用层 (App) | + | 框架层 (Framework) | ← TensorFlow / PyTorch / MindSpore + | API层 (ACL) | ← AscendCL 编程接口 +…… | 运行时 & 调度层 | ← Task Dispatch, Memory Management+ | 驱动与固件层 | ← Firmware, Driver, Kernel +……
1. 框架层:多框架无缝接入
通过 Framework Adapter,CANN实现了对主流AI框架的支持:
MindSpore:原生支持,性能最优
- PyTorch/TensorFlow:通过 `ge_runner` 或第三方工具链转换ONNX模型后部署
> 💡 示例:使用 `tf2onnx` + `omg` 工具将TF模型转为 `.om` 模型,在Ascend上推理。
2. ACL(Ascend Computing Language)
这是CANN最核心的编程接口,提供C/C++/Python三种绑定,用于:
- 内存管理(malloc/free)
- 模型加载与执行
- 数据传输控制(Host ↔ Device)
- 事件同步与性能分析
```python
import acl
# 初始化环境
acl.init()
# 加载OM模型
model = acl.mdl.load_from_file("resnet50.om")
# 创建输入输出buffer
input_buf = acl.rt.malloc(224*224*3*4)
output_buf = acl.rt.malloc(1000*4)
# 推理执行
acl.mdl.execute(model, [input_buf], [output_buf])
3. 算子引擎:TBE 与 AICPU 双轮驱动
TBE(Tensor Boost Engine):基于DSL(领域专用语言)自动生成高效AI Core算子
AICPU:处理复杂逻辑或不规则计算(如TopK、Sort)
⚙️ TBE支持自动向量化、流水线优化,显著降低开发门槛。
三、典型应用场景与优势
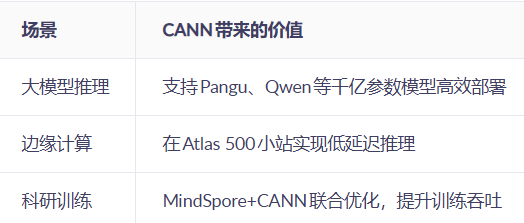
✅ 案例:某金融客户使用CANN部署BERT模型,相较CPU方案提速47倍,功耗下降60%。
四、如何开始学习CANN?
推荐路径如下:

五、结语
CANN不仅是昇腾的软件底座,更是中国构建自主AI生态的关键一步。随着国产替代加速推进,掌握CANN将成为AI工程师的重要竞争力。
👉 如果你正在从事AI基础设施、模型部署或高性能计算相关工作,强烈建议深入研究CANN体系。
报名链接:https://www.hiascend.com/developer/activities/cann20252
💬 欢迎在评论区分享你的CANN实践心得!点赞+收藏不迷路~

















 569
569

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









