






一、LLM基本概念
大模型LLM(Large Language Model)是指具有大规模参数和复杂计算结构的机器学习模型。这些模型通常由深度神经网络构建而成,拥有数十亿甚至数千亿个参数。大模型的设计目的是为了提高模型的表达能力和预测性能,能够处理更加复杂的任务和数据。大模型在各种领域都有广泛的应用,包括自然语言处理、计算机视觉、语音识别和推荐系统等。大模型通过训练海量数据来学习复杂的模式和特征,具有更强大的泛化能力,可以对未见过的数据做出准确的预测。
二、发展历程与技术原理
1.演进路径
早期阶段(20世纪90年代-2010年):基于统计方法的语言模型(N-gram)主导,受限于数据量与计算能力。
深度学习阶段(2013年-2018年):引入RNN、LSTM等神经网络,通过词嵌入技术提升语义理解能力。
预训练时代(2018年至今):Transformer架构(如BERT、GPT系列)成为主流,通过自监督学习实现大规模无标注文本预训练,突破模型参数上限。
2.技术架构
自注意力机制:动态捕捉文本长距离依赖关系,解决传统RNN的梯度消失问题。
预训练任务:掩码语言建模(BERT)、自回归生成(GPT)等,驱动模型学习语言通用规律。
三、大模型图谱
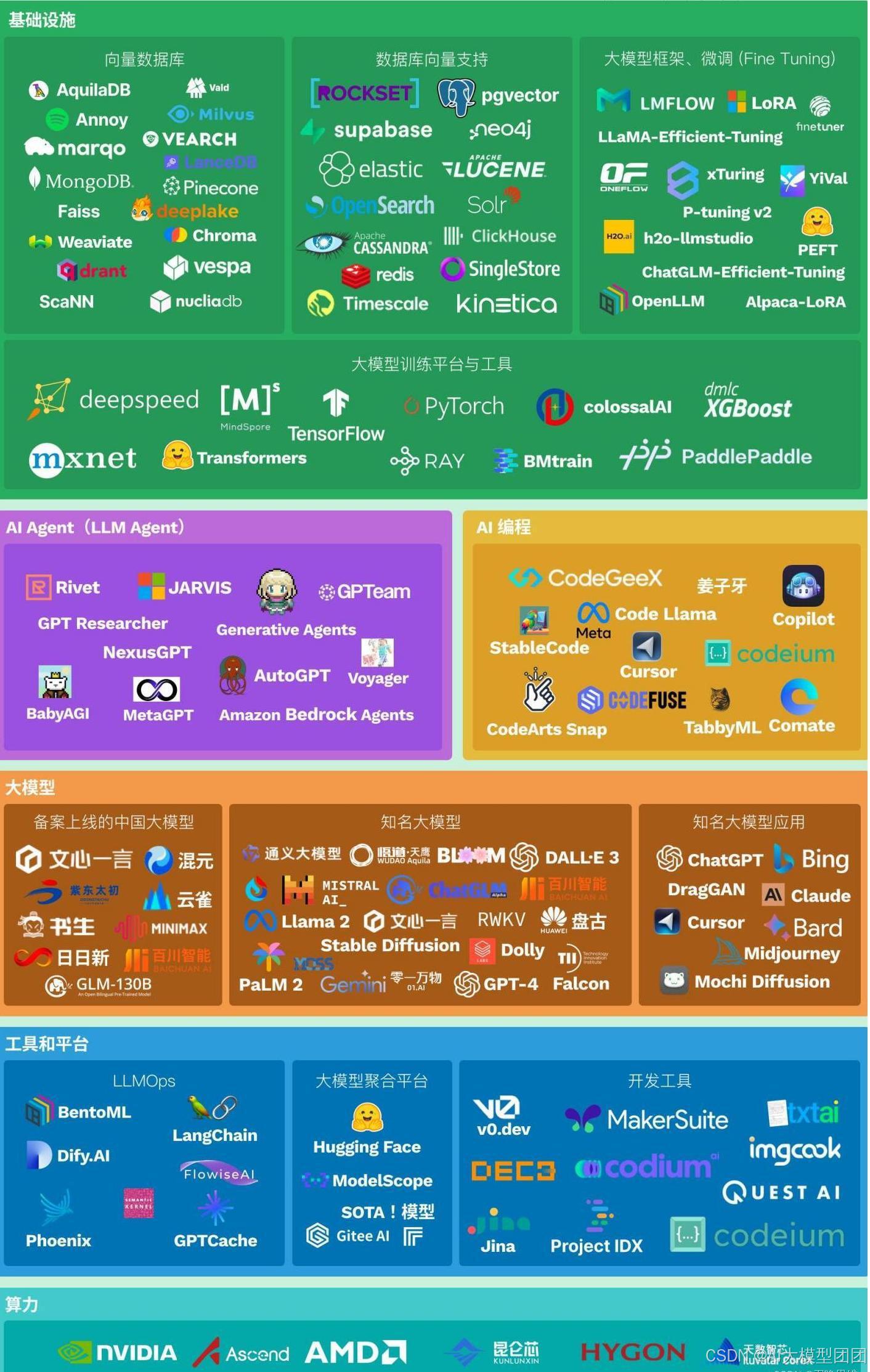
四、如何从入门到精通LLM?
1.入门阶段:学习基础知识
理解自然语言处理基础:了解NLP的基本任务(如词性标注、命名实体识别、情感分析等)。
学习深度学习基础:掌握深度学习的基本概念,尤其是神经网络的工作原理,如反向传播、梯度下降等。
熟悉Transformer架构:Transformer是LLM的核心,因此深入理解其工作原理、自注意力机制、位置编码等知识至关重要。
2.进阶阶段:实践与应用
使用预训练模型:借助开源的预训练模型(如Hugging Face的Transformers库)进行实践。你可以快速加载像 GPT、BERT 这样的预训练模型,进行文本分类、翻译、生成等任务。
参与Kaggle比赛:Kaggle是一个很好的实践平台,参加NLP相关的比赛,解决真实世界的问题。
3.高级阶段:理解模型的训练与优化
训练自己的LLM:当你掌握了基本使用方法后,可以尝试微调或训练自己的LLM。在云平台(如AWS、Google Cloud)上配置GPU,进行模型的训练。
探索模型优化与解释性:学习如何通过知识蒸馏、剪枝、量化等方法优化LLM的大小和性能。同时,研究如何提高LLM的解释性,使其更易理解和控制。
五、未来趋势
1.技术突破
多模态融合:整合文本、图像、语音数据,扩展应用边界(如智能座舱多模态交互)。
认知智能升级:从“模式匹配”向逻辑推理、因果推断等深层能力演进。
2.生态发展
垂直领域深化:开发医疗、法律等专用模型,提升行业适配性。
开源与标准化:推动模型开源(如LLaMA系列)与安全测试国际标准(如《大语言模型安全测试方法》)落地。
要么驾驭AI,要么被AI碾碎
当DeepSeek大模型能写出比80%人类更专业的行业报告,当AI画师的作品横扫国际艺术大赛,这场变革早已不是“狼来了”的寓言。2025年的你,每一个逃避学习的决定,都在为未来失业通知书签名。
记住:在AI时代,没有稳定的工作,只有稳定的能力。今天你读的每一篇技术文档,调试的每一个模型参数,都是在为未来的自己铸造诺亚方舟的船票。
1.AI大模型学习路线汇总

L1阶段-AI及LLM基础
L2阶段-LangChain开发
L3阶段-LlamaIndex开发
L4阶段-AutoGen开发
L5阶段-LLM大模型训练与微调
L6阶段-企业级项目实战
L7阶段-前沿技术扩展
2.AI大模型PDF书籍合集

3.AI大模型视频合集
4.LLM面试题和面经合集
5.AI大模型商业化落地方案

📣朋友们如果有需要的话,可以V扫描下方二维码联系领取~


















 541
541

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









