



卷积神经网络(CNN)提出了这么久,针对于CNN的改进还能拿下顶会吗?
DCNv4在继承对前几版本DCN对卷积核改进的成果外,针对于DCN算子的计算速度做出了更多改进,成功拿下CVPR2024。DCN相较于传统CNN的核心优势在于其动态适应性和灵活性。传统CNN的卷积核限制了其对目标的建模能力,而DCN通过引入可学习的偏移量,使得卷积核能够根据输入内容动态调整。
我整理了各版本可变形卷积网络(v1 - v4)的论文将帮助大家深入了解DCN。
点击【AI十八式】的主页,获取更多优质资源!
一、Deformable Convolutional Networks(DCNv1)
1.方法
-
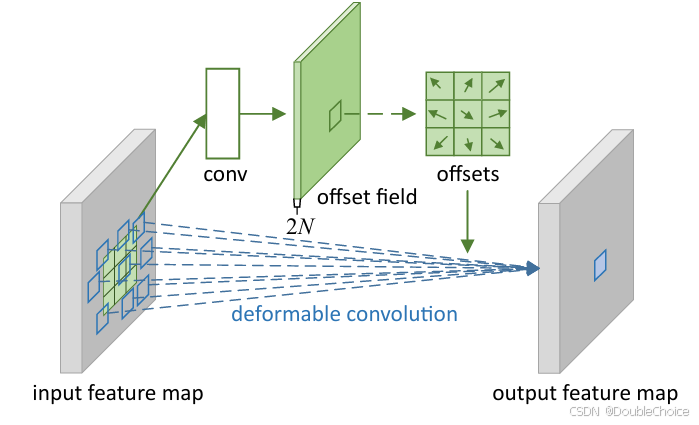
可变形卷积
-
在标准卷积的规则采样网格上引入可学习的2D偏移量,使采样位置能够根据输入特征动态调整。偏移量通过附加的卷积层从前一层特征图中学习,无需额外监督。
-
使用双线性插值实现分数坐标的采样,保证计算效率。
-
-
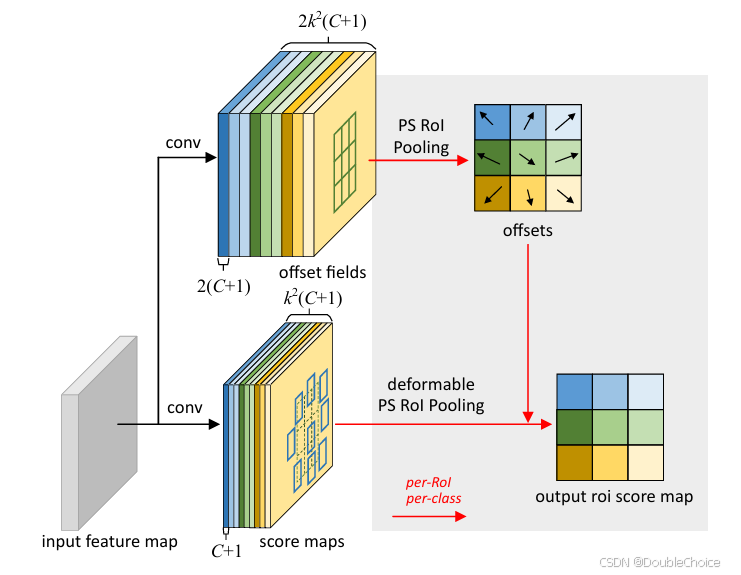
可变形RoI池化
-
在传统RoI池化的固定空间分箱基础上,为每个分箱位置添加可学习的偏移量,使池化区域能够适应物体形状变化。
-
通过全连接层或卷积层生成归一化的偏移量,并映射到实际坐标。
-
-
网络集成与训练
-
可变形模块可直接替换现有CNN中的标准卷积和RoI池化层,通过反向传播端到端训练。
-
初始化偏移学习层时权重设为零,学习率根据任务调整。
-
2.创新点
-
动态空间自适应
-
提出可变形卷积和可变形RoI池化,首次在深层CNN中实现密集空间变换建模,克服了传统CNN固定几何结构的限制。
-
-
无监督偏移学习
-
偏移量完全由目标任务驱动学习,无需额外标注或手工设计,显著提升模型对几何变换的鲁棒性。
-
-
高效性与通用性
-
通过双线性插值和轻量级参数设计,计算开销仅小幅增加。
-
可无缝集成至主流网络。
-
-
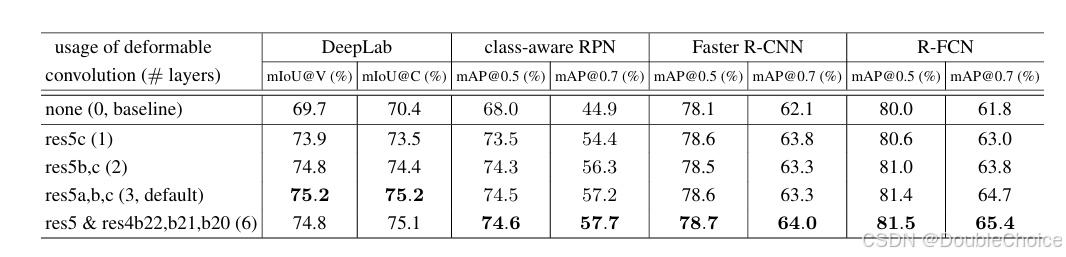
实验验证与性能突破
-
在目标检测和语义分割任务中显著优于基线模型。
-
可变形卷积的有效感受野与物体尺度自适应,验证了其空间建模能力。
-
-
理论扩展性
-
可变形卷积是空洞卷积的泛化形式,支持更灵活的感受野调整。
-
与STN、DPM等方法相比,避免了全局参数化或浅层模型的局限性,更适合复杂视觉任务。
 论文链接:https://arxiv.org/pdf/1703.06211
论文链接:https://arxiv.org/pdf/1703.06211
-
二、Efficient Deformable ConvNets: Rethinking Dynamic and Sparse Operator for Vision Applications(DCNv4)
1.方法
-
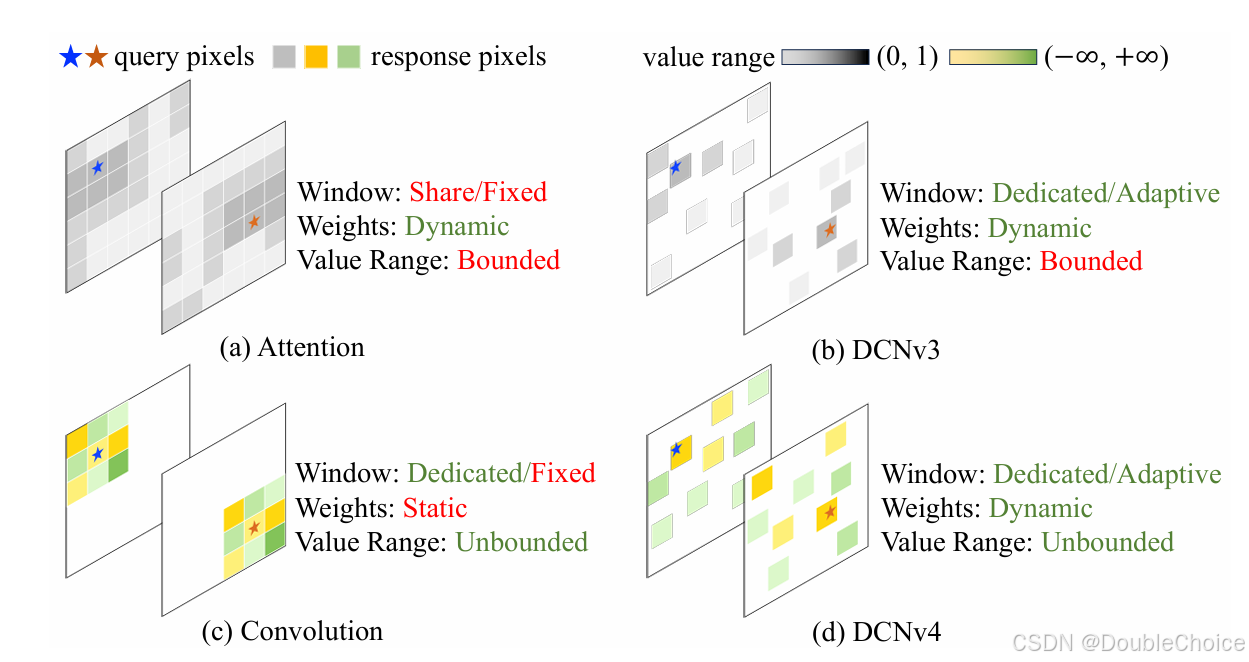
动态性与稀疏性优化
-
移除Softmax归一化:在DCNv3中,空间聚合权重通过softmax归一化到0-1范围,限制了权重的动态表达能力。DCNv4移除softmax,使权重范围无界,增强模型的动态性和表达能力。
-
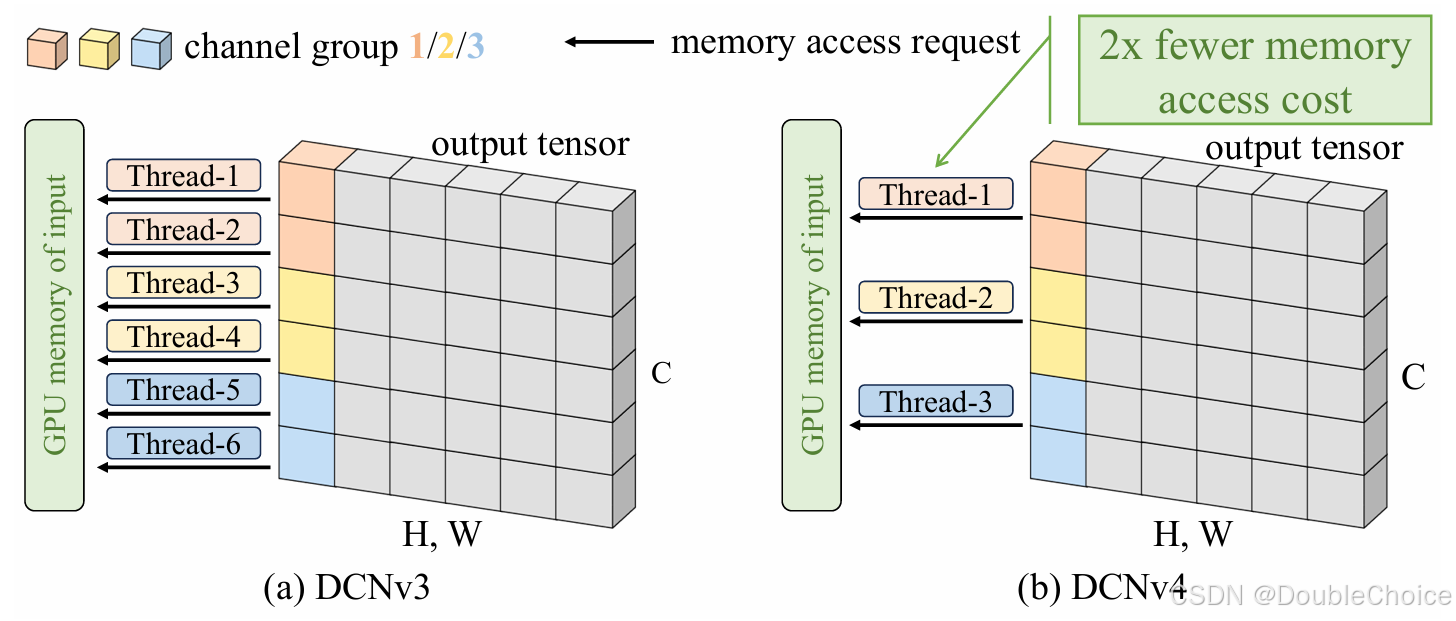
内存访问优化:作者分析DCNv3的GPU内存访问模式,发现冗余的内存读取。DCNv4通过合并线程处理多个通道、向量化加载/存储指令,减少内存访问次数,显著降低延迟。
-
-
算子实现改进
-
计算与存储分离:将偏移和动态权重的线性层合并,减少网络碎片化,降低GPU内核启动开销。
-
简化模块设计:移除DCNv3中的LayerNorm和GELU层,采用轻量化的可分离卷积结构,进一步提升运行效率。
-
半精度支持优化:通过向量化指令和内存布局优化,显著提升FP16/BF16格式下的计算吞吐量。
-
-
通用化适配
-
跨架构兼容性:将DCNv4作为通用算子集成到ConvNeXt和ViT,在不调整超参数的情况下保持性能并提升速度。
-
生成模型应用:在扩散模型(如Stable Diffusion的U-Net)中替换常规卷积,验证DCNv4在生成任务中的有效性。
-
2.创新点
-
动态权重的无界表达
通过移除softmax,使DCNv4的聚合权重范围不受限,克服了DCNv3的表达能力瓶颈,同时加速了模型收敛速度。 -
内存访问效率革命
-
提出“组内通道合并处理”策略,减少冗余内存访问,实现3倍以上的前向速度提升。
-
结合向量化指令和半精度优化,内存带宽利用率提升至原DCNv3的2倍以上。
-
-
多任务与多架构通用性
-
感知任务:在FlashInternImage中替换DCNv3,目标检测、语义分割和3D检测任务中速度提升80%,并且性能超越基线模型。
-
生成任务:首次验证DCN系列在扩散模型中的有效性,FID指标优于常规卷积。
-
-
轻量化设计
通过合并线性层、简化网络结构,耗时降低至DCNv3的30%。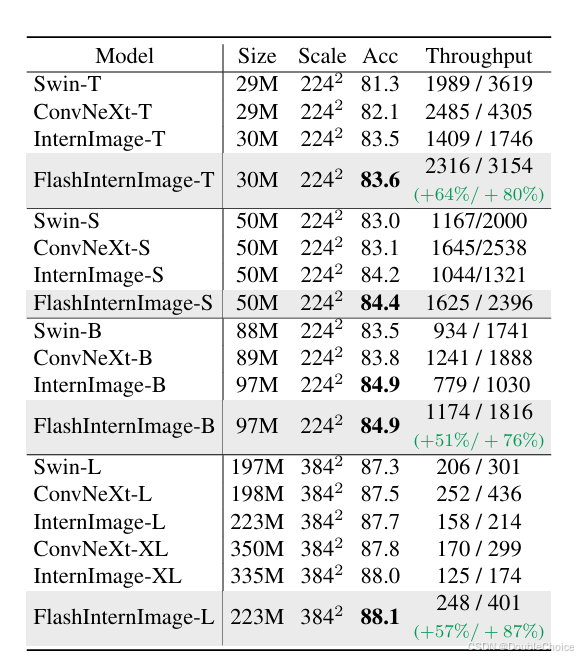
论文链接:https://arxiv.org/pdf/2401.06197
点击【AI十八式】的主页,获取更多优质资源!

















 217
217

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









