







python教程自学全套基础入门学习爬虫数据分析视频。

对于希望自学Python并专注于爬虫和数据分析的初学者来说,网络上有很多优质的资源可以帮助你入门。以下是一个简要的学习路径和一些推荐的学习资源,包括视频教程和代码示例。
学习路径
-
Python基础
- 数据类型(数字、字符串、列表、元组、字典等)
- 控制流(条件语句、循环)
- 函数定义与使用
- 文件操作
- 错误和异常处理
-
Web爬虫
- 理解HTML/CSS/JavaScript结构
- 使用
requests库发送HTTP请求 - 使用
BeautifulSoup解析网页内容 - 利用
Selenium进行动态网页抓取 - 遵循robots.txt规则和道德爬虫实践
-
数据分析
NumPy:数值计算的基础包Pandas:数据处理和分析工具Matplotlib和Seaborn:绘图和可视化- 数据清洗、转换、合并技巧
- 基础统计学知识
推荐学习资源
-
Python基础:
-
Web爬虫:
- 视频教程: B站Python爬虫系列
- 实战项目: Scrapy框架实战
-
数据分析:
- 视频教程: 网易云课堂数据分析入门
- 书籍: “Python数据科学手册” by Jake VanderPlas
示例代码
这里给出一个简单的爬虫示例,使用requests和BeautifulSoup来获取网页标题:
import requests
from bs4 import BeautifulSoup
url = 'http://example.com'
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
print(soup.title.string) # 输出网页标题
对于数据分析,这里有一个简单的例子,使用Pandas读取CSV文件并查看前几行数据:
import pandas as pd
# 加载数据
df = pd.read_csv('data.csv')
# 查看前5行数据
print(df.head())
总结
通过上述资源和步骤,你可以系统地学习Python编程,并深入到爬虫和数据分析领域。记得在学习过程中多做练习和项目,这将极大提高你的实际操作能力。
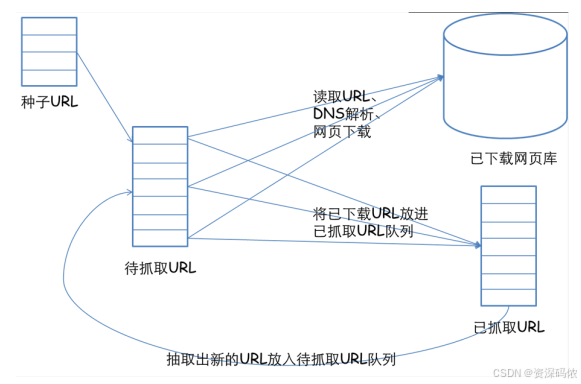
这张图展示了一个典型的网络爬虫的工作流程。以下是各个部分的解释和对应的Python代码示例:
图解说明
- 种子URL:初始的URL列表,用于开始爬取。
- 待抓取URL:当前需要抓取的URL列表。
- 已下载网页库:存储已下载的网页内容。
- 已抓取URL:已经处理过的URL列表。
工作流程
- 从种子URL中读取URL。
- 对每个URL进行DNS解析并下载网页。
- 将已下载的URL放入已抓取URL队列。
- 从已下载的网页中提取新的URL,并将其放入待抓取URL队列。
Python代码示例
下面是一个简单的Python爬虫框架,使用requests和BeautifulSoup库来实现上述流程。
安装所需库
pip install requests beautifulsoup4
代码示例
import requests
from bs4 import BeautifulSoup
import time
class SimpleCrawler:
def __init__(self, seed_urls):
self.seed_urls = seed_urls
self.to_crawl = set(seed_urls)
self.crawled = set()
self.downloaded_pages = {}
def crawl(self):
while self.to_crawl:
url = self.to_crawl.pop()
if url not in self.crawled:
try:
response = requests.get(url)
if response.status_code == 200:
self.crawled.add(url)
self.downloaded_pages[url] = response.text
new_urls = self.extract_links(response.text)
self.to_crawl.update(new_urls)
print(f"Crawled {url}")
else:
print(f"Failed to fetch {url}: {response.status_code}")
except Exception as e:
print(f"Error fetching {url}: {e}")
def extract_links(self, html):
soup = BeautifulSoup(html, 'html.parser')
links = set()
for link in soup.find_all('a'):
href = link.get('href')
if href and href.startswith('http'):
links.add(href)
return links
if __name__ == "__main__":
seed_urls = ['http://example.com']
crawler = SimpleCrawler(seed_urls)
crawler.crawl()
代码解释
-
初始化:
seed_urls是初始的URL列表。to_crawl是待抓取的URL集合。crawled是已抓取的URL集合。downloaded_pages是已下载的网页内容字典。
-
爬取过程:
crawl方法循环处理待抓取的URL。- 使用
requests.get下载网页内容。 - 如果请求成功(状态码为200),则将URL添加到已抓取集合,并保存网页内容。
- 提取新的URL并添加到待抓取集合。
-
链接提取:
extract_links方法使用BeautifulSoup解析HTML并提取所有链接。
运行示例
运行上述代码后,爬虫会从种子URL开始,递归地抓取页面中的链接,并将这些链接加入待抓取队列,直到没有新的URL可抓取为止。
注意事项
- 确保遵守目标网站的
robots.txt文件规则。 - 添加适当的延迟以避免对服务器造成过大负担。
- 处理异常情况,如重定向、超时等。
希望这个示例能帮助你理解并实现一个基本的网络爬虫!

















 505
505

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









