






YOLO-V3
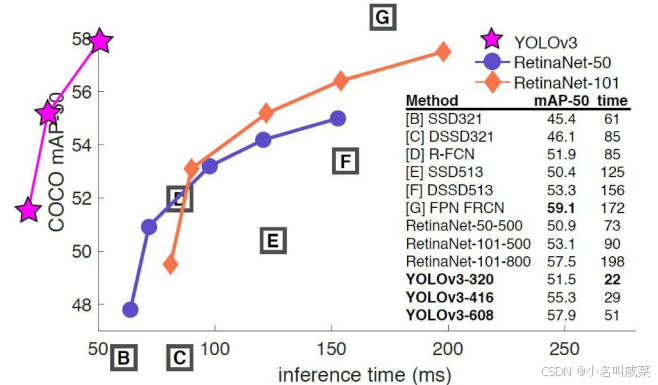
- 终于到V3了,最大的改进就是网络结构,使其更适合小目标检测
- 特征做的更细致,融入多持续特征图信息来预测不同规格物体
- 先验框更丰富了,3种scale,每种3个规格,一共9种
- softmax改进,预测多标签任务
多scale
为了能检测到不同大小的物体,设计了3个scale
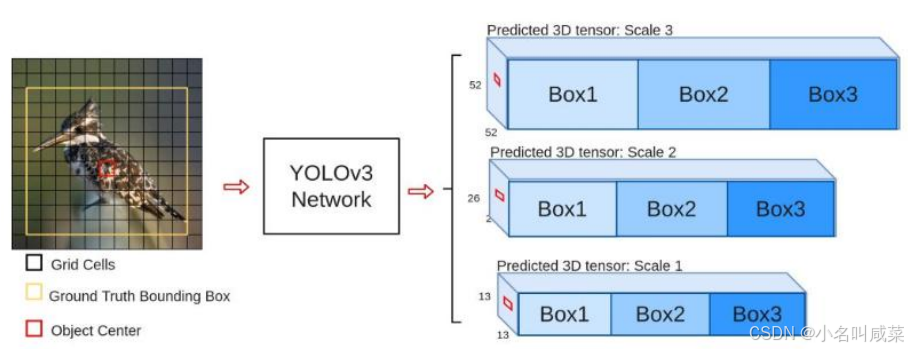
- scale变换经典方法
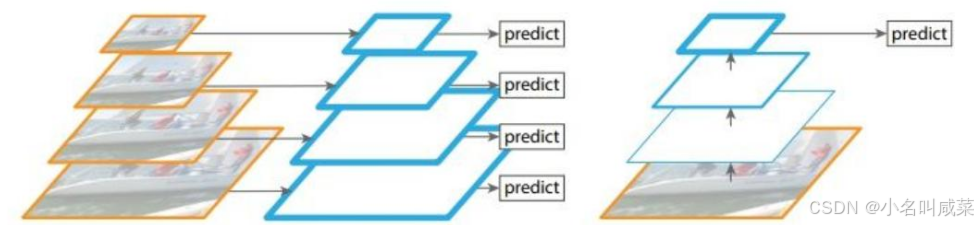
左图:图像金字塔;右图:单一的输入;
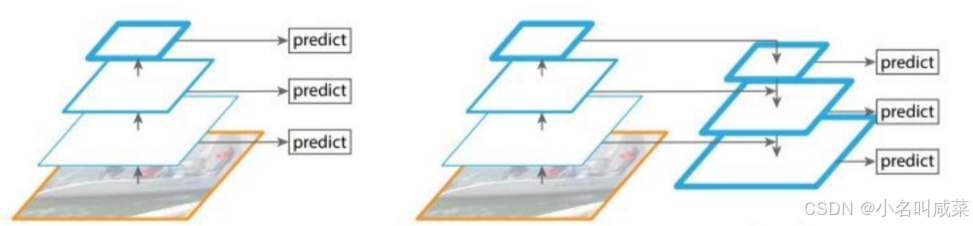
左图:对不同的特征图分别利用;右图:不同的特征图融合后进行预测;
残差连接-为了更好的特征
从今天的角度来看,基本所有网络架构都用上了残差连接的方法
V3中也用了resnet的思想,堆叠更多的层来进行特征提取
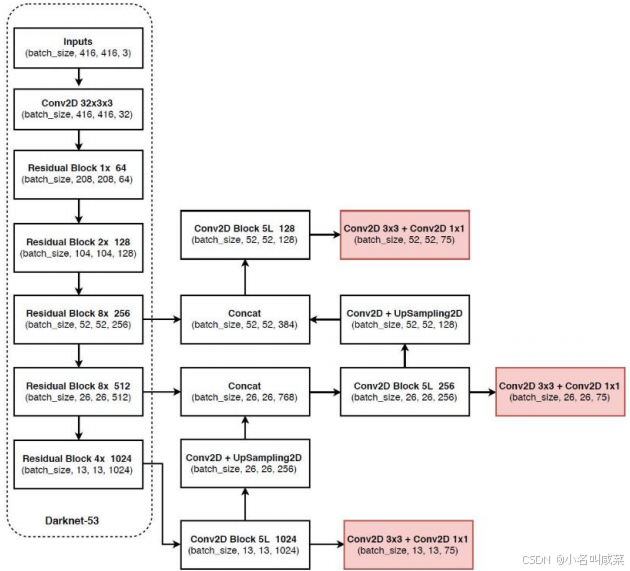
核心网络架构
没有池化和全连接层,全部卷积
下采样通过stride为2实现3种scale,更多先验框
基本上当下经典做法全融入了
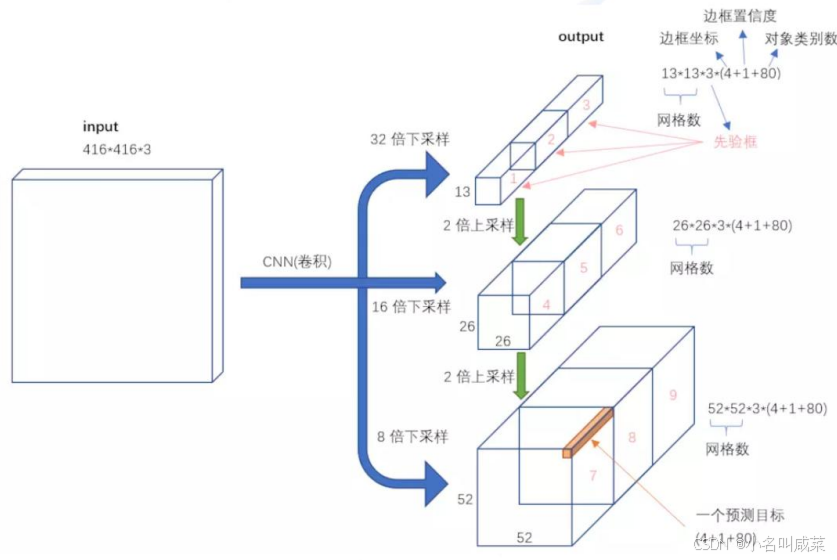
先验框设计
YOLO-V2中选了5个,这回更多了,一共有9种
13*13特征图上:(116x90),(156x198),(373x326)
26*26特征图上:(30x61),(62x45),(59x119)
52*52特征图上:(10x13),(16x30),(33x23)

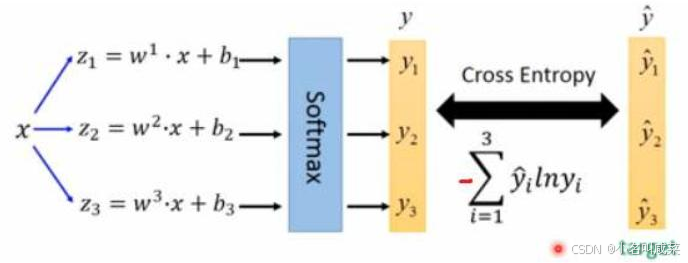
softmax层替代
物体检测任务中可能一个物体有多个标签
logistic激活函数来完成,这样就能预测每一个类别是/不是

















 2802
2802

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









