







前言
看了很多视频之后,我觉得不论学习什么算法都应该明确一个对于算法学习的框架,避免很多时候自己都不知道自己在干嘛,很混乱,这里我自己总结了一下:
1.首先最重要的就是搞清楚为什么我们要学习这个算法
(比如举个例子,对于可以用二分查找来解决的问题,我们一般一开始不会就直接去用二分查找,而是先用暴力的解法先写出来看一看,分析一下时间和空间复杂度如何,再去考虑如何去优化它,比如从O(n)->O(1)就是非常大的提升)
2.然后才对于一些细节的把控
前缀和
引入(一维前缀和)

首先对于这个题目 如果你没有学过前缀和,对于这个问题可能就是会用暴力的方法,思路就非常的原始:比如要求计算区间【3,5】的元素的和,我们就遍历这个数组,定义一个sum,起点是3,终点是5,sum【i】++就行了,但是对于数组长度为n,遍历完询问区间和的次数是m,那么时间复杂度就是O(mn)!所以我们就要想办法去优化他,前缀和就是一个非常好的方法。
对于前缀和我的理解:对于长长的火车,一开始只有一节火车头,后面慢慢的一节一节往上接,每接一次然后求他的长度的过程 就是我们求前缀和数组的过程。
至于前缀和数组有什么作用,其实是非常好理解的,我们用O(n)的时间复杂度来遍历来创建所谓的前缀和数组,此时还是原来的问题如果我们要求某个区间的和,直接就是return右端点减去左端点就可以了,此时只需要O(1)即可。*
代码示例:视频
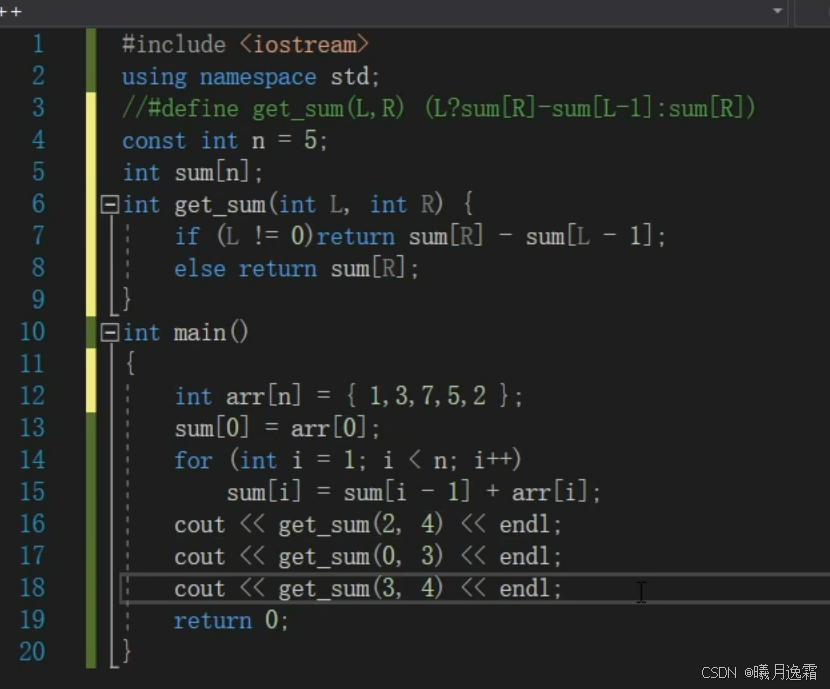
为什么L需要-1?
举个例子就能简单明白了
比如要你求的是【3,4】的区间和,我们需要用sum【4】也就是从下标0一直加到4的和减去sum【2】,如果减去的是sum【3】,那么求出的就直接是数组元素a【4】了,希望大家能够理解
下面这种方法是labuladong的题解,对于上述的问题进行了优化,可以称之为数组的偏移,使得前缀和数组presum从0开始递增,从而与原数组sum一一对应,但是思路依旧是不变的
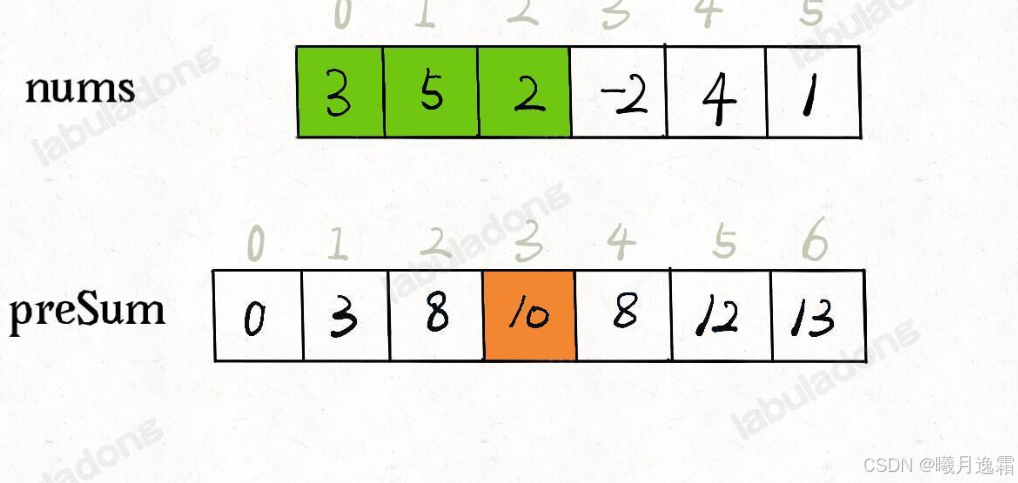
#include <vector>
class NumArray {
// 前缀和数组
std::vector<int> preSum;
// 输入一个数组,构造前缀和
public:
NumArray(std::vector<int>& nums) {
// preSum[0] = 0,便于计算累加和
preSum.resize(nums.size() + 1);
// 计算 nums 的累加和
for (int i = 1; i < preSum.size(); i++) {
preSum[i] = preSum[i - 1] + nums[i - 1];
}
}
// 查询闭区间 [left, right] 的累加和
int sumRange(int left, int right) {
return preSum[right + 1] - preSum[left];
}
};
二维前缀和
从名字就能看出来二维其实就是从一行或者一列的区间和问题
升维成了一个大矩阵的中 子矩阵和的问题 但是其实思想是一样的

对
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 356
356

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









