






1 什么是canal
我们都知道一个系统最重要的是数据,数据是保存在数据库里。但是很多时候不单止要保存在数据库中,还要同步保存到Elastic Search、HBase、Redis等等。
这时我注意到阿里开源的框架Canal,他可以很方便地同步数据库的增量数据到其他的存储应用。所以在这里总结一下,分享给各位读者参考~
我们先看官网的介绍
canal,译意为水道/管道/沟渠,主要用途是基于 MySQL 数据库增量日志解析,提供增量数据订阅和消费。
这句介绍有几个关键字:增量日志,增量数据订阅和消费。
这里我们可以简单地把canal理解为一个用来同步增量数据的一个工具。
接下来我们看一张官网提供的示意图:
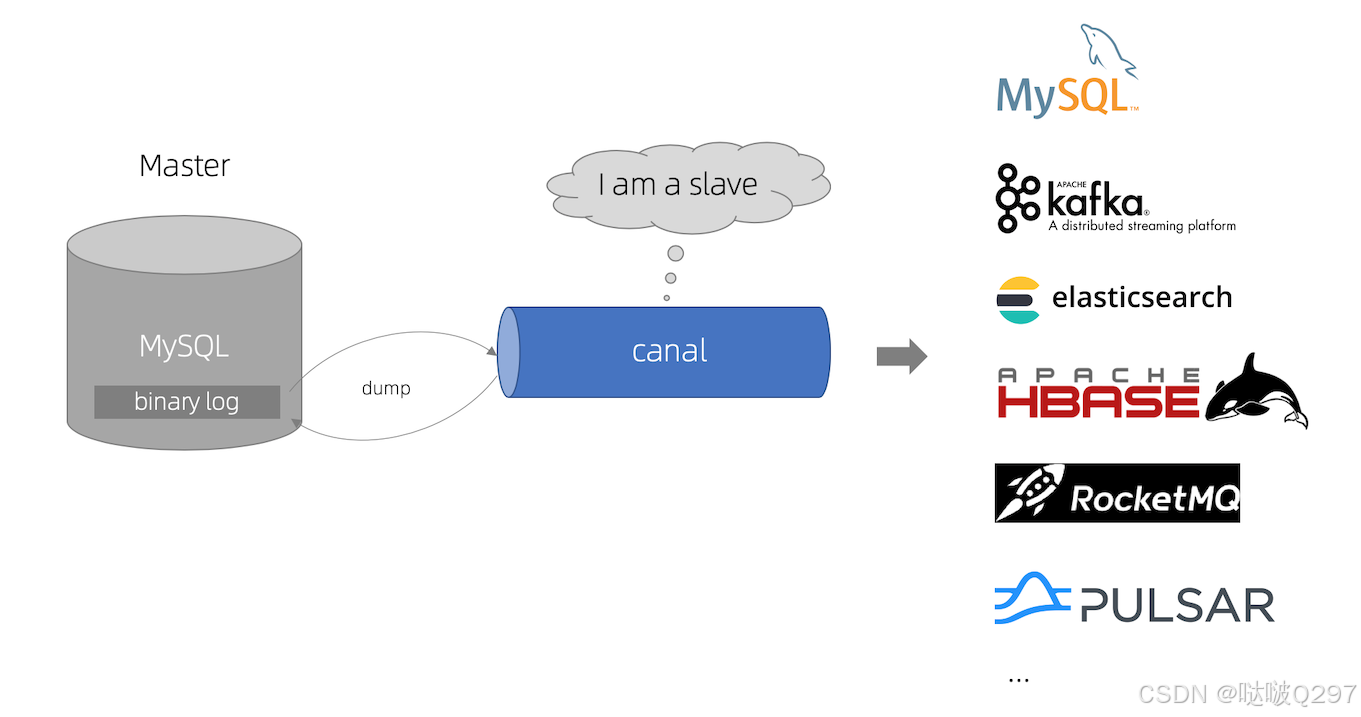
canal的工作原理就是把自己伪装成MySQL slave,模拟MySQL slave的交互协议向MySQL Mater发送 dump协议,MySQL mater收到canal发送过来的dump请求,开始推送binary log给canal,然后canal解析binary log,再发送到存储目的地,比如MySQL,Kafka,Elastic Search等等。
2 canal能做什么
以下参考canal官网。
与其问canal能做什么,不如说数据同步有什么作用。
但是canal的数据同步不是全量的,而是增量。基于binary log增量订阅和消费,canal可以做:
- 数据库镜像
- 数据库实时备份
- 索引构建和实时维护
- 业务cache(缓存)刷新
- 带业务逻辑的增量数据处理
3 如何搭建canal
3.1 首先有一个MySQL服务器
当前的 canal 支持源端 MySQL 版本包括 5.1.x , 5.5.x , 5.6.x , 5.7.x , 8.0.x
我的Linux服务器安装的MySQL服务器是8.0.26版本。
MySQL的安装这里就不演示了,比较简单,网上也有很多教程。
然后在MySQL中需要创建一个用户,并授权:
-- 使用命令登录:mysql -u root -p
-- 创建用户 用户名:canal 密码:Canal@123456
create user 'canal'@'%' identified by 'Canal@123456';
-- 授权 *.*表示所有库
grant SELECT, REPLICATION SLAVE, REPLICATION CLIENT on *.* to 'canal'@'%' identified by 'Canal@123456';
下一步在MySQL配置文件my.cnf设置如下信息:
[mysqld]
# 打开binlog
log-bin=mysql-bin
# 选择ROW(行)模式
binlog-format=ROW
# 配置MySQL replaction需要定义,不要和canal的slaveId重复
server_id=1
3.2 启动 Canal Server
sh bin/startup.sh
4. 配置 Canal Client
使用 Java 或其他编程语言编写 Canal Client,连接到 Canal Server 并订阅数据变化事件。 示例 Java 代码:
CanalConnector connector = CanalConnectors.newSingleConnector(
new InetSocketAddress("127.0.0.1", 11111), "example", "", "");
connector.connect();
connector.subscribe(".*\\..*");
connector.rollback();
while (true) {
Message message = connector.getWithoutAck(100);
long batchId = message.getId();
int size = message.getEntries().size();
if (batchId != -1 && size > 0) {
printEntries(message.getEntries());
}
connector.ack(batchId);
}
4.优势
开源免费:Canal 是开源项目,完全免费使用。
社区支持:活跃的社区提供支持和更新,不断改进和扩展功能。
易于集成:提供简单易用的 API,可以轻松集成到现有系统中。
Canal 是一个功能强大且灵活的数据同步工具,适用于各种实时数据同步和监控的需求。

















 175
175

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









