






欢迎关注微信公众号:互联网全栈架构
在大型应用系统中,往往存在数据异构的现象,比如业务数据保存在MySQL关系数据库中,比如缓存数据放在Redis中,比如支持多维度查询的数据存储在ElasticSearch里面,等等。。。如此种种,不一而足。在这些异构数据之间,我们往往需要把MySQL中的业务数据同步到其他异构数据服务器中,而阿里巴巴推出的一款开源的数据同步工具Canal就可以满足这样的需求。
一、Canal简介
Canal是一款基于MySQL数据库binlog的增量订阅和消费组件,可以使用它来订单数据库的binlog日志,然后进行一些数据消费,基于这种日志增量订阅和消费的业务包括数据库镜像、数据异构、数据索引、缓存更新等。
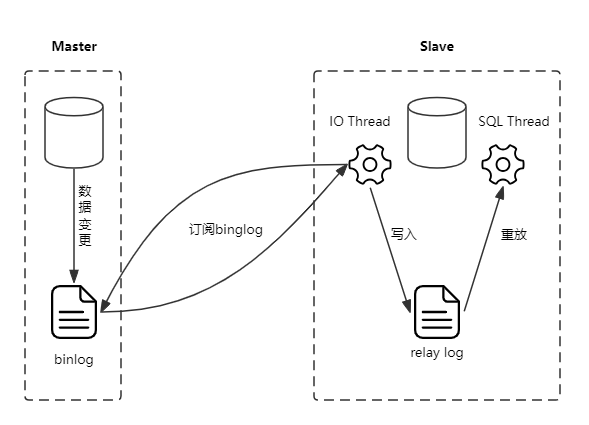
首先看看MySQL主从复制的原理:
-
Master将数据变更写入binlog中。
Slave会订阅Master数据库的binlog,通过I/O线程从binlog拉取日志进行主从同步。
Slave的I/O线程读取到日志后会先写入relay log重放日志中。
Slave的SQL 线程读取relay log进行日志重放,这样就实现了主从数据库间的同步。
而Canal的工作原理就是把自己伪装成MySQL的Slave,模拟MySQL Slave的交互协议向MySQL Master发送dump协议,MySQL Master收到Canal发送过来的dump请求,开始推送binlog给Canal,然后Canal解析binlog,按业务需求进行后续操作,比如同步到其他数据库中等等。
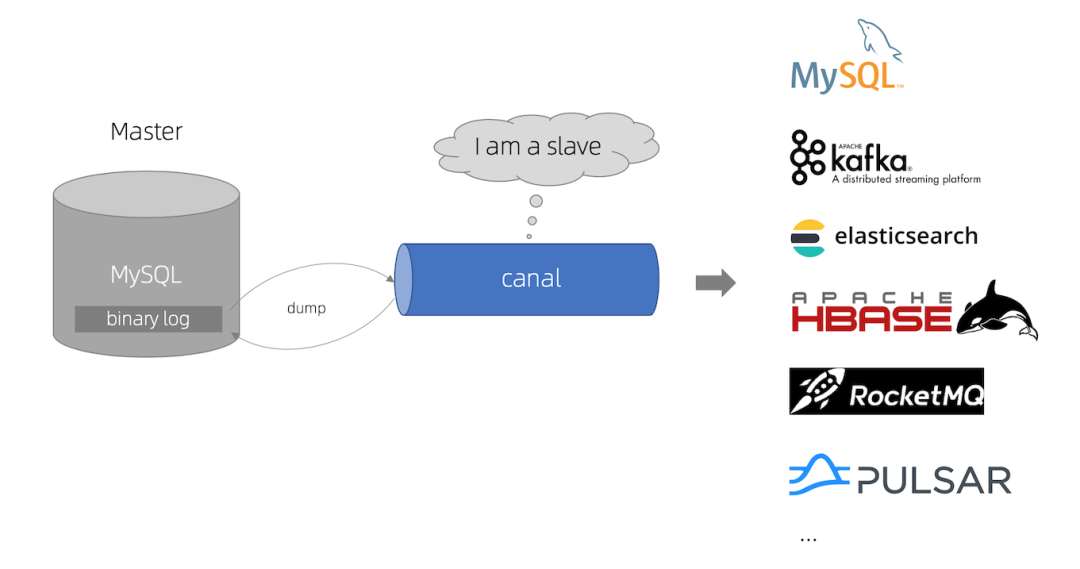
二、Canal示例
接下来我们看看Canal的具体用法,包括数据库的配置、Java代码编写等。
在MySQL的配置文件my.cnf中添加如下配置:
log-bin=mysql-bin # 开启二进制日志
binglog-format=ROW #使用row模式
server-id=1 #配置主数据库id,不能与从数据库重复MySQL的主从复制分为三种模式:
Statement,基于语句的复制,在简单来说,就是在主库上执行的SQL,在从库上原样地执行一遍;
Row,基于行的复制,记录每次DML操作导致的数据行变化,并把行的变更同步到从库中;
Mixed,混合模式,根据执行的每一条具体SQL来选择Statement模式或者Rows模式。
使用Canal时建议使用Row模式。
然后创建一个新的MySQL用户,并为其授予查询和复制权限:
CREATE USER 'canal' IDENTIFIED BY 'canal';
GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'canal'@'%';
FLUSH PRIVILEGES;从canal官网下载canal.deployer-1.1.7.tar.gz,解压后在目录conf/example下面有一个文件instance.properties,然后修改里面的数据库相关配置信息,主要是以下几项(IP地址、端口号修改成实际的配置):
# 数据库地址
canal.instance.master.address=MySQL服务器的IP地址:端口号
# 用户名/密码,数据库字符集
canal.instance.dbUsername=canal
canal.instance.dbPassword=canal
canal.instance.connectionCharset = UTF-8对于服务器的配置canal.properties,可以先不用修改。
接下来我们写一段示例代码,如果连接的MySQL中数据表数据发生了变化,那么在Java程序监听到这种变化并做相应的业务处理。首先引入Canal客户端的依赖:
<!-- canal 客户端的集成 -->
<dependency>
<groupId>com.alibaba.otter</groupId>
<artifactId>canal.client</artifactId>
<version>1.1.6</version>
</dependency>
<!-- 客户端通信 消息传递 -->
<dependency>
<groupId>com.alibaba.otter</groupId>
<artifactId>canal.protocol</artifactId>
<version>1.1.6</version>
</dependency>Java代码如下:
package com.sample.canal;
import com.alibaba.otter.canal.client.CanalConnector;
import com.alibaba.otter.canal.client.CanalConnectors;
import com.alibaba.otter.canal.protocol.CanalEntry;
import com.alibaba.otter.canal.protocol.Message;
import java.net.InetSocketAddress;
import java.util.List;
public class CanalExample {
public static void main(String[] args) throws Exception {
CanalConnector canalConnector = CanalConnectors.newSingleConnector(
new InetSocketAddress("此处为Canal服务地址", 11111), "example", "","");
canalConnector.connect();
while (true){
canalConnector.subscribe();
Message message = canalConnector.getWithoutAck(100);
for(CanalEntry.Entry entry: message.getEntries()){
// 如果是行数据
if(entry.getEntryType() == CanalEntry.EntryType.ROWDATA){
// 解析行变更
CanalEntry.RowChange row = CanalEntry.RowChange.parseFrom(entry.getStoreValue());
CanalEntry.EventType eventType = row.getEventType();
for(CanalEntry.RowData rowData: row.getRowDatasList()){
// 如果是新增或者更新数据
if(eventType == CanalEntry.EventType.INSERT
|| eventType == CanalEntry.EventType.UPDATE) {
List<CanalEntry.Column> columns = rowData.getAfterColumnsList();
// 打印出数据变动情况。此处按业务要求处理
printChanges(columns);
}
}
}
}
canalConnector.ack(message.getId());
}
}
private static void printChanges(List<CanalEntry.Column> columns){
columns.forEach((column -> {
String name = column.getName();
String value = column.getValue();
System.out.println("列名:"+name+",更新后的值:"+value);
}));
}
}如果我们在数据表中插入一条记录(创建一个很简单的表,只有id和name字段),那么上面的Java程序就会打印出如下的信息:

三、总结
从上面可以看出,Canal的部署和使用也相对比较简单,它把自己伪装成MySQL的Slave,从而可以监听主数据库的变化,这样就方便进行数据同步等操作,当然,它是做一个增量数据的同步,另外,Canal对于业务逻辑没有侵入,在很多需要异构数据同步的场所,它能够大显神威。
创作不易,烦请点赞、分享,感谢!
鸣谢:
https://github.com/alibaba/canal
https://zhuanlan.zhihu.com/p/655011270
推荐阅读:

















 5455
5455

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









