






一、人类的英语阅读理解:意群如何加速大脑处理?
1.1 什么是意群(Chunking):自然语义单元
意群,顾名思义,就是将语言中具有内在联系的部分组合在一起,形成一个相对独立且完整的语义单元。举个简单的例子,在句子“I love reading books in the cozy library on rainy days.”中,“reading books”可以看作是一个意群,它表达了“阅读书籍”这一完整的行为;“in the cozy library”是另一个意群,描绘了阅读发生的场所;“on rainy days”则构成了第三个意群,说明了时间背景。通过这种方式,原本冗长的句子被划分成几个简洁明了的模块,大大降低了理解难度。
1.2 人类通过意群实现语言切割
在日常英语阅读中,逐字翻译往往会让人陷入混乱,效率低下。而意群就像一把神奇的剪刀,帮助我们把语言切割成有意义的模块。当我们看到一个长句时,大脑会自动根据语法结构、语义关联以及生活常识等因素,快速地将句子分解成一个个意群。例如,面对句子“The boy who was playing soccer in the park suddenly fell down.”,我们不会逐个单词去理解,而是会将其划分为“The boy”(主语意群)、“who was playing soccer in the park”(定语从句意群,修饰主语)、“suddenly fell down”(谓语及宾语意群)。这样一来,我们就能迅速把握句子的核心意思,即“那个在公园踢足球的男孩突然摔倒了”,而无需纠结于每个单词的单独含义。
二、大模型的“意群”实现:Token 与注意力机制
2.1 Token:机器的“语言积木”
对于大模型来说,Token 是其处理文本的基础单元。简单来说,Token 就是文本被切分后的最小单位,它可以是一个单词,也可以是一个子词。以 GPT-3 为例,它将“hiking”视为一个 Token,因为这是一个完整的单词;而对于“unhappy”,它可能会将其切分为“un”+“happy”两个 Token。这种切分方式类似于我们把积木拆分成一个个小块,方便后续的组合与处理。大模型通过对大量文本的学习,掌握了如何将文本分解成这些 Token,并以此为基础进行后续的分析和生成。
2.2 注意力机制:机器的“伪意群”生成
大模型通过注意力机制来动态关联 Token,从而生成类似意群的结构。具体来说,模型会计算每个 Token 之间的权重,将那些高频共现的 Token 组视为关联单元。就好比在一篇关于烹饪的文章中,“salt”(盐)和“pepper”(胡椒)这两个 Token 经常一起出现,模型就会将它们视为一个关联单元,类似于人类眼中的一个“伪意群”。通过这种方式,大模型能够在一定程度上模拟人类对意群的理解,但它的原理与人类是完全不同的。人类是基于语法、语境和常识来划分意群,而大模型则是基于统计概率和 Token 共现的规律。
三、人类与大模型的意群处理:关键区别与启示
我们先来看一个例子:“你愿意我做女朋友吗”,即使没有看得很匆忙,我们也会很快意识到这句话的语序有问题,正确的应该是“你愿意做我的女朋友吗”。这是因为我们在理解时会结合读得懂的单词和意群的方法,同时还会受到常见语境出现概率以及第一个语序逻辑不顺的影响。这说明人类在做英语阅读理解时,利用意群的方法是可行的。
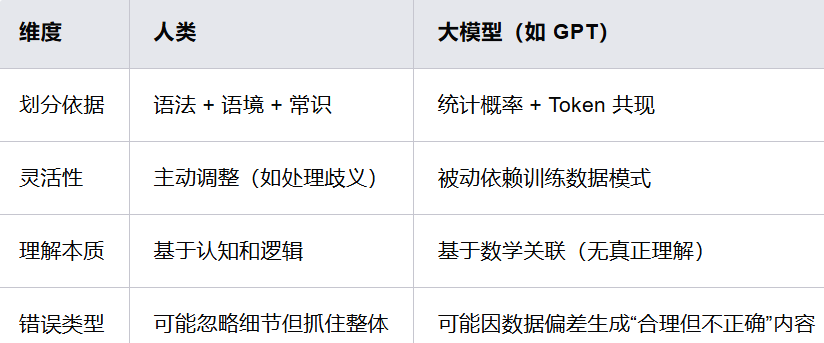
尽管人类和大模型都会处理意群,但它们之间存在着显著的区别。从上表可以看出,人类在划分意群时,依据的是语法、语境和常识,具有很强的主动性和灵活性,能够根据具体情况进行调整。例如,当我们遇到一个有歧义的句子时,可以凭借生活经验和逻辑推理来判断正确的理解方式。而大模型则是基于统计概率和 Token 共现来划分意群,它被动地依赖于训练数据中的模式,缺乏真正的认知和逻辑理解。因此,大模型可能会因为数据偏差而生成一些“合理但不正确”的内容。
启示:
• 人类的优势:
主动推理、灵活适应新语境。我们能够根据不同的语境和背景,灵活地调整对意群的理解和划分,这是大模型所不具备的。
• 机器的优势:
快速处理海量固定模式数据。大模型在处理大量文本数据时表现出色,能够快速识别出常见的模式和规律,为我们提供参考和帮助。
四、英语学习者的意群训练法:结合人类与大模型的思维
4.1 技巧 1:分块阅读训练
练习方法:用斜杠手动分割句子意群。例如,对于句子“The rapid development of technology/has significantly changed/how people communicate.”,我们可以先尝试自己划分意群,然后再与标准答案进行对比。通过这种方式,我们可以逐渐培养对意群的敏感度,提高阅读理解能力。
工具辅助:用 Grammarly 或 ChatGPT 检查划分是否合理。Grammarly 是一款强大的语法检查工具,它可以帮助我们发现句子中的语法错误,同时也能对意群划分提供一定的参考。而 ChatGPT 则可以根据我们的输入,给出更自然、更合理的意群划分建议。通过借助这些工具,我们可以更准确地掌握意群划分的方法。
4.2 技巧 2:聚焦“语义单元”而非单词
在英语学习中,我们常常会逐个单词地去翻译和理解,这不仅效率低下,还容易导致理解偏差。相反,我们应该将一些固定的短语和表达视为一个整体的“语义单元”。例如,“take place”(发生)就是一个常见的语义单元,我们不能将其拆分成“take”和“place”分别去翻译,而应该将其作为一个整体来理解和记忆。大模型在生成文本时,也会将类似的短语作为连贯的单元来进行处理,这为我们提供了一个很好的启示。通过聚焦语义单元,我们可以更好地把握句子的整体意思,提高阅读速度和理解能力。
4.3 技巧 3:利用大模型输出分析意群
实践:输入复杂句子至 GPT,要求其用简单意群重写,对比学习。我们可以将一些复杂的句子输入到 GPT 中,然后要求它用更简单的意群来重新表达。通过对比原始句子和 GPT 的输出,我们可以学习到如何将复杂的句子分解成简单易懂的意群,从而提高自己的阅读和写作能力。不过,我们也要注意,大模型可能会过度依赖高频搭配,有时会忽略一些特殊情况。因此,在学习过程中,我们需要结合实际情况,灵活运用所学到的知识。

五、总结:意群是高效阅读的桥梁
• 对人类:刻意练习意群划分,摆脱逐字翻译。通过不断地练习和积累,我们可以逐渐养成用意群来阅读和理解英语的习惯,从而提高阅读效率,让英语阅读变得更加轻松自然。
• 对大模型:理解其 Token 化与注意力机制的本质,善用工具而非盲从结果。大模型为我们提供了强大的语言处理能力,但我们不能完全依赖它。只有理解了其背后的原理和机制,我们才能更好地利用它来辅助我们的学习和工作,同时避免因过度依赖而产生的错误。
• 终极目标:通过“意群思维”实现流畅阅读,让语言像母语一样自然输入大脑。无论是人类还是大模型,意群都是实现高效阅读的关键。我们希望通过不断地学习和实践,能够真正掌握意群思维,让英语阅读变得像阅读母语一样流畅自然,从而更好地享受阅读带来的乐趣和收获。


















 1038
1038

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









