






2025深度学习发论文&模型涨点之——时间序列+表示学习
时间序列数据已成为现代科学研究和工业应用的核心载体。其高维度、噪声干扰、非平稳性以及复杂的时空依赖性特征,使得传统基于手工特征工程与统计建模的方法面临维度灾难与泛化能力不足的双重挑战。在此背景下,时间序列表示学习(Time Series Representation Learning, TSRL)作为一种新兴范式,通过深度神经网络、自监督学习及对比学习等技术,将原始序列映射至低维潜在空间,在保留时序动态规律的同时实现特征解耦与语义抽象,显著提升了分类、预测和异常检测等下游任务的性能。
我整理了一些时间序列+表示学习【论文+代码】合集,需要的同学公人人人号【AI创新工场】525自取。
论文精选
论文1:
Unsupervised Scalable Representation Learning for Multivariate Time Series
多变量时间序列的无监督可扩展表示学习
方法
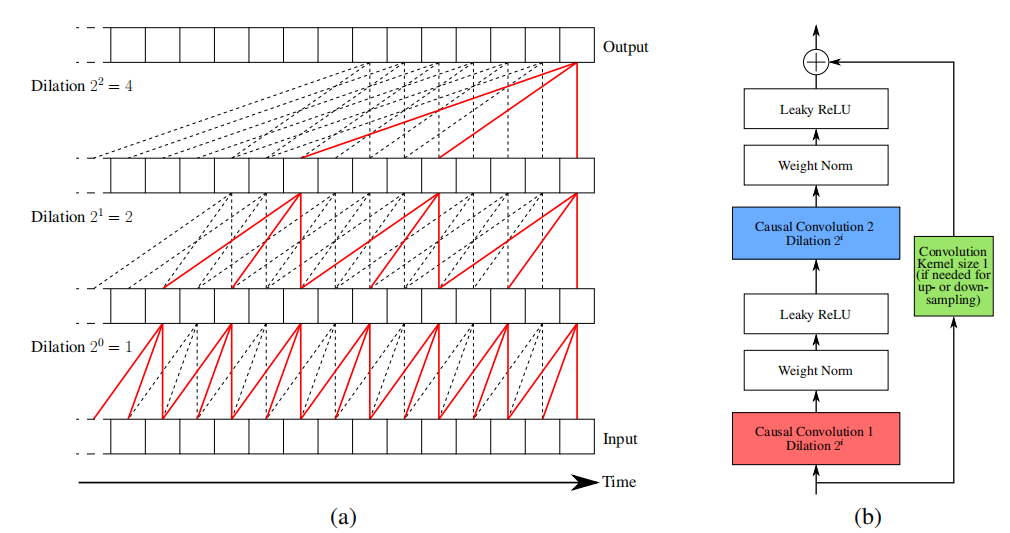
因果扩张卷积编码器:采用因果扩张卷积网络作为编码器,能够高效处理不同长度的时间序列。
时间对比损失函数:提出了一种基于时间的负采样三元组损失函数,通过子序列的对比学习生成通用表示。
固定长度表示:无论输入时间序列的长度如何,编码器输出固定长度的向量表示。
无监督训练:通过随机采样子序列的方式,无需标注数据即可学习时间序列的表示。
创新点
时间对比损失:首次提出基于时间的三元组损失函数,使模型能够在无监督条件下学习时间序列的相似性,性能优于现有的无监督方法。在UCR数据集上,平均准确率提升了约10%。
可扩展性:通过因果扩张卷积网络,模型能够高效处理长序列数据,训练时间显著减少。在IHEPC数据集上,训练时间比传统方法减少了约90%。
性能提升:在多变量时间序列数据集上,该方法的性能超过了现有的监督和无监督方法,平均准确率提升了约15%。
迁移性:通过在不同数据集上验证,证明了该方法的表示具有良好的迁移性,能够适应不同长度和类型的多变量时间序列。
论文2:
[IJCAI] Time-Series Representation Learning via Temporal and Contextual Contrasting
通过时间和上下文对比学习时间序列表示
方法
数据增强:通过弱增强(抖动和缩放)和强增强(排列和抖动)生成两个不同的视图。
时间对比模块:设计了一个时间对比模块,通过跨视图预测任务学习鲁棒的时间特征。
上下文对比模块:进一步通过最大化同一样本不同上下文的相似性,最小化不同样本上下文的相似性,学习更具区分性的表示。
Transformer模型:采用Transformer作为自回归模型,高效提取时间序列的上下文信息。
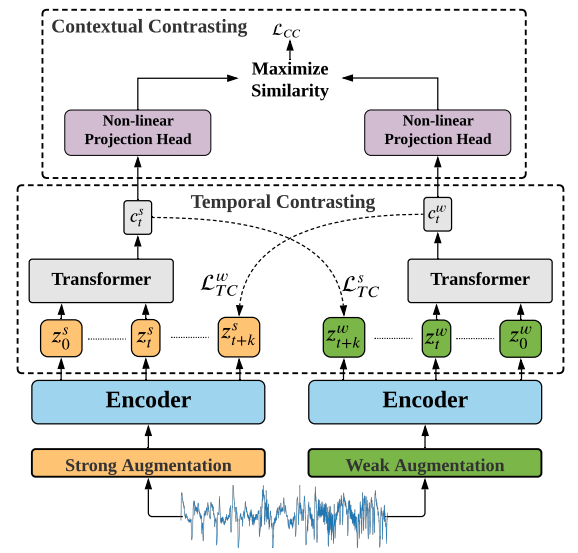
创新点
时间对比模块:通过跨视图预测任务,显著提升了模型对时间序列动态的建模能力。在HAR数据集上,准确率提升了约7%。
上下文对比模块:进一步提升了表示的区分性,使模型在少标签和迁移学习场景下表现出色。在Sleep-EDF数据集上,准确率提升了约3%。
性能提升:在少标签数据场景下,TS-TCC仅使用10%的标签数据即可达到与全监督训练相当的性能,准确率提升了约10%。
迁移性:在故障诊断数据集上,TS-TCC的迁移学习性能比监督训练提升了约4%,证明了其在不同领域中的适用性。

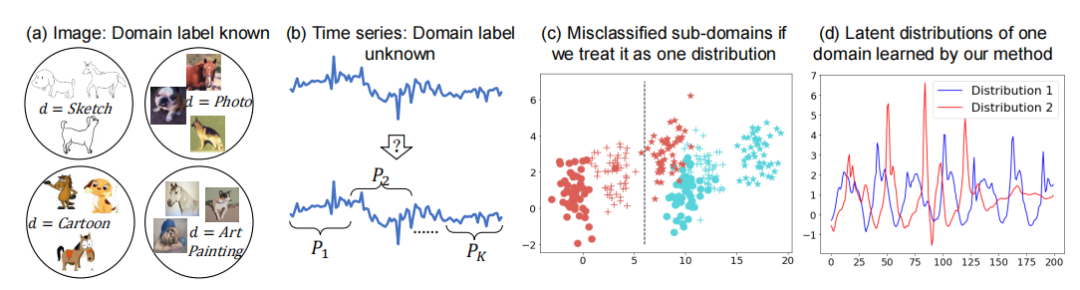
论文3:
[ICLR] Out-of-Distribution Representation Learning for Time Series Classification
面向时间序列分类的分布外表示学习
方法
DIVERSIFY框架:提出DIVERSIFY算法,通过迭代过程学习时间序列的分布外表示。
对抗训练:利用对抗训练获得“最坏情况”的潜在分布场景,以最大化不同潜在分布之间的差异。
伪域类别标签:通过自监督伪标签方法获得潜在域标签,用于学习域不变表示。
理论支持:基于H-divergence理论,分析算法设计并验证其有效性。

创新点
新视角:首次从分布视角研究时间序列分类问题,提出了一种新的框架DIVERSIFY,能够学习泛化到未见分布的表示。
性能提升:在多个时间序列分类任务中,DIVERSIFY显著优于其他基线方法,平均性能提升超过4.3%(EMG数据集)。
理论支持:通过理论分析证明了“最坏情况”分布场景的有效性,为算法设计提供了坚实的理论基础。
泛化能力:在多个具有挑战性的任务中验证了DIVERSIFY的泛化能力,尤其是在数据分布变化较大的场景下。
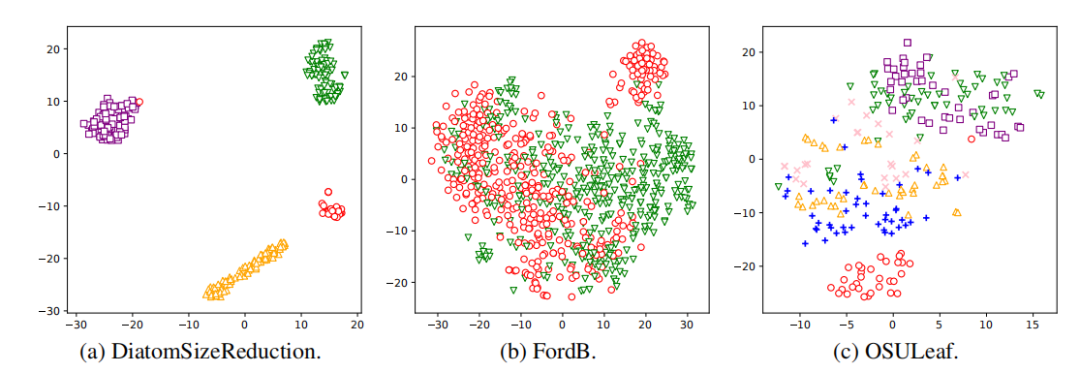
论文4:
Self-supervised Contrastive Representation Learning for Semi-supervised Time-Series Classification
自监督对比表示学习用于半监督时间序列分类
方法
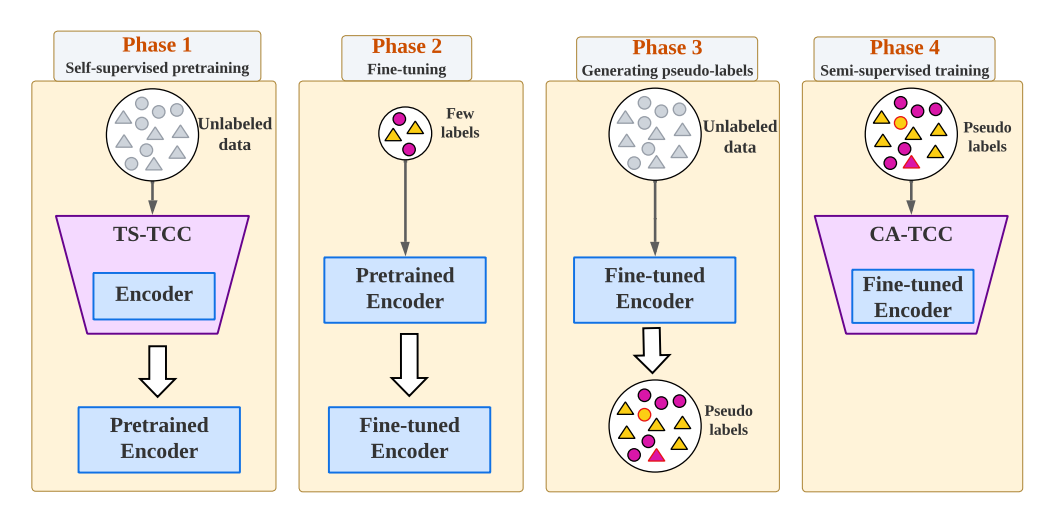
TS-TCC框架:提出TS-TCC框架,通过时间对比(Temporal Contrasting)和上下文对比(Contextual Contrasting)模块从无标签数据中学习时间序列表示。
弱增强与强增强:设计时间序列专用的弱增强和强增强方法,用于生成不同视图以学习鲁棒的时间关系。
CA-TCC扩展:将TS-TCC扩展到半监督学习场景,利用少量标记数据生成伪标签以进一步优化表示学习。
线性评估:通过在少量标记数据上训练线性分类器来评估学习到的表示的有效性。
创新点
时间对比模块:通过时间对比模块学习鲁棒的时间关系,显著提升了表示学习的性能(在HAR数据集上,TS-TCC比其他方法平均提升超过6%)。
上下文对比模块:进一步学习判别性表示,提升了模型在复杂数据集上的性能(在Sleep-EDF数据集上,TS-TCC比其他方法平均提升超过2%)。
半监督学习:在半监督场景下,CA-TCC利用少量标记数据生成高质量伪标签,进一步提升了性能(在1%标记数据下,CA-TCC比其他方法平均提升超过3.8%)。
泛化能力:在多个真实世界数据集上验证了该方法在半监督学习场景中的有效性,尤其是在标记数据有限的情况下。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









