






使用DeepLabV3+进行GID遥感图像语义分割:从数据准备到模型训练 如何进行学习率调度, 损失函数优化
本人不才。
仅供参考,同学。
以DeepLabV3+为例,提供一个基本的代码框架来帮助开始训练GID数据集。此示例使用PyTorch框架,并假设同学尼亚,已经安装了必要的库,如torch, torchvision, 和用于数据增强和处理的albumentations等。
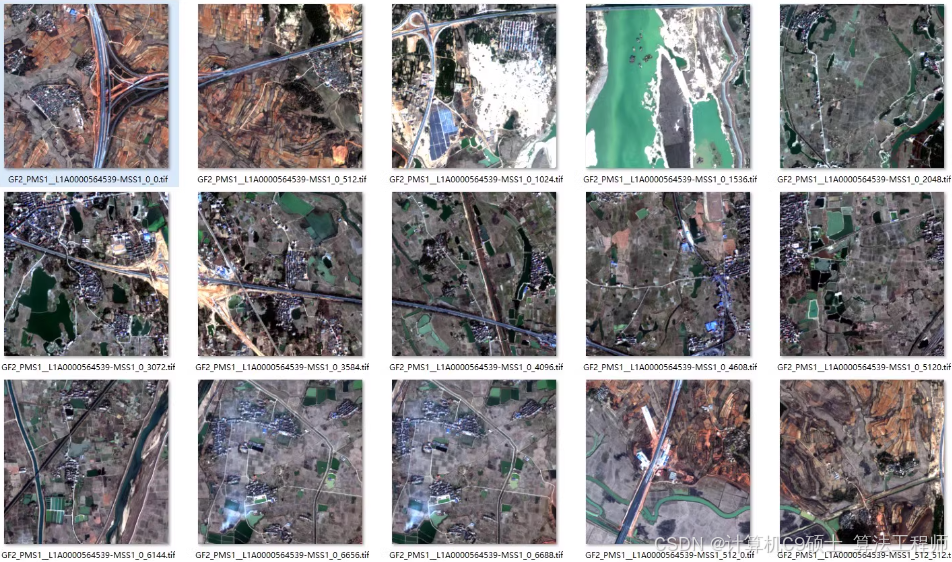
DeepLabV3+ 模型训练GID数据集
安装依赖
确保安装了所有需要的库:
pip install torch torchvision albumentations opencv-python

数据加载与预处理
创建一个自定义的数据加载器来加载GID数据集并进行必要的预处理:
import torch
from torch.utils.data import Dataset, DataLoader
import cv2
import os
import numpy as np
import albumentations as A
from albumentations.pytorch.transforms import ToTensorV2
class GIDSegmentationDataset(Dataset):
def __init__(self, image_dir, mask_dir, transform=None):
self.image_dir = image_dir
self.mask_dir = mask_dir
self.transform = transform
self.images = os.listdir(image_dir)
def __len__(self):
return len(self.images)
def __getitem__(self, idx):
img_path = os.path.join(self.image_dir, self.images[idx])
mask_path = os.path.join(self.mask_dir, self.images[idx].replace(".jpg", "_mask.png"))
image = cv2.imread(img_path)
mask = cv2.imread(mask_path, 0) # Load grayscale mask
if self.transform is not None:
augmented = self.transform(image=image, mask=mask)
image = augmented['image']
mask = augmented['mask']
return image, mask.long()
transform = A.Compose(
[
A.Resize(512, 512),
A.Normalize(),
ToTensorV2(),
],
)
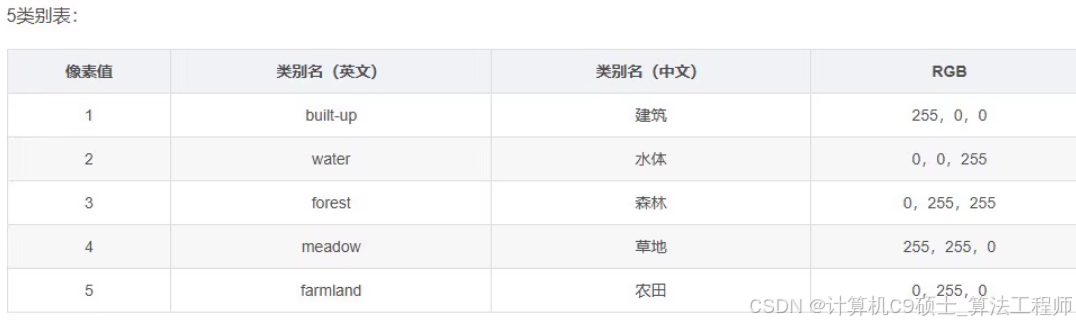
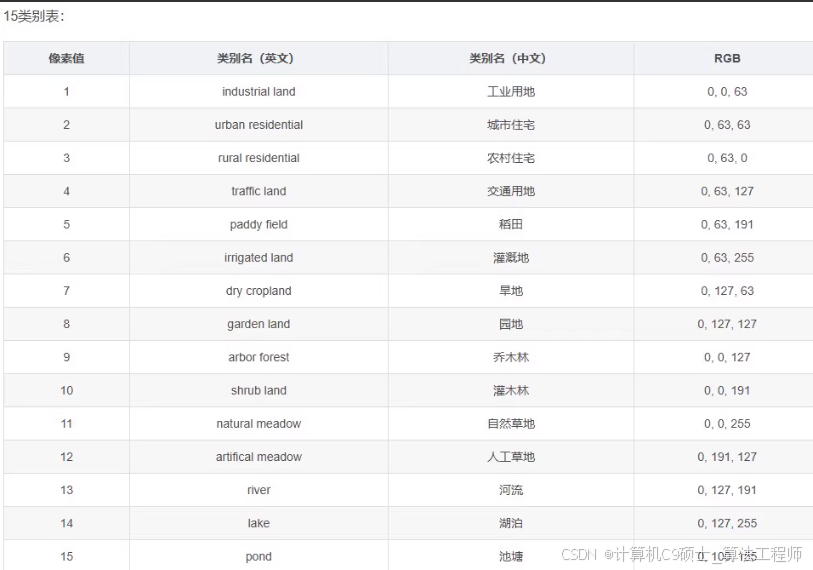
模型定义
接下来是DeepLabV3+模型的定义:
import torchvision
from torchvision.models.segmentation.deeplabv3 import DeepLabHead
def createDeepLabv3(outputchannels=15):
"""创建DeepLabV3+模型实例"""
model = torchvision.models.segmentation.deeplabv3_resnet101(pretrained=True, progress=True)
model.classifier = DeepLabHead(2048, outputchannels)
return model
model = createDeepLabv3(outputchannels=15).cuda() # 假设GID-15有15个类别
训练过程
最后,设置训练循环:
import torch.optim as optim
# 设置训练参数
num_epochs = 20
learning_rate = 0.001
batch_size = 8
dataset = GIDSegmentationDataset(image_dir="path/to/images", mask_dir="path/to/masks", transform=transform)
dataloader = DataLoader(dataset, batch_size=batch_size, shuffle=True)
optimizer = optim.Adam(model.parameters(), lr=learning_rate)
criterion = torch.nn.CrossEntropyLoss()
for epoch in range(num_epochs):
model.train()
running_loss = 0.0
for images, masks in dataloader:
images = images.cuda()
masks = masks.cuda()
optimizer.zero_grad()
outputs = model(images)['out']
loss = criterion(outputs, masks)
loss.backward()
optimizer.step()
running_loss += loss.item()
print(f"Epoch {epoch+1}/{num_epochs}, Loss: {running_loss/len(dataloader)}")
仅提供了一个基本的框架,具体实现可能需要根据实际情况(例如数据路径、类别数量等)进行调整。
为了在学习率调度和损失函数优化方面进行深入探索,采取多种策略来提高模型的性能。
以下是一些常用的方法及其实现示例。仅供参考。
学习率调度
- StepLR:每隔固定epoch数降低学习率。
- ReduceLROnPlateau:当监控量(如验证损失)停止下降时降低学习率。
- CosineAnnealingLR:基于余弦函数周期性地调整学习率。
损失函数优化
除了常用的交叉熵损失,对于不平衡数据集,可以考虑使用加权交叉熵损失或Focal Loss等方法来处理类别不平衡问题。
代码实现
如何将这些技术集成到您的训练流程中的示例代码:
import torch
from torch.optim.lr_scheduler import StepLR, ReduceLROnPlateau, CosineAnnealingLR
import torch.nn as nn
import torch.optim as optim
# 假设已经定义了模型、dataloader、optimizer等
# StepLR 示例
step_lr_scheduler = StepLR(optimizer, step_size=7, gamma=0.1)
# ReduceLROnPlateau 示例
reduce_on_plateau_scheduler = ReduceLROnPlateau(optimizer, mode='min', factor=0.1, patience=5, verbose=True)
# CosineAnnealingLR 示例
cosine_annealing_scheduler = CosineAnnealingLR(optimizer, T_max=10, eta_min=0)
# 加权交叉熵损失函数,适用于类别不平衡的情况
class_weights = torch.tensor([1.0, 2.0, 1.5, ...], dtype=torch.float).cuda() # 根据实际情况设置权重
criterion = nn.CrossEntropyLoss(weight=class_weights)
# Focal Loss 实现
class FocalLoss(nn.Module):
def __init__(self, alpha=1, gamma=2, reduction='mean'):
super(FocalLoss, self).__init__()
self.alpha = alpha
self.gamma = gamma
self.reduction = reduction
self.criterion = nn.CrossEntropyLoss(reduction='none') # 不直接应用reduction
def forward(self, inputs, targets):
ce_loss = self.criterion(inputs, targets)
pt = torch.exp(-ce_loss)
focal_loss = self.alpha * (1 - pt) ** self.gamma * ce_loss
if self.reduction == 'mean':
return focal_loss.mean()
elif self.reduction == 'sum':
return focal_loss.sum()
else:
return focal_loss
focal_loss = FocalLoss(alpha=1, gamma=2)
# 训练循环示例,使用ReduceLROnPlateau作为例子
for epoch in range(num_epochs):
model.train()
running_loss = 0.0
for images, masks in dataloader:
images = images.cuda()
masks = masks.cuda()
optimizer.zero_grad()
outputs = model(images)['out']
loss = criterion(outputs, masks) # 或者使用 focal_loss(outputs, masks)
loss.backward()
optimizer.step()
running_loss += loss.item()
avg_loss = running_loss / len(dataloader)
print(f"Epoch {epoch+1}/{num_epochs}, Loss: {avg_loss}")
# 调整学习率
reduce_on_plateau_scheduler.step(avg_loss) # 对于其他调度器,根据需要调整此处调用
进一步优化建议
- 混合精度训练:使用
torch.cuda.amp自动混合精度训练以加速训练并减少显存占用。 - 数据增强:更复杂的数据增强策略可以增加模型的泛化能力。
- 模型剪枝与量化:对模型进行剪枝和量化以减少计算成本和存储需求。
- 迁移学习:利用预训练模型并在其基础上微调,特别是在数据量有限的情况下非常有用。
通过结合上述策略,您可以进一步优化模型的训练过程,从而获得更好的性能。请根据具体应用场景调整参数和方法。


















 920
920

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









