






想用YOLO做目标检测,但却完全卷不动?强烈推荐大家试试Transformer+目标检测!近来其更是取得了新突破,模型RT-DETRv3,在性能和耗时方面,都碾压YOLOv10!
主要在于,相比YOLO模型,Transformer能够捕捉到全局上下文信息,有助于模型更准确地理解图像内容,提高检测性能。且其具有端到端的特点,能直接从图像到边界框和类别标签进行预测,无需额外的锚框或复杂的后处理步骤,从而简化了训练流程,提高了效率。
此外,基于Transformer做目标检测目前还在上升期,可发挥空间大!
为了让大家紧跟领域前沿,找点发出自己的顶会,我给大家准备了11种创新思路和源码,一起来看!
论文原文+开源代码需要的同学看文末
论文:RT-DETRv3: Real-time End-to-End Object Detection with Hierarchical Dense Positive Supervision
内容
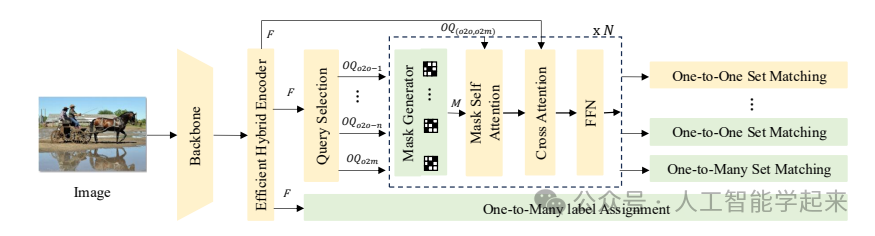
该论文提出的RT-DETRv3是一种基于Transformer的实时端到端目标检测算法,通过引入多层次的密集正样本辅助监督模块来提升模型性能和加速收敛,这些模块仅在训练时使用,不影响推理速度,在保持相同延迟的同时,性能优于现有的实时检测器。
论文:Dpft: Dual perspective fusion transformer for camera-radar-based object detection
内容
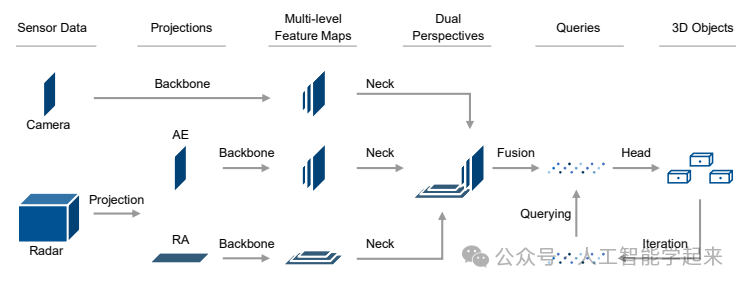
该论文介绍了一种名为Dual Perspective Fusion Transformer (DPFT)的新型相机-雷达融合方法,用于提高自动驾驶车辆的3D目标检测性能,通过利用原始的雷达数据(雷达立方体)而不是处理过的点云数据,以及在相机和地面平面上的投影,有效地使用具有高度信息的雷达并简化与相机数据的融合。
论文:GM-DETR: Generalized Muiltispectral DEtection TRansformer with Efficient Fusion Encoder for Visible-Infrared Detection
内容
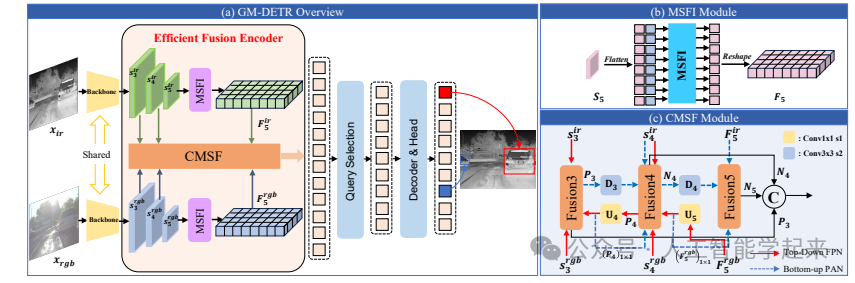
该论文提出了一种名为GM-DETR(Generalized Multispectral DEtection TRansformer)的新型多光谱目标检测算法,该算法通过设计模态特定特征交互(MSFI)模块和跨模态尺度特征融合(CMSF)模块,实现了对RGB和IR数据的有效提取和融合,它采用两阶段训练策略,首先在隔离数据集上训练以增强模型对IR和RGB模态的特征提取能力,然后在对齐数据集上进行融合训练。
论文:Towards sar automatic target recognition multicategory sar image classification based on light weight vision transformer
内容
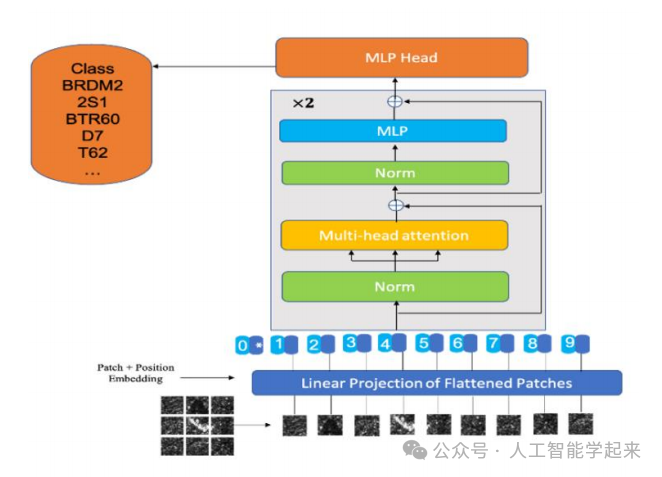
该论文介绍了一种基于轻量级视觉变换器(LViT)的多类别合成孔径雷达(SAR)图像分类方法,用于自动目标识别(ATR),通过在MSTAR数据集上验证该结构,并与传统网络结构进行比较,包括整合多视图数据收集方法和风格迁移输入,如热成像、光学图像和分割表示,以提高模型在不同场景下的泛化能力,并打算将深度学习不确定性度量集成到模型中,以增强SAR图像分类的可靠性和可解释性。
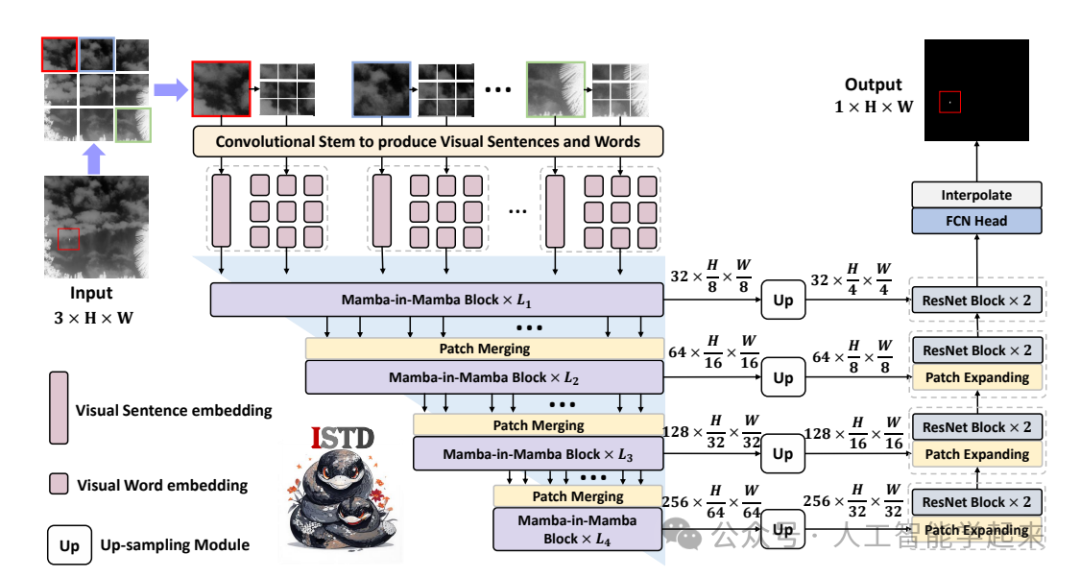
论文:Mim-istd: Mamba-in-mamba for efficient infrared small target detection
内容
该论文提出了一种名为Mamba-in-Mamba(MiM-ISTD)的新型红外小目标检测结构,通过将图像均匀划分为“视觉句子”和“视觉单词”的小块,利用纯Mamba基础的MiM层次化编码器来同时捕获局部和全局特征,实现了更高的准确性和效率,在保持高分辨率红外图像的实时检测能力的同时,显著减少了计算复杂度和GPU内存使用。
关注下方《人工智能学起来》
回复“目标T”获取全部论文+开源代码
码字不易,欢迎大家点赞评论收藏

















 1894
1894

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









