






目录
神经网络的偏差和方差问题
当我们在小型到中型数据集上训练大型神经网络时,通常会遇到偏差和方差的问题。这两个问题会影响模型的性能:
-
偏差(Bias):指的是模型在训练集上的表现。如果模型在训练集上的误差很高,比如与人类水平或其他基准性能相差很大,就说明模型存在高偏差(欠拟合)。这意味着模型没有很好地学习到训练数据中的规律。
-
方差(Variance):指的是模型在训练集和交叉验证集(或测试集)之间的表现差异。如果模型在训练集上表现很好,但在交叉验证集上表现很差,说明模型存在高方差(过拟合)。这意味着模型对训练数据过度拟合,无法泛化到新的数据上。
优化模型的策略
第一步:减少偏差
-
训练模型:首先在训练集上训练神经网络。
-
评估训练误差(Jtrain):检查模型在训练集上的表现,看训练误差是否很高。
-
判断偏差问题:如果训练误差(Jtrain)与目标性能(如人类水平或其他基准)之间存在巨大差距,说明模型存在高偏差。
-
解决方法:增加神经网络的规模,比如增加更多的隐藏层或每层的隐藏单元数量。通过这种方式,可以让模型更复杂,从而更好地拟合训练数据。
-
循环调整:继续增大网络规模,直到模型在训练集上的误差达到满意的水平,比如接近人类水平的误差。
第二步:减少方差
-
评估交叉验证误差(Jcv):在模型已经在训练集上表现良好后,检查它在交叉验证集上的表现。
-
判断方差问题:如果交叉验证误差(Jcv)比训练误差(Jtrain)高很多,说明模型存在高方差。
-
解决方法:获取更多的训练数据,以减少模型对方差的敏感性。
-
重新训练:用更多的数据重新训练模型,然后再次检查模型在训练集和交叉验证集上的表现。
-
循环调整:重复上述过程,直到模型在交叉验证集上也表现良好,即Jcv与Jtrain之间的差距缩小。
方法的局限性
虽然上述方法在某些情况下非常有效,但也存在一些局限性:
-
计算成本:
-
问题:训练更大的神经网络需要更多的计算资源。随着网络规模的增加,训练时间会变得很长。
-
硬件支持:虽然GPU等硬件加速器可以显著提高训练速度,但当网络规模超过一定限度时,即使有硬件支持,训练成本仍然很高。
-
限制:计算成本的限制可能会阻碍进一步增大网络规模。
-
-
数据获取:
-
问题:在某些情况下,可能难以获取更多的训练数据。如果无法获得更多数据,即使模型在训练集上表现良好,也可能无法有效解决高方差问题。
-
限制:数据量的不足可能会限制模型的泛化能力。
-
总结
这种方法的核心思想是通过不断调整神经网络的规模和数据量来优化模型性能。具体步骤是:
-
先通过增大网络规模减少偏差。
-
再通过增加数据量减少方差。

图像内容整理
图像展示了神经网络正则化的概念,以及如何在一个简单的神经网络模型中应用正则化。具体内容如下:
-
正则化公式:
-
损失函数 J(W,B) 包含两部分:一部分是经验风险(即训练集上的损失),另一部分是正则化项。
-
经验风险:
 ,其中 L 是损失函数,m 是样本数量,f 是模型,x(i) 是输入,y(i) 是标签。
,其中 L 是损失函数,m 是样本数量,f 是模型,x(i) 是输入,y(i) 是标签。 -
正则化项:
 ,其中 λ 是正则化参数,w 是权重。
,其中 λ 是正则化参数,w 是权重。
-
-
未正则化的MNIST模型:
-
包含三层全连接层(Dense层):
-
第一层:25个单元,ReLU激活函数。
-
第二层:15个单元,ReLU激活函数。
-
第三层:1个单元,Sigmoid激活函数。
-
-
使用Sequential模型将这三层连接起来。
-
-
正则化的MNIST模型:
-
与未正则化模型结构相同,但在每一层都添加了L2正则化:
-
第一层:25个单元,ReLU激活函数,L2正则化系数为0.01。
-
第二层:15个单元,ReLU激活函数,L2正则化系数为0.01。
-
第三层:1个单元,Sigmoid激活函数,L2正则化系数为0.01。
-
-
同样使用Sequential模型将这三层连接起来。
-
神经网络正则化的重要性和应用方法
-
正则化的好处:
-
拥有一个更大的神经网络几乎没有坏处,只要适当地进行正则化。更大的神经网络可以提供更强的表达能力,从而更好地拟合复杂的函数。
-
适当的正则化可以防止过拟合,即使在计算上可能会稍微增加训练和推理的时间。
-
-
低偏差特性:
-
对于不是特别大的训练集,大型神经网络通常表现出低偏差的特性。这意味着它们在训练集上的表现通常很好,能够很好地学习训练数据中的规律。
-
-
正则化的实现:
-
在TensorFlow中,可以通过在每一层中添加
kernel_regularizer参数来实现正则化。例如,使用L2正则化时,可以设置kernel_regularizer=L2(0.01),其中0.01是正则化系数 λ。 -
可以为不同的层选择不同的正则化系数,但在简单的情况下,通常为所有层选择相同的系数。
-
-
计算成本:
-
虽然更大的神经网络在计算上可能更昂贵,但只要适当地进行正则化,它们通常不会损害算法的性能,甚至可以显著提高性能。
-
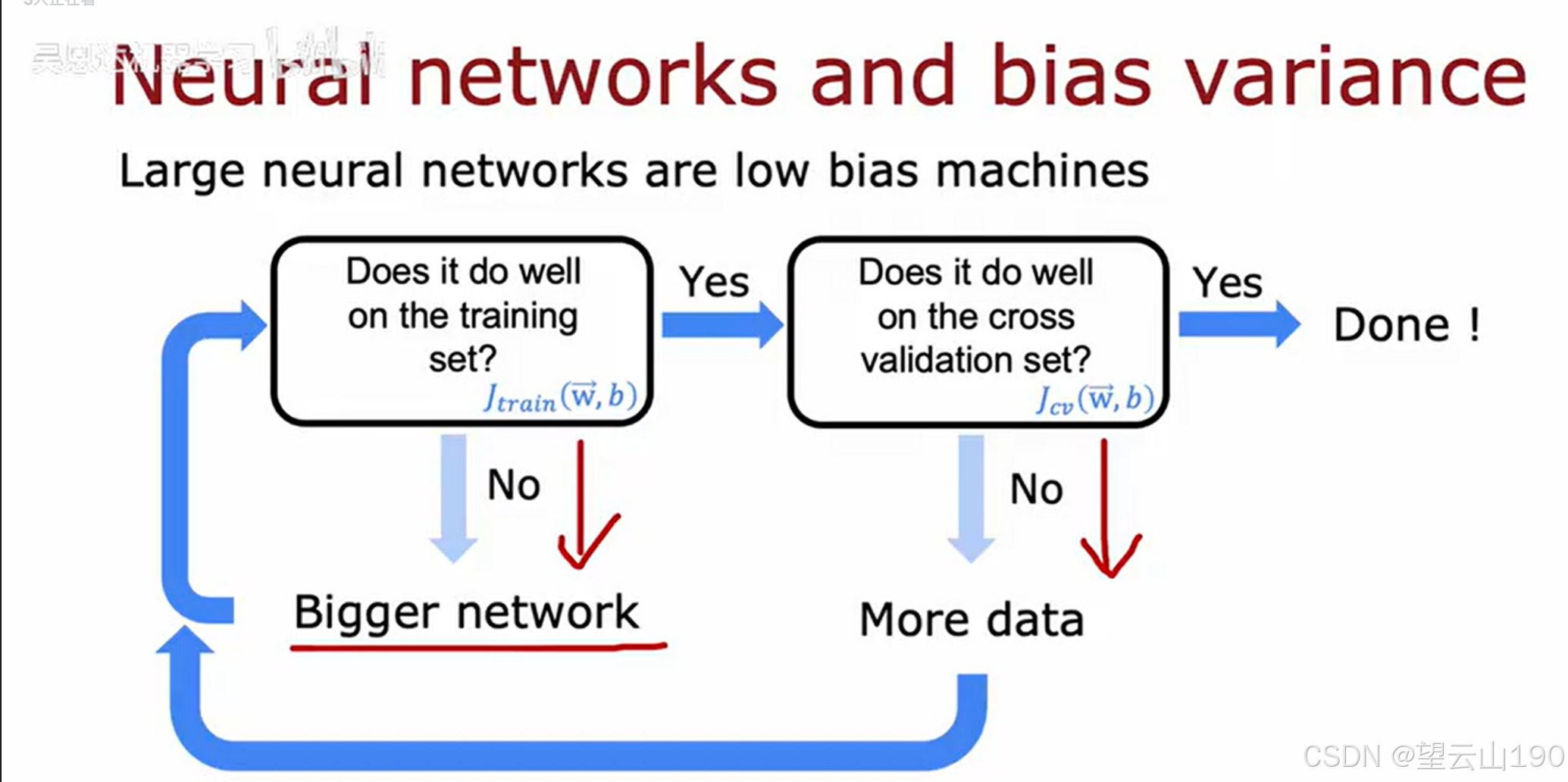
图片展示了一个关于神经网络及其偏差-方差权衡的流程图。标题为“神经网络与偏差方差”,并指出大型神经网络是低偏差机器。流程图描述了训练神经网络时的决策过程:
-
首先,检查神经网络在训练集上的表现:
-
如果在训练集上表现良好(即损失函数 Jtrain(w,b) 较小),则进入下一步。
-
如果在训练集上表现不佳,则需要一个更大的网络。
-
-
接下来,检查神经网络在交叉验证集上的表现:
-
如果在交叉验证集上也表现良好(即损失函数 Jcv(w,b) 较小),则训练完成。
-
如果在交叉验证集上表现不佳,则需要更多的数据。
-
总结来说,这个流程图强调了在训练大型神经网络时,如果模型在训练集上表现良好但在验证集上表现不佳,可能需要更多的数据来减少过拟合。如果模型在训练集上就表现不佳,则可能需要增加模型的复杂度(例如,增加网络层数或神经元数量)。
总结
-
更大的神经网络:只要适当地进行正则化,使用更大的神经网络几乎没有坏处。它们可以提供更强的表达能力,更好地拟合复杂的函数,并且通常表现出低偏差的特性。
-
正则化的实现:在TensorFlow中,可以通过在每一层中添加
kernel_regularizer参数来实现L2正则化。适当的正则化可以防止过拟合,即使在计算上可能会稍微增加训练和推理的时间。 -
低偏差特性:对于不是特别大的训练集,大型神经网络通常表现出低偏差的特性,这意味着它们在训练集上的表现通常很好,能够很好地学习训练数据中的规律。

















 46
46

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









