



Transformer
1 transformer整体架构
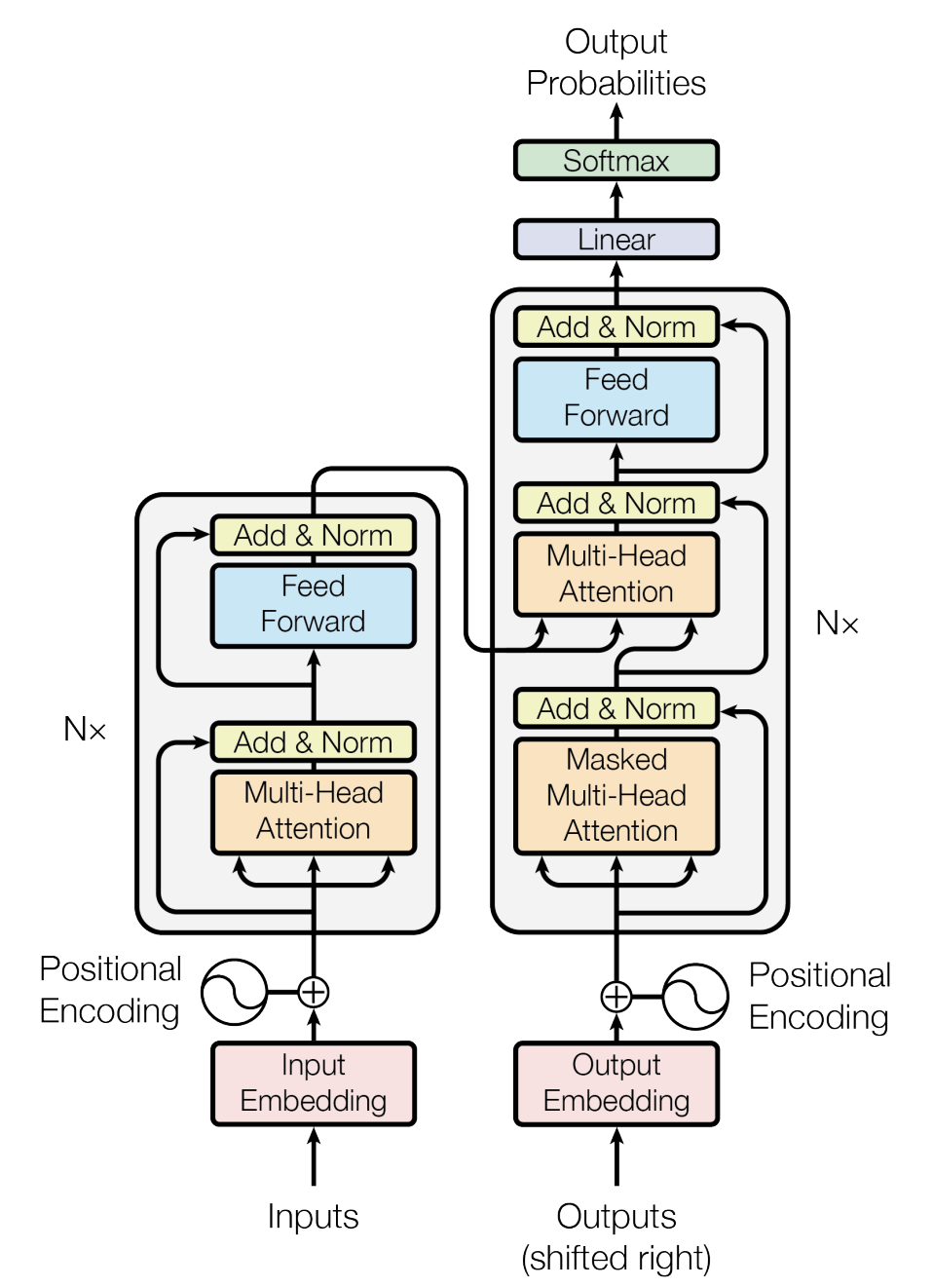
2. 输入
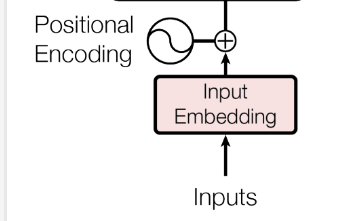
前期数据处理完后得到,语料库,得到了每条数据的批次(batch_size),长度(seq_len),
所以inputs的形状为(batch_size,seq_len)
- batch_size:每批次传入多少句话
- seq_len:一句话最大词数,大于seq的句子被截断,小于seq_len的进行填充(一般是0)
2.1 词嵌入
经过Embedding(vab_size,d_model)---->输出形状为(batch_size,seq_len,d_model)
- vab_size:语料库的大小
- d_model:词向量的维度
2.2 位置编码(positional encoding)
固定的公式,不会随梯度更新而改变

位置编码的形状(batch_size,seq_len,d_model),形状跟词嵌入之后的形状一样可以进行相加操作
最终得到形状(batch_size,seq_len,d_model)
3 编码器层(encoder)
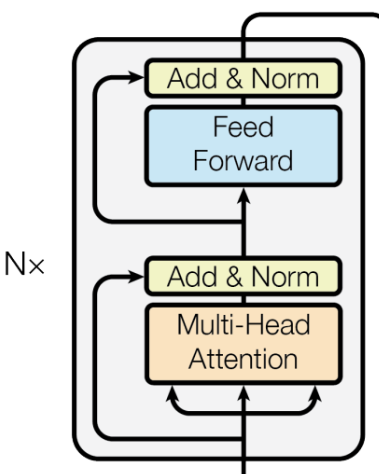
3.1 自注意力机制和多头注意力机制
输入的形状(batch_size,seq_len,d_model)
- 计算Q,K,V,形状不变(batch_size,seq_len,d_model)
- 拆分多头
(batch_size,seq_len,d_model)---->(batch_size,seq_len,num_head,head_dim)
- num_head:头的数量
- head_dim:每个头的维度=d_model//num_head
- 维度变换:(batch_size,seq_len,num_head,head_dim)---->(batch_size,num_head,seq_len,head_dim)
- 计算注意力形状不变:
- 拼接头:(batch_size,num_head,seq_len,head_dim)—>(batch_size,seq_len,num_head,head_dim)---->(batch_size,seq_len,d_model)
- 线性映射,残差连接和层归一化
- 输出(batch_size,seq_len,d_model)
3.2 前馈神经网络(FFN)
输入(batch_size,seq_len,d_model)----->输出(batch_size,seq_len,d_model)
4. 解码器(decoder)
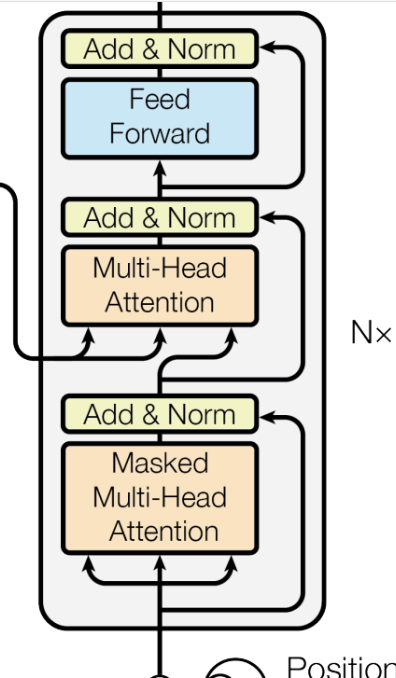
4.1 自注意力机制和掩码多头注意力机制
输入的形状(batch_size,seq_len,d_model)
- 计算Q,K,V,形状不变(batch_size,seq_len,d_model)
- 拆分多头
(batch_size,seq_len,d_model)---->(batch_size,seq_len,num_head,head_dim)
- num_head:头的数量
- head_dim:每个头的维度=d_model//num_head
- 维度变换:(batch_size,seq_len,num_head,head_dim)---->(batch_size,num_head,seq_len,head_dim)
- 计算掩码
- 计算注意力形状不变:
- 拼接头:(batch_size,num_head,seq_len,head_dim)—>(batch_size,seq_len,num_head,head_dim)---->(batch_size,seq_len,d_model)
- 线性映射,残差连接和层归一化
- 输出(batch_size,seq_len,d_model)
4.2 交叉注意力机制
输入的形状enc_outs:(batch_size,s_seq_len,d_model),dec_inputs:(batch_size,d_seq_len,d_model)
- 计算Q,K,V,Q:(batch_size,d_seq_len,d_model)K,V::(batch_size,s_seq_len,d_model
- 拆分多头
(batch_size,seq_len,d_model)---->(batch_size,seq_len,num_head,head_dim)
- num_head:头的数量
- head_dim:每个头的维度=d_model//num_head
- 维度变换:(batch_size,seq_len,num_head,head_dim)---->(batch_size,num_head,seq_len,head_dim)
- 计算掩码
- 计算注意力形状:(batch_size,num_head,d_seq_len,head_dim)
- 拼接头:(batch_size,num_head,d_seq_len,head_dim)—>(batch_size,d_seq_len,num_head,head_dim)---->(batch_size,d_seq_len,d_model)
- 线性映射,残差连接和层归一化
- 输出(batch_size,d_seq_len,d_model)
5 Transformer
输入:enc_inputs:(batch_size,s_seq_len,d_model),dec_inputs:(batch_size,d_seq_len,d_model),
输出:dec_outs:(batch_size,d_seq_len,d_model)

















 1414
1414

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









