






你是否也有这样的桌面?为了方便找材料,全部放到了桌面,最后结果就是“用起一时爽,找起火葬场” 。
。
(图片来源于网络)
你是否也是盘即个人电脑磁使再怎么不够用,也舍不得删除几年前做的运维方案、架构方案、设计方案文档?最后即使文档都保存了,存云盘了,到用的时候依旧发现找不到,找的也不是想要的。
|大模型知识库来袭

现在不用再担心了找不到材料文档了,GitHub开源了一款可离线,支持检索增强生成(RAG)大模型的知识库项目。虽然开源时间不长,但是势头很猛,已经斩获25K Star。具备以下特点:
|
总结下重点就是:
-
支持中文,可私有化部署,免费商用!
-
支持中文,可私有化部署,免费商用!
-
支持中文,可私有化部署,免费商用!
重要的事情说三遍

 ********
********
项目名称:Langchain-Chatchat``项目地址:https://github.com/chatchat-space/Langchain-Chatchat
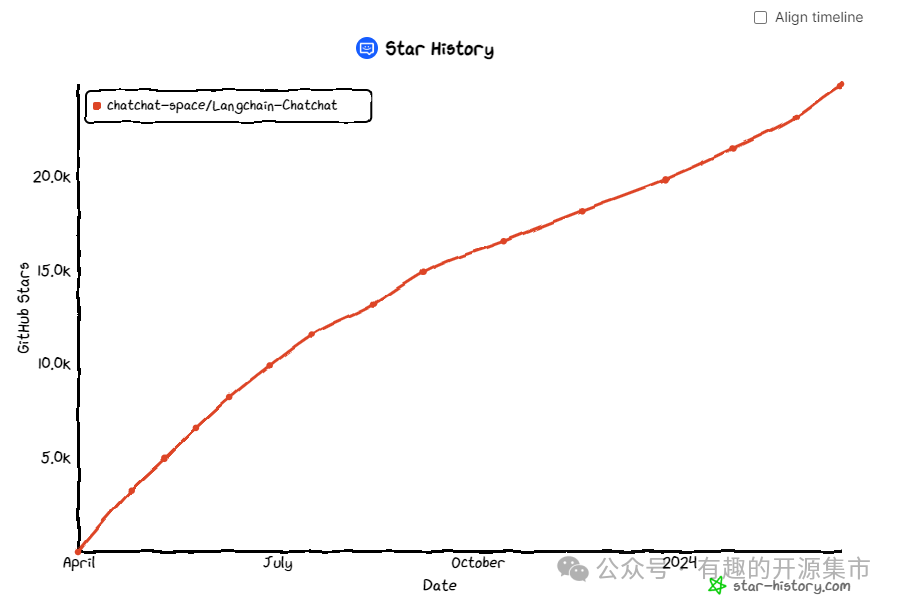
📺 原理介绍视频(点击可看视频)
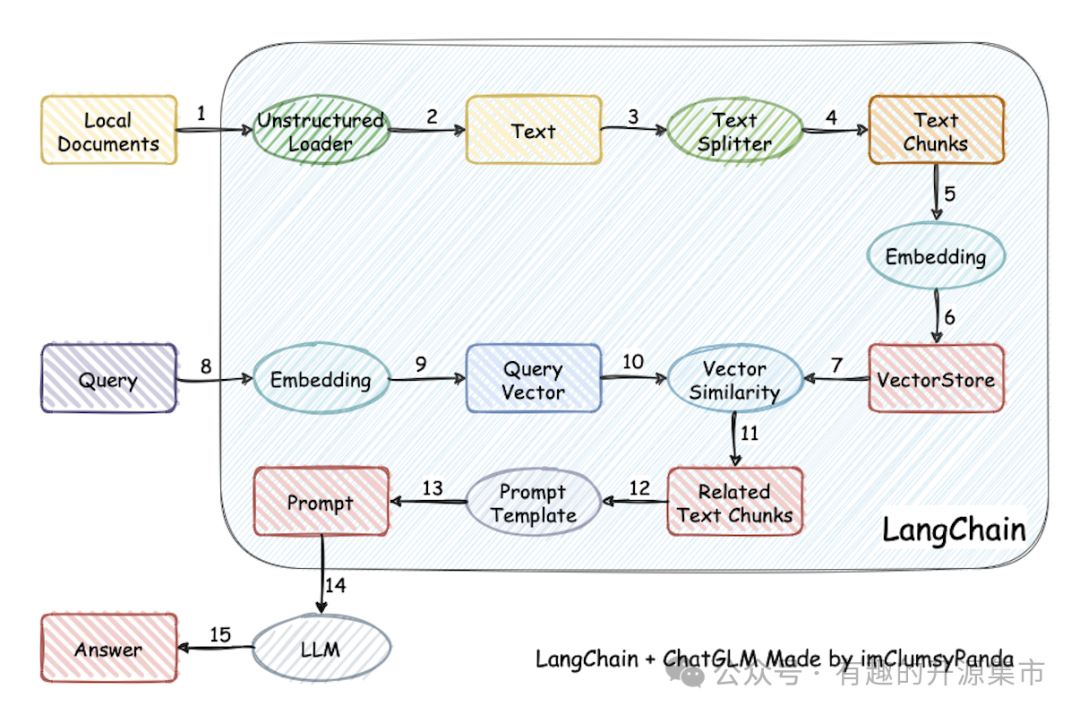
从文档处理角度来看,实现流程如下:
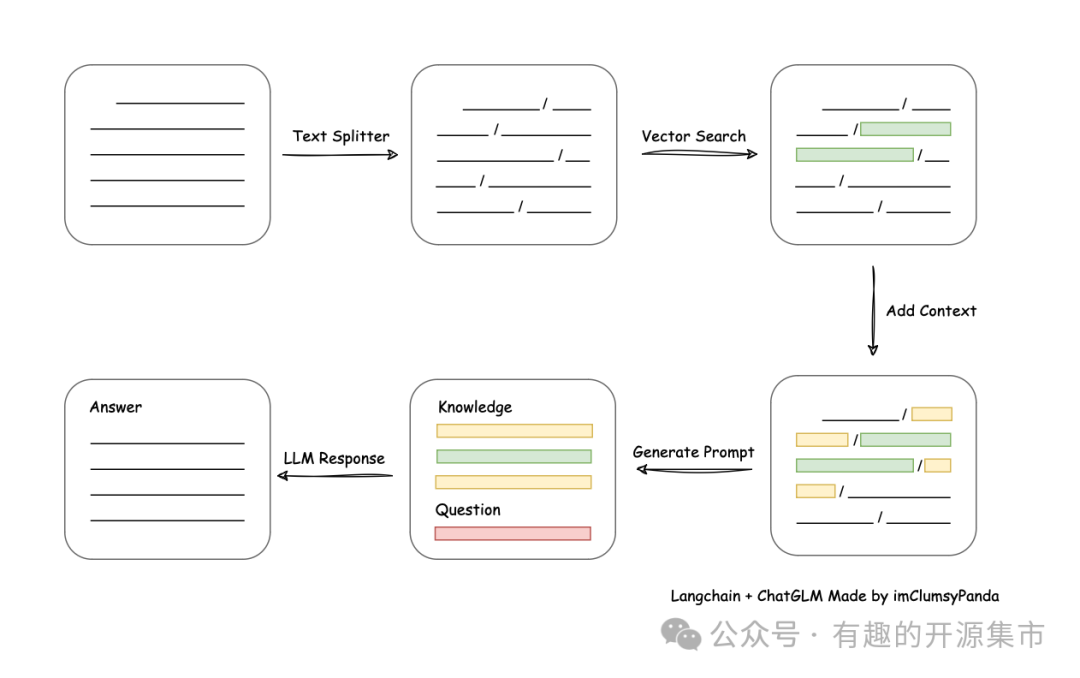
技术路线图:
-
Langchain 应用
-
基础React形式的Agent实现,包括调用计算器等
-
Langchain 自带的Agent实现和调用
-
智能调用不同的数据库和联网知识
-
Bing 搜索
-
DuckDuckGo 搜索
-
Metaphor 搜索
-
接入非结构化文档
-
结构化数据接入
-
分词及召回
-
.txt, .rtf, .epub, .srt
-
.eml, .msg
-
.html, .xml, .toml, .mhtml
-
.json, .jsonl
-
.md, .rst
-
.docx, .doc, .pptx, .ppt, .odt
-
.enex
-
.pdf
-
.jpg, .jpeg, .png, .bmp
-
.py, .ipynb
-
.csv, .tsv
-
.xlsx, .xls, .xlsd
-
接入不同类型 TextSplitter
-
优化依据中文标点符号设计的 ChineseTextSplitter
-
本地数据接入
-
搜索引擎接入
-
Agent 实现
-
LLM 模型接入
-
支持通过调用 FastChat api 调用 llm
-
支持 ChatGLM API 等 LLM API 的接入
-
支持 Langchain 框架支持的LLM API 接入
-
Embedding 模型接入
-
支持调用 HuggingFace 中各开源 Emebdding 模型
-
支持 OpenAI Embedding API 等 Embedding API 的接入
-
支持 智谱AI、百度千帆、千问、MiniMax 等在线 Embedding API 的接入
-
基于 FastAPI 的 API 方式调用
-
Web UI
-
基于 Streamlit 的 Web UI
**|**大模型知识库来袭
Docker 部署
一行代码搞定,但是建议网速不好的同学不要尝试
docker run -d --gpus all -p 80:8501 registry.cn-beijing.aliyuncs.com/chatchat/chatchat:0.2.7
常规模式本地部署方案
1. 环境配置
# 首先,确信你的机器安装了 Python 3.8 - 3.10 版本``$ python --version``Python 3.8.13`` ``# 如果低于这个版本,可使用conda安装环境``$ conda create -p /your_path/env_name python=3.8`` ``# 激活环境``$ source activate /your_path/env_name`` ``# 或,conda安装,不指定路径, 注意以下,都将/your_path/env_name替换为env_name``$ conda create -n env_name python=3.8``$ conda activate env_name # Activate the environment`` ``# 更新py库``$ pip3 install --upgrade pip`` ``# 关闭环境``$ source deactivate /your_path/env_name`` ``# 删除环境``$ conda env remove -p /your_path/env_name
接着,开始安装项目的依赖
# 拉取仓库``$ git clone --recursive https://github.com/chatchat-space/Langchain-Chatchat.git`` ``# 进入目录``$ cd Langchain-Chatchat`` ``# 安装全部依赖``$ pip install -r requirements.txt`` ``# 默认依赖包括基本运行环境(FAISS向量库)。以下是可选依赖:``- 如果要使用 milvus/pg_vector 等向量库,请将 requirements.txt 中相应依赖取消注释再安装。``- 如果要开启 OCR GPU 加速,请安装 rapidocr_paddle[gpu]``- 如果要使用在线 API 模型,请安装对用的 SDK``
此外,为方便用户 API 与 webui 分离运行,可单独根据运行需求安装依赖包。
- 如果只需运行 API,可执行:
$ pip install -r requirements_api.txt`` ``# 默认依赖包括基本运行环境(FAISS向量库)。如果要使用 milvus/pg_vector 等向量库,请将 requirements.txt 中相应依赖取消注释再安装。
- 如果只需运行 WebUI,可执行:
$ pip install -r requirements_webui.txt
2. 模型下载
如需在本地或离线环境下运行本项目,需要首先将项目所需的模型下载至本地,通常开源 LLM 与 Embedding 模型可以从 HuggingFace 下载。
以本项目中默认使用的 LLM 模型 THUDM/ChatGLM3-6B 与 Embedding 模型 BAAI/bge-large-zh 为例:
下载模型需要先安装 Git LFS ,然后运行
$ git lfs install``$ git clone https://huggingface.co/THUDM/chatglm3-6b``$ git clone https://huggingface.co/BAAI/bge-large-zh
3. 初始化知识库和配置文件
按照下列方式初始化自己的知识库和简单的复制配置文件
$ python copy_config_example.py``$ python init_database.py --recreate-vs
4. 一键启动
按照以下命令启动项目
$ python startup.py -a
最轻模式本地部署方案
该模式的配置方式与常规模式相同,但无需安装 torch 等重依赖,通过在线API实现 LLM 和 Ebeddings 相关功能,适合没有显卡的电脑使用。
$ pip install -r requirements_lite.txt``$ python startup.py -a --lite
Demo示例
- Web UI 对话界面:
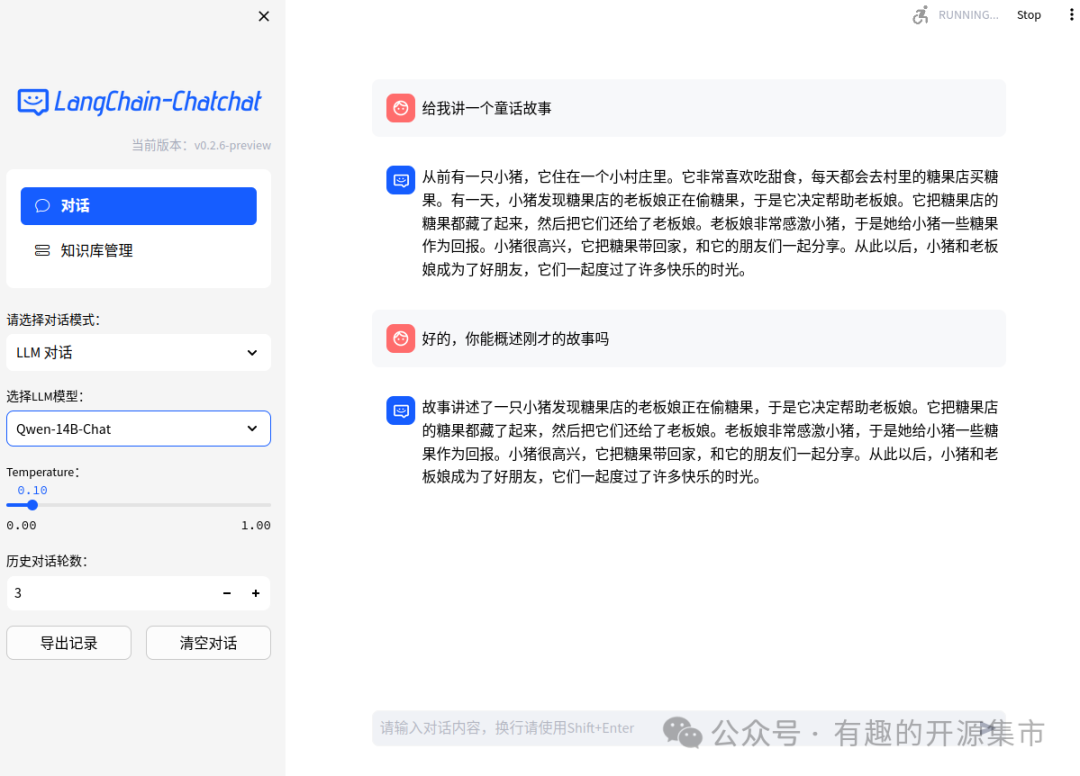
- Web UI 知识库管理页面:
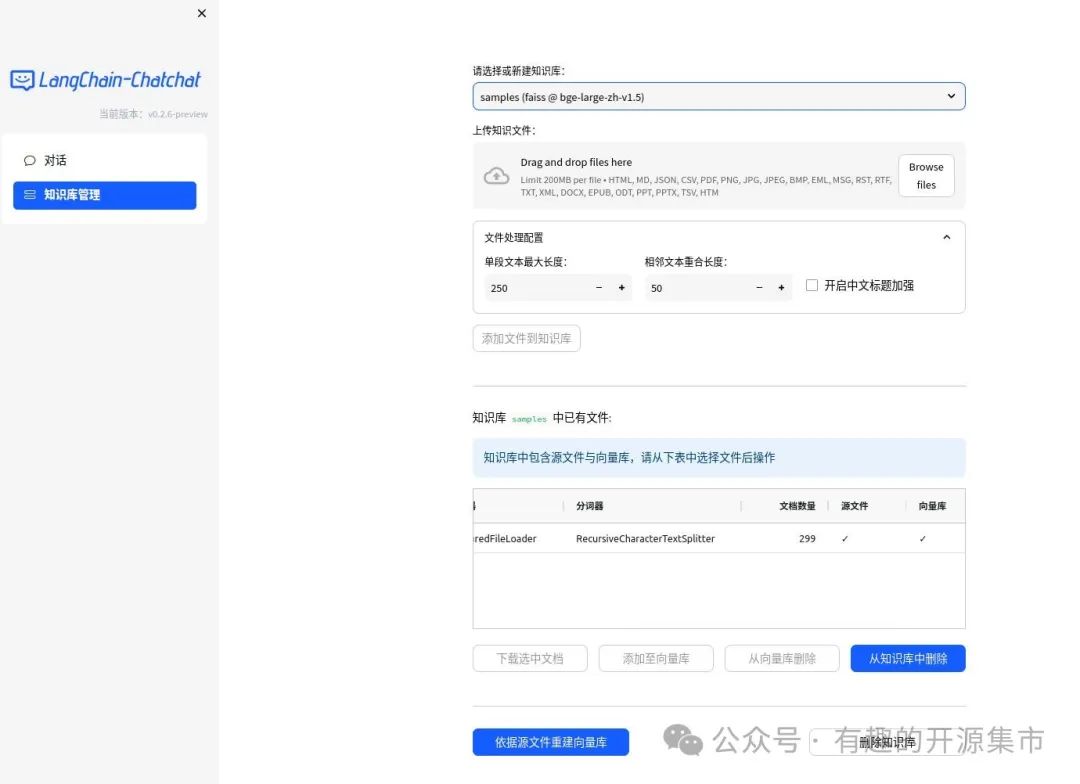
零基础入门AI大模型
今天贴心为大家准备好了一系列AI大模型资源,包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
有需要的小伙伴,可以点击下方链接免费领取【保证100%免费】
1.学习路线图

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
2.视频教程
网上虽然也有很多的学习资源,但基本上都残缺不全的,这是我自己整理的大模型视频教程,上面路线图的每一个知识点,我都有配套的视频讲解。


(都打包成一块的了,不能一一展开,总共300多集)
3.技术文档和电子书
这里主要整理了大模型相关PDF书籍、行业报告、文档,有几百本,都是目前行业最新的。

4.LLM面试题和面经合集
这里主要整理了行业目前最新的大模型面试题和各种大厂offer面经合集。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
1.AI大模型学习路线图
2.100套AI大模型商业化落地方案
3.100集大模型视频教程
4.200本大模型PDF书籍
5.LLM面试题合集
6.AI产品经理资源合集
5.免费获取
这份完整版的大模型 AI 学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码或者点击以下链接都可以免费领取【保证100%免费】


















 4099
4099

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









