






文章目录
- 前言
- 一、🍀插值排序
- 1.🌟插值排序的基本概念
- 2.🌟插值排序的具体步骤
- 3.🌟插值排序的特点
- 4.🌟插值排序与二分查找的关系
- 二、🌻木桶排序
- 1.🌿木桶排序原理
- 2.🌿排序过程
- 3.🌿时间和空间复杂度分析
- 4.🌿桶排序的运用场景
- 5.🌿实际应用木桶
- 🌈总结
前言
本篇文章会介绍算法中的排序问题会用C语言和python两种语言实现,以及在问题中的应用,同时也会分析本次涉及的排序算法的平均运行时间
想要了解数组和冒泡排序、选择排序、二分法查找请看这篇文章:添加链接描述
一、🍀插值排序
实现插值排序的关键是双层循环嵌套
插值排序的原理可以通过以下方面进行详细阐述:
1.🌟插值排序的基本概念
插值排序,又称插入排序,是一种简单直观的排序算法。它的工作原理是通过构建有序序列,对于未排序数据,在已排序序列中从后向前扫描,找到相应位置并插入。
2.🌟插值排序的具体步骤
从第一个元素开始,该元素可以认为已经被排序。
取出下一个元素,在已经排序的元素序列中从后向前扫描。
如果该元素(已排序)大于新元素,则将该元素移到下一位置。
重复步骤3,直到找到已排序的元素小于或者等于新元素的位置。
将新元素插入到该位置后。
重复步骤2~5,直到所有元素均排序完毕。
以集合{3,1,2,9,6}为例,插值排序的过程如下:
从后往前比较,首先拿1与3比较(1<3),则把1插入到3前面,此时集合为{1,3,2,9,6},前面两位数1,3为有序。
拿2依次与3、1比较并插入,此时集合为{1,2,3,9,6},集合中形成有序数列1,2,3。
拿9一次与1、2、3比较,集合仍为{1,2,3,9,6},集合中形成有序数列1,2,3,9。
拿6一次与1、2、3、9比较并插入,形成顺序排列集合{1,2,3,6,9}。
3.🌟插值排序的特点
时间复杂度:在最坏的情况下(即数组元素逆序),插值排序需要进行n(n-1)/2次比较和交换,因此时间复杂度为O(n^2)。但在元素近似有序的情况下,插值排序的效率会更高。
空间复杂度:插值排序是一种原地排序算法,只需要O(1)的额外空间来存储临时变量。
稳定性:插值排序在元素相等时不会进行交换,因此是一种稳定的排序算法。
4.🌟插值排序与二分查找的关系
需要注意的是,插值排序(Interpolation Search)还是一种用于在有序数组中查找特定元素的搜索算法,它是二分查找算法的改进版本。通过使用当前查找值与数组中值的比例来估计下一次查找的位置,而不是简单地取中点。不过,这与上述提到的插入排序是两种不同的算法,不应混淆。
综上所述,插值排序是一种简单且直观的排序算法,适用于小规模数据的排序和元素近似有序的情况。
/*插值排序:从小到大排序*/
#include<stdio.h>
int main()
{
int i,j,arr[]={3,1,2,6,9};
int len=sizeof(arr)/sizeof(int);
printf("没有排序之前:\n");
for(i=0;i<len;i++)
{
printf("%d ",arr[i]);
}
for(i=1;i<len;i++) //遍历数组中的每一个数字
{
int temp=arr[i];
j=i-1;
while(j>=0&&temp<=arr[j]) //可以循环的条件是下标索引值j大于等于零且temp小于等于arr[j],那么前面大于temp的数都会向后移动
{
arr[j+1]=arr[j];
j--;
}
arr[j+1]=temp;
}
printf("\n**********************\n");
printf("\n排序之后:\n");
for(i=0;i<len;i++)
{
printf("%d ",arr[i]);
}
return 0;
}
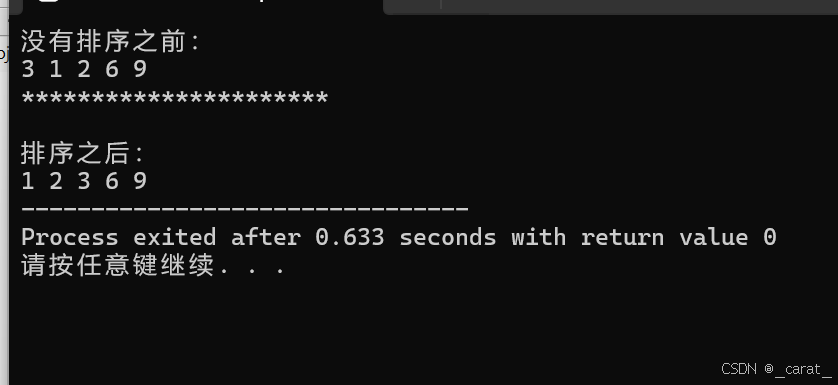
#从小到大排序
def insert(list):
for i in range(1,len(list)): #i表示为牌的下表索引值
temp = list[i] #list[i]表示摸到的牌
j = i-1 #j表示为前面牌的下标索引值,接下来摸到的牌和其前面的牌比大小并交换位置(当摸到的牌比前面某个牌大时 或 摸到的牌已经到牌的最左边即下标索引值为0 )
while j >= 0 and list[j] > temp:
list[j+1] = list[j] #摸到牌的前面比其大就会向右移动一位,即下表索引值会随之+1
j -= 1
list[j+1] = temp #跳出while循环(j==-1 or 下标索引值为j时的牌大小比list[i]小就跳出while循环)后就可以确定摸到牌被放到的位置为j+1了
return list
print("排序以前:")
list_=[1,2,3,6,9]
print(list_)
new_list = insert(list_)
print("由小到大排序以后:")
print(new_list)
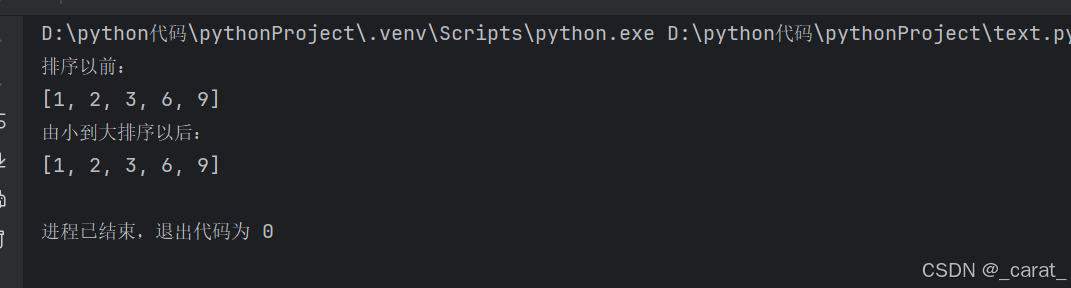
二、🌻木桶排序
1.🌿木桶排序原理
木桶排序,或称桶排序,是一种排序算法,其工作原理是将数组分到有限数量的桶子里,然后对每个桶内的元素再进行个别排序(有可能再使用别的排序算法或是以递归方式继续使用桶排序进行排序)。以下是木桶排序原理的详细解释:
1)、基本假设与前提
桶排序是鸽巢排序的一种归纳结果。
它假设输入数据是由一个随机过程产生的,且该过程将元素一致地分布在某个区间上(如[0, 1))。
在实际应用中,通常要求数据的长度或范围已知,以便合理设计桶的数量和大小。
2.🌿排序过程
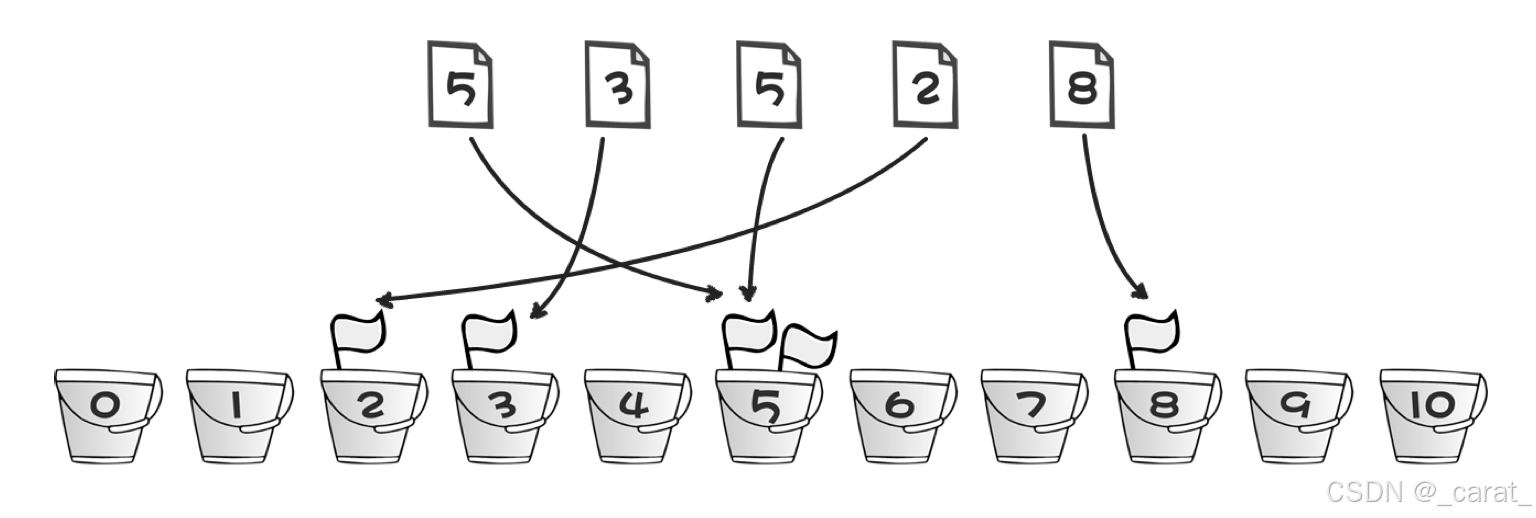
划分桶(桶的作用是存储与桶编号相等的数字):
根据输入数据的范围和数量,划分出有限数量的桶。
每个桶(每个桶有编号,这个编号是下标索引值)可以看作是一个容器,用于存放输入数据(数据大小和桶的编号相等)中的一部分元素。
分配元素到桶:
遍历输入数据,根据某种映射关系(如整除、区间划分等)将元素分配到对应的桶中。
分配过程应确保元素能够较为均匀地分布在各个桶中,以提高排序效率。
桶内排序:
对每个桶内的元素进行排序。
可以使用任何有效的排序算法对桶内元素进行排序,如插入排序、快速排序等。
合并桶:
按照桶的顺序(通常是从左到右或从上到下),将桶内的元素依次连接起来,形成最终的排序结果。
3.🌿时间和空间复杂度分析
在平均情况下,桶排序的时间复杂度为O(n),其中n是输入数据的数量。
当输入数据均匀分布在各个桶中时,每个桶内的元素数量较少,桶内排序的时间复杂度较低。
然而,在最坏情况下(如所有元素都落在同一个桶中),桶排序的时间复杂度会退化为O(n^2),因为此时需要对整个输入数据进行排序。
空间复杂度分析:
桶排序的空间复杂度取决于桶的数量和大小。
如果桶的数量较多或桶的大小较大,会占用较多的内存空间。
因此,在使用桶排序时,需要权衡时间复杂度和空间复杂度之间的关系。
应用与限制
桶排序适用于输入数据范围已知且能够较为均匀地分布在各个桶中的情况。
它不适用于输入数据范围未知或数据分布不均匀的情况,因为此时桶的数量和大小难以合理设计。
此外,桶排序也不适用于浮点数据的排序,因为浮点数的精度和表示范围可能导致映射关系不准确或元素分布不均匀。
综上所述,木桶排序(桶排序)是一种利用桶的映射关系和桶内排序来实现数据排序的算法。它的时间复杂度和空间复杂度取决于桶的数量、大小和输入数据的分布情况。在适当的应用场景下,桶排序可以高效地完成数据排序任务。
4.🌿桶排序的运用场景
木桶排序(桶排序)的运用场景主要包括以下几种情况:
1.数据分布均匀且范围明确:
当待排序数据分布均匀且范围已知时,桶排序能充分利用数据特性,实现高效排序。例如,统计学中的随机样本数据、均匀分布的模拟数据等。
2.高效内部排序算法可用:
若桶内排序可选用计数排序、基数排序等线性时间复杂度的排序算法,桶排序的整体效率将显著提升。这是因为桶排序的时间复杂度在很大程度上取决于桶内排序的效率。
3.对稳定性有要求:
在需要保持相等元素原始相对顺序的场景中,桶排序的稳定性使其成为理想选择。桶排序的稳定性来源于元素是按照其值放入对应的桶中,且桶内排序不影响桶间关系。
特定类型数据排序:
对于具有特定结构或属性的数据(如整数、日期等),可以设计出针对性的桶划分策略,进一步优化桶排序效果。例如,在考试成绩排序中,可以按成绩区间划分范围,统计前几名排行。
4.大规模数据处理:
桶排序在处理大规模数据时具有一定的优势,因为它可以将数据分散到多个桶中进行处理,从而降低了单次排序的复杂度。然而,这也需要额外的空间来存储桶,因此在实际应用中需要权衡空间复杂度和时间复杂度之间的关系。
5.外部排序:
桶排序思想也适用于外部排序,即数据存储在外部存储设备(如磁盘)上时的排序。通过将数据划分成多个桶,并分别对每个桶进行排序和存储,最后再合并所有已排序的桶,可以实现大规模数据的外部排序。
6.数据分析与统计:
在市场分析、网站流量分析等领域,需要对大量数据进行分段统计(如年龄分布、访问量区间等)。桶排序能高效地对数据进行初步分组和排序,为后续的数据分析提供便利。
7.图像处理:
在某些图像处理算法中,比如直方图均衡化,需要对像素强度进行统计和重新分配。桶排序可以用来高效地对像素值进行分组处理,从而优化图像的处理效果。
综上所述,木桶排序(桶排序)在数据分布均匀、高效内部排序算法可用、对稳定性有要求、特定类型数据排序、大规模数据处理、外部排序、数据分析与统计以及图像处理等领域具有广泛的应用场景。然而,在实际应用中也需要根据具体的数据特性和需求来选择合适的排序算法。
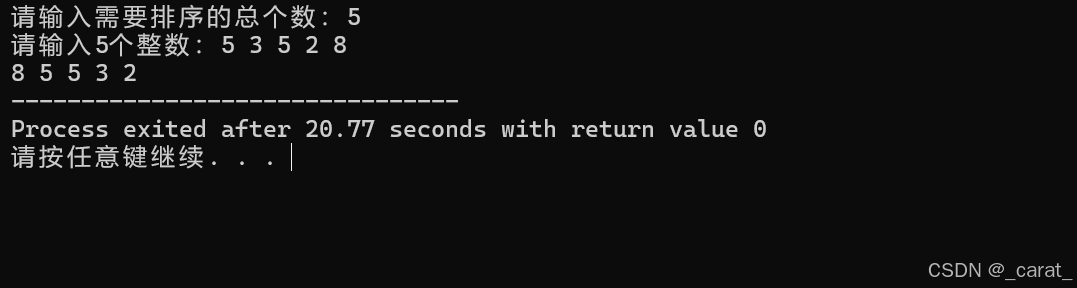
/*木桶排序:从大到小排序*/
#include "stdio.h"
int main()
{
int arr[101],i,j,a,t; //对0~101的整数数据进行排序,数组的作用是记录每一个装入数据与下标索引值相同的数字
printf("请输入需要排序的总个数:");
scanf("%d",&a); //a表示需要排序的数字总个数(范围是0~101)
for(i=0;i<101;i++) //i表示下标索引值
{
arr[i]=0; //把数组中所有的102个元素都初始化为0(每个数据的个数起始值为0)
}
printf("请输入%d个整数:",a);
for(j=0;j<a;j++)
{
scanf("%d",&t);
arr[t]++; //如果每输入一次数字t,则对应下表索引值t的木桶会+1
}
for(i=101;i>=0;i--)
{
for(j=1;j<=arr[i];j++) //控制每个数字输出的次数
{
printf("%d ",i);
}
}
return 0;
}
5.🌿实际应用木桶

题目:
在公司的小哼的学校要建立一个图书角,老师派小哼去找一些同学做调查,看看同学们都喜欢读和可靠性哪些书。小哼让每个同学写出一个自己最想读的书的 ISBN 号(你知道吗?每本书都有唯一的重视。 的 ISBN 号,不信的话你去找本书翻到背面看看)。当然有一些好书会有很多同学都喜欢, 泛采用这样就会收集到很多重复的 ISBN 号。小哼需要去掉其中重复的 ISBN 号,即每个 ISBN 号只多很多, 保留一个,也就说同样的书只买一本(学校真是够抠门的)。然后再把这些 ISBN 号从小到大排序,小哼将按照排序好的 ISBN 号去书店买书。请你协助小哼完成“去重”与“排序” 的工作。
/*木桶排序:从大到小排序+去重处理*/
#include "stdio.h"
int main()
{
int arr[1001],i,j,a,t,count=0; //对0~101的整数数据进行排序,数组的作用是记录每一个装入数据与下标索引值相同的数字
printf("请输入需要编号的总个数:");
scanf("%d",&a); //a表示需要排序的数字总个数(范围是0~101)
for(i=0;i<1001;i++) //i表示下标索引值
{
arr[i]=0; //把数组中所有的102个元素都初始化为0(每个数据的个数起始值为0)
}
printf("请输入%d个整数:",a);
for(j=0;j<a;j++)
{
scanf("%d",&t);
arr[t]=1; //如果每输入一次数字t,则对应下表索引值t的木桶会+1
}
for(i=0;i<1001;i++) //遍历编号数
{
if(arr[i]==1) //控制每个编号输出的次数1次
{
printf("%d ",i);
count++;
}
}
printf("经过去重处理后一共还有%d个编号",count);
return 0;
}
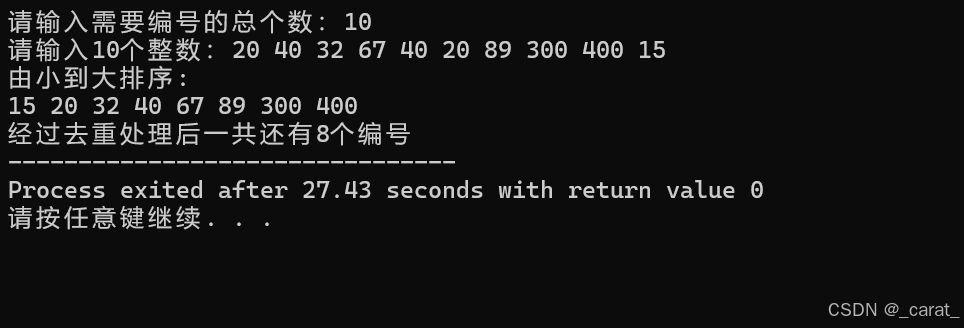
其实这个题还有其他解法,特别是使用python解决更方便!
🌈总结
本篇文章介绍了两种排序算法,除此以外还有快数排序,分块排序…

















 528
528

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









