






要是大家觉得这篇文章还行的话,留个赞再离开吧😍,朋友们的认可是我更新的动力,感谢朋友们的支持😁💐
文章目录
- 前言
- 一、数组
- 🎋1.数组的定义
- 🎋2.元素访问
- 🌟3.内存中的数组
- 🎋4.数组中常见的两个小问题
- 💐二、一些数组的相关算法
- 🍀1.基本查找
- 🍀2.二分法查找
- 🍀3.冒泡排序
- 🍀 4.选择排序
- 🍀 5.打乱数组顺序
- 🎋 总结
前言
本篇文章会详细地介绍数组的相关语法,数组的常见运用。
一、数组
🎋1.数组的定义
一维数组的定义:
数组中存储元素的类型 数组名[ 数组长度 ]={ 存 储的元素 };
二维数组的定义:
数组中存储元素的类型 数组名[ 行数 ][ 列数 ]={存储的元素};
#include "stdio.h"
int main()
{
int arr[]={2,5,6,9,15,16};
int a[][3]={{1,1,3},{2,6,8}};
}
注意:
1.数组名的命名规则同变量名的。
2.一维数组/二维数组的所有元素是存储在一个连续的空间里,二维数组中存储的是多个一维数组。
3. 一旦定义了,那么该数组的长度就是固定不变的。
4. 在一维数组中元素总个数即为数组长度,数组长度可以忽略不写;二维数组定义时行数可以省略不写,但是列数必须写。
5. 数组名是代表数组的首地址,即数组名为该数组存储第一个元素的常量地址,数组一但定义好了,那么在整个代码执行过程中这个首地址也是固定不变的。
6. 数组中存储的元素总个数不能超过数组长度;二维数组中存储总元素的个数不能超过 行数x列数。
int arr[5]={1,2,3}的内存存储示意图如下

🎋2.元素访问
一维数组引用元素的格式:数组名[下标索引值]
二维数组引用元素的格式:数组名[行数][列数]
#include "stdio.h"
int main()
{
int arr[]={2,5,6,9,15,16};
int a[][3]={{1,1,3},{2,6,8}};
}
注意:
1).访问元素时[ ]中必须填入必须是大于等于0的整数常量或则为大于等于0的变量, 每个一维数组的最大索引值为数组长度(数组中总的元素个数)- 1。
2).可以用for循环一次就访问输出一个数组所有的元素;访问一个二维数组的所有元素需要for循环嵌套(此时for循环嵌套就是有内外两层for循环组成的) ,外层是循环二维数组的行数,内层是循环二维数组的列数。
3).下标索引值都是从0开始,然后相邻的下标索引值相隔1。
4).计算每个数组元素总个数=sizeof(arr)/sizeof(arr[0]),由于一个数组内存储的是相同类型的元素,则每个数组元素总个数=sizeof(arr)/sizeof(数组中存储元素的类型)【sizeof(…)可以计算…占有内存的总字节数】
对一维数组的遍历:
#include "stdio.h"
int main()
{
int arr[]={2,5,6,9,15,16};
int len=sizeof(arr)/sizeof(int);
printf("arr的数组为:\n");
for(int i=0;i<len;i++)
{
printf("%d ",arr[i]);
}
}
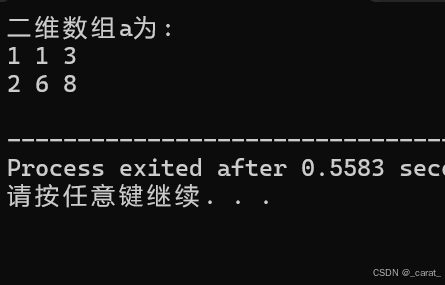
对二维数组的遍历(可以通过这个例子得到对于一个二维数组的同一行就是1个一维数组,则二维数组的行数代表其存储一维数组的总个数):
#include "stdio.h"
int main()
{
int a[][3]={{1,1,3},{2,6,8}};
int num=sizeof(a)/(sizeof(int)*3); //计算二维数组的行数
int i,j;
printf("二维数组a为:\n");
for(i=0;i<num;i++) //二维数组有2行,即外层循环2次
{
for(j=0;j<3;j++) //二维数组有3列,内层每完成3次循环则为外层循环1次
{
printf("%d ",a[i][j]);
}
printf("\n");
}
}
🌟3.内存中的数组
1.数组名表示的是数组的首地址(即第一个元素的地址),其类型是指向数组第一个元素的指针,但带有数组大小的信息。在一维数组中是多个元素组成:数组名就是代表数组第一个元素的地址,即数组名表示数组名[0]元素的地址(访问地址的格式 &访问对象的名称)。【在二维数组中数组名就不是指向第一个存储的数字。由于二维数组是由多个一维数组构成的,则二维数组的元素就是一维数组,那么对于二维数组的数组名指向的就是一个包含数组第一行首元素的数组(即指向第一个一维数组)。】
2.这里就要提到数组名 和 &数组名的区别了。&数组名表示整个数组的地址,类型是指向整个数组的指针,指针运算考虑整个数组的大小;数组名表示数组的首地址,通常隐式转换为指向数组第一个元素的指针,具有数组大小的信息(在指针运算中体现)。
3.&数组名常用于需要将整个数组传递给函数时。例如,当你需要将一个数组作为参数传递给函数,并希望在函数内部知道数组的大小时,可以使用指向整个数组的指针。
4.sizeof(&数组名)实际上给出的是指针的大小(在大多数系统上,这通常是4或8字节,取决于系统是32位还是64位),而不是整个数组的大小。要获取整个数组的大小,你应该直接在定义数组时数组名上使用sizeof,sizeof(数组名)。
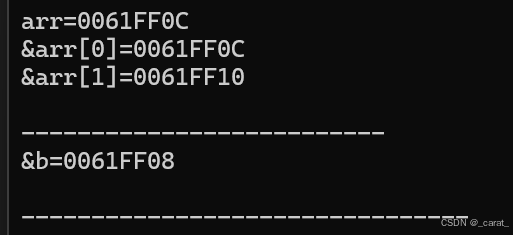
#include"stdio.h"
int main()
{
int arr[]={1,2,6,8,9};
printf("arr=%p\n",arr);
printf("&arr[0]=%p\n ",&arr[0]);
printf("&arr[1]=%p\n ",&arr[1]);
printf("\n--------------------------\n");
int b=20;
printf("&b=%p\n",&b);
}
#include "stdio.h"
int main()
{
int arr[2][3]={{1,1,3},{2,6,8}};
printf("arr[2][3]=%p\n",arr[2][3]);
printf("&arr[0][0]=%p\n",&arr[0][0]); //系统中内存地址表现形式为16进制
printf("&arr[1][0]=%p\n",&arr[1][0]);
//注意:arr[0][0]到arr[1][0]的偏移量位一个单位(一个偏移量单位此时表示1个一维数组所占总字节数位3x4=12)
}
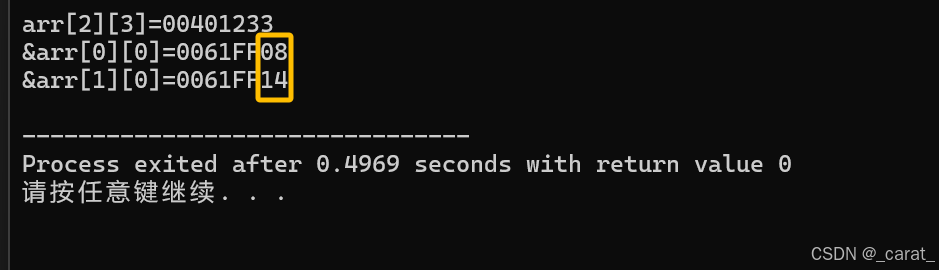

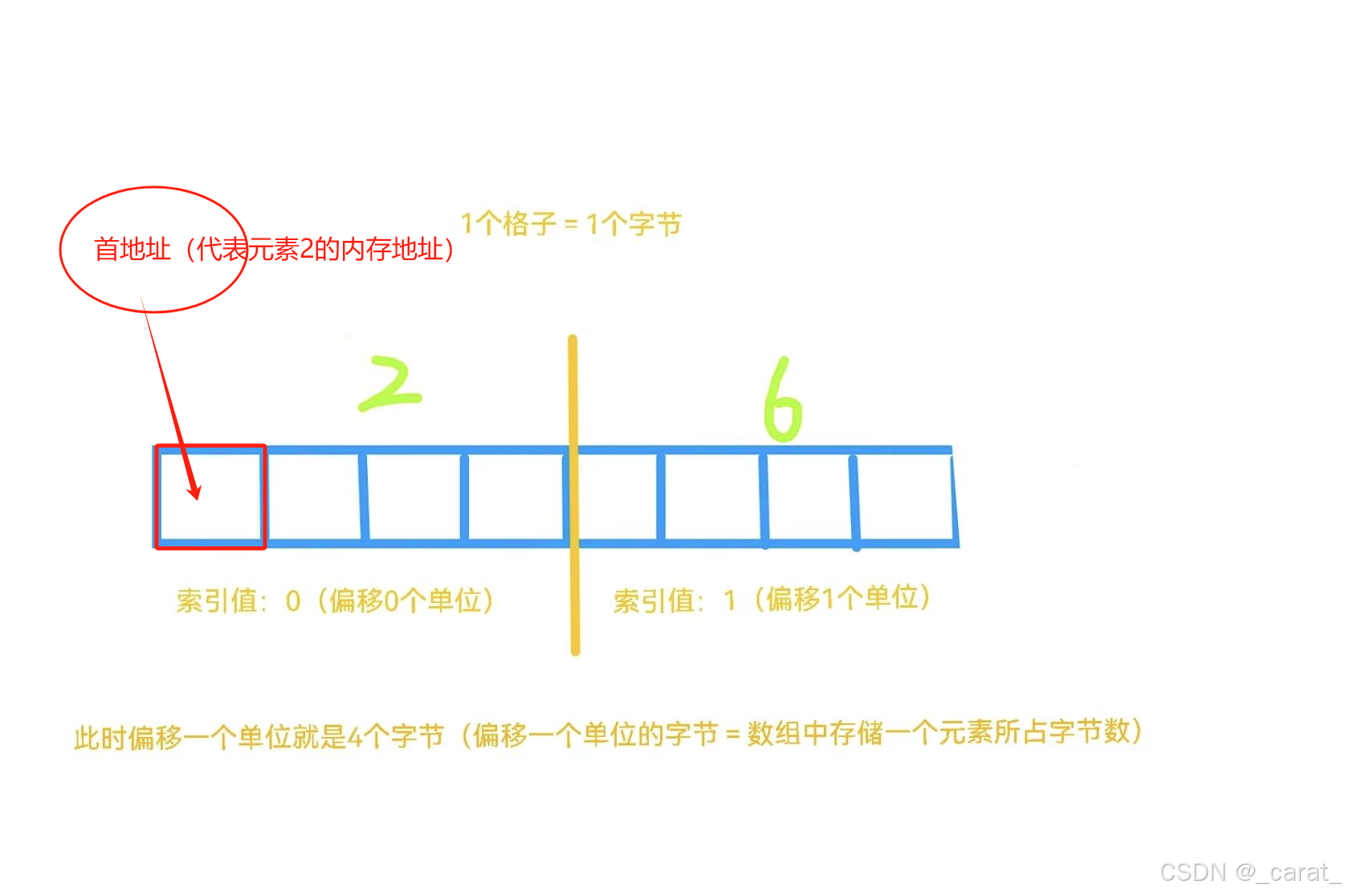
2.深层探究数组内存:数组的下标索引值都是从0开始的,因为在数组中存储的第一个元素的偏移量为0,然后到下一个元素的索引值变为1是因为这个元素相比于首元素向右偏移量为1。但是对于一维数组的偏移量相差1个单位的内存地址值相差量就是该数组存储元素类型占有内存的字节(比如一维数组存储元素为int型,则相邻元素的内存地址值相差4个字节…);对于二维数组,二维数组的存储元素为一维数组,那么二维数组中偏移量相差1个单位就是1个一维数组总占的内存地址字节数(比如二维数组存储的每一个一维数组中都是3个int类型的数字,则该二维数组相差偏移量为1个单位的内存地址值就相差3x4=12个字节)。概括来讲就是访问数组元素的索引本质上为偏移量(在同一个数组中的每一个元素占有的字节数就是1个索引值 或者说成 1个偏移量)。
理解偏移量有助于对后续指针运算的理解!!!
int arr[]={2,6}
一维数组arr的内存示意图
int a[3][5]={{1,2,3,4,5},{6,7,8,9,10},{11,12,13,14,15}}
二维数组a的内存示意图:

常见数据类型占用字节数:
#include "stdio.h"
int main()
{
int num1=sizeof(int); //int占4个字节
int num2=sizeof(char); //char占1个字节
int num3=sizeof(float); //float占4个字节
int num4=sizeof(double); //double占8个字节
int num5=sizeof(long int); //long int占4个字节
int num6=sizeof(long long int); //long long int占8个字节
printf("num1=%d num2=%d num3=%d ",num1,num2,num3);
printf("num4=%d num5=%d num6=%d ",num4,num5,num6);
}
3.注意数组存储空间是连续的,即是相邻元素的下标索引值相差1(也是偏移量相差1,1个偏移量代表元素类型所占字节数)。
🎋4.数组中常见的两个小问题
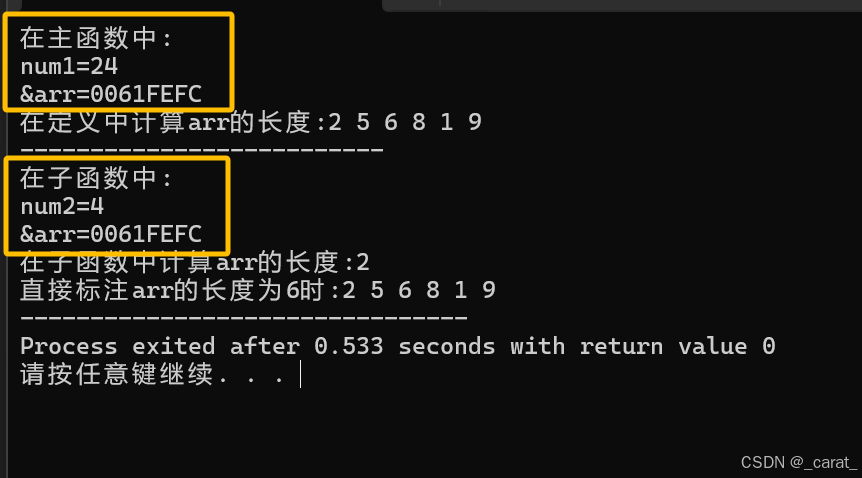
1.问题一:数组作为参数在函数中传递的注意事项:在定义arr数组时,arr是一个完整的数组;在子函数中arr作为参数传递时,只是一个变量,记录数组首元素的地址,arr虽然还是表示整个数组,但是在arr作为子函数的参数传递时其数组长度发生变化了,意味这在子函数中借助len=sizeof(arr)就无法在子函数访问arr中所有元素。
那么如何把数组arr在子函数中借助len+for循环遍历所有arr中的元素:记得把数组在函数中传递的时候,同时,把数组arr的长度一起传递给相同的子函数 。
(这里以一维数组举例)
#include "stdio.h"
int text(int arr[]);
int main()
{
printf("在主函数中:\n");
int arr[]={2,5,6,8,1,9};
int num1=sizeof(arr);
printf("num1=%d\n",num1);
printf("&arr=%p\n",arr);
int len=sizeof(arr)/sizeof(int);
printf("在定义中计算arr的长度:");
for(int i=0;i<len;i++)
{
printf("%d ",arr[i]);
}
printf("\n--------------------------\n");
printf("在子函数中:\n");
text(arr);
}
int text(int arr[])
{
int num2=sizeof(arr);
printf("num2=%d\n",num2);
int len=sizeof(arr)/sizeof(int);
printf("&arr=%p\n",arr);
printf("在子函数中计算arr的长度:");
for(int i=0;i<len;i++) //要是在函数中计算数组arr的长度sizeof(arr),那么用for循环遍历时就无法完整访问输出所有arr元素
{
printf("%d\n",arr[i]);
}
printf("直接标注arr的长度为6时:");
for(int i=0;i<6;i++) //用for循环遍历时直接写数组arr长度为6,在函数中arr所有元素也可以完整地被访问输出
{
printf("%d ",arr[i]);
}
}
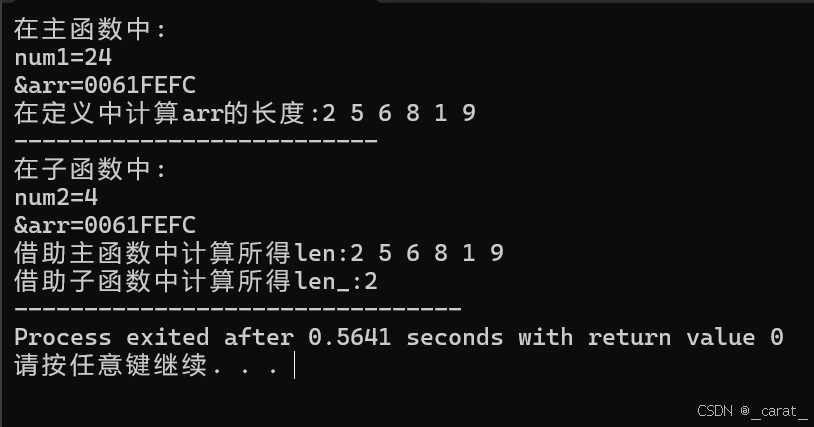
下面是对以上代码的改良版本:
#include "stdio.h"
int text(int arr[],int len);
int main()
{
printf("在主函数中:\n");
int arr[]={2,5,6,8,1,9};
int num1=sizeof(arr);
printf("num1=%d\n",num1);
printf("&arr=%p\n",arr);
int len=sizeof(arr)/sizeof(int);
printf("在定义中计算arr的长度:");
for(int i=0;i<len;i++)
{
printf("%d ",arr[i]);
}
printf("\n--------------------------\n");
printf("在子函数中:\n");
text(arr,len);
}
int text(int arr[],int len)
{
int num2=sizeof(arr);
int len_=sizeof(arr)/sizeof(int);
printf("num2=%d\n",num2);
printf("&arr=%p\n",arr);
printf("借助子函数中计算所得len_:");
for(int i=0;i<len_;i++)
{
printf("%d ",arr[i]);
}
printf("\n借助主函数中计算所得:");
for(int i=0;i<len;i++)
{
printf("%d ",arr[i]);
}
}
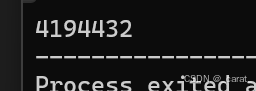
2.问题2:数组的索引越界(注意数组索引长度最大不超过数组长度-1)
#include "stdio.h"
int main()
{
int arr[]={1,2,8,9,6};
printf("%d",arr[5]); //输出的结果异常
}
💐二、一些数组的相关算法
🍀1.基本查找
原理:for循环遍历每个数组的元素寻找目标值,然后用return返回保存结果方便调用输出【return作用:1.表示函数结束 2.返回保存一个具体值 或者 返回保存一个表达式】。
/*借助自定义函数实现基本查找*/
#include "stdio.h"
int order(int arr[],int len,int num); //自定函数写在main函数以前 或 写到main函数以后但是要在main函数申明自定义函数名(形参类型 形参)
int main()
{
int arr[]={1,33,2,11,9,5,90,145,150};
int num,len=sizeof(arr)/sizeof(int); //每个数组中的元素总个数=sizeof(数组名)/sizeof(数组存储元素类型)
printf("请输入一个正整数;\n");
scanf("%d",&num);
printf("arr数组为:\n");
for(int i=0;i<len;i++)
{
printf("%d ",arr[i]);
}
printf("\n------------------------------\n");
int result=order(arr,len,num); //函数return返回只需要一个东西接受
if(result==-1)
{
printf("\n%d",result);
printf("\n%d不在数组arr中 ",num);
}
else
{
printf("在数组arr中的下标索引值为:%d",result);
}
}
int order(int arr[],int len,int num)
{
for(int i=0;i<len;i++)
{
if(arr[i]==num) //return有两个作用:1.结束执行一个函数,2.可以返回一个值保存可以再次调用
{
return i;
}
}
return -1; //当数组遍历一次结束,但是在数组没有与目标数据相等的就返回-1
}
🍀2.二分法查找
使用前提是数组必须有序。关键是if语句和while循环,while循环条件是min<=max,注意没有在数组中找到target之前mid会随时因为min或者max变化而改变大小,那么mid=(mid+max)/2应该写在while循环里面的。
原理(按由小到大的数组举例):
1.先定义初始下标索引值:两个初始两min=0,max=数组总的元素个数-1。
2.当 left 小于等于 right 时,执行以下步骤:
计算中间索引 mid:mid = left + (right - left) / 2(避免 (left + right) / 2 可能导致的整数溢出)。
·比较中间元素 arr[mid] 与目标元素 target:
·如果 arr[mid] == target,查找成功,return返回 mid。
·如果 arr[mid] < target,说明目标元素在右半部分,更新 left = mid + 1。
·如果 arr[mid] > target,说明目标元素在左半部分,更新 right = mid - 1。
2.查找失败:如果循环结束仍未找到目标元素,返回 -1 或其他表示未找到的值。
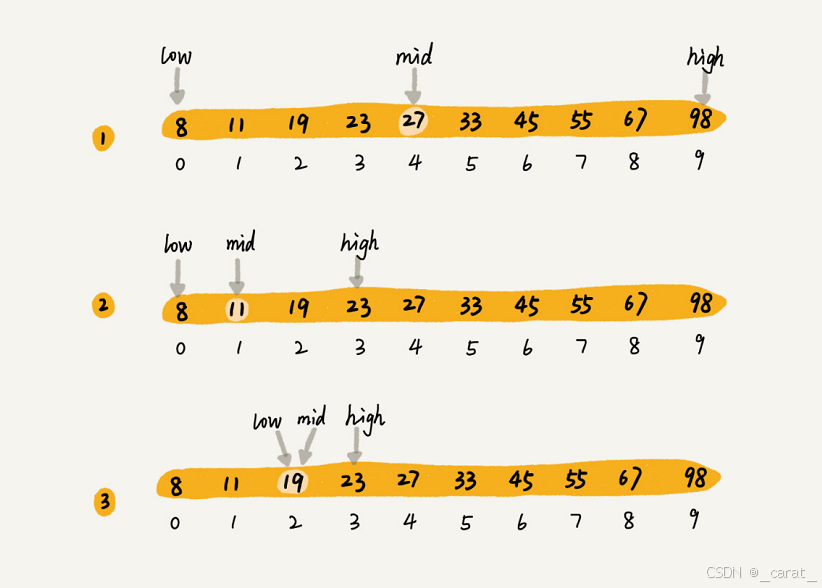
//算法:二分法查找
#include "stdio.h"
int order(int arr[],int len,int num)
{
int min=0,max=len-1;
while(min<=max) //在循环的数一定有min值不超过max值恒成立
{ int mid=(min+max)/2; //在没找到目标数据之前mid值会在循环中一直因min或max发生变化而变化
if(arr[mid]<num)
{
min=mid+1;
}
else if(arr[mid]>num)
{
max=mid-1;
}
else
{
return mid;
}
}
return -1;
}
int main()
{
int arr[]={8,11,19,23,27,33,45,55,67,98};
int len=sizeof(arr)/sizeof(int),num;
printf("请输入一个整数:");
scanf("%d",&num);
int index=order(arr,len,num);
if(index==-1)
{
printf("\n%d\n",index);
printf("\n%d不在arr数组中",num);
}
else
{
printf("\n%d在arr中下标索引值为:%d",num,index);
}
return 0;
}
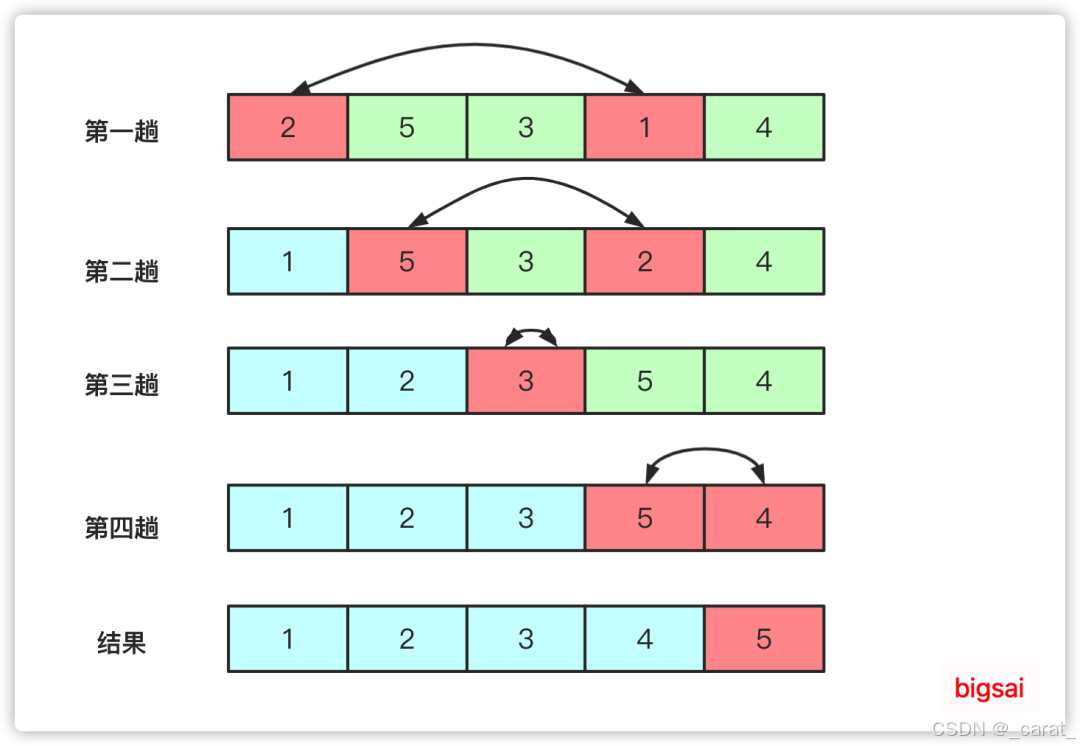
🍀3.冒泡排序
首先明确冒泡排序的关键是for循环的嵌套,要明白for循环外层是代表循环总次数=需要排序的总个数-1,而for循环内层代表每一轮冒泡排序时相邻数字比较大小的总次数,每完成一轮冒泡排序那么下一轮的冒泡排序就会比上一轮的冒泡排序时相邻数字大小比较的总次数减少1次,本质是那在参与比较的数字中的最大值就会排到参与比较的所有数最后(排好位置的数就不用管了)
原理:
1.相邻元素之间比较大小,直到排好一个元素的位置就是完成一轮冒泡排序(即是完成一次外层循环)
2.每排好一个元素的位置,则相邻元素比较大小的总次数就比上一轮的冒泡排序减少一次
3.重复过程对每一轮比较和交换后的数列(不包括已经排序好的末尾部分),重复上述步骤,直到整个数列排序完成。
代码如下(由小到大排序):
//算法:冒泡排序(从小到大排序)
#include "stdio.h"
int text(int arr[],int len);
int main()
{
int arr[]={2,5,3,1,4};
int len=sizeof(arr)/sizeof(int);
printf("没有排序之前的数组arr为:\n");
for(int i=0;i<len;i++)
{
printf("%d ",arr[i]);
}
printf("\n-----------------------------\n");
text(arr,len);
printf("由小到大排序的数组arr为:\n");
for(int j=0;j<len;j++)
{
printf("%d ",arr[j]);
}
return 0;
}
int text(int arr[],int len)
{
int i,j;
for(i=0;i<len-1;i++) //对arr中每个数据的遍历,len-1是为了防止i=5时arr[6]不存在导致数据溢出
{
for(j=0;j<len-1-i;j++)
{
if(arr[j]>arr[j+1])
{
int temp=arr[j]; //借助中间"容器"temp交换arr[j]和arr[j+1]的位置
arr[j]=arr[j+1];
arr[j+1]=temp;
}
}
}
}
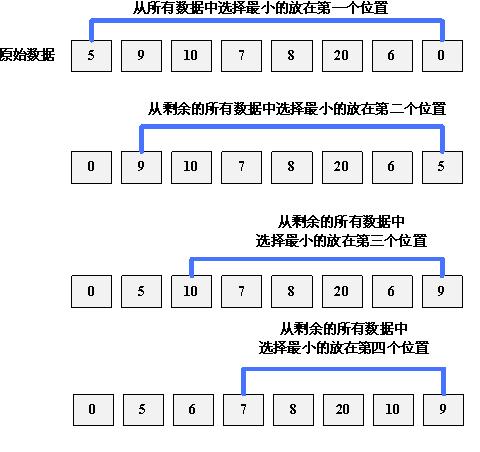
🍀 4.选择排序
选择排序的关键也是for循环嵌套,for循环的外层循环是每一次循环固定要比较大小的数字,for循环的内层循环是完成一次循环与固定外层循环数字后面位置比较大小的数字。每完成一次排序,那么下一次比较大小的总次数会减少1次。
原理(由小到大排序,如果需要从大到小排序那么原理和以下内容类似,这里就只用由小到大排序为例):
1.初始化:
假设数组为 arr,长度为 n。
初始化已排序部分的边界为 0(即开始时没有元素是已排序的)。
2.外层循环:
从 i = 0 到 n - 1,每次迭代将 arr[i] 设置为当前未排序部分的最小值。
内层循环:
在每次外层循环中,从 j = i + 1 到 n - 1,查找后面排序部分的最小元素。
3.交换:
如果满足arr[i]>arr[j],则将 arr[i] 与 arr[j] 交换。
4.完成:
当外层循环结束时,数组已完全排序。
//算法:选择排序
#include "stdio.h"
int main()
{
int arr[]={9,1,2,5,7,4,8,6,3,5};
int len=sizeof(arr)/sizeof(int);
int i,j;
printf("没有排序前的数组为:\n");
for(i=0;i<len;i++)
{
printf("%d ",arr[i]);
}
printf("\n----------------------------\n");
for(i=0;i<len-1;i++)
{
for(j=i+1;j<len;j++) //从arr[i]的下一项开始比大小,直到和arr[len-1]比完大小,则为完成一次循环
{
if(arr[i]>arr[j]) //每一次循环把后面最小的数字提前
{
int temp=arr[i];
arr[i]=arr[j];
arr[j]=temp;
}
}
}
printf("由小到大排序前的数组为:\n");
for(i=0;i<len;i++)
{
printf("%d ",arr[i]);
}
return 0;
}
🍀 5.打乱数组顺序
原理:借助电脑生成伪随机数作为下标索引值以及for循环使数组arr中元素的顺序被打乱。
/*打乱数组的排序,借助随机数的生成*/
#include "stdio.h"
#include "time.h"
#include "stdlib.h"
int main()
{
int arr[]={1,2,3,4,5,6};
int len=sizeof(arr)/sizeof(int);
printf("打乱顺序后的数组为:\n");
for(int i=0;i<len;i++){
printf("%d ",arr[i]);
}
srand(time(NULL)); //利用时间戳(时间戳是一直都在变化的)来设置种子
//下标索引的范围是0~5,则生成随机数的范围也是0~5
for(int i=0;i<len;i++){
int index=rand()%len; //随机数除以数组长度取余数,那么余数为不超过数组长度的正整数,index的范围是0~5
int temp=arr[index];
arr[index]=arr[i];
arr[i]=temp;
}printf("\n--------------------------------");
printf("\n打乱顺序后的数组为:\n");
for(int i=0;i<len;i++){
printf("%d ",arr[i]);
}
}
🎋 总结
1.本篇文章探究了数组内存的本质:索引值本质为偏移量,而一个偏移量所占内存大小等于数组存储元素类型所占字节数。用偏移量理解这个问题,有助于对指针运算的理解,所以偏移量是一个重点。
2.简单查找的效率低于二分法查找,但是简单查找能用于有序数组和无序数组。
3.选择排序的效率有时候优于冒泡排序,要是从选择冒泡、选择排序挑一个方法对乱序数组排序,建议选择后者。
感谢朋友们耐心读完这篇文章,要是有什么问题可以在讨论区提出来,欢迎大家提出自己的看法。😃



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









