






大家知道无论是大语言模型GPT系列,还是推理模型OpenAI o1、DeepSeek R1,都采用了Transformer架构。Transformer架构通过“自注意力机制”彻底重塑了自然语言处理,使得模型能够更好地理解和生成语言。本文从注意力机制的起源、发展历程说起,核心介绍了注意力机制的原理,并介绍了自注意力机制与注意力机制的区别。
01 什么是注意力机制?
注意力机制(Attention Mechanism)是一种模仿人类注意力行为的计算模型,其核心思想是让模型能够有选择性地关注输入序列中的不同部分,并为这些部分分配不同的权重,以此来突出对任务更关键的信息。
深度学习引入注意力机制的主要原因是为了解决传统模型在处理长序列数据时存在的信息遗忘和上下文信息丢失问题。传统的序列模型如RNN和LSTM在处理长序列时,容易出现信息遗忘和梯度消失的问题,导致模型难以捕捉到长距离的依赖关系。
02 注意力机制的起源
注意力机制起源于人类或动物大脑的注意力机制。比如动物在广阔的大草原上会快速注意到自己的猎物或者天敌。人类在环境中也会根据随意线索(主观)和不随意(客观)线索选择注意点。
比如如下例子,第一眼我们会看到红色的杯子,它相比于其它物品颜色偏亮,属于不随意线索。假设拿起杯子喝了之后,接下来想读书,那这就是随意线索(跟随意志,有意识:有意识的关注你想要的)。想要读书的这个随意线索,就代表了我们把注意力要投入到书本当中。
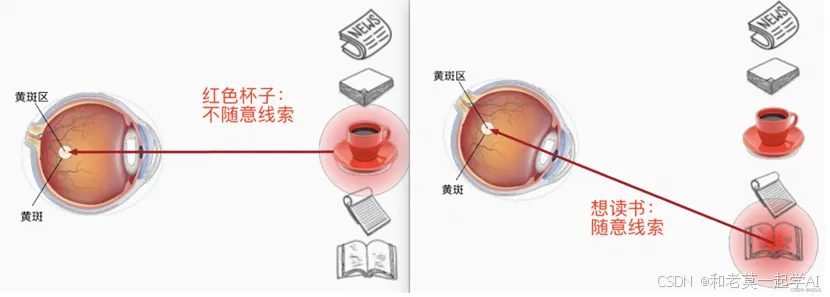
也就是说人类的视野开阔,但是焦点只有一小范围或一个点,这就是所谓的注意力Attention,但是人眼不可能一次性把所有东西都看全面,总会通过一些刻意或不刻意的线索然后通过注意力来接受视野。再比如当你看到这句话的时候,你的注意力在这里,而不是在其它地方。所以在当前计算机算力资源的限制下,注意力机制绝对是提高效率的一种必要手段,将注意力集中到有用的信息上,从而减小在噪声中花费的时间。
同样,当我们读一句话时,大脑也会首先记住重要的词汇,这样就可以把注意力机制应用到自然语言处理任务中,于是人们就通过借助人脑处理信息过载的方式,提出了Attention机制。
03 Attention注意力机制的出现和应用
1.注意力机制最早可以追溯到1998年****。
1998年,一篇名为《A model of saliency-based visual attention for rapid scene analysis》的论文发表,这是早期将注意力机制应用于计算机视觉领域的代表作,作者受早期灵长目视觉系统的神经元结构启发,提出了一种视觉注意力系统,可将多尺度的图像特征组合成单一的显著性图,利用动态神经网络按显著性顺序选择重点区域。
2.在深度学习领域,注意力机制首次被引入是在2014年。
2014年,谷歌DeepMind发表的《Recurrent models of visual attention》使注意力机制受到广泛关注,该论文首次在RNN模型上应用注意力机制进行图像分类。同年,Yoshua Bengio等人在《Neural machine translation by jointly learning to align and translate》中将注意力机制首次应用到自然语言处理(NLP)领域,实现了同步的对齐和翻译,解决了以往神经机器翻译(NMT)领域使用encoder-decoder架构的一个潜在问题。
3.注意力机制在2017年得到了进一步的发展和推广。
2017年,来自谷歌的Ashish Vaswani等人发表了《Attention Is All You Need》论文,提出了Transformer模型,该模型完全基于注意力机制,极大地推动了自然语言处理领域的发展。
04 注意力机制
注意力机制的核心包括三个概念:Q-查询(query)、K-键(key)、V-值(value)。
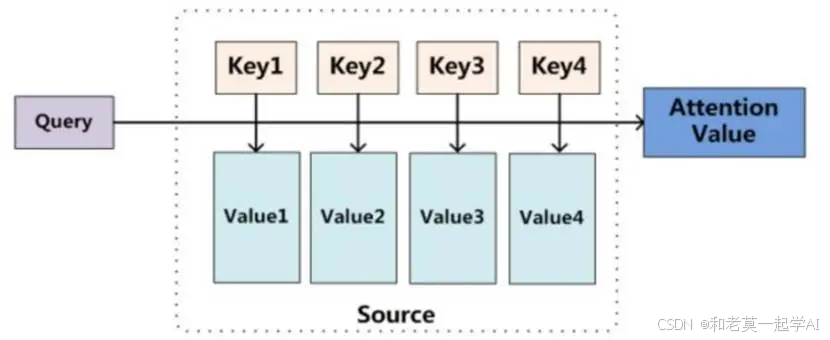
查询(query)是用来在输入序列中查找相关信息的向量,即查询向量。它代表了当前模型对于某一特定输出所需要关注的信息。
键(key)是用于与查询向量进行匹配的向量。每个输入序列的元素都会有一个键向量,表示该元素的特征或信息。
值(Value) 向量是与键(Key)向量对应的,用于生成最终的输出。
从本质上理解,Attention是从大量信息中有筛选出少量重要信息,并聚焦到这些重要信息上,忽略大多不重要的信息。权重越大越聚焦于其对应的Value值上,即权重代表了信息的重要性,而Value是其对应的信息。具体来说,它涉及以下三个关键步骤:
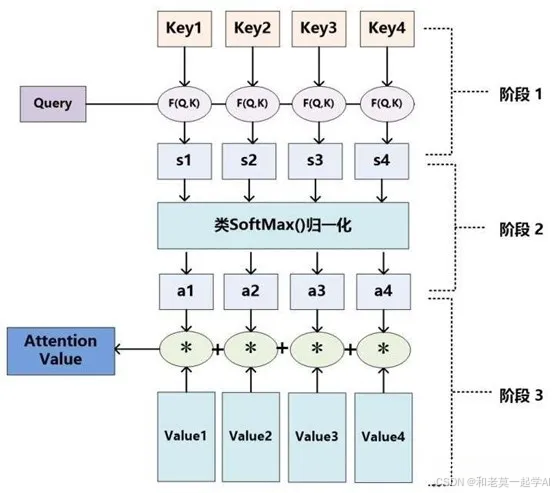
Step1:计算查询(Query)各部分的相关性:
这是注意力机制的第一步,目的是确定输入序列数据中每个部分对于当前任务的重要性。权重的计算通常是基于**查询(Query)**和模型参数某个Key i ,计算两者的相似性或者相关性。最常见的方法包括:点积、余弦相似性或多层感知机(MLP)网络。

Step2:对相关性进行归一化处理得到权重:
引入类似SoftMax的计算方式对第一阶段的得分进行数值转换,主要是进行归一化处理,将原始计算分值整理成所有元素权重之和为1的概率分布。另外,也可以通过SoftMax的内在机制更加突出重要元素的权重。即一般采用如下公式计算:
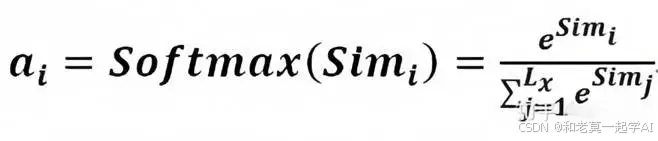
Step3:对Value进行加权求和得到Attention数值:
前两步的计算结果即为Valuei 对应的权重系数,然后进行加权求和即可得到Attention数值:
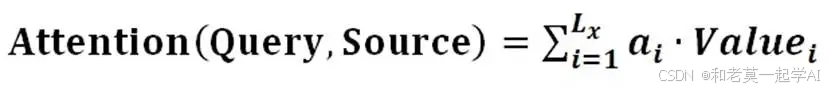
这样,模型就能够根据权重的大小,对输入数据进行有选择的关注。
05 自注意力机制
自注意力机制是注意力机制的变体。注意力机制发生在目标元素(输出)与源元素(输入)之间。而自注意力机制是在输入序列内部元素之间,或者输出序列内部元素之间的相互作用。
注意力机制的一个应用场景是机器翻译,比如中译英模型中,查询(Query)是中文单词的特征,键(Key)是英文单词的特征。而自注意力机制的查询(Query)和键(Key)则来自同一组元素,即查询和键都是中文特征,彼此之间进行注意力计算。这可以用于理解为同一句话中的词元或同一张图像中的不同patch之间的相互作用,理解更加深入。因此,自注意力机制(Self-Attention)也被称为内部注意力机制(Intra-Attention)。
自注意力机制通过计算每个元素与其他所有元素之间的相关性(注意力权重),将输入序列进行加权求和,从而得到新的表示。这种表示不仅包含了序列中所有元素的信息,还能够突出与当前元素关联的重要部分。
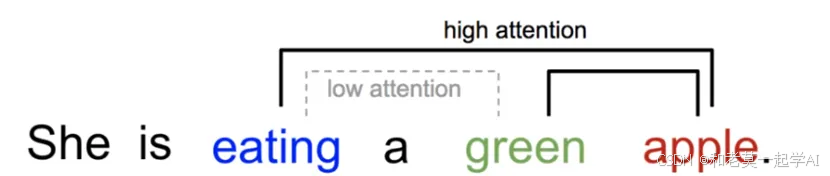
比如我们在理解句子时,当遇到“eating”这个词时,自然会预期下文可能会提到与食物相关的词汇。而句中其他词汇,虽然可能也与食物有关,但它们与“eating”的直接关联性较低,注意力机制能有效捕捉这种重要的关联性。
06 注意力机制的主要优势
注意力机制有力地促进了大模型的发展,其主要优势如下:
1.提升模型的表达能力
通过动态分配权重,注意力机制可以捕捉输入数据中长距离依赖关系以及重要的特征。
2.并行化计算
在Transformer中,自注意力机制被扩展为多头注意力(Multi-Head Attention),即并行计算多个查询、键和值的组合,帮助模型从多个子空间中学习信息。这种方法能够提高模型的表示能力,使其能够同时关注序列中的不同部分。
3.适用范围广泛
注意力机制从自然语言处理扩展到图像处理、语音识别等众多领域,表现出了很强的通用性。可以用于自然语言处理(NLP)领域,尤其是在机器翻译(如 Transformer 模型)、文本生成、问答系统等任务中。也被广泛应用于图像处理领域,如图像描述生成、视觉问答等。
普通人如何抓住AI大模型的风口?
领取方式在文末
为什么要学习大模型?
目前AI大模型的技术岗位与能力培养随着人工智能技术的迅速发展和应用 , 大模型作为其中的重要组成部分 , 正逐渐成为推动人工智能发展的重要引擎 。大模型以其强大的数据处理和模式识别能力, 广泛应用于自然语言处理 、计算机视觉 、 智能推荐等领域 ,为各行各业带来了革命性的改变和机遇 。
目前,开源人工智能大模型已应用于医疗、政务、法律、汽车、娱乐、金融、互联网、教育、制造业、企业服务等多个场景,其中,应用于金融、企业服务、制造业和法律领域的大模型在本次调研中占比超过 30%。

随着AI大模型技术的迅速发展,相关岗位的需求也日益增加。大模型产业链催生了一批高薪新职业:

人工智能大潮已来,不加入就可能被淘汰。如果你是技术人,尤其是互联网从业者,现在就开始学习AI大模型技术,真的是给你的人生一个重要建议!
最后
如果你真的想学习大模型,请不要去网上找那些零零碎碎的教程,真的很难学懂!你可以根据我这个学习路线和系统资料,制定一套学习计划,只要你肯花时间沉下心去学习,它们一定能帮到你!
大模型全套学习资料领取
这里我整理了一份AI大模型入门到进阶全套学习包,包含学习路线+实战案例+视频+书籍PDF+面试题+DeepSeek部署包和技巧,需要的小伙伴文在下方免费领取哦,真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发

部分资料展示
一、 AI大模型学习路线图
整个学习分为7个阶段


二、AI大模型实战案例
涵盖AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,皆可用。



三、视频和书籍PDF合集
从入门到进阶这里都有,跟着老师学习事半功倍。



四、LLM面试题


五、AI产品经理面试题

六、deepseek部署包+技巧大全

😝朋友们如果有需要的话,可以V扫描下方二维码联系领取~


















 2675
2675

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









