






本文将从零开始构建本地知识库,从而辅助 ChatGPT 基于知识库内容生成回答。
核心观点:
- 向量:将人类的语言(文字、图片、视频等)转换为计算机可识别的语言(数组)。
- 向量相似度:计算两个向量之间的相似度,表示两种语言的相似程度。
- 语言大模型的特性:上下文理解、总结和推理。
这三个概念结合起来,就构成了 “向量搜索 + 大模型 = 知识库问答” 的公式。
👉[优快云大礼包🎁:全网最全《LLM大模型入门+进阶学习资源包》免费分享(安全链接,放心点击)]()👈

一、FastGPT 部署
1.介绍
FastGPT 是目前 Prompt 串接做的最好的项目,知识库核心流程图如下:
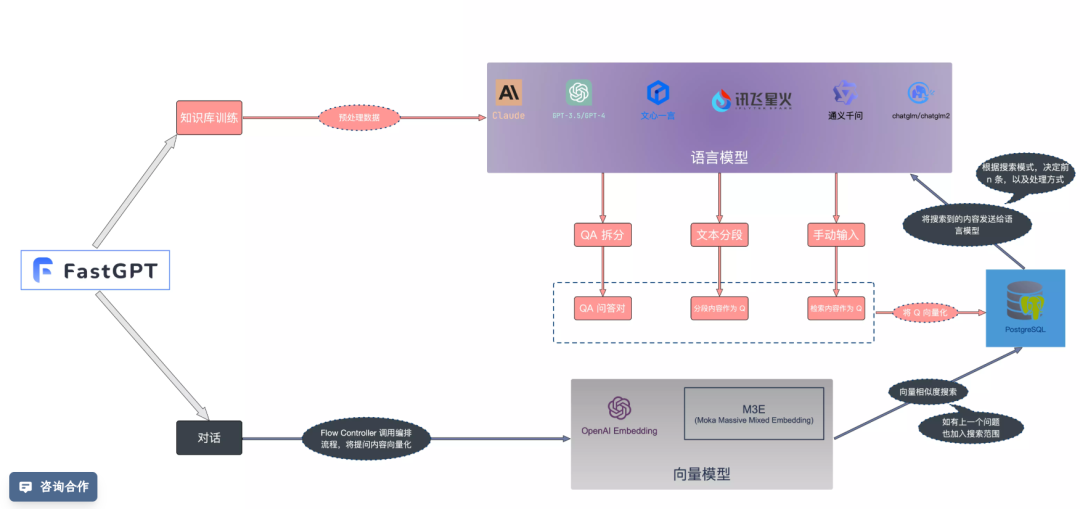
从官方简介也可以看出很牛逼:
FastGPT 是一个基于 LLM 大语言模型的知识库问答系统,提供开箱即用的数据处理、模型调用等能力。同时可以通过 Flow
可视化进行工作流编排,从而实现复杂的问答场景!
2. 安装 Docker
话不多说直接开干,首选需要我们安装 Docker 应用,这里以 Windows 安装为例(其他系统可自行百度解决)。
登录 Docker 官网 双击下载的 Docker for Windows Installer 安装文件,一路 Next,点击 Finish 完成安装。
安装完成后,Docker 会自动启动。通知栏上会出现个小鲸鱼的图标,这表示 Docker 正在运行。
我装的 docker-desktop 自带了 docker-compose,如果未安装可以去 Docker-Compose 官网 下载。
安装 Docker 还是比较简单,如果遇到大家可直接百度解决,网上这类文章很多。
3. 配置文件
先创建一个文件夹
# 创建文件夹
mkdir fastgpt
# 进入文件夹
cd fastgpt
创建 config.json,内容如下:
{
"FeConfig": {
"show_emptyChat": false,
"show_contact": false,
"show_git": false,
"show_doc": true,
"systemTitle": "个人知识库",
"limit": {
"exportLimitMinutes": 0
},
"scripts": []
},
"SystemParams": {
"vectorMaxProcess": 15,
"qaMaxProcess": 15,
"pgIvfflatProbe": 20
},
"ChatModels": [
{
"model": "gpt-3.5-turbo",
"name": "GPT35-4k",
"contextMaxToken": 4000,
"quoteMaxToken": 2000,
"maxTemperature": 1.2,
"price": 0,
"defaultSystem": ""
},
{
"model": "gpt-3.5-turbo-16k",
"name": "GPT35-16k",
"contextMaxToken": 16000,
"quoteMaxToken": 8000,
"maxTemperature": 1.2,
"price": 0,
"defaultSystem": ""
},
{
"model": "gpt-4",
"name": "GPT4-8k",
"contextMaxToken": 8000,
"quoteMaxToken": 4000,
"maxTemperature": 1.2,
"price": 0,
"defaultSystem": ""
}
],
"VectorModels": [
{
"model": "text-embedding-ada-002",
"name": "Embedding-2",
"price": 0,
"defaultToken": 500,
"maxToken": 3000
}
],
"QAModel": {
"model": "gpt-3.5-turbo-16k",
"name": "GPT35-16k",
"maxToken": 16000,
"price": 0
},
"ExtractModel": {
"model": "gpt-3.5-turbo-16k",
"functionCall": true,
"name": "GPT35-16k",
"maxToken": 16000,
"price": 0,
"prompt": ""
},
"CQModel": {
"model": "gpt-3.5-turbo-16k",
"functionCall": true,
"name": "GPT35-16k",
"maxToken": 16000,
"price": 0,
"prompt": ""
},
"QGModel": {
"model": "gpt-3.5-turbo",
"name": "GPT35-4k",
"maxToken": 4000,
"price": 0,
"prompt": "",
"functionCall": false
}
}
再创建 docker-compose.yml 文件,内容如下:
# 非 host 版本, 不使用本机代理
version: '3.3'
services:
pg:
# 使用阿里云的 pgvector 镜像
image: registry.cn-hangzhou.aliyuncs.com/fastgpt/pgvector:v0.4.2
container_name: pg
restart: always
# 生产环境建议不要暴露端口
ports:
- "5432:5432"
networks:
- fastgpt
# 环境变量配置,首次运行生效,修改后需删除持久化数据再重启
environment:
- POSTGRES_USER=username
- POSTGRES_PASSWORD=password
- POSTGRES_DB=fastgpt
# 卷挂载,包括初始化脚本和数据持久化
volumes:
- ./pg/init.sql:/docker-entrypoint-initdb.d/init.sh
- ./pg/data:/var/lib/postgresql/data
mongo:
# 使用阿里云的 mongo 镜像
image: registry.cn-hangzhou.aliyuncs.com/fastgpt/mongo:5.0.18
container_name: mongo
restart: always
# 生产环境建议不要暴露端口
ports:
- "27017:27017"
networks:
- fastgpt
# 环境变量配置,首次运行生效,修改后需删除持久化数据再重启
environment:
- MONGO_INITDB_ROOT_USERNAME=username
- MONGO_INITDB_ROOT_PASSWORD=password
# 卷挂载,包括数据和日志
volumes:
- ./mongo/data:/data/db
- ./mongo/logs:/var/log/mongodb
fastgpt:
container_name: fastgpt
# 使用阿里云的 fastgpt 镜像
image: registry.cn-hangzhou.aliyuncs.com/david_wang/fastgpt:latest
ports:
- "3000:3000"
networks:
- fastgpt
# 确保在 mongo 和 pg 服务启动后再启动 fastgpt
depends_on:
- mongo
- pg
restart: always
# 可配置的环境变量
environment:
- DEFAULT_ROOT_PSW=123456
- OPENAI_BASE_URL=https://api.openai.com/v1
- CHAT_API_KEY=sk-*****
- DB_MAX_LINK=5
- TOKEN_KEY=wenwenai
- ROOT_KEY=wenwenai
- FILE_TOKEN_KEY=filetoken
- MONGODB_URI=mongodb://username:password@mongo:27017/fastgpt?authSource=admin
- PG_URL=postgresql://username:password@pg:5432/fastgpt
# 配置文件的卷挂载
volumes:
- ./config.json:/app/data/config.json
# 定义使用的网络
networks:
fastgpt:
注意修改 docker-compose.yml 中的 CHAT_API_KEY 为你的 OpenAI Key 即可。
4. 启动
执行命令启动本地知识库:
# 在 docker-compose.yml 同级目录下执行
docker-compose pull
docker-compose up -d
执行完成后就可以在浏览器上通过 http://localhost:3000/ 网址来访问个人知识库了。
二、构建知识库
基于上述操作我们已经成功访问到个人知识库页面,接下来带大家创建导入个人数据进行访问。
登录用户名为 root,密码为 docker-compose.yml 环境变量里设置的 DEFAULT_ROOT_PSW。
1. 创建知识库
新建一个知识库,这里将我的个人经历导入,所以取名为知白个人经历。

通过文件将个人经历导入到知识库中。

确认后就开始将当前数据转化为向量数据。

全文大约2300多字,大概3~5分钟就导入完成了。由于文本限制问题,按照固定字数拆分为了8个数据集。

至此,我们的个人知识库已经建好了。我们尝试进行问答,这里的 0.7881 就是向量相似度,相似度越高的越靠前。

2. 使用知识库
创建一个应用来使用知识库。

这里简单设置了一下开场白,选择并绑定对应知识库。

开始对话,效果展示如下:

读者福利:如果大家对大模型感兴趣,这套大模型学习资料一定对你有用
对于0基础小白入门:
如果你是零基础小白,想快速入门大模型是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以根据这些资料规划好学习计划和方向。
包括:大模型学习线路汇总、学习阶段,大模型实战案例,大模型学习视频,人工智能、机器学习、大模型书籍PDF。带你从零基础系统性的学好大模型!
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓

👉AI大模型学习路线汇总👈
大模型学习路线图,整体分为7个大的阶段:(全套教程文末领取哈)

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
👉大模型实战案例👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

👉大模型视频和PDF合集👈
观看零基础学习书籍和视频,看书籍和视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。


👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


















 21万+
21万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}