






前言
一个多月前,全球两大技术顶流,围绕Multi-Agent吵的天翻地覆。
一方是开发 Claude 的 Anthropic,他们认为Multi-Agent更有效。在他们的实验中,多 Agent 协作成功率比单一 Agent 高出 90.2%。
另一方则是推出「Devin」的 Cognition,他们看来:单一 Agent 配合长上下文压缩与精细调度,其实更加稳健、好用、成本低。
表面上看,这是 Multi-Agent 的路线之争,但本质上,这场讨论的核心,其实是:如何管理Agent的上下文?
打个比方, 如果说大语言模型是CPU,那么上下文窗口就是RAM——它是模型的工作内存。
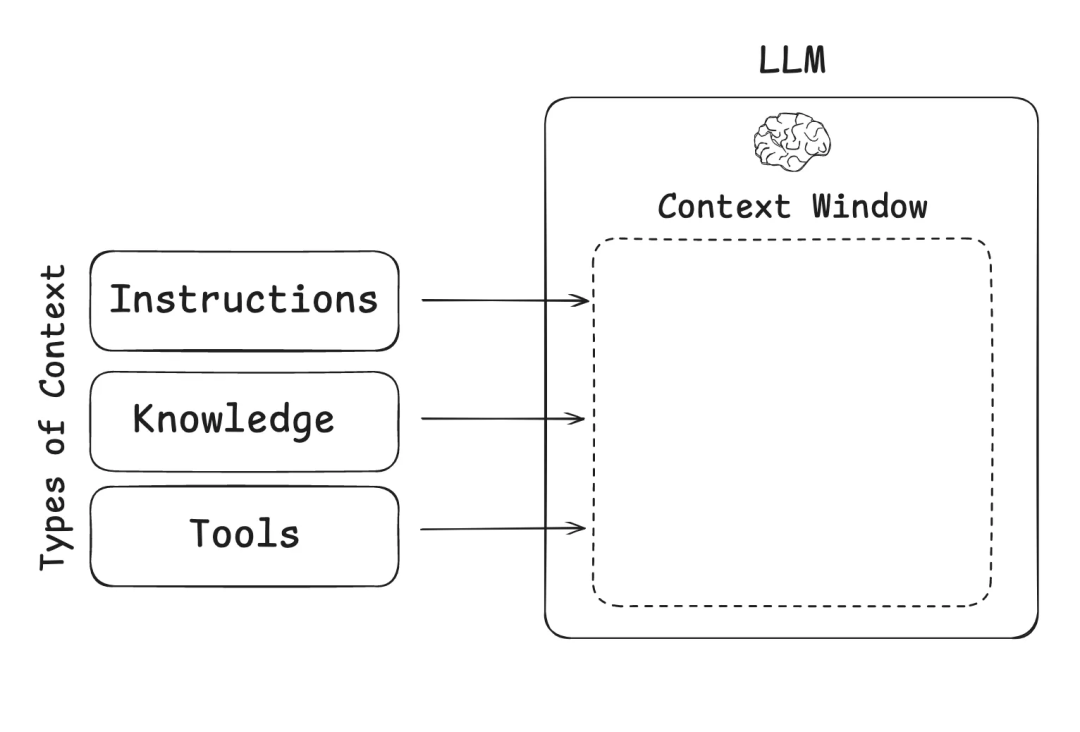
但一个问题是,硬件的**RAM是有限的,模型的上下文长度,也是有限的。**但对于AI智能体,尤其是多智能体这种场景来说,其多步骤、长时间的复杂任务,会产生海量信息,导致AI"消化不良"。这会引发几个致命的问题:
- 信息超载:超出AI的"记忆容量",直接卡死
- 成本飙升:处理信息越多,花钱越多,延迟越高
- 性能下降:信息太杂乱,AI反而变笨了
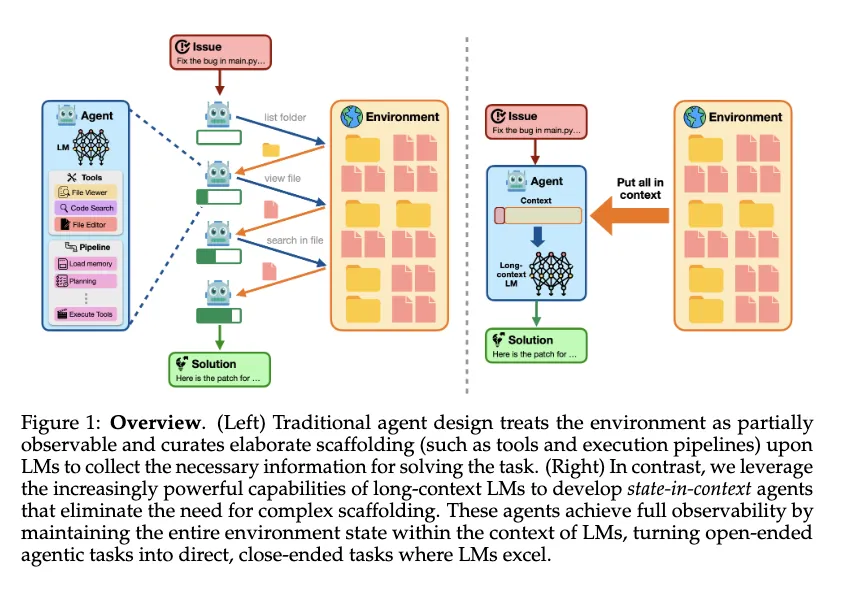
那么如何解决这个问题,Langchain、Lossfunk、manus在内,业内有几个不同的思路,在本文中,我们将为大家一一解读。
01、langchain的Context Engineering的四大策略
langchain看来,agent的上下文管理问题,可以归纳为四种:
-
上下文污染:错误信息混进来,AI开始胡说八道
-
上下文分散:有用信息被垃圾信息淹没
-
上下文混淆:无关信息太多,AI搞不清重点
-
上下文冲突:前后矛盾的信息让AI精神分裂
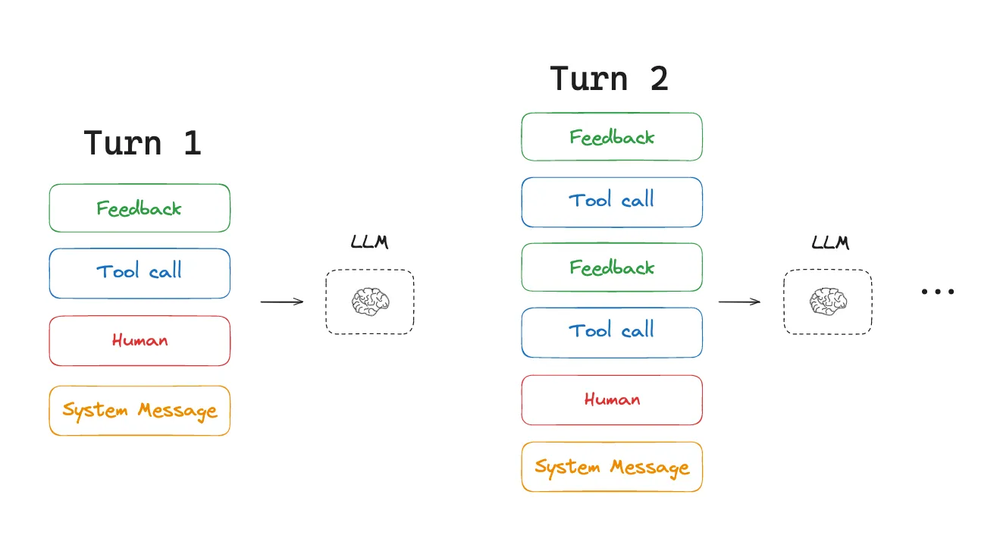
面对这些挑战,Langchain团队深入研究后,提出了Context Engineering的四大核心策略:写入、选择、压缩、隔离。

1.写入上下文:给AI装上"便签纸"
就像我们做复杂工作时会记笔记一样,AI处理复杂任务时也需要把关键信息写下来,避免重复分析。
比如在代码审查中,AI会把每个文件的问题清单和修改建议记录下来,而不是每次都重新扫描整个代码库。这样既省时间又避免遗漏。
2.选择上下文:只看重要的信息
不是所有信息都值得进入AI的视野。Windsurf团队在处理大型代码库时发现,必须结合语法分析、知识图谱检索等技术,才能从成千上万行代码中找出真正相关的片段。这就像在图书馆里精准找到需要的那几本书。

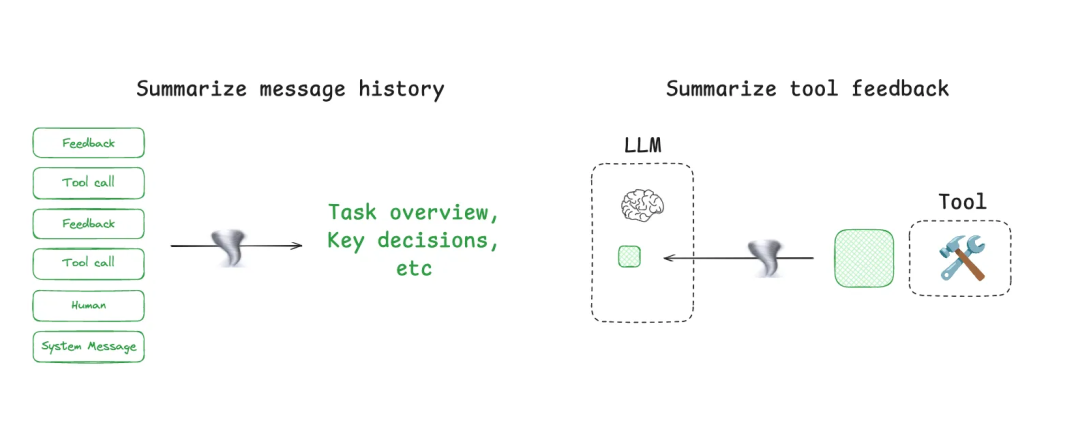
3.压缩上下文:把长故事变成要点
Claude Code的"auto-compact"功能展示了最佳实践:当对话记录快撑爆"内存"时(使用率超过95%),自动把几百轮对话压缩成核心要点。
4.隔离上下文:分工合作,各司其职
LangGraph的多智能体架构把复杂任务拆解成独立模块,每个子任务在专门的"房间"里处理,避免相互干扰。
Anthropic也指出,经过隔离上下文的multi-agent表现会优于单一智能体,因为每个子智能体都会拥有独立的上下文,探索一个问题的不同角度。
就像项目团队中每个成员专注自己的模块,最后整合成完整方案。这样既提高效率,又避免了"一锅粥"的混乱。
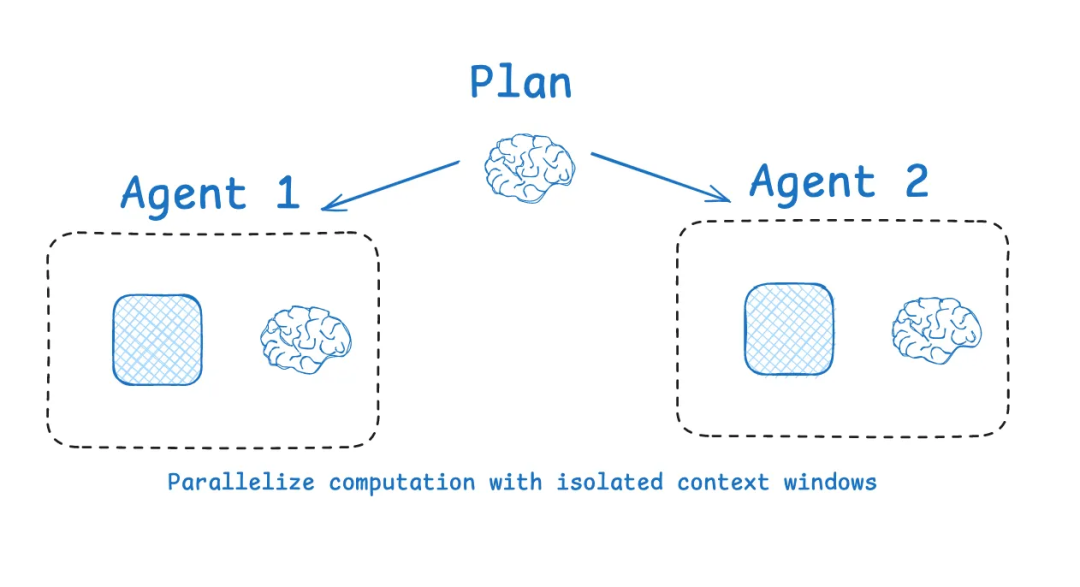
这四种策略相互配合,形成了完整的上下文管理体系。掌握这些方法,能让你的AI系统处理信息更高效、响应更准确。
02 、Lossfunk 的6个上下文管理技巧
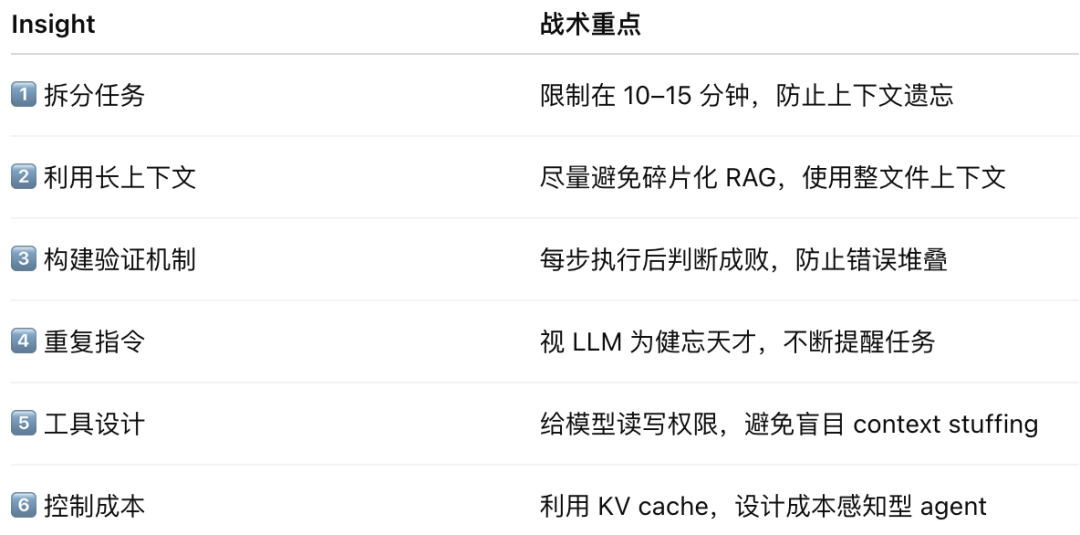
1、将任务拆分为人类可在 10–15 分钟内完成的小块
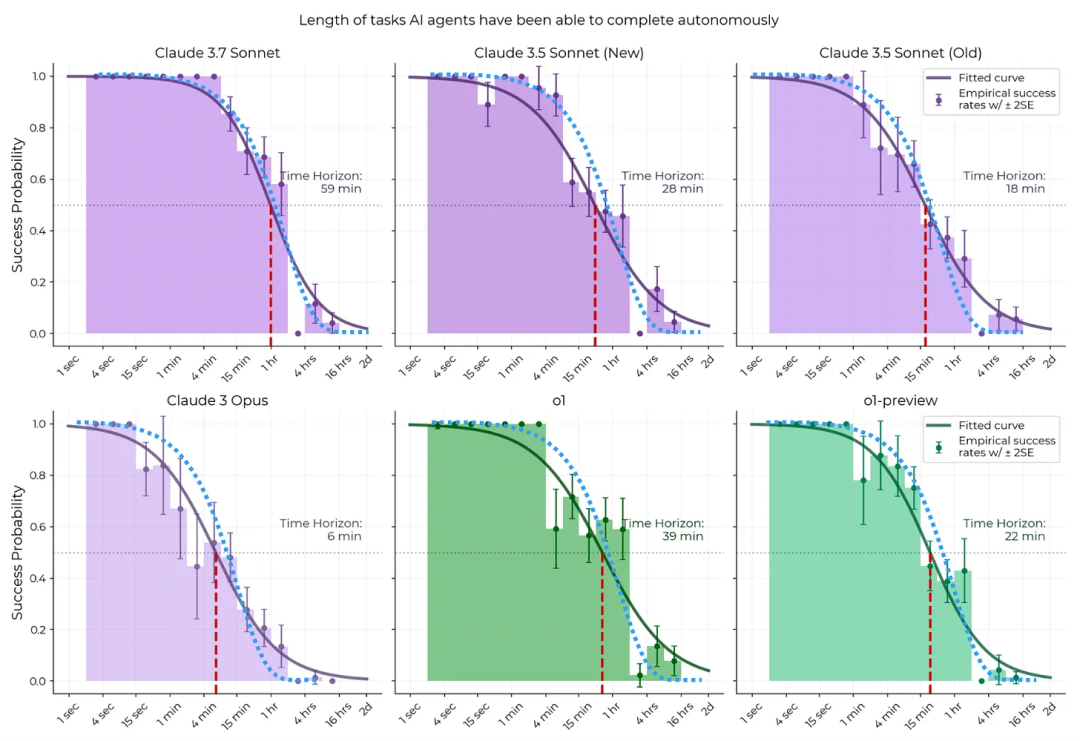
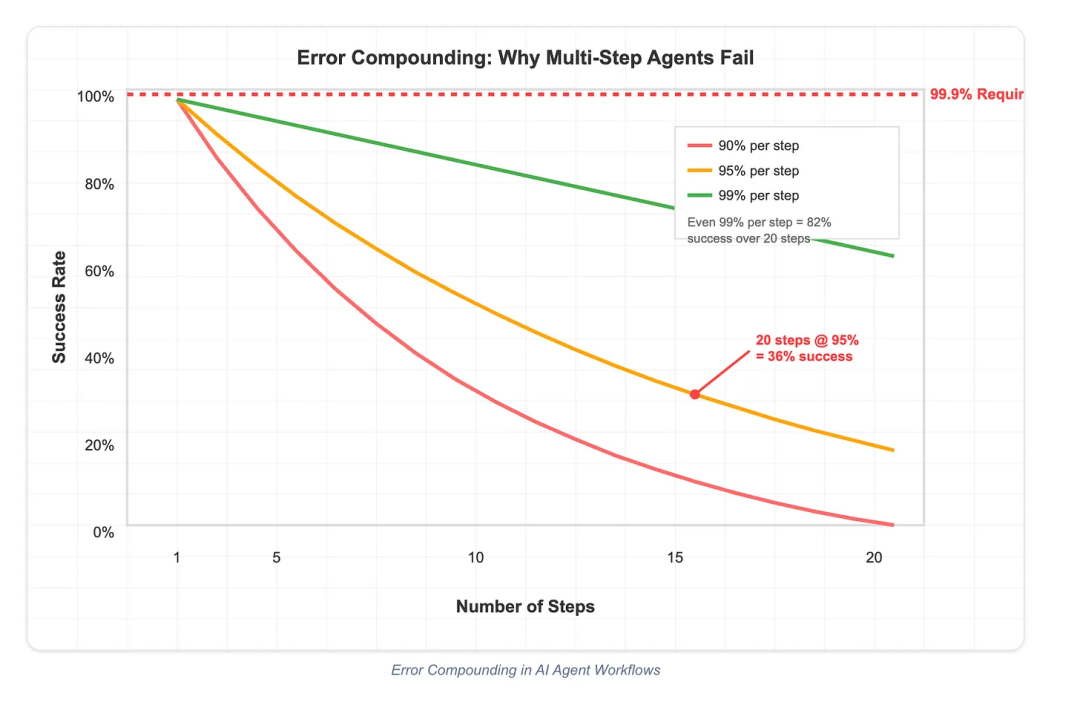
- 核心观点:LLM 成功执行任务的概率与人类完成该任务所需时间强相关。根据 METR 研究,任务耗时越短,LLM 成功率越高(10 分钟任务 ≈ 90% 成功率)。
- 工程建议:不要期望 LLM 能在一个长 session 内完成复杂任务。应该将其拆分为原子化任务,每个子任务能在模型当前上下文内自洽完成。
2、 一体化 Agent + 长上下文胜于多 Agent + RAG
- 观点:如果模型的上下文窗口够大,应尽量将完整文件或数据一次性塞进 context,而不是碎片化检索(RAG),后者的知识是碎片化的。
- 经验引用:Cline 项目和 SWE-bench-Verified benchmark 都证明完整上下文效果更佳。以前使用 diff 模型组合处理更新,误差高达 20%;改用 LLM 生成 REPLACE block,误差降到 5%。
- 隐含逻辑:绕过成本的工程取巧(如快照 diff 模型)往往带来质量牺牲。随着基础模型变强,应少用 workaround,多信任模型原生能力。
3、长流程易失败,务必构建逐步验证机制
-
挑战:任务流程越长,出错概率越大,且错误会层层积累。
-
应对策略:
-
- 将每一步设计为尽可能 无状态的函数调用,减少上下文依赖;
- 每一步任务完成后进行显式验证,模型必须能区分成功与失败,否则会带着错误一路狂奔。
-
目标:降低耦合度、增强可测试性,使每步可观察、可诊断、可回滚。
4、 把 LLM 当失忆天才,持续喂任务和上下文
-
原理:模型容易遗忘早期输入。尤其在长对话中,前面的任务指令可能会被挤出上下文窗口。
-
实践建议:
-
- 不断重复 todo list 或关键任务信息;
- 在 prompt 中显式列出当前步骤、目标和注意事项;
- 引导模型先读文件再执行,有助于自建思路。
-
提示:你不需要一次性把所有上下文硬塞进 prompt,而是让模型通过指令主动拉取信息。
5、 给模型工具权限,让它主动构建自己的上下文
-
新范式:别只往 context 塞内容,而是让模型自己去读写——就像人一样,动手比死记更强。
-
设计重点:
-
- 工具(如读文件、查数据库)需精心构建,避免信息过载或不足;
- 工具调用的返回内容应简洁明确(如:“查询成功,有10k条,这里展示前5条”);
- 出错时,提供恰当量级的信息以便恢复,而非一味输出全量堆栈。
-
总结:工具接口设计是门信息设计的艺术。
6、 多轮对话成本呈二次增长,务必保持上下文不可变
-
事实:每增加一次对话轮次,如果上下文每次都变,LLM 无法命中 KV cache,成本激增。
-
- 50 轮时 ≈ $2.5/response,100 轮时可飙升至 $100/response;
- 如果上下文不变,命中 KV cache 成本可下降到 1/10。
-
工程对策:
-
- 只追加上下文,不要替换;
- 设计结构化 memory 和状态保存策略,以节省 token;
- 明确你的 agent 是否值得花这么多钱运行(用户真的愿意为它花钱吗?)。
03 Manus的七个agent小技巧
Manus 不久前正式公开了其产品逻辑,以及踩坑经验,并且给出了七大context 工程设计原则:

1️⃣ 设计围绕 KV-Cache 展开:缓存命中率是王道
-
核心观点:生产级 agent 的最关键指标就是 KV-cache 命中率,直接影响成本与响应时间(TTFT)。
-
原因:Agent 的输入越来越长(大量上下文与工具调用记录),但输出短(如函数调用),prefill 成本极高。
-
优化策略:
-
- 保持 prompt prefix 稳定,避免加入每秒变动的时间戳等干扰缓存;
- 上下文追加而非修改,JSON 序列化时使用确定性顺序;
- 明确打上缓存断点标记,在某些模型框架中需手动设置。
2️⃣ 工具动态加载容易毁掉 Agent,应该使用 “屏蔽” 而非 “删除”
-
问题:随着工具越来越多(甚至用户自定义数百个),模型选择工具时更容易出错或卡住。
-
教训:
-
- 动态插入/移除工具会使 KV-cache 失效,并引发引用未定义工具的问题;
-
解决方案:
-
- 不删除,只屏蔽:使用 token masking 技术动态调整可调用工具集;
- 工具命名应有统一前缀(如
browser_),便于分组与限制; - 使用 Hermes 格式或 API 支持的 function-calling prefill 来控制选择空间。
3️⃣ 文件系统是无损上下文的最佳外部内存
-
挑战:128K 上下文看似足够,但遇到大网页、PDF 等非结构数据时依然吃紧;
-
常规压缩问题:过早丢弃信息容易导致未来步骤丧失上下文;
-
Manus 的方法:
-
- 让 agent 使用文件系统读写,把数据外部化;
- 删除网页内容但保留 URL,清除文档但保留路径,确保信息可恢复;
- 实现类似“长期记忆”系统,也为未来用更轻量架构(如 SSM)打下基础。
4️⃣ 利用 Recitation 操控注意力,保持任务对齐
-
机制:Manus 会不断更新
todo.md,将未完成目标“复述”到上下文尾部; -
好处:
-
- 避免“lost-in-the-middle”问题;
- 提升模型在长流程中保持目标一致性的能力;
-
总结:通过自然语言“自我提醒”是目前最有效的 attention 操控方式之一。
5️⃣ 不要隐藏错误,保留失败痕迹让模型自我修正
-
错误是常态:语言模型总会有 hallucination、环境崩溃、调用失败等问题;
-
通病:很多系统习惯清除失败痕迹、重试或 reset;
-
正确做法:保留失败记录,包括栈追踪或观察结果;
-
- 这有助于模型调整 belief,避免重复同样错误;
-
结论:错误恢复能力是 agent 智能的真正表现。
6️⃣ 别被 few-shot 绑架,打破模式有助提升表现
-
问题:模型会“模仿”上下文模式;
-
- 如果你放了太多重复的 few-shot 示例,它就会陷入固定思路;
-
案例:当 Manus 批量评审简历时,模型会机械重复行为;
-
解决策略:
-
- 在 action-observation 模板中加入轻微变化(格式、顺序、措辞);
- 引入结构化噪声,打破固定模式;
-
总结:保持上下文多样性,避免 agent 变得脆弱僵化。
7️⃣ Context Engineering 胜于 Fine-Tuning,灵活快、省钱多
-
历史经验:manus早年使用 BERT 等模型需数周迭代 fine-tune,如今这种方式效率低、成本高;
-
Manus 的选择:坚定押注“context engineering”而非 end-to-end 训练;
-
收益:
-
- 产品更新周期从数周缩短为数小时;
- 模型更新可以无缝接入,无需重新适配或训练;
- 让产品变成可以灵活移动的“船”,而非“钉死在海底的柱子”。
04 几个Context Engineering神器推荐
在这里,我们有几个神器推荐
1.上下文不够怎么办?用Milvus向量数据库
在实际应用中,面对海量外部知识、历史对话和多模态数据,如何高效存储、检索和动态调用上下文,是AI-Agent的核心挑战之一。
以向量数据库为例,像Milvus这类高性能数据库能够支持文本、图片等多模态数据的向量化存储和高效检索,帮助AI-Agent实时获取最相关的知识片段和历史信息。通过与LangChain、LlamaIndex等主流AI-Agent框架集成,可以实现RAG(检索增强生成)系统,提升智能体的知识获取和推理能力。
简单SDK调用流程:开发者可通过Milvus的Python SDK快速实现上下文的存储与检索闭环,降低技术门槛。
from pymilvus import MilvusClient# 创建本地Milvus实例client = MilvusClient("demo.db")# 创建向量集合client.create_collection(collection_name="knowledge_base", dimension=768)# 向知识库批量插入向量化数据client.insert(collection_name="knowledge_base", data=embedding_vectors)# 检索最相关的上下文信息query_vector = embedding_fn.encode_queries(["什么是Context Engineering?"])results = client.search( collection_name="knowledge_base", data=query_vector, limit=3, output_fields=["text", "source"])
2.Context Engineering的工具选型推荐
2.1 TRAE SOLO 模式
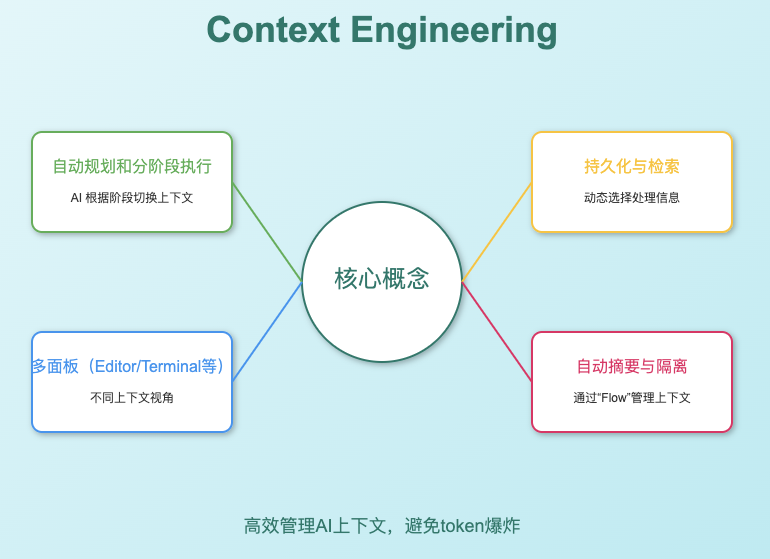
就在前几天TRAE推出了2.0版本新增了SOLO模式,该模式本质是一个高度自动化的 AI 开发 agent,它会根据用户输入(自然语言、语音、文件等)自动拆解需求、生成代码、测试、预览和部署。其 context engineering 体现在:
2.2Kiro 的 spec 专家模式
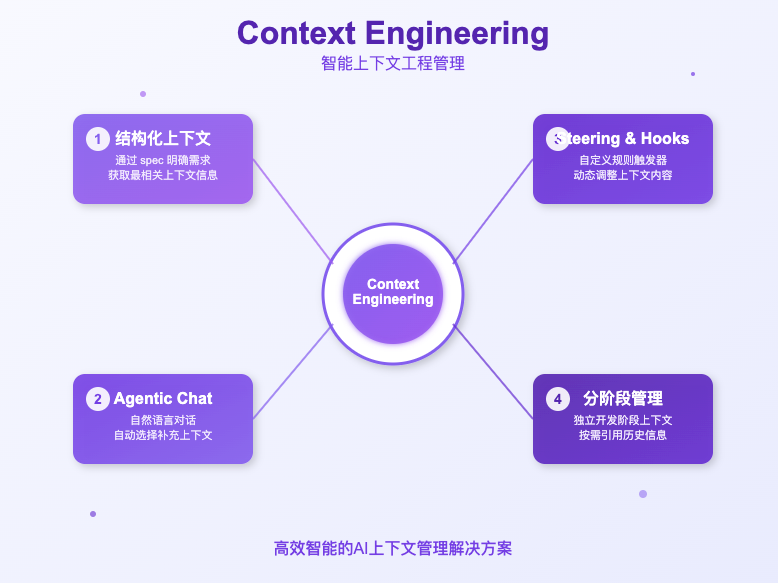
最近AWS推出爆火的IDE工具Kiro。其中有一个spec 专家模式,强调用结构化规范(spec)来规划和驱动开发流程,其 context engineering 体现在:
无论是 TRAE 的 SOLO 还是 Kiro 的 spec 专家模式,本质上都在通过工程化手段管理 AI/Agent 的上下文,以提升智能体的任务完成能力和效率。这正是 context engineering 的核心思想。
结语
随着AI模型能力提升,Context Engineering的重要性愈发突出。
在这里,有一点经验可以分享:
对于上下文依赖弱、信息集中明确的任务,例如事实查询或简单问答,最有效的策略是“选择 + 压缩”。无需大量写入和记录历史内容,系统就可以迅速从现有数据中筛选相关内容并进行压缩提炼,以实现快速响应和低成本运行。这种策略广泛应用于智能客服、搜索问答等场景中,强调速度优先和资源节省。
而对于长期且具有线性结构的任务,如代码开发或文档撰写,则需要采用“写入 + 选择 + 压缩”的组合策略。这类任务要求系统能够逐步积累内容,保持上下文的连贯性,同时不断对内容进行选择性提取和压缩,以避免信息冗余并确保文档质量。此策略特别适合多轮编辑、协同创作等场景,强调信息积累与组织能力的协同优化。
面对复杂且需要并行处理的任务,例如研究分析或数据处理,最佳实践是引入“隔离 + 写入 + 选择”的策略组合。这类任务通常包含多个并行子任务或分析维度,若直接写入可能导致上下文混乱,因此需通过“隔离”机制将不同任务空间划分清晰,再辅以写入和选择策略对结果进行整合。此组合能显著提升处理量和效率,同时避免信息污染。
最后,在创意探索类任务中,如创意设计或头脑风暴,推荐使用“写入 + 选择”的策略。这类任务强调自由生成、思维发散和灵活性,因此不宜在初期过度压缩内容。系统应尽可能保留多样化的想法,并在后续阶段通过选择机制筛选出有价值的思路。这一策略鼓励创新,适用于设计工作坊、品牌构思等需要灵感迸发的环境。
最后
为什么要学AI大模型
当下,⼈⼯智能市场迎来了爆发期,并逐渐进⼊以⼈⼯通⽤智能(AGI)为主导的新时代。企业纷纷官宣“ AI+ ”战略,为新兴技术⼈才创造丰富的就业机会,⼈才缺⼝将达 400 万!
DeepSeek问世以来,生成式AI和大模型技术爆发式增长,让很多岗位重新成了炙手可热的新星,岗位薪资远超很多后端岗位,在程序员中稳居前列。

与此同时AI与各行各业深度融合,飞速发展,成为炙手可热的新风口,企业非常需要了解AI、懂AI、会用AI的员工,纷纷开出高薪招聘AI大模型相关岗位。

最近很多程序员朋友都已经学习或者准备学习 AI 大模型,后台也经常会有小伙伴咨询学习路线和学习资料,我特别拜托北京清华大学学士和美国加州理工学院博士学位的鲁为民老师给大家这里给大家准备了一份涵盖了AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频 全系列的学习资料,这些学习资料不仅深入浅出,而且非常实用,让大家系统而高效地掌握AI大模型的各个知识点。
这份完整版的大模型 AI 学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】
AI大模型系统学习路线
在面对AI大模型开发领域的复杂与深入,精准学习显得尤为重要。一份系统的技术路线图,不仅能够帮助开发者清晰地了解从入门到精通所需掌握的知识点,还能提供一条高效、有序的学习路径。

但知道是一回事,做又是另一回事,初学者最常遇到的问题主要是理论知识缺乏、资源和工具的限制、模型理解和调试的复杂性,在这基础上,找到高质量的学习资源,不浪费时间、不走弯路,又是重中之重。
AI大模型入门到实战的视频教程+项目包
看视频学习是一种高效、直观、灵活且富有吸引力的学习方式,可以更直观地展示过程,能有效提升学习兴趣和理解力,是现在获取知识的重要途径

光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

海量AI大模型必读的经典书籍(PDF)
阅读AI大模型经典书籍可以帮助读者提高技术水平,开拓视野,掌握核心技术,提高解决问题的能力,同时也可以借鉴他人的经验。对于想要深入学习AI大模型开发的读者来说,阅读经典书籍是非常有必要的。

600+AI大模型报告(实时更新)
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

AI大模型面试真题+答案解析
我们学习AI大模型必然是想找到高薪的工作,下面这些面试题都是总结当前最新、最热、最高频的面试题,并且每道题都有详细的答案,面试前刷完这套面试题资料,小小offer,不在话下


这份完整版的大模型 AI 学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









