






AI 私有化部署的时代已来
在数据隐私日益重要的今天,企业及开发者对本地化AI解决方案的需求激增。本文将手把手教你如何通过开源工具AnythingLLM与Ollama,无需云端依赖、完全免费地搭建基于DeepSeek大模型的本地知识库系统,实现数据100%自主掌控的智能化升级。
一、为什么选择本地化AI知识库?
- 数据零泄漏风险:敏感信息完全离线处理
- 响应速度提升:本地计算无需网络延迟
- 定制化自由:支持任意垂直领域知识训练
- 长期成本优化:避免云服务持续付费
二、工具准备清单
- AnythingLLM:开源企业级LLM应用框架(https://anythingllm.com/)
- 支持多模态文档处理(PDF/Word/网页等)
- 可视化知识库管理界面
- 本地向量数据库集成
- Ollama:本地大模型运行神器(https://ollama.com/)
- 一键部署各类开源大模型
- 支持 CPU/GPU 混合计算
- 模型版本管理功能
- DeepSeek模型:
- 推荐下载 8B/14B参数的量化版本,工作环境使用建议 14B 以上
- 可通过 HuggingFace 或官方渠道获取
- 硬件:推荐英伟达3060 12G显卡和16G内存以上,可部署 14B 以上模型
三、两步搭建实战指南
- Ollama 本地化部署 DeepSeek R1
- 下载并安装 Ollama 应用到本地电脑

- 下载 Deepseek 模型,推荐 8B/14B 以上量化模型
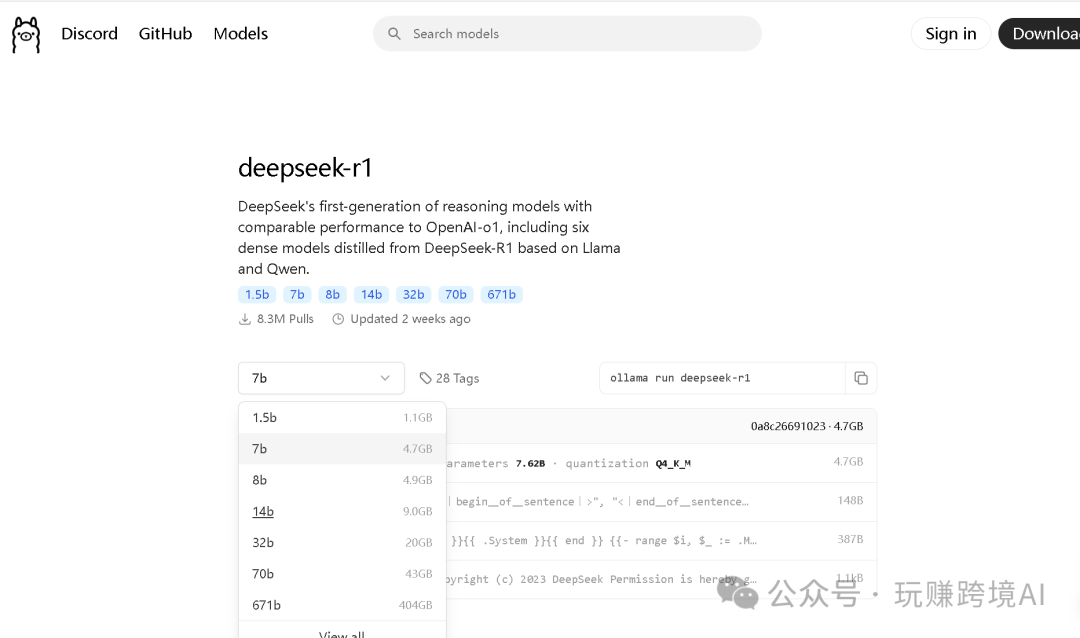
安装:windows环境下,win + R 输入 cmd 打开命令行对话框,输入 ollama run deepseek-r1:14b,即可下载模型到本地电脑,下载完成后,运行 Ollama即可(Ollama没有前端,可以在电脑的右下角看到Ollama图标)

其他命令参考:
介绍几个Ollama常用的命令:
-
列出本地可用的模型列表:ollama list
-
启动模型:ollama run model_name
-
查看模型信息:ollama show model_name
-
删除指定模型:ollama rm model_name
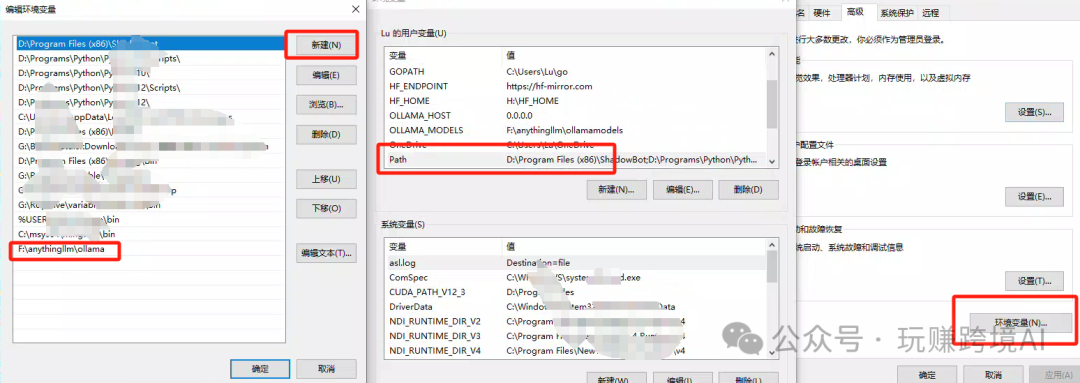
- 由于Ollama默认安装在C盘,可以参考以下方式,迁移到其他盘
1)打开环境变量:“我的电脑”(邮件)- “属性” – “高级系统设置” – “环境变量”
2)修改 Ollama 路径,打开 Path,添加新路径,例如:F:\anythingllm\ollama,保存,然后将 C盘 Ollama 整个文件夹下的所有文件剪切到这里
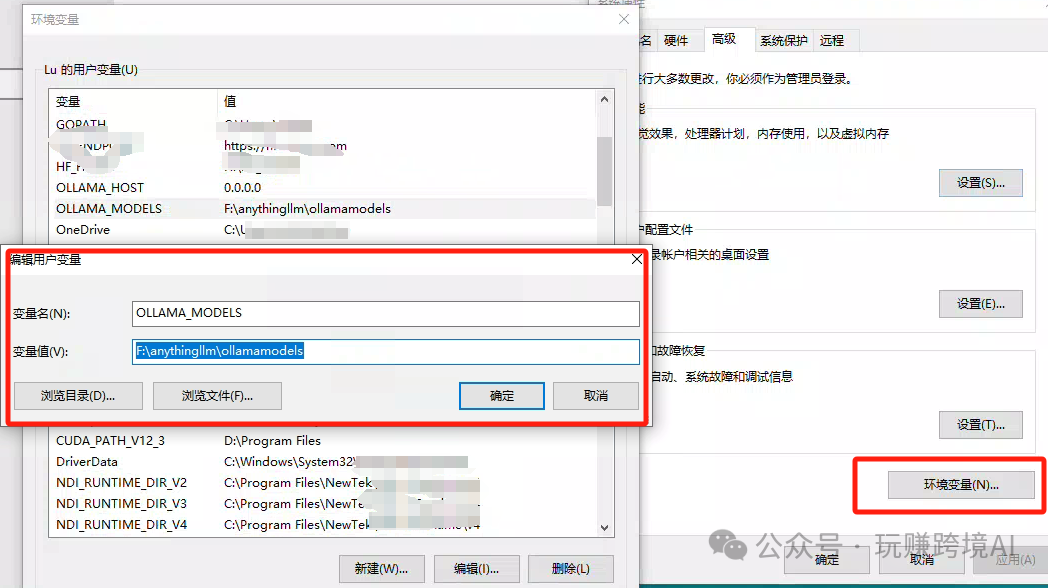
3)修改 Ollama 模型环境变量
将刚安装并且剪切到其他盘的模型文件夹设置为新的环境
- 部署 AnythingLLM
打开官网地址:https://anythingllm.com/desktop,根据自己的系统选择下载的版本。
默认路径安装,或者修改默认安装路径都可以。
安装完成后,运行客户端
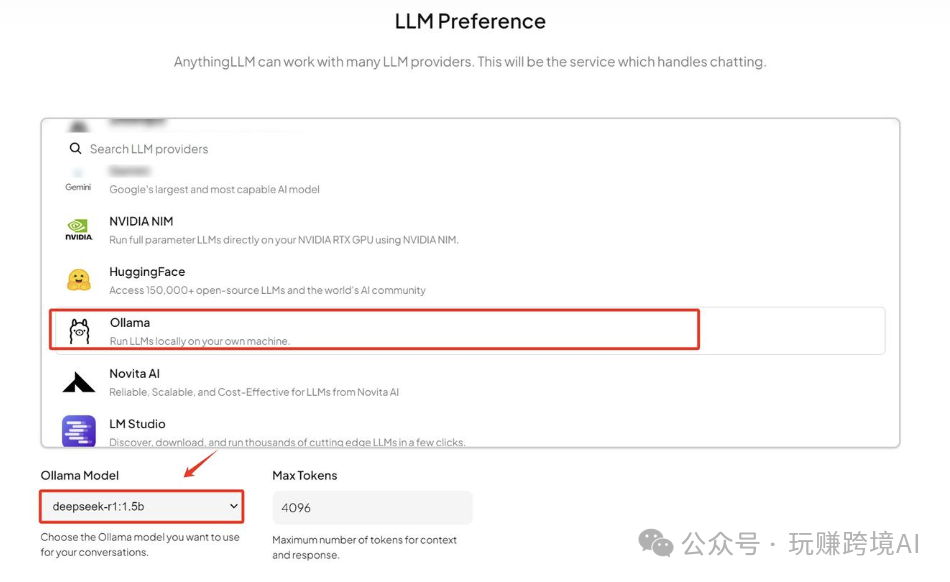
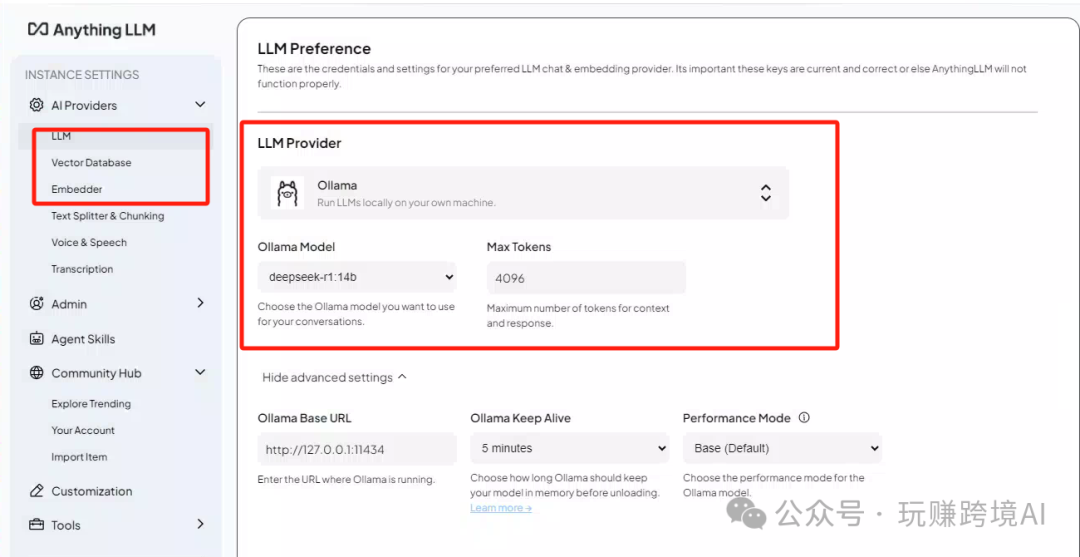
- 设置模型
选择Ollama,并选择模型,下图示为1.5b模型,可在此选择上面下载的 14b 模型
- 要使用本地知识库,还需要设置 Embedding 模型和向量数据库
正常路径是,点击左下角的设置icon,打开下图所示界面,还可以在下方 的 Customization 中将语言更改为中文。
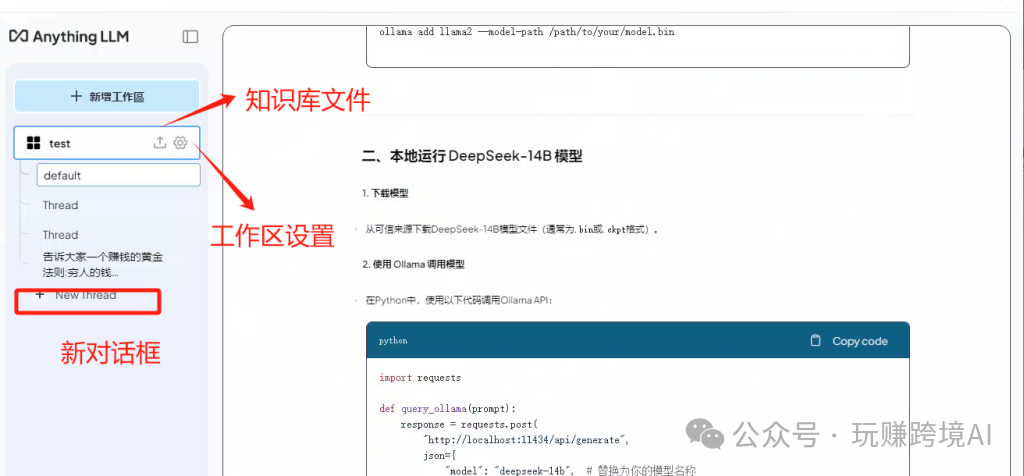
- 创建工作区,填写工作区名称,就可以对话了。
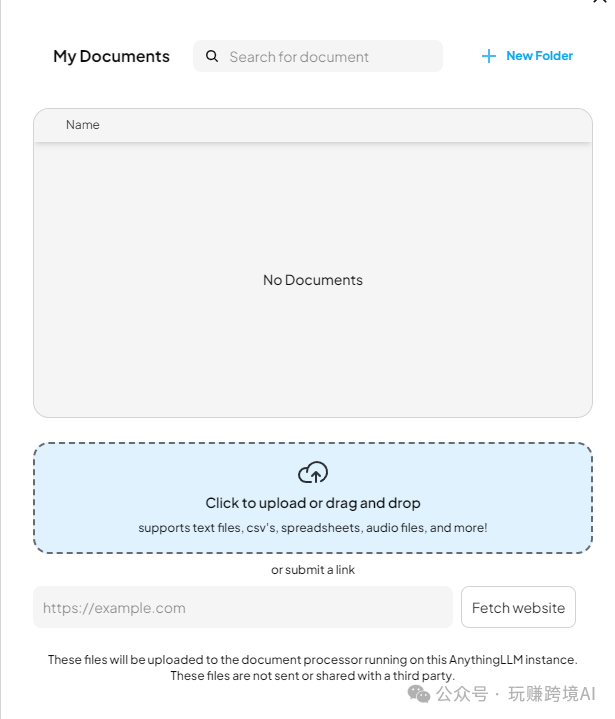
添加知识库文件。
- DeepSeek R1 API 接入LLM
如果本地硬件条件有限,想使用DeepSeek官网服务怎么办?
AnythingLLM 也支持直接调用DeepSeek官方提供的API接口。
点击“工作区设置”,选择聊天设置,可以更改LLM模型。
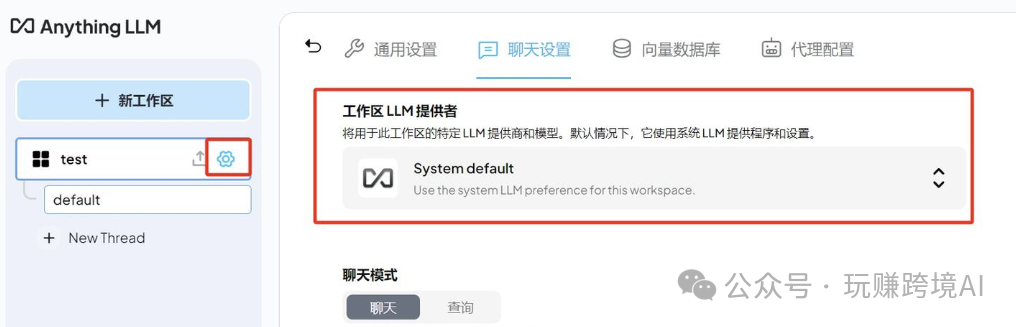
选择DeepSeek,输入API Key,选择DeepSeek R1模型,输入DeepSeek API Key,选择DeepSeek R1模型就可以了。
四、Anythingllm 联网搜索
AnythingLLM 本地模型,默认是不联网的,如需将本地模型联网,可以进行以下操作。
1、启用 Web Search
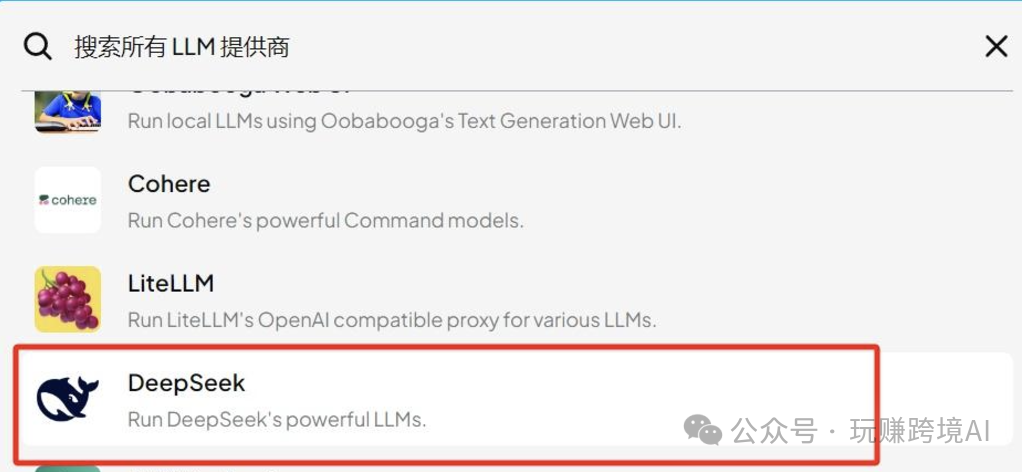
-
打开设置:在 AnythingLLM 的设置界面中,找到“代理技能”选项。
-
启用 Web Search:在代理技能列表中找到 Web Search,点击开启。
-
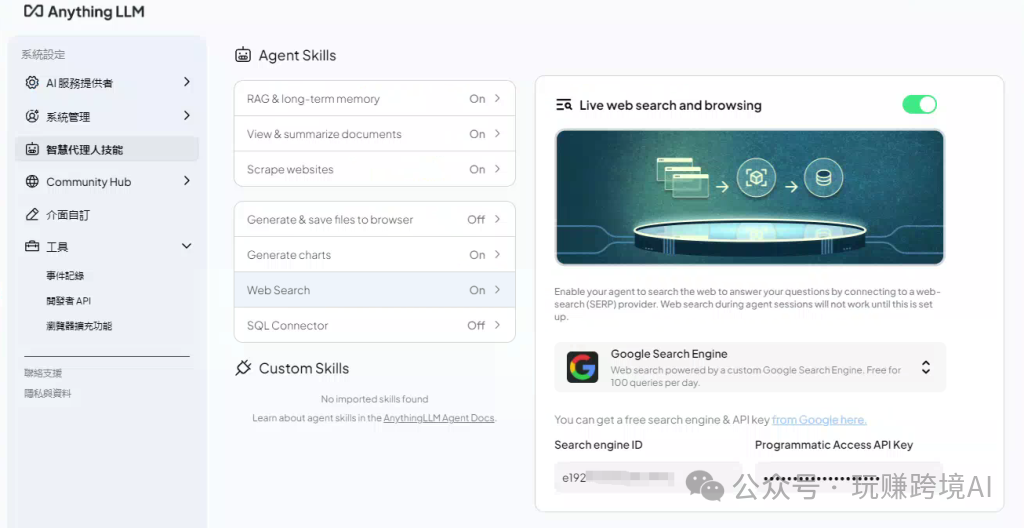
选择搜索引擎:选择一个搜索引擎。如果你只是想尝试一下,建议选择 DuckDuckGo,因为它无需任何配置即可直接使用。如果选择 Goolge search engine,则需要在google search 控制台申请 API Key。(注意: 无论是 DuckDuckGo 还是 Google Search Engine,都需要科上网才能正常使用。)
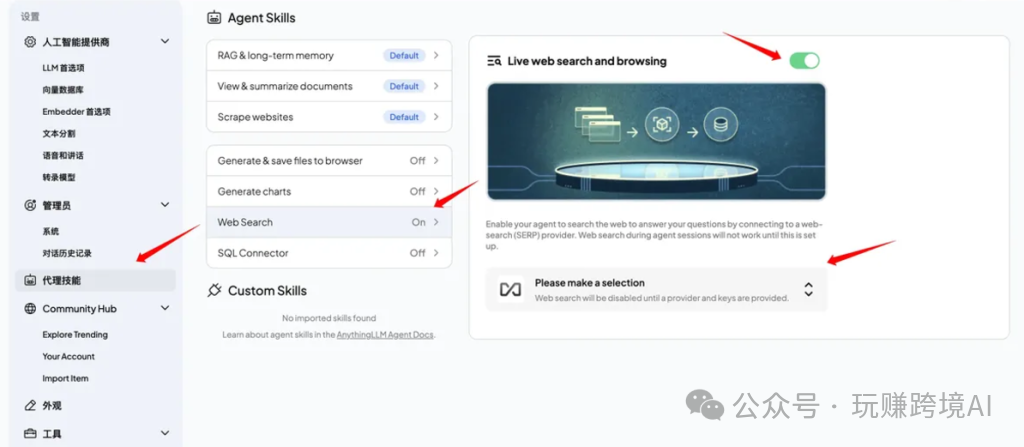
- 申请 Google Search API Key
- 访问 Google Search 控制台:前往 Google Search 控制台 创建一个新的搜索引擎 (https://programmablesearchengine.google.com/controlpanel/create)。
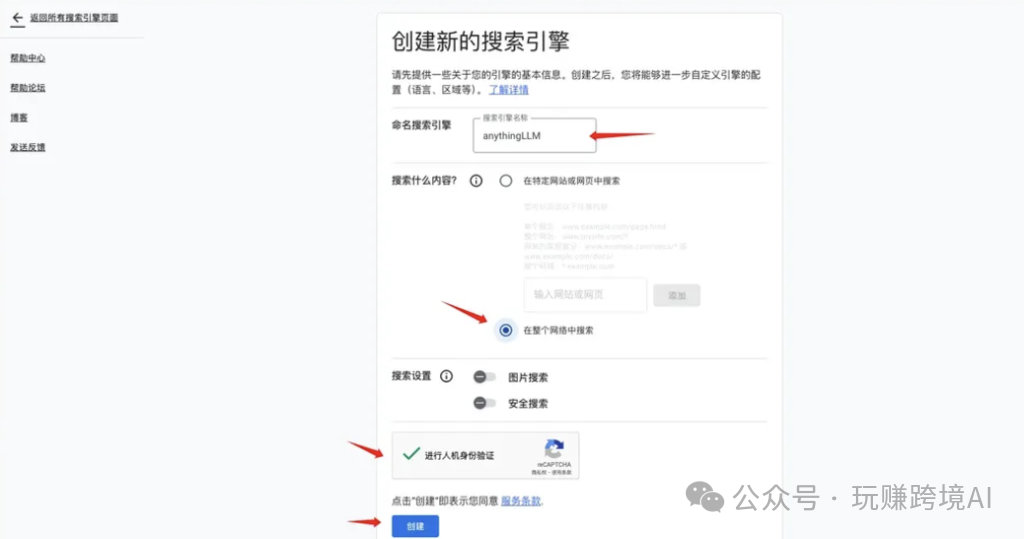
- 自定义搜索引擎:创建完成后,点击“自定义”按钮,进入配置页面。
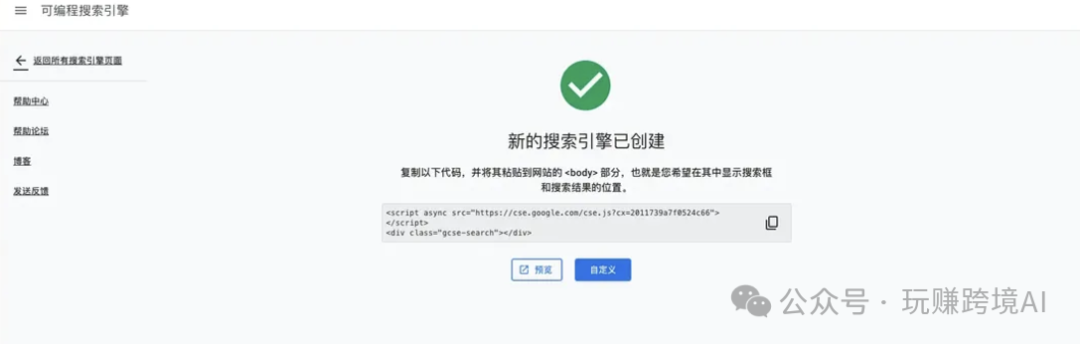
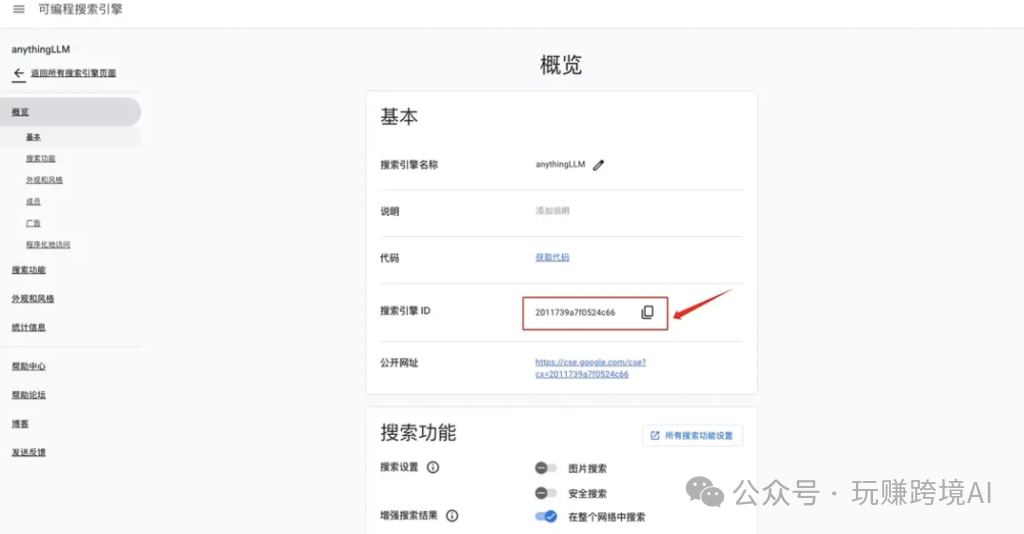
- 获取搜索引擎 ID:在配置页面中,找到搜索引擎 ID,并记录下来。这个 ID 在后续配置 AnythingLLM 时会用到。
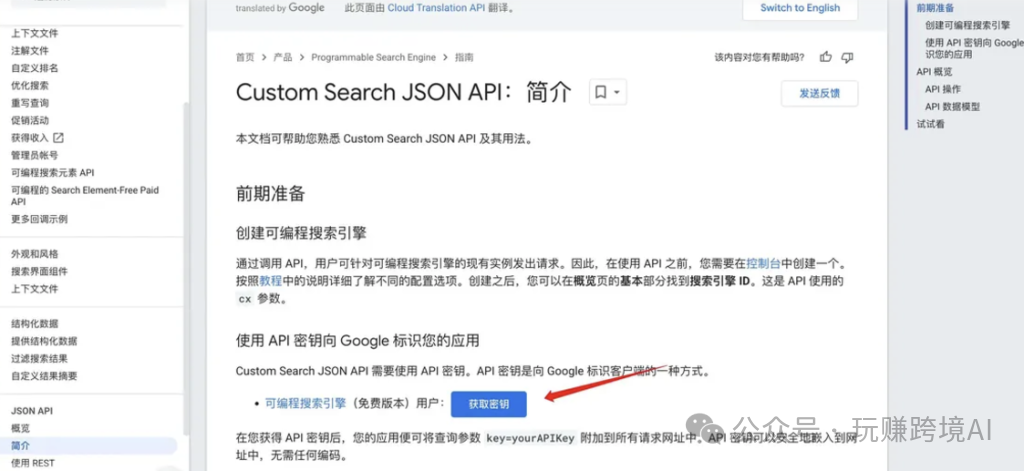
- 获取 API Key:在页面底部,点击“开始使用”按钮,然后点击“获取密钥”按钮。
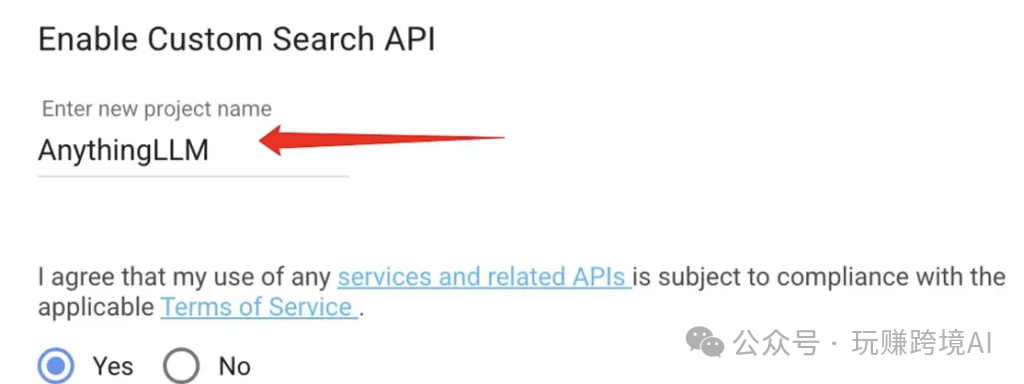
- 创建 API Key:自定义一个项目名称,勾选“Yes”,然后点击“下一步”。
- 复制 API Key:创建成功后,复制生成的 API Key。
- 配置 Google Search Engine
-
回到 AnythingLLM:在 AnythingLLM 的设置界面中,将搜索引擎修改为 Google Search Engine。
-
输入配置信息:在相应的输入框中,填入之前获取的 Search Engine ID 和 API Key,然后点击保存。
- 测试搜索功能:回到聊天界面,通过 @agent + 提示词 的方式启用搜索功能。
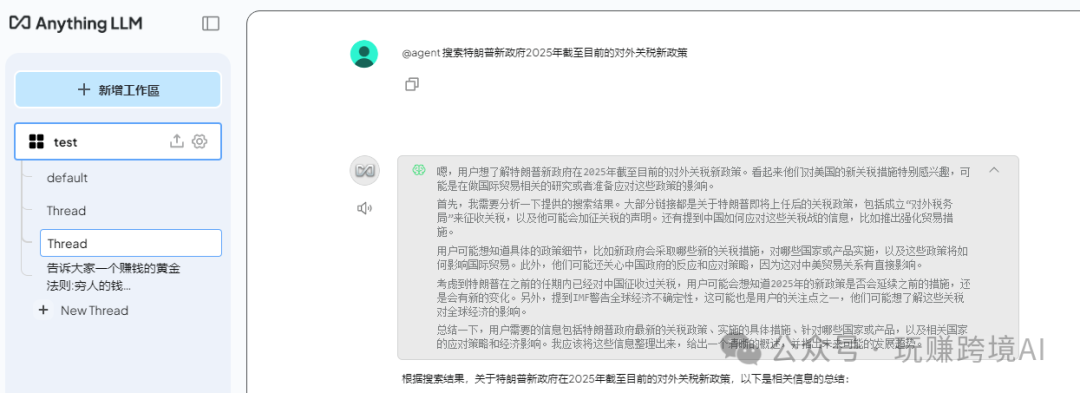
以上,Ollama 部署本地大模型,Anythingllm 构建本地知识库,实现电脑端大模型知识库。
最后的最后
感谢你们的阅读和喜欢,作为一位在一线互联网行业奋斗多年的老兵,我深知在这个瞬息万变的技术领域中,持续学习和进步的重要性。
为了帮助更多热爱技术、渴望成长的朋友,我特别整理了一份涵盖大模型领域的宝贵资料集。
这些资料不仅是我多年积累的心血结晶,也是我在行业一线实战经验的总结。
这些学习资料不仅深入浅出,而且非常实用,让大家系统而高效地掌握AI大模型的各个知识点。如果你愿意花时间沉下心来学习,相信它们一定能为你提供实质性的帮助。
这份完整版的大模型 AI 学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】
大模型知识脑图
为了成为更好的 AI大模型 开发者,这里为大家提供了总的路线图。它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

经典书籍阅读
阅读AI大模型经典书籍可以帮助读者提高技术水平,开拓视野,掌握核心技术,提高解决问题的能力,同时也可以借鉴他人的经验。对于想要深入学习AI大模型开发的读者来说,阅读经典书籍是非常有必要的。

实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

面试资料
我们学习AI大模型必然是想找到高薪的工作,下面这些面试题都是总结当前最新、最热、最高频的面试题,并且每道题都有详细的答案,面试前刷完这套面试题资料,小小offer,不在话下

640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

这份完整版的大模型 AI 学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】

















 1417
1417

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









