






前言
其核心思想是使用注意力机制来处理输入序列中的每个元素与其他元素之间的关系,从而捕捉全局的依赖关系。
Transformer 中的注意力机制有几种形式,包括自注意力机制、多头自注意力机制、掩蔽自注意力机制和交叉(编码器-解码器)自注意力机制。
自注意力机制
自注意力机制是 Transformer 中的关键机制,它通过计算输入序列中每个元素与其他元素的相关性,来捕捉序列中的全局依赖关系。
其基本原理是让每个输入元素(Token)与整个序列的所有其他元素进行交互,计算其对整个序列的注意力权重,并根据这些权重来生成新的表示。
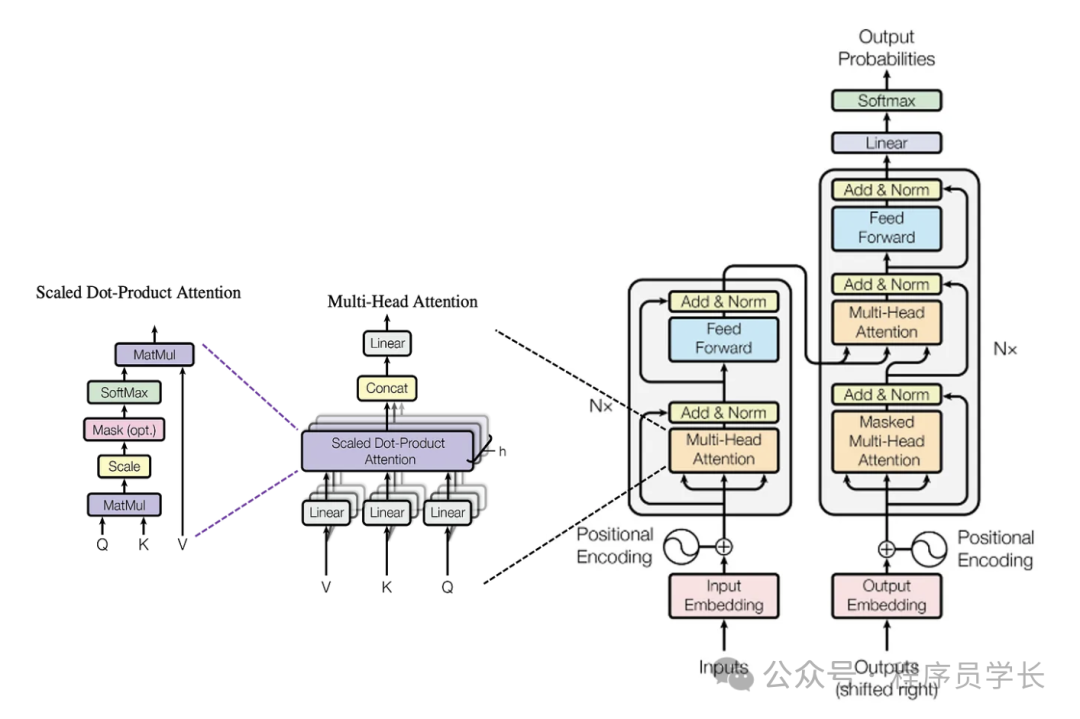
计算步骤如下所示
-
线性变换
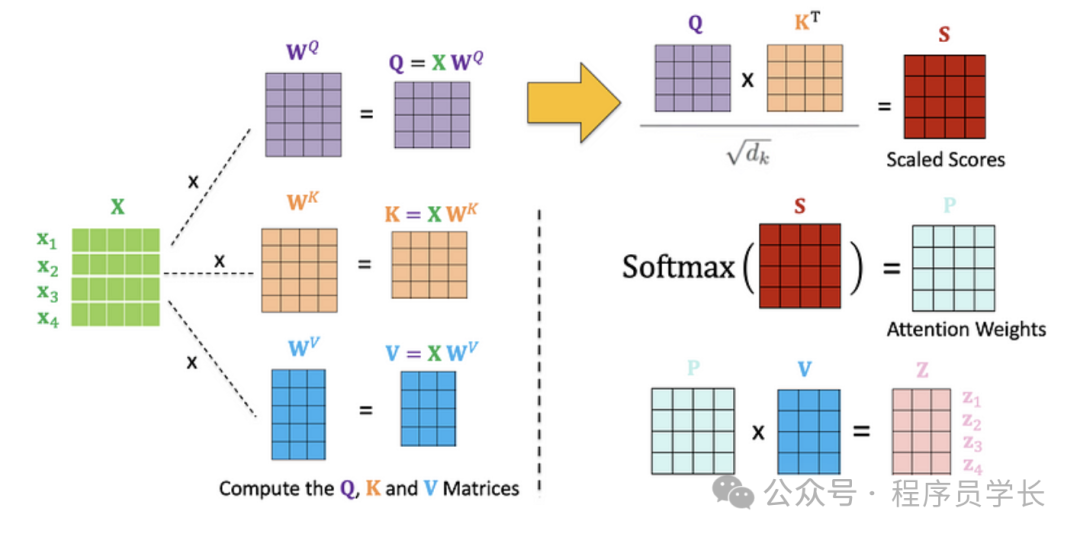
首先,将输入 X 通过三个不同的线性变换,生成查询 Q、键 K 和 值 V 矩阵。
其中, 是权重矩阵。
-
计算注意力权重
通过计算查询 Q 和键 K 之间的相似度,得到的结果是一个矩阵,表示了每个位置的查询向量与其他位置键向量的相似度。
-
缩放
为了避免数值过大,通常将相似度值除以 ,其中 是键向量的维度。
-
归一化 (Softmax)
对相似度分数应用 Softmax 函数,将其转换为权重
-
加权和
最后,将得到的权重与值矩阵 V 进行加权求和,得到每个位置的最终表示。
这样,每个位置的输出就是一个包含了整个序列上下文信息的向量表示。
自注意力的优点
- 全局信息捕捉:通过自注意力机制,模型能够在每个位置考虑到其他位置的信息,从而能够捕捉到长期依赖关系。
- 并行计算:与 RNN 等传统方法不同,自注意力机制不依赖于序列的顺序,因此可以进行并行化计算。
import torch
import torch.nn as nn
class SelfAttention(nn.Module):
def __init__(self, embed_dim):
super(SelfAttention, self).__init__()
self.embed_dim = embed_dim
# 定义可训练参数
self.W_Q = nn.Linear(embed_dim, embed_dim)
self.W_K = nn.Linear(embed_dim, embed_dim)
self.W_V = nn.Linear(embed_dim, embed_dim)
def forward(self, x):
"""
:param x: 输入序列 (batch_size, seq_len, embed_dim)
:return: 自注意力后的输出 (batch_size, seq_len, embed_dim)
"""
Q = self.W_Q(x) # (batch_size, seq_len, embed_dim)
K = self.W_K(x) # (batch_size, seq_len, embed_dim)
V = self.W_V(x) # (batch_size, seq_len, embed_dim)
# 计算注意力分数
attn_scores = torch.matmul(Q, K.transpose(-2, -1)) / torch.sqrt(torch.tensor(self.embed_dim, dtype=torch.float32))
attn_probs = torch.softmax(attn_scores, dim=-1) # 归一化
# 计算加权和
attn_output = torch.matmul(attn_probs, V) # (batch_size, seq_len, embed_dim)
return attn_output
# 测试
batch_size, seq_len, embed_dim = 2, 5, 8
x = torch.rand(batch_size, seq_len, embed_dim)
self_attention = SelfAttention(embed_dim)
output = self_attention(x)
print("Self-Attention Output Shape:", output.shape)
多头自注意力机制
多头自注意力机制是对自注意力机制的扩展,它通过多个注意力头学习不同的特征子空间,以增强模型的表达能力。
具体来说,它将查询、键和值的线性变换拆分成多个头(多个子空间),然后每个头可以在不同的子空间中学习不同的注意力模式。最终,将所有头的输出拼接起来并通过线性变换得到最终的输出。
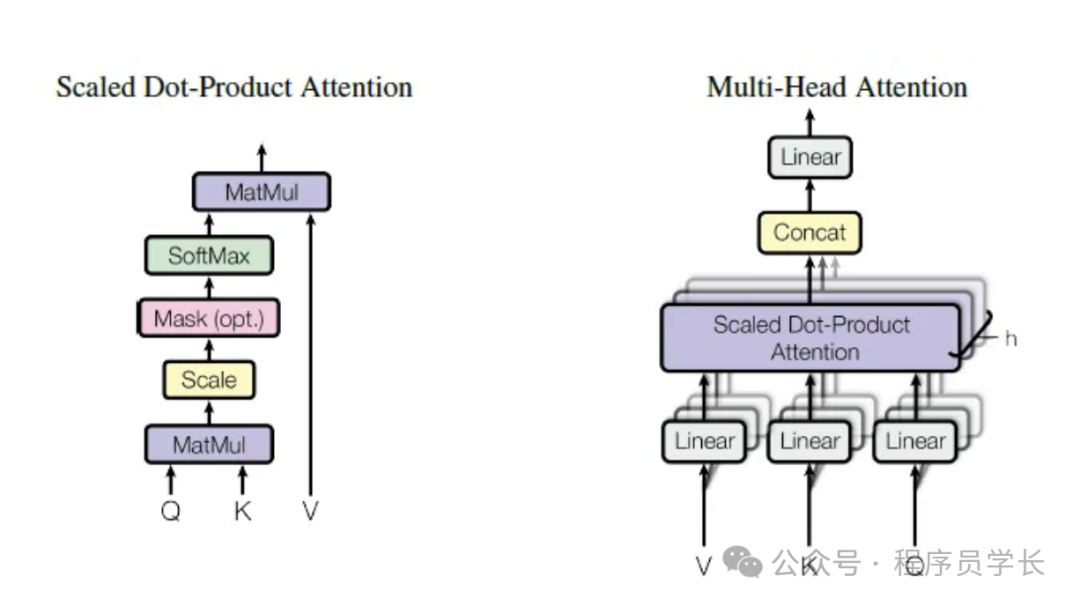
多头自注意力的计算过程如下。
-
将输入映射到多个头,每个头独立执行自注意力计算
-
拼接与线性变换
将所有注意力头的输出拼接起来,并通过线性变换得到最终输出。
其中,h 是头的数量, 是输出的线性变换矩阵。
class MultiHeadAttention(nn.Module):
def __init__(self, embed_dim, num_heads):
super(MultiHeadAttention, self).__init__()
assert embed_dim % num_heads == 0, "Embedding dimension must be divisible by number of heads"
self.embed_dim = embed_dim
self.num_heads = num_heads
self.head_dim = embed_dim // num_heads # 每个头的维度
# 线性变换矩阵
self.W_Q = nn.Linear(embed_dim, embed_dim)
self.W_K = nn.Linear(embed_dim, embed_dim)
self.W_V = nn.Linear(embed_dim, embed_dim)
self.W_O = nn.Linear(embed_dim, embed_dim) # 最终输出变换
def forward(self, x):
batch_size, seq_len, embed_dim = x.shape
# 计算 Q, K, V
Q = self.W_Q(x) # (batch_size, seq_len, embed_dim)
K = self.W_K(x) # (batch_size, seq_len, embed_dim)
V = self.W_V(x) # (batch_size, seq_len, embed_dim)
# 变形为多头形式: (batch_size, num_heads, seq_len, head_dim)
Q = Q.view(batch_size, seq_len, self.num_heads, self.head_dim).transpose(1, 2)
K = K.view(batch_size, seq_len, self.num_heads, self.head_dim).transpose(1, 2)
V = V.view(batch_size, seq_len, self.num_heads, self.head_dim).transpose(1, 2)
# 计算注意力分数
attn_scores = torch.matmul(Q, K.transpose(-2, -1)) / torch.sqrt(torch.tensor(self.head_dim, dtype=torch.float32))
attn_probs = torch.softmax(attn_scores, dim=-1)
# 计算加权和
attn_output = torch.matmul(attn_probs, V) # (batch_size, num_heads, seq_len, head_dim)
# 恢复形状: 先transpose再reshape
attn_output = attn_output.transpose(1, 2).reshape(batch_size, seq_len, embed_dim)
# 通过最终的线性变换
output = self.W_O(attn_output) # (batch_size, seq_len, embed_dim)
return output
# 测试
num_heads = 4
multihead_attention = MultiHeadAttention(embed_dim, num_heads)
output = multihead_attention(x)
print("Multi-Head Attention Output Shape:", output.shape)
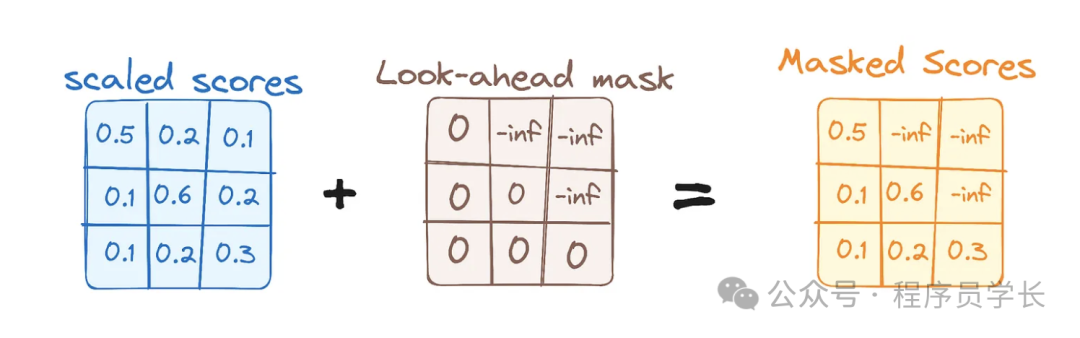
掩蔽自注意力机制
掩蔽自注意力机制出现在 Transformer 模型的解码器部分,它作用是防止模型在预测当前位置的词时,看到未来位置的信息,从而保持自回归的生成顺序。
在掩蔽自注意力中,掩蔽操作会将注意力得分矩阵中的未来信息掩盖,通常是将其设置为负无穷大()。这样,通过应用 Softmax 时,这些位置的权重会变为零,从而避免了信息泄漏。
数学公式为
其中 M 是一个掩蔽矩阵
如果如果
这意味着计算出来的所有掩蔽位置的注意力得分为零,不会对最终结果产生影响。
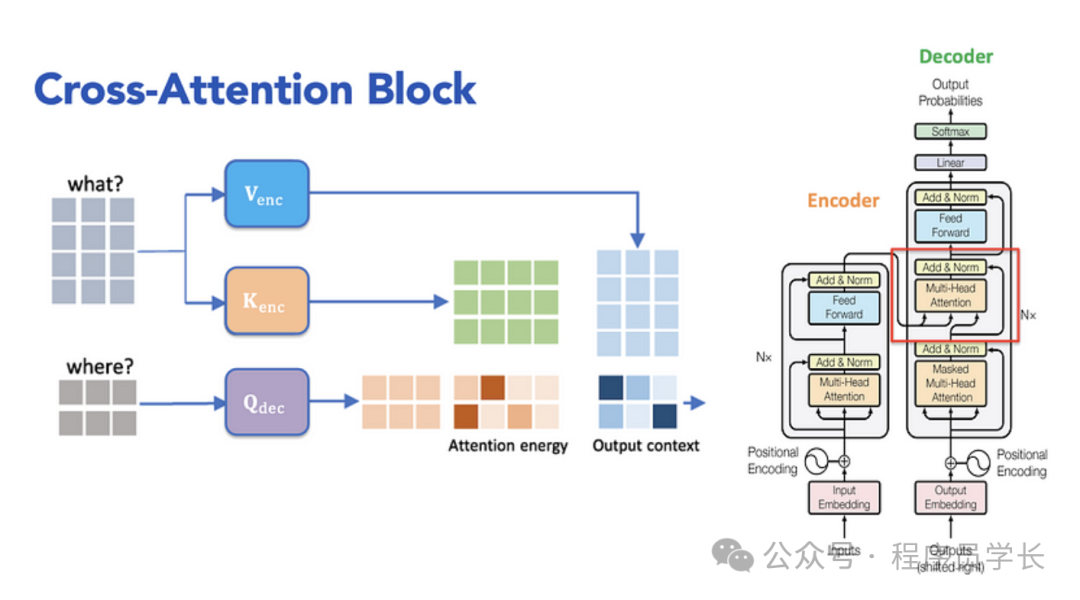
交叉自注意力机制(Cross-Attention)
交叉(编码器-解码器)自注意力机制用于 Transformer 解码器部分,它允许解码器在生成输出时关注编码器的输出。这个机制使得解码器能够利用编码器产生的上下文信息来生成目标序列。
交叉自注意力的计算过程类似于自注意力,只是它使用了来自编码器的输出作为值(Value)和键(Key),而查询(Query)来自解码器的当前输入。
交叉注意力计算的公式如下:
其中,查询向量 Q 来自解码器的输入,而键向量 K 和值向量 V 来自编码器的输出。
交叉注意力的核心思想是解码器在生成每个词时,不仅依赖于自己已经生成的部分(自注意力),还会关注编码器输出的表示。
最后的最后
感谢你们的阅读和喜欢,作为一位在一线互联网行业奋斗多年的老兵,我深知在这个瞬息万变的技术领域中,持续学习和进步的重要性。
为了帮助更多热爱技术、渴望成长的朋友,我特别整理了一份涵盖大模型领域的宝贵资料集。
这些资料不仅是我多年积累的心血结晶,也是我在行业一线实战经验的总结。
这些学习资料不仅深入浅出,而且非常实用,让大家系统而高效地掌握AI大模型的各个知识点。如果你愿意花时间沉下心来学习,相信它们一定能为你提供实质性的帮助。
这份完整版的大模型 AI 学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】

大模型知识脑图
为了成为更好的 AI大模型 开发者,这里为大家提供了总的路线图。它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

经典书籍阅读
阅读AI大模型经典书籍可以帮助读者提高技术水平,开拓视野,掌握核心技术,提高解决问题的能力,同时也可以借鉴他人的经验。对于想要深入学习AI大模型开发的读者来说,阅读经典书籍是非常有必要的。

实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

面试资料
我们学习AI大模型必然是想找到高薪的工作,下面这些面试题都是总结当前最新、最热、最高频的面试题,并且每道题都有详细的答案,面试前刷完这套面试题资料,小小offer,不在话下

640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

这份完整版的大模型 AI 学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】

















 2504
2504

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









