



本文围绕如何落地一个全新的,具备自主规划、自主编排、自主执行、自主反思和自主优化的多智能体开发平台,具备A2A、MAS、n8n、MCP、记忆、ACE、反思、自主规划、RAG、知识库、知识图谱、工作流编排、多模态知识导入、抽帧、对齐与检索等功能技术的前沿开发平台展开。
一、整体架构总览
Agent 系统 = 认知引擎(ACE) + 记忆系统 + 工具执行层 + 编排控制层 + 协作通信层。
系统架构图
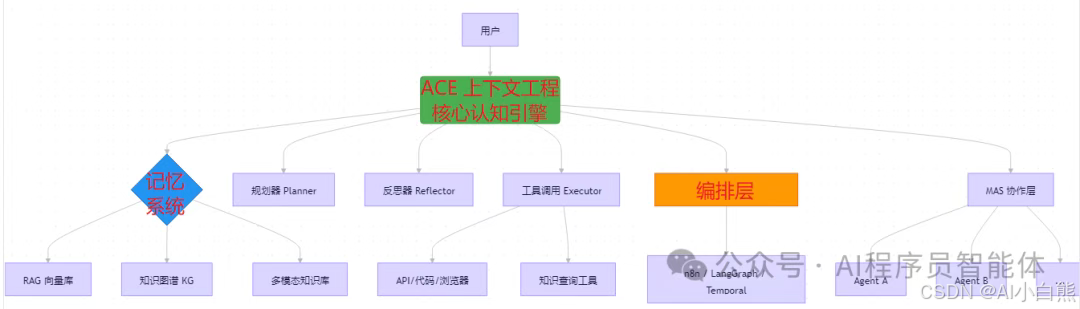
二、Agent 核心能力模型(7 大支柱)
-
感知(Perception)
理解用户意图与环境状态
-
记忆(Memory)
短期上下文 + 向量知识库(RAG) + 结构化知识图谱(KG) + 多模态知识
-
规划(Planning)
任务分解、路径搜索、目标导向推理
-
行动(Action)
工具调用、代码执行、API 请求、人机协同
-
反思(Reflection)
自我评估、错误修正、策略优化
-
协作(Collaboration)
A2A 通信、多智能体系统(MAS)
-
控制(Control)
安全沙箱、权限管理、工作流编排、可观测性
三、记忆系统详解
整体架构:三层记忆体系
-
Working Memory
当前对话上下文(LLM 上下文窗口)
-
Episodic Memory
历史交互日志(用于个性化与反思)
-
Semantic Memory
- 向量知识库(RAG)
- 结构化知识图谱(KG)
- 多模态知识库(图像/音频/视频 Embedding)
3.1 RAG 知识处理流水线
端到端流程:接入 → 解析 → 切片 → 向量化 → 存储 → 检索 → 融合生成
RAG 知识处理流程:
① 知识源接入(Knowledge Ingestion)
- 支持格式:PDF、Word、PPT、HTML、Markdown、数据库表、API 文档
- 接入方式:
- 手动上传(Web UI)
- 自动同步(S3/OSS 监听、Git Hook、数据库 CDC)
- n8n 触发 ETL 流程
② 文档解析与清洗(Parsing & Cleaning)
- 工具选型:
Unstructured 通用文档解析LlamaParse / Marker:高精度 PDF 表格/公式保留- 自定义规则:移除页眉页脚、广告、水印
- 输出:结构化文本块(含元数据:source, page, section)
③ 文本切片(Chunking)
- 切片策略:
- 固定长度(512 tokens)
- 语义边界(按段落、标题、句子)
- 重叠切片(overlap=50 tokens,避免上下文断裂)
- 高级策略:
-
Parent-Child Chunking
小 chunk 检索 + 大 chunk 生成
-
摘要增强切片
每个 chunk 附加 LLM 生成的摘要
④ 向量化(Embedding)
- 模型选型:
- 通用:
text-embedding-3-large、bge-large-zh-v1.5 - 领域微调:在企业语料上继续预训练 embedding 模型
- 批量向量化:异步任务队列(Celery / Ray)
- 向量维度压缩(可选):PCA / PQ 降低存储成本

⑤ 向量存储与索引
- 数据库选型:
- Pinecone(托管,易用)
- Weaviate(支持混合搜索 + KG)
- Milvus / Qdrant(开源,高吞吐)
- 索引类型:HNSW(近似最近邻)、IVF(大规模场景)
- 元数据过滤:支持按 source、date、department 等字段筛选
⑥ 检索与重排序(Retrieval & Re-ranking)
- 初检:向量相似度(cosine)
- 查询优化:
- HyDE(生成假设文档再检索)
- 查询扩展(同义词、实体链接)
- 重排序:
bge-reranker、Cohere Rerank提升 Top-K 质量 - 幻觉抑制:拒绝低相关性结果(阈值控制)
⑦ RAG 与 Agent 集成(Agent Prompt 注入,LLM 生成带引用的回答)
- 工具封装:
search_knowledge_base(query, filters={}) - 上下文注入:将 Top-3 chunks 拼接进 prompt
- 可追溯性:回答中标注引用来源
3.2 多模态知识处理流水线
图像/音频/视频 → 内容提取 → 跨模态 Embedding → 统一检索
流程图
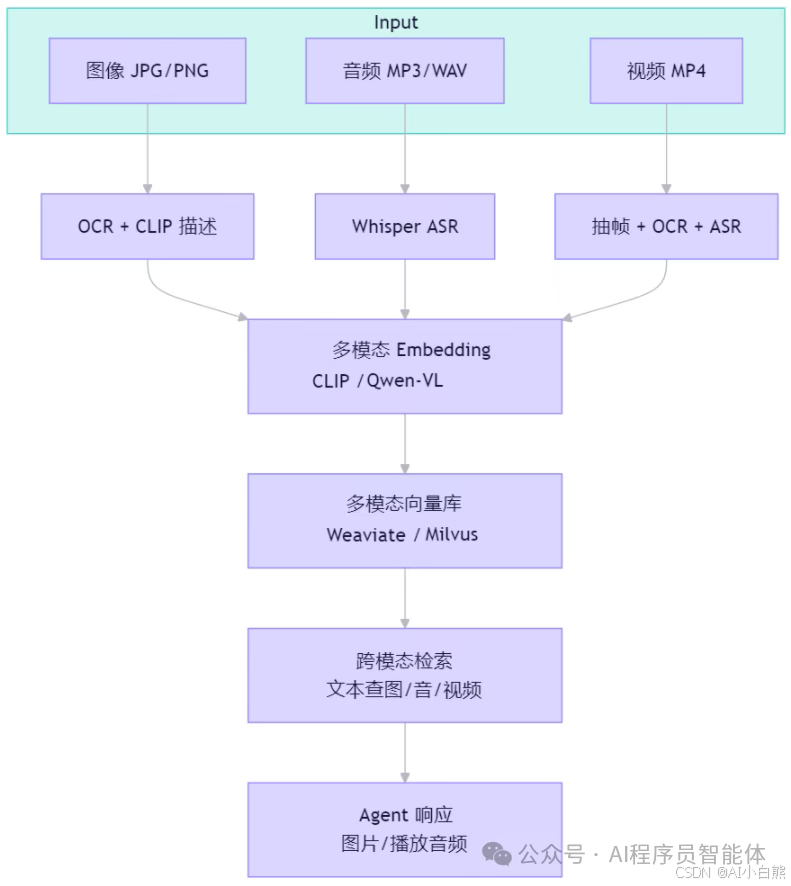
注意:需要支持时间戳对齐(视频)、说话人分离(音频)、敏感内容过滤。
3.3 统一记忆服务接口
组件交互图
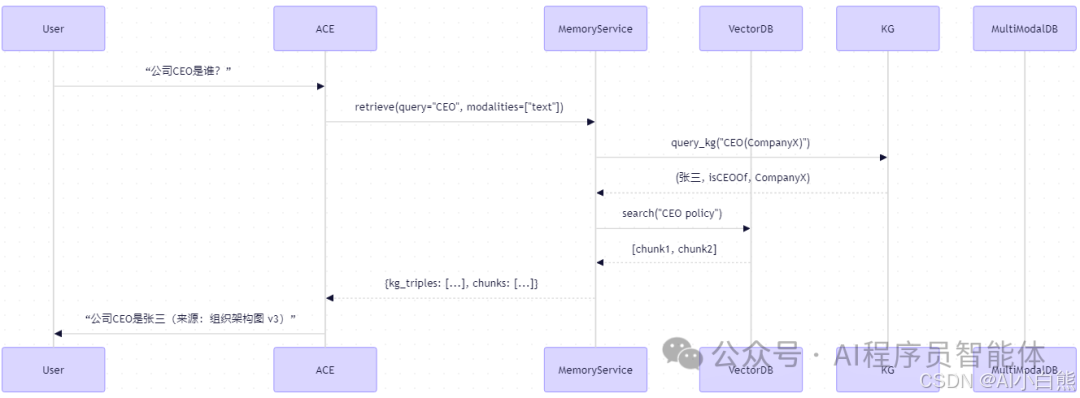
体现“一次查询,多源融合”。
多模态知识导入与 RAG(图像/音频/视频)
① 多模态知识源接入
- 图像:产品图、流程图、截图(JPG/PNG)
- 音频:会议录音、客服语音(MP3/WAV)
- 视频:培训录像、操作演示(MP4)
② 多模态内容解析
| 类型 | 处理技术 |
|---|---|
| 图像 | OCR(Tesseract, PaddleOCR) + 视觉理解(CLIP, Florence-2) → 生成描述文本 |
| 音频 | ASR(Whisper, Paraformer) → 转文字 + 说话人分离 |
| 视频 | 抽帧(每5秒) + 图像描述 + 语音转写 → 时间戳对齐的多模态文本 |
③ 多模态 Embedding
- 统一嵌入空间:
- 使用 多模态大模型(如 CLIP、Qwen-VL、LLaVA)生成跨模态向量
- 文本 query 可直接检索图像/视频片段
- 向量存储:与文本向量共库存储(Weaviate / Milvus 支持 multi-vector)
④ 多模态 RAG 检索
- 用户问:“展示服务器安装步骤的视频”
- 系统检索视频描述向量 → 返回匹配视频 + 时间戳(如 2:15–3:30)
- 用户问:“这张图里有什么设备?”(附图)
- 图像编码 → 检索相似图像或关联文档
- 混合检索:文本 + 图像联合查询(late fusion)
⑤ 多模态响应生成
- Agent 调用 TTS 生成语音回答
- 在 Web 界面嵌入检索到的图像/视频片段
- 支持“看图问答”、“听音查文档”等场景
知识图谱(KG)集成(与 RAG 互补)
- 从文本中抽取三元组(LLM + OpenIE)
- 存储于 Neo4j,支持 Cypher 查询
- 用于精确关系推理(如“张三的直属领导是谁?”)
统一记忆服务接口
class MemoryService:
def retrieve(
self,
query: str,
modalities: List[str] = ["text", "image", "audio"],
sources: List[str] = None,
top_k: int = 5
) -> List[MemoryItem]:
# 内部路由到 RAG / KG / 多模态检索
2. 自主规划(Autonomous Planning)
- 规划范式:ReAct、Plan-and-Execute、Tree-of-Thoughts、LATS
- 动态重规划:应对工具失败、知识缺失、环境变化
- 规划与知识联动:“写周报” → 自动检索上周任务(KG)+ 会议纪要(RAG)
3. 工具调用与执行器(Tool Use & Executor)
- 工具类型:
- 通用 API(天气、支付)
- 知识工具(
search_knowledge_base,query_knowledge_graph) - 代码解释器(Python REPL)
- 浏览器自动化(Playwright)
- 工具注册与描述:供 LLM 决策调用
- 错误处理:重试、降级、转人工
4. 反思机制(Reflection / Self-Critique)
- 触发条件:任务失败、用户负面反馈、低置信度
- 反思内容:
- 检索是否相关?
- 规划是否冗余?
- 知识是否缺失?
- 输出:更新策略、修正记忆、优化 prompt
5. ACE(Advanced Cognitive Engine)—— 中枢认知控制器
- 集成规划、记忆、反思、工具调度
- 支持元认知:评估自身能力边界
- 动态路由:根据任务类型选择 RAG / KG / 参数化知识
- 与传统 Agent Loop 区别:更强的状态管理与干预能力
6. 工作流编排(Workflow Orchestration)—— Agent 的执行骨架
- 为什么需要显式编排?
LLM 规划不确定,生产需确定性、可审计、可重试的执行路径
- 编排类型
- 单 Agent 内部 DAG(查天气 → 查航班 → 生成行程)
- 多 Agent 协作流程(Manager → Researcher → Writer)
- 人机混合流程(高风险操作需审批)
- 引擎选型
- 低代码:n8n、Zapier(适合简单触发)
- 代码化 DAG:Airflow、Temporal(高可靠)
- Agent 原生:LangGraph、CrewAI、AutoGen(支持循环、条件、状态)
-
关键能力
状态持久化、并行执行、条件分支、版本管理、可观测性
四、工作流编排
4.1 Agent 内部工作流(LangGraph 示例)
使用状态机实现:Plan → Execute → Reflect → Retry/End
状态机流程图
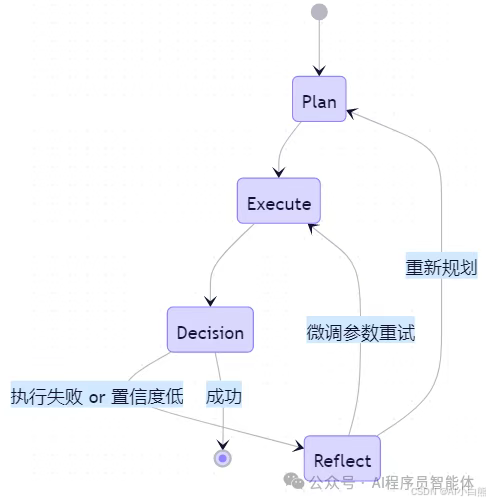
支持循环、条件跳转、最大重试次数限制。
4.2 n8n 与 Agent 集成
集成架构图
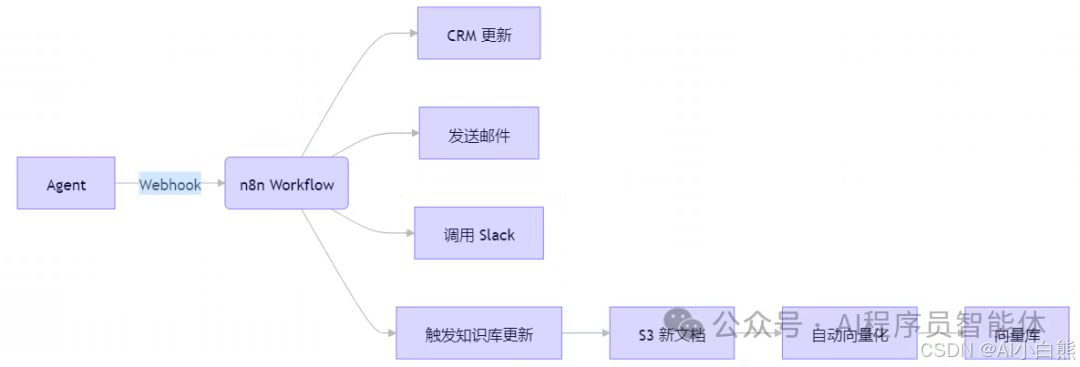
n8n 作为“低代码执行后端”,处理非智能但高频的操作。
执行:CRM 更新、邮件发送、数据同步、知识库 ETL
优势:可视化、连接器生态、错误重试
五、多智能体系统(MAS)
5.1 MAS 协作模式:编排式和编舞式2种
方式一:编排式 MAS(Orchestration)
中心 Manager 分配任务(CrewAI)
时序交互图
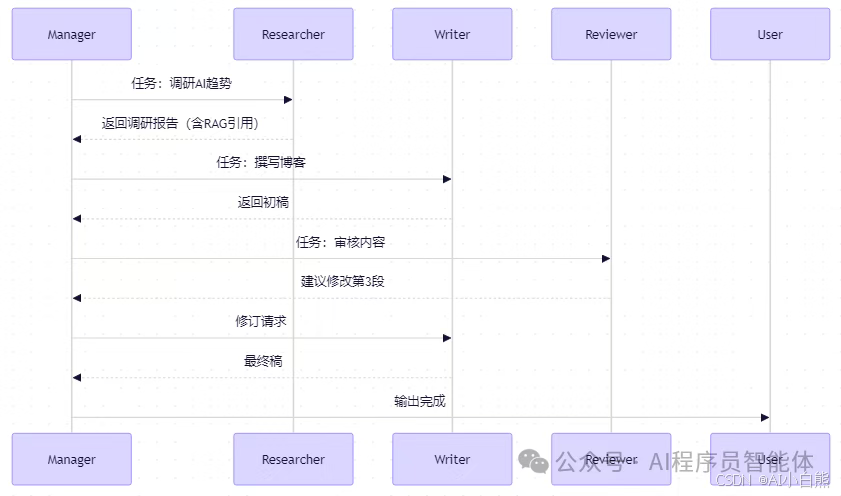
中心化控制,适合企业审批流。
方式二:Choreography(编舞式)
事件驱动,Agent 自主响应
5.2 典型范式
- Debate(辩论决策)
- Critic-Actor(批评-执行)
- Hierarchical Teams(分层协作)
****5.3协作中的工作流与知识共享
- Specialist Agents 各维护领域知识库
- Knowledge Broker Agent 负责跨源融合
- 工作流模板作为协作协议标准
5.4 A2A(Agent-to-Agent)通信
- 通信协议:自然语言、结构化 JSON、MCP(Model Context Protocol)
- MCP核心字段
{
"workflow_id": "report_gen_v2",
"current_step": "research",
"knowledge_references": ["KB#123", "KG:CEO(Apple)"],
"next_agents": ["writer_agent"]
}
-
MCP(Model Context Protocol)消息结构
JSON 结构示意图

标准化 A2A 通信,支持知识溯源。
目标:标准化 Agent 与工具/记忆/其他 Agent 的上下文交换
支持携带:规划步骤、知识引用、工作流状态、反思笔记
六、工程化落地关键技术
知识基础设施
| 组件 | 技术选型 |
|---|---|
| 向量数据库 | Pinecone, Weaviate, Qdrant, Milvus |
| 知识图谱 | Neo4j, Amazon Neptune, JanusGraph |
| 文档解析 | Unstructured, LlamaParse |
| 图谱构建 | LLM-based IE, Stanford OpenIE |
多模态知识基础设施
| 功能 | 技术方案 |
|---|---|
| 文档解析 | Unstructured, LlamaParse, Apache Tika |
| OCR | PaddleOCR, Google Vision API |
| ASR | Whisper-large-v3, FunASR |
| 视频抽帧 | OpenCV, FFmpeg |
| 多模态 Embedding | CLIP ViT-L/14, Qwen-VL-Chat, Jina-Clip-v2 |
| 多模态向量库 | Weaviate(原生支持)、Milvus(自定义 schema) |
| 内容审核 | 敏感图像/语音过滤(阿里云内容安全、AWS Rekognition) |
状态管理
- 任务状态机:Pending → Executing → Reflecting → Done/Failed
- 上下文持久化:支持中断恢复、多轮延续
- 分布式状态同步(MAS 场景)
安全沙箱
- 代码执行隔离:Docker / Firecracker
- 网络访问控制:API 白名单、代理网关
- 敏感操作审批:Human-in-the-loop
可观测性
-
追踪链路:用户请求 → 规划 → 工具调用 → 反思 → 输出
-
关键指标:
任务成功率
RAG/KG 召回率
工作流平均时长
幻觉率
-
日志结构化:便于 bad case 分析与自动评估
-
监控指标:
多模态解析成功率
图像/语音检索召回率
跨模态对齐准确率
n8n 与多模态 ETL:
- n8n workflow 示例:
上传视频 → FFmpeg抽帧 → Whisper转语音 → CLIP编码图像 → 入库 Milvus - 支持自动触发知识更新
七、安全与可观测性
7.1 安全沙箱架构
分层安全模型
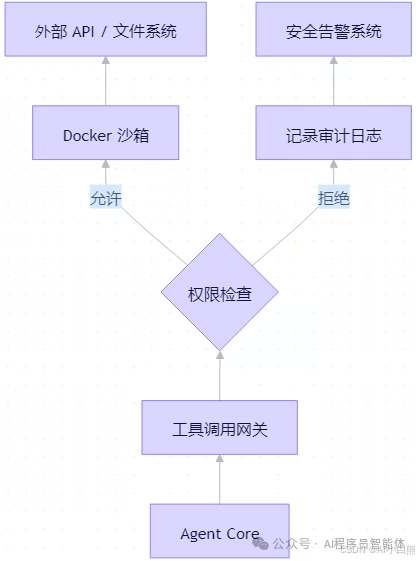
所有危险操作(代码执行、文件写入)必须通过沙箱。
7.2 可观测性追踪链路
Trace 链路图
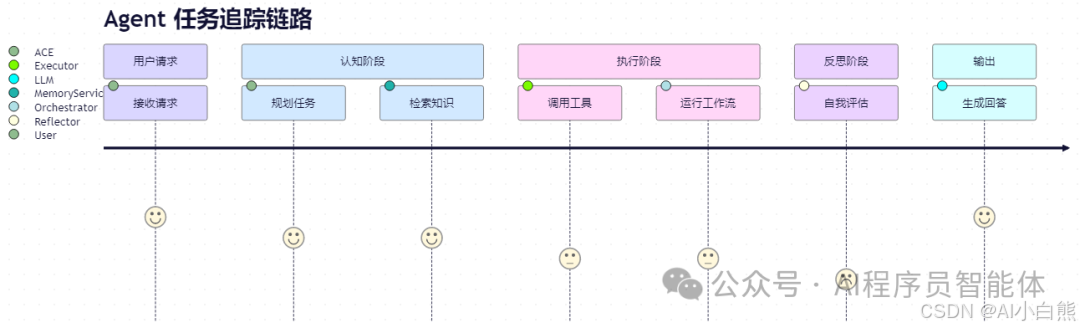
每个环节记录耗时、输入/输出、错误码,支持全链路回放。
八、开发与部署实战路径
- 知识准备阶段:
- 构建多模态知识采集 pipeline
- 设计统一元数据标准(含 modality、source、timestamp)
- 单 Agent 原型:
- 实现文本 RAG + 图像检索双通道
- 测试“图文混合问答”场景
- 工作流设计:
- 绘制任务 DAG 图(使用 Mermaid 或 BPMN)
- 区分确定性步骤(用编排引擎) vs 不确定性步骤(用 LLM 规划)
- 原型开发:
- 简单场景:用 n8n + Webhook 接入 Agent
- 复杂场景:用 LangGraph 实现带反思循环的工作流
- 多 Agent 协同:
- 使用 CrewAI 或 LangGraph 实现角色分工
- 集成 n8n:
- 将重复性操作下沉至低代码 workflow
- 生产部署:
- 容器化(K8s)
- 工作流定义版本化(GitOps)
- 限流、熔断、A/B 测试
- 持续迭代:
- 自动化评估(AgentBench、WebArena)
- 用户反馈闭环
- 经验回放与微调
九、未来趋势
-
Agent OS
操作系统级智能体平台
-
Unified Knowledge Interface
RAG + KG + 参数知识的统一查询
-
Self-Evolving Workflows
Agent 自动生成并优化工作流
-
Decentralized MAS
基于区块链的 Agent 经济与身份系统
-
Multimodal Agents
支持图像、语音、视频的感知与行动
十、总结:
构建生产级 Agent 系统的三大支柱:
-
认知引擎(ACE)
负责思考、规划、反思
-
知识基础设施
RAG + 知识库 + 知识图谱 + 多模态,提供事实支撑
-
工作流编排系统
将智能转化为可靠、可审计的行动
核心原则:
- 模块化:各组件可插拔、可替换
- 可观测:每一步都可追踪、可回放
- 可干预:始终保留 Human-in-the-loop 控制权
- 可进化:通过反思与反馈持续优化知识与流程
普通人如何抓住AI大模型的风口?
领取方式在文末
为什么要学习大模型?
目前AI大模型的技术岗位与能力培养随着人工智能技术的迅速发展和应用 , 大模型作为其中的重要组成部分 , 正逐渐成为推动人工智能发展的重要引擎 。大模型以其强大的数据处理和模式识别能力, 广泛应用于自然语言处理 、计算机视觉 、 智能推荐等领域 ,为各行各业带来了革命性的改变和机遇 。
目前,开源人工智能大模型已应用于医疗、政务、法律、汽车、娱乐、金融、互联网、教育、制造业、企业服务等多个场景,其中,应用于金融、企业服务、制造业和法律领域的大模型在本次调研中占比超过 30%。

随着AI大模型技术的迅速发展,相关岗位的需求也日益增加。大模型产业链催生了一批高薪新职业:

人工智能大潮已来,不加入就可能被淘汰。如果你是技术人,尤其是互联网从业者,现在就开始学习AI大模型技术,真的是给你的人生一个重要建议!
最后
只要你真心想学习AI大模型技术,这份精心整理的学习资料我愿意无偿分享给你,但是想学技术去乱搞的人别来找我!
在当前这个人工智能高速发展的时代,AI大模型正在深刻改变各行各业。我国对高水平AI人才的需求也日益增长,真正懂技术、能落地的人才依旧紧缺。我也希望通过这份资料,能够帮助更多有志于AI领域的朋友入门并深入学习。
真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发

大模型全套学习资料展示
自我们与MoPaaS魔泊云合作以来,我们不断打磨课程体系与技术内容,在细节上精益求精,同时在技术层面也新增了许多前沿且实用的内容,力求为大家带来更系统、更实战、更落地的大模型学习体验。

希望这份系统、实用的大模型学习路径,能够帮助你从零入门,进阶到实战,真正掌握AI时代的核心技能!
01 教学内容

-
从零到精通完整闭环:【基础理论 →RAG开发 → Agent设计 → 模型微调与私有化部署调→热门技术】5大模块,内容比传统教材更贴近企业实战!
-
大量真实项目案例: 带你亲自上手搞数据清洗、模型调优这些硬核操作,把课本知识变成真本事!
02适学人群
应届毕业生: 无工作经验但想要系统学习AI大模型技术,期待通过实战项目掌握核心技术。
零基础转型: 非技术背景但关注AI应用场景,计划通过低代码工具实现“AI+行业”跨界。
业务赋能突破瓶颈: 传统开发者(Java/前端等)学习Transformer架构与LangChain框架,向AI全栈工程师转型。

vx扫描下方二维码即可
本教程比较珍贵,仅限大家自行学习,不要传播!更严禁商用!
03 入门到进阶学习路线图
大模型学习路线图,整体分为5个大的阶段:

04 视频和书籍PDF合集

从0到掌握主流大模型技术视频教程(涵盖模型训练、微调、RAG、LangChain、Agent开发等实战方向)

新手必备的大模型学习PDF书单来了!全是硬核知识,帮你少走弯路(不吹牛,真有用)

05 行业报告+白皮书合集
收集70+报告与白皮书,了解行业最新动态!

06 90+份面试题/经验
AI大模型岗位面试经验总结(谁学技术不是为了赚$呢,找个好的岗位很重要)

07 deepseek部署包+技巧大全

由于篇幅有限
只展示部分资料
并且还在持续更新中…
真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发

















 28万+
28万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









