







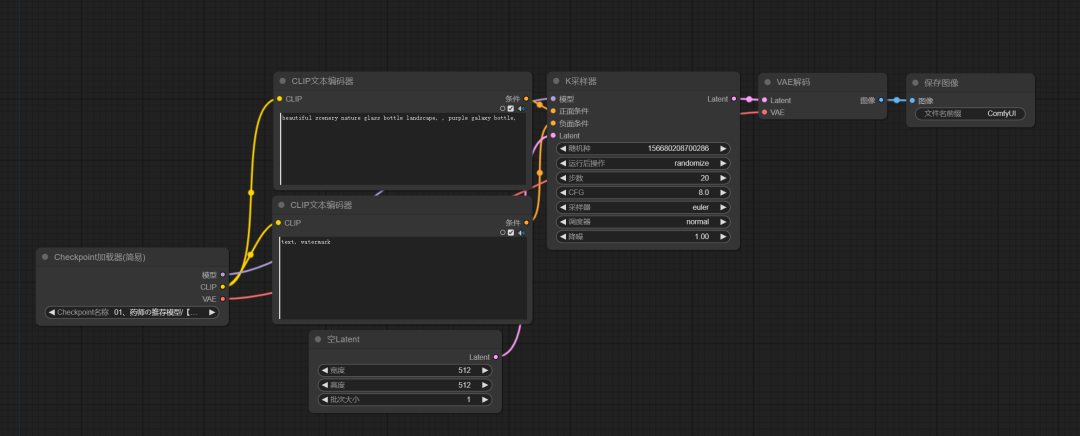
上一期带大家对comfyui的安装有了基本的认知,本期教大家搭建基础的文生图工作流。
首先我回忆一下在原先的SD WEBUI中进行文生图的时候用到了哪些功能包括了:
-
**大模型:**这是整个流程的基础,通常指的是一个预训练的深度学习模型,用于生成或处理数据。
-
**正向提示词:**这些是输入到大模型中的文本,用于引导模型生成或预测特定的输出。
-
**反面提示词:**与正向提示词相对,这些是用于避免不希望的输出或引导模型避免某些特定的行为。
-
**采样器:**在生成模型中,采样器决定了如何从模型的输出分布中选择最终的输出。
-
**步数:**这通常指的是在生成过程中模型需要进行的迭代次数。
-
**宽高:**在图像处理中,这指的是生成图像的尺寸。
-
**VAE:**变分自编码器(Variational Autoencoder),一种生成模型,用于学习数据的潜在表示。
-
**显示图像:**这是流程的最终输出,即生成的图像。
有需要comfyui整合包以及商业应用工作流,可以扫描下方,免费获取

创建流程:
大模型加载器:
-
**打开右键菜单:**首先,我们点击右键打开菜单。
-
**选择新建节点:**在菜单中找到并选择“新建节点”选项。
-
**浏览加载器列表:**在弹出的窗口中,我们会看到许多不同的加载器选项。
-
**识别熟悉的加载器:**我们的目标是找到几个特定的加载器,包括“大模型加载器”、“VAE加载器”和“Lora加载器”。
-
**添加大模型加载器:**我们将“大模型加载器”添加到场景中。我们也可以使用“Checkpoint Loader”
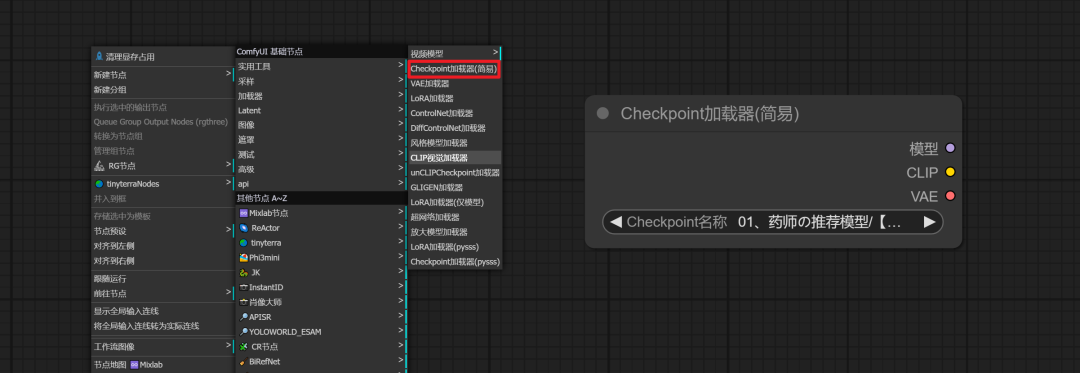
文本输入节点(CLIP文本编码器):
-
添加关键词输入节点:首先,我们需要添加一个用于输入关键词的节点。
-
选择CLIP文本编码器:在新建节点的选项中,我们选择“CLIP文本编码器”。这个节点没有区分正反关键词,因此我们将使用它来输入正反关键词。
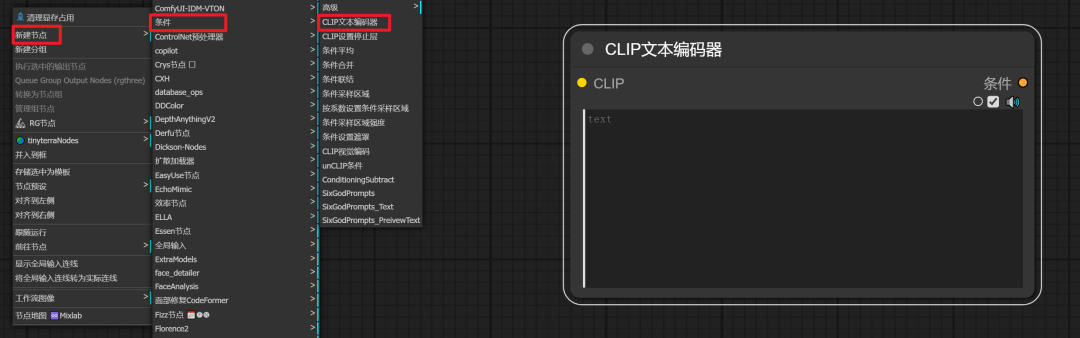
-
添加两个CLIP文本编码器:为了输入正反关键词,我们需要添加两个“CLIP文本编码器”节点。
-
修改节点名称和颜色:为了区分正反关键词,我们可以修改节点的名称和颜色。通过右键点击节点上方,选择“标题”来输入新的名称,然后通过“颜色”选项来选择不同的颜色。
-
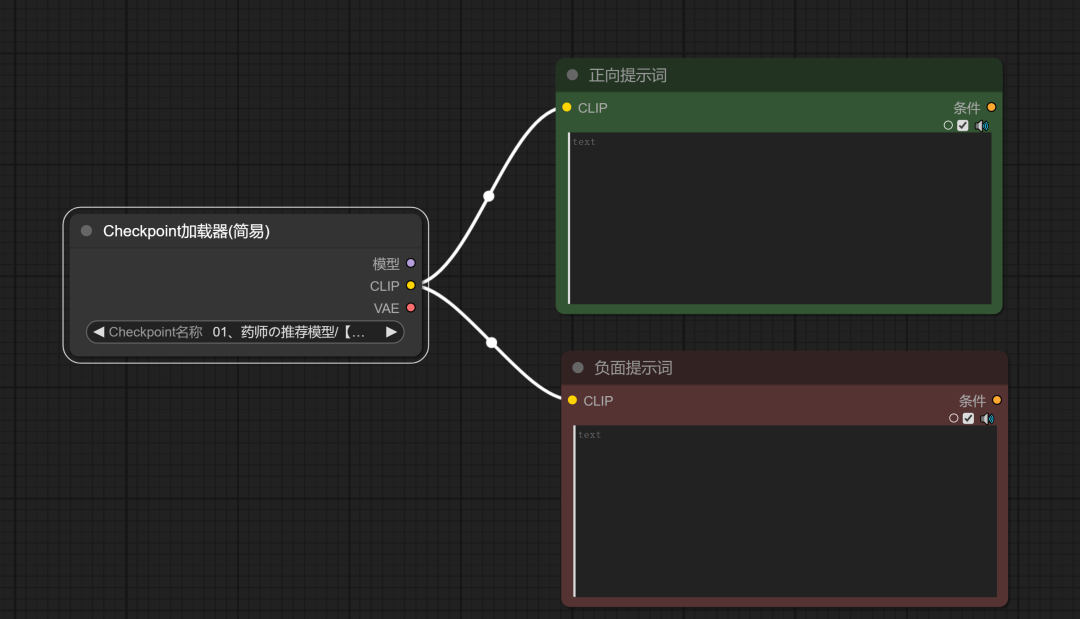
连接Checkpoint加载器和CLIP文本编码器:我们注意到“Checkpoint加载器”和“CLIP文本编码器”都有一个黄色的点,表示它们可以连接。我们可以通过将鼠标放在黄点上,当出现“十”字标识时,按住左键拖动到另一个节点的对应位置来连接它们。
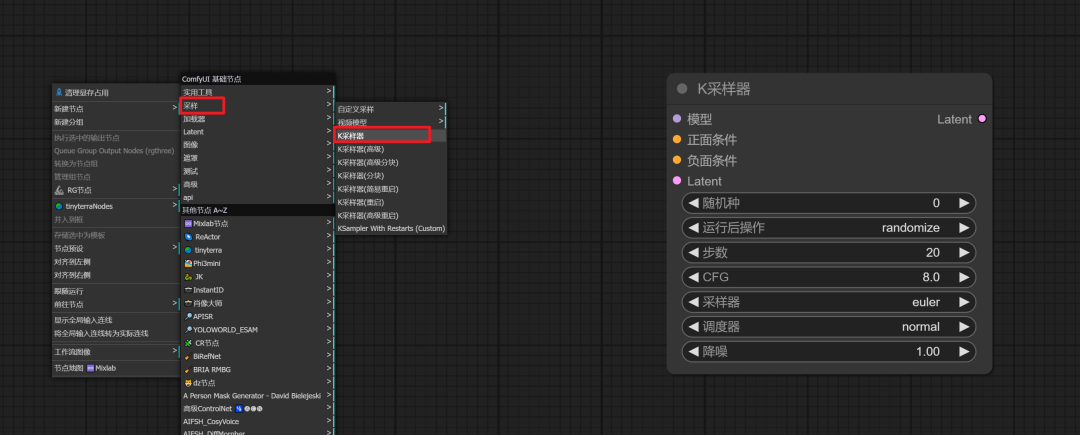
采样器:
在Stable Diffusion模型中,采样器(Sampler)的作用是从噪声数据中逐步构建图像。它们通过逐渐减少噪声的强度,使图像的细节逐渐显现,直至变得清晰。
“右键——采样——采样器(这个地方是有两个采样器的,我们选择普通的采样器就好)”。
-
**随机种子:**用于生成每张图像的独特编号,确保每次生成的图像都有不同的随机性。
-
**运行后操作:**决定种子值是固定、增加、减少还是随机。通常我们选择固定或随机,以控制图像生成的一致性或多样性。
-
**步数:**设置去除噪声的迭代次数,即生成图像所需的计算步骤数量。
-
CFG:提示词引导系数,用于调整生成图像与输入提示词的匹配程度。一般设置在8左右。
-
**采样器:**有多种选项可供选择,每种采样器都有其特定的特性和适用场景。常见的选择包括euler_ancestral、dpmpp_2m等。
-
**调度器:**控制每次迭代中噪声量的大小,常见的选择有normal或karras。
-
**降噪:**与步数相关,用于调整实际执行的步数。例如,如果设置为1,则完全按照输入的步数执行;如果设置为0.1,则只执行10%的步数。
各种采样器的描述和特点
调度器:
-
调度器的作用:调度器通过控制噪声的减少,影响着图像生成的每个阶段。
-
调度器的影响:不同的调度器设置会导致图像生成过程和最终结果的差异。
-
调度器的重要性:调度器的选择和配置对于生成高质量图像至关重要。
各种调度器的描述和特点
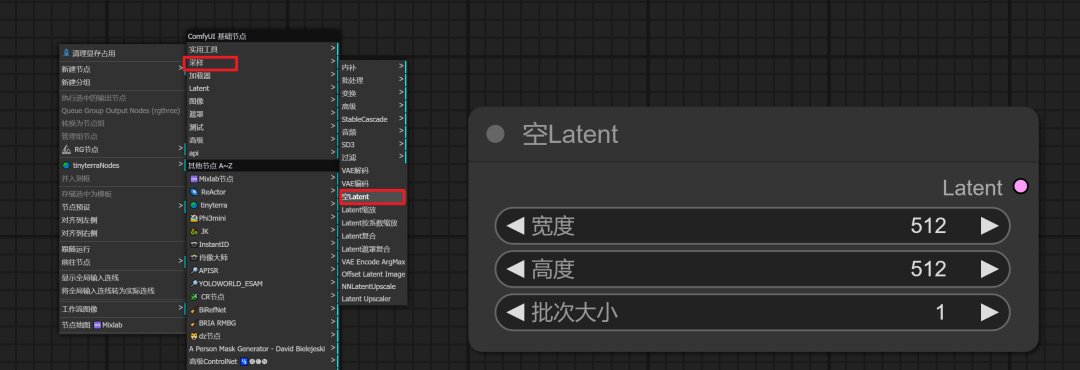
宽高(空Latent):
-
添加Latent节点:
-
- 鼠标点击“Latent”节点。
- 拖动并释放,选择“空Latent”选项。
- 系统会自动添加一个新的Latent节点,并与原先的节点连接。
-
通用节点添加方法:
-
- 这种添加节点的方法适用于所有类型的节点,包括模型和CLIP文本编码器。
- 通过拖动节点的连接点,可以快速添加新的节点并建立连接。
-
设置宽高:
-
- 在Latent节点中设置生成图像的宽度和高度。
-
设置批次:
-
- 批次(Batch size)指的是一次生成图像的数量。
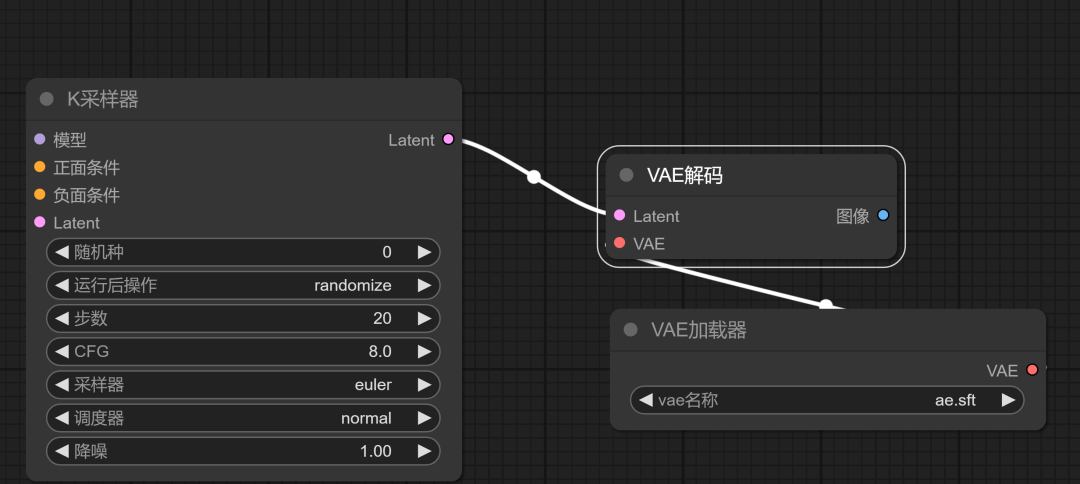
VAE解码:
-
添加VAE解码节点:
-
- 右键点击空白区域,选择“新建节点”。
- 选择“Latent”类别下的“VAE解码”。
- 通过左键拖拽,可以直接添加并连接节点。
-
连接VAE解码的Latent:
-
- 将“VAE解码的Latent”节点与“采样器的Latent”节点相连。
-
处理剩余的VAE连接点:
-
- 在左侧会剩下一个未连接的VAE连接点。
- 将“Checkpoint加载器”的剩余“VAE”连接点与“VAE解码”的连接点相连。
-
连接方法的选择:
-
-
大部分大模型都包含有VAE模型在里面,我们可以直接连接。
-
也可以选择添加一个“VAE加载器”去加载一个VAE模型进行连接。
-
这两种连接方法选择其中一个即可。
-
保存图像:
-
添加保存图像节点:
-
- 右键点击空白区域,选择“新建节点”。
- 选择“图像”类别下的“保存图像”。
- 通过左键拖拽,可以直接添加并连接节点。
-
选择保存图像或预览图像:
-
- 我们可以选择“保存图像”或“预览图像”。
- “保存图像”相比“预览图像”多了一个功能,就是将生成的图像保存到“ComfyUI下的output”文件夹里。
- “保存图像”同样具有预览功能。
-
连接保存图像节点:
-
- 将生成流程的最后一个节点(如采样器)与“保存图像”节点相连。
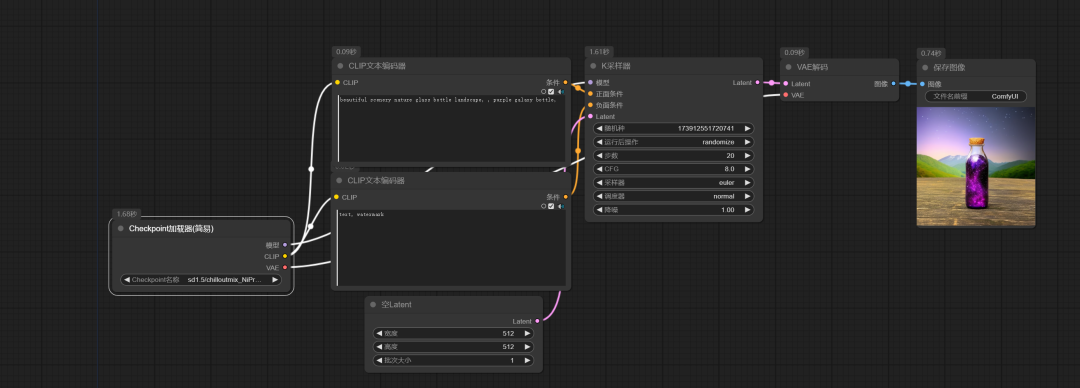
出图:
-
输入关键词:
-
- 在CLIP文本编码器节点中输入正面和负面关键词。
-
调节参数:
-
- 调整模型、步数、宽度、高度等参数,以满足生成图像的需求。
-
启动图像生成:
-
- 点击界面右侧的设置面板中的“提示词队列”按钮。
- 或者使用快捷键“Ctrl+回车”来启动图像生成过程。
-
检查节点连接:
-
- 如果图像生成成功,说明所有节点的连接都是正确的。
-
保存工作流:
-
- 按照之前课程的指导,保存当前的工作流,以便将来重复使用。
-
监控生成过程:
-
- 在图像生成过程中,可以通过观察哪个节点被绿色框选中来判断当前进行到哪一步,这有助于熟悉整个生成流程。
-
关于AI绘画技术储备
学好 AI绘画 不论是就业还是做副业赚钱都不错,但要学会 AI绘画 还是要有一个学习规划。最后大家分享一份全套的 AI绘画 学习资料,给那些想学习 AI绘画 的小伙伴们一点帮助!
对于0基础小白入门:
如果你是零基础小白,想快速入门AI绘画是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以找到适合自己的学习方案
包括:stable diffusion安装包、stable diffusion0基础入门全套PDF,视频学习教程。带你从零基础系统性的学好AI绘画!
零基础AI绘画学习资源介绍
👉stable diffusion新手0基础入门PDF👈
(全套教程文末领取哈)

👉AI绘画必备工具👈

温馨提示:篇幅有限,已打包文件夹,获取方式在:文末
👉AI绘画基础+速成+进阶使用教程👈
观看零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

温馨提示:篇幅有限,已打包文件夹,获取方式在:文末
👉12000+AI关键词大合集👈

这份完整版的AI绘画全套学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】


















 7952
7952

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









