






前言
本文主要回答几个问题
**MJ和SD都有什么区别?
ComfyUI工作流是什么?
为什么AI需要"可控"?
****AI这么强大还需要学习3D吗?
**设计师不学习AI会被市场淘汰吗?
所有的AI设计工具,模型和插件,都已经整理好了,👇获取~
所以本篇主要讲的是ComfyUI是什么?和传统的WebUI以及Midjourney都有什么区别.相信看完本篇大家都可以对这些AI工具有着初步了解。
关于AI的绘画工具,市面上大体上只有两种,即是Midjourney(简称MJ)和Stable Diffusion(简称SD)。
Midjourney
MJ是一个AI绘画平台,充值后,上手即用.使用简单,风格效果出色.这也是大部分同学刚刚学习AI的时候最早接触的平台.
MJ最大的优点是:学习简单,上手可用, 出图的美学水准较高.
MJ最大的缺点就是:收费,出图可控性较弱,只能在线生成。
**Stable Diffusion 大模型
**
SD是一个开源AI大模型Stable Diffusion,因为是开源,所以基于SD的模型或者应用百花齐放,这也是AI深度爱好者比较热于研究和探索的模型。
SD 最大的优点就是:开源,免费,本地可部署,可控性很强,可商业落地。
SD最大的缺点就是:环境配置复杂,不好直接上手,需要一定学习成本。
**Flux 大模型 22G
**
上面提到大体有两种,为什么这里又多了一个呢,因为Flux的效果实在太强了.Flux类似SD大模型,是从SD公司离职后自立门户的一个团队,叫黑森林工作室开发的.效果吊打SD,且媲美MJ的精美程度.唯一的问题就是刚刚出来,其生态并不是很完善,但是未来可期.
关于两者的可控性,举个例子,比如生成吗喽版的黑神话,MJ生成的图像(上图)总是像猩猩,因为在西方眼中,悟空就是类似于金刚之类的生物,是猩猩,所以Monkey King这个关键词,出来都是猩猩脸.而下图为Flux结合Lora控图,得出的效果就好很多.细节质感和美术表现都明显好于MJ.


也许你会疑惑MJ生成了那么多高质量的图片,但是如何把自家产品弄上去。有人会告诉你,利用生成好的图PS,也会有人告诉你使用SD,而可控性,意味着商业的落地可能。
但是SD/Flux等只是一个大模型,就好比发动机,只有发动机是不能开动的,还得需要车壳和一系列的零集合成“框架”,基于SD的框架主要有两种,分别是WebUI和ComfyUI。
WebUI可以理解成更加专业版的MJ,只是多很多复杂的调整选项。简单易上手,属于比较传统的“框架”
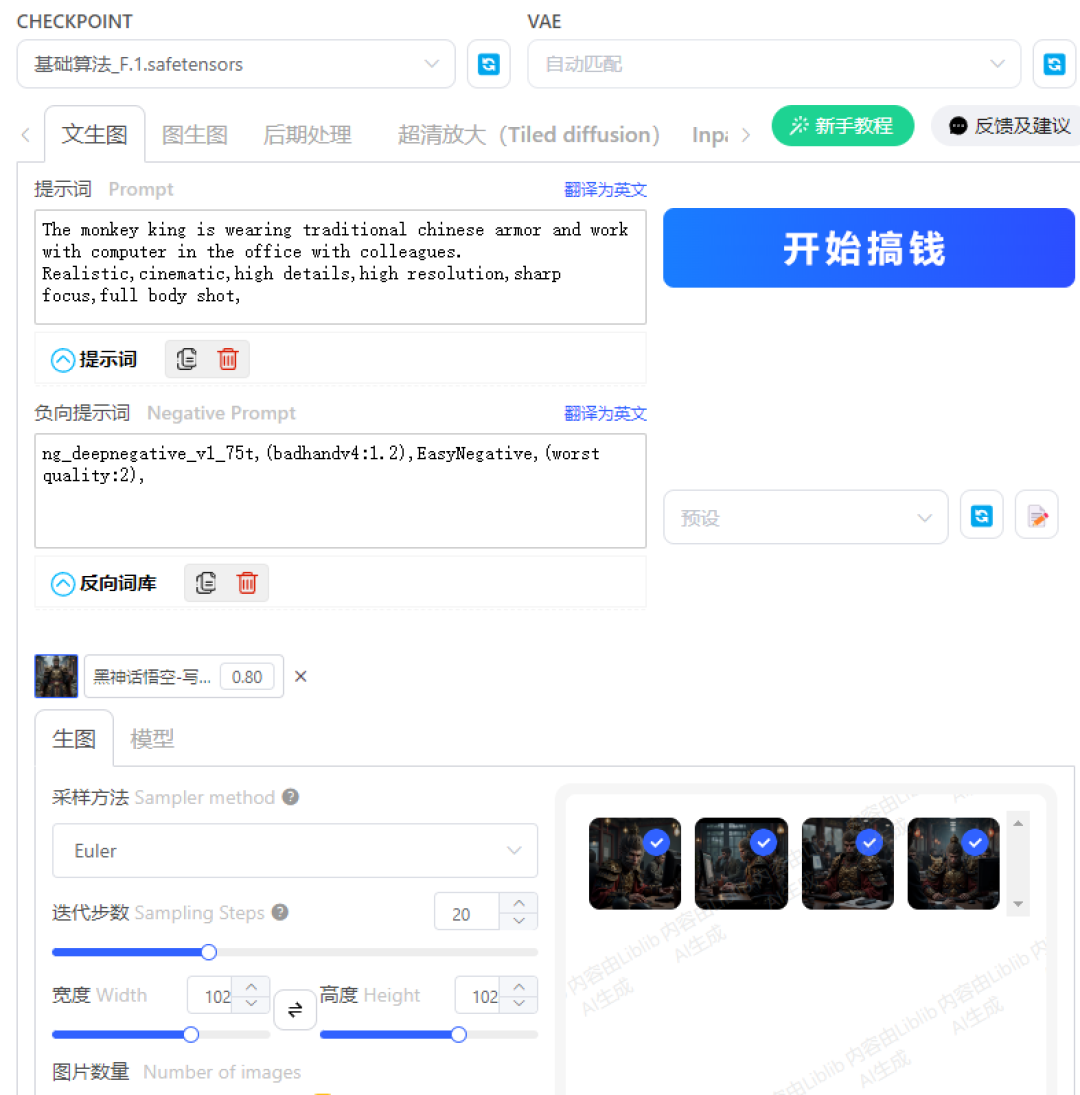
而ComfyUI是基于节点方式的运行方式,通过调用各种节点来实现所需功能.属于比较新型的“框架”,事实上,市面上有很多新兴软件也采用了节点式,比如houdini,touch designer等。

如果学过C4D的同学,这么解释一下也许就懂了.比如我们调一个材质球有两种方法,一种直接在材质球的属性里面直接调颜色,粗糙度,折射率等等,这些相当于模板预设,是软件开发者给大家设置好了。而如果想进行更复杂一些的材质,就必须用到材质节点。而WebUI就相当于已经集成好各项功能的传统材质球,而ComfyUI就好比节点材质球。
什么叫做ComfyUI工作流?
WebUI适合某单项的的功能,从界面的框架可以看出,功能都是定制好的。ComfyUI因为其节点的运作方式,更像一个乐高。需要什么功能,就可以拼上去。比如,可以使用抠图节点把自家产品抠出来,然后使用合图节点融入到一个新的场景中去,最后使用IClight节点重新打光,再高清放大,这样一个成品的流程,就叫做ComfyUI工作流。
在学习成本方面,WebUI学习成本低,易上手。而ComfyUI上手比较困难。难在部署,但一旦上手,灵活性很高.关于部署的教程将会在下一篇文章说明。
**处理越单一的工作时,比如图片高清放大/图生图等,使用WebUI是比较简单的。
而处理越复杂的工作时,使用ComfyUI搭建虽然较为麻烦,但是一旦搭建好之后,之后就可以批量出图。提高未来的工作效率.**
就比如我搭建了一个线稿转3D-IP角色效果的工作流,有了线稿图之后,可以一键生成3D渲染效果,然后用节点生成的图扣成png,每次有了线稿图,可以很快生成3D效果.根本不用打开C4D建模和渲染了。


再比如做了一个字体海报,苦于没有灵感,不知道如何变得更有趣.也可以使用AI来快速获得灵感
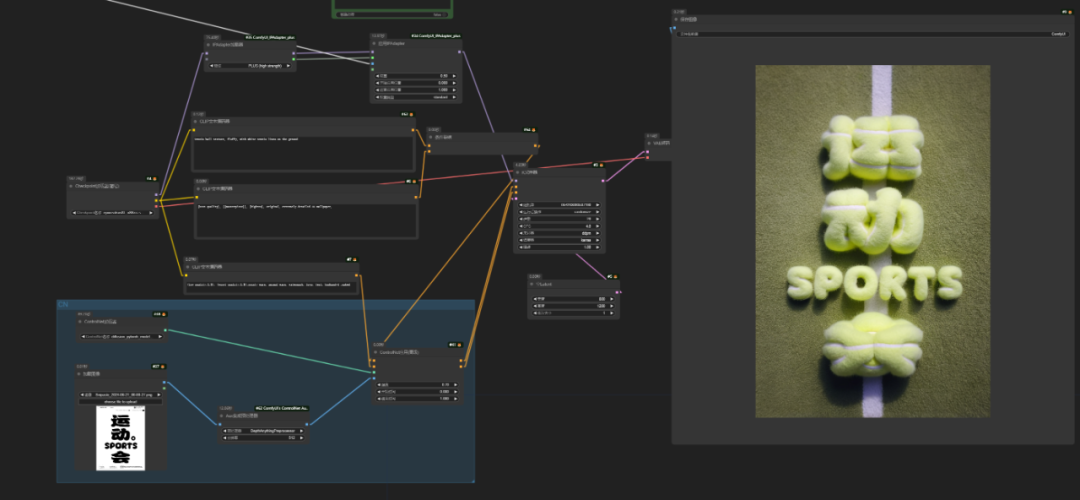

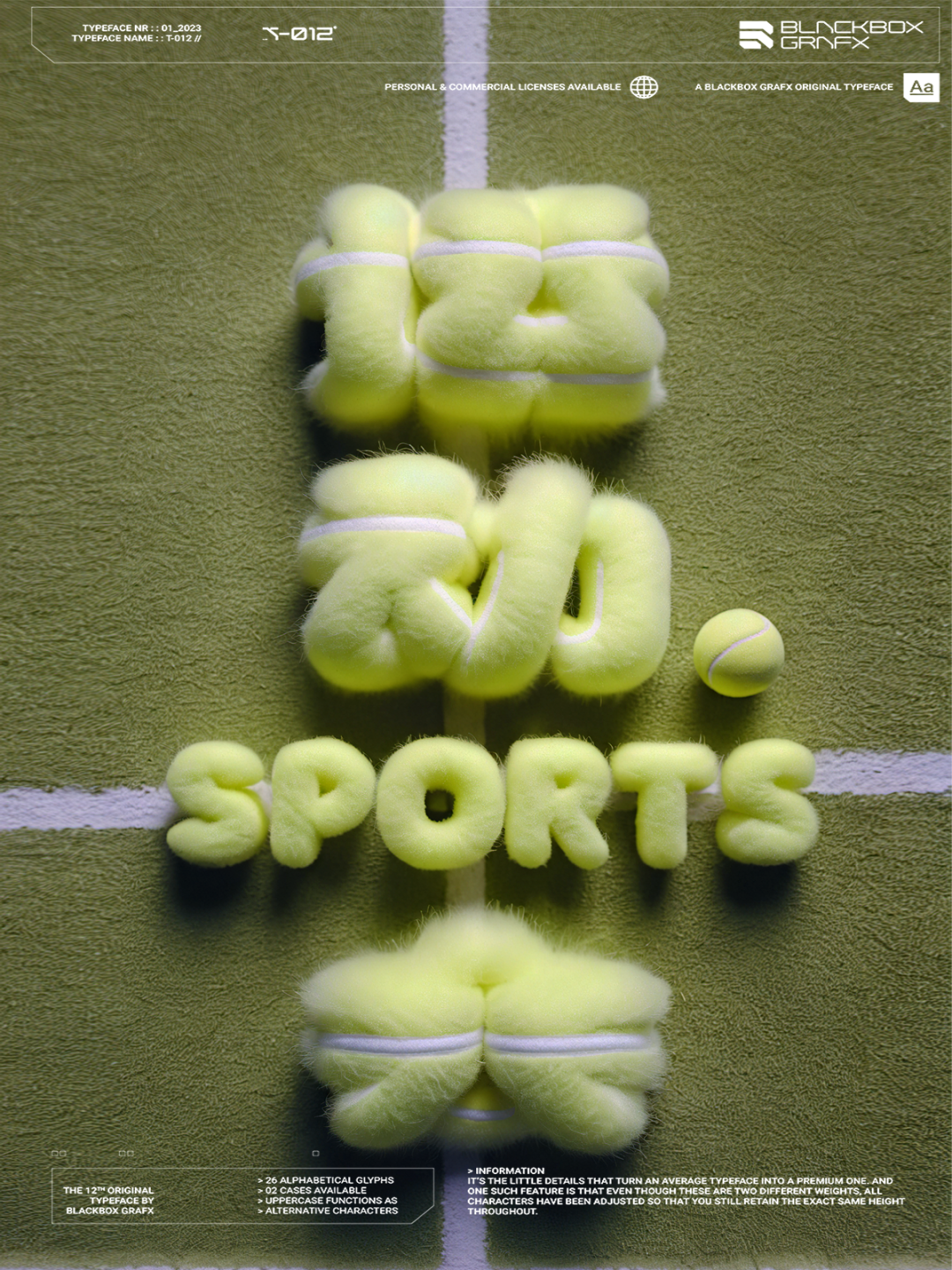
当然,如果有一个模板,甚至可以把这个模板使用节点合上去,不过我这里用的是PS.如果同学们对这个流程感兴趣,我会在未来这套免费课程里面分享这个流程的做法.
到此为止,大家已经初步了解两者的区别。其实都是AI绘图模型的两种不同方式,ComfyUI是大势所趋。所以大家如果想学习ComfyUI,有WebUI的基础更好,没有也没关系,也可以直接学习。
**AI为什么需要可控性?
**可控性是对AI的天马行空胡编乱画的一种约束.比如说我们常常提到的"垫图",就是通过上传参考图让AI生成类似风格或者构图的图像.这就是最常见的可控性.
举个例子,甲方经常觉得设计师做的东西不是自己想要的,这个时候只需要拿出一张图,告诉设计师,就照这个风格抄,往往能得到想要的结果.
在AI生成体系里,设计师是甲方,AI是设计师,我们使用垫图来告诉AI,按这个方向来生图.这就是AI生成里面的图生图的模式.
**在SD/Flux中,有很多重要的控制功能如下
LORA
**LORA是一种用于微调大模型的低秩适应技术.啥叫低秩适应不用管,简单来讲就是大模型是通过亿万张海量图片机器学习而来,普通人当然没有这个条件.但是我们可以通过少量特定风格图片来训练成LORA.这个家用显卡就可以做到.比如用100张黑神话的图来训练成LORA,然后通过使用训练后的LORA,我们可以很轻松的控制大模型生成黑神话风格的图片,上面的图片就是通过LORA生成的.大家应该听过AI炼丹,就是指的炼制LORA.
**IP-Adapter
**IP-Adapter是控制风格迁移的利器,有点类似于垫图,可以把一张图的风格,迁移到另一张图上面.不过大家需要注意,IP-Adapter主要控制的是风格,LORA控制的也是风格.IP-Adapter可以看做是一张图的LORA.
**Controlnet
**Controlnet是一种控制构图的技术,注意,和上面两个不同啦,是控制构图.通过线稿图/深度图/骨骼等方法来控制图像的构图,通过这个技术,可以生成某个动作的人物,或者某个构图的海报.比如通过字体来控型,生成字体海报.就用的是Controlnet


比如在电商领域中可以通过Controlnet里面的深度图控制所需产品的构图,从而保证征程的图片的轮廓和位置,可以大大节省后期合成的时间
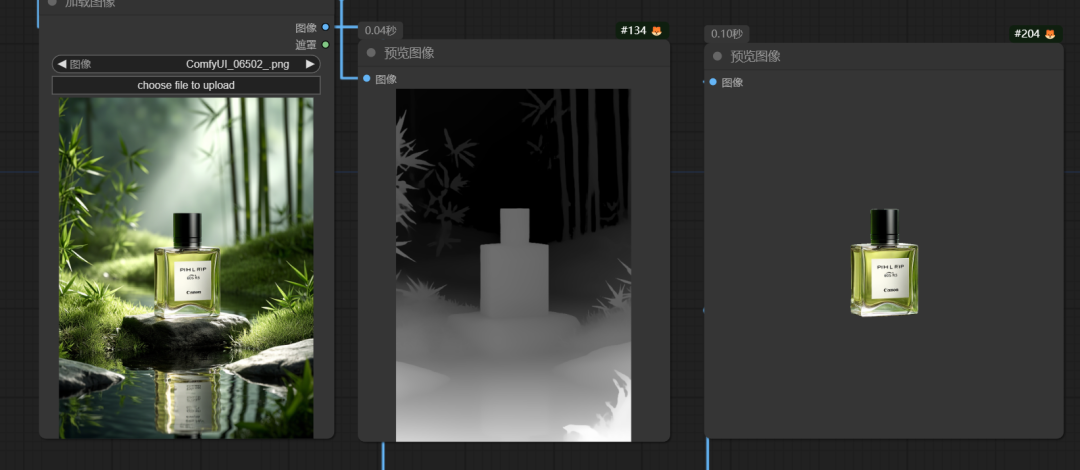


当然,除了控制之外,Comfy有N多的节点可以开发,比如生成的产品图片差强人意,也可以用inpaint技术来抹除主体.比如下图,产品不对,石头影响构图,所以抹掉,以便方便后期.


**另外同学们可能会有个疑惑,既然AI那么强大,还需要学习3D吗?
**
其实这个问题很简单,AI是辅助技能,学习更多技能,只是为了在工作中提高效率,更加游刃有余。
我们都知道决定都是领导和甲方定的,
以前的作图方式可能是花费一天时间使用PS或者C4D做一张图。这里面有试错成本。领导甲方不满意,就得重做。
而现在的方式是使用AI做50张不同风格的图,领导甲方从这里面挑一些继续细化。要求不高的话,这一步就领导就定稿了。
要求高的话,最后使用PS或者C4D做完稿或者动态。**
大多数情况下,选择哪个方案这并不是我们设计师能做的决定。我们能做的是给客户或者甲方更多选择,然后把这个稿子尽快推动落地。在一定时间内,尽量降低试错成本。**
要求低的情况下,AI=落地。
而要求高的情况下,AI可以降低试错成本,而PS或者3D负责落地。
但是AI有很多不足的地方,比如产品短片,AI完全没法做.现在一些主流AI视频模型已经迭代了大概3代,可控性依然比较差.这也可以理解,这是由AI生成的底层原理决定的.未来几年还需要使用3D软件去实现特定的动态效果.
**未来设计师不会AI会被淘汰吗?
**
和一些技术职业不同,设计师这个职业本来就是应该紧跟设计趋势的,降低焦虑的办法就是,紧跟趋势持续学习就可以了.
再说了,现在都卷,连一部分司机都被萝卜快跑替代了.何况我们设计师呢?
这里分享给大家一份Adobe大神整理的《AIGC全家桶学习笔记》,相信大家会对AIGC有着更深入、更系统的理解。
有需要的朋友,可以点击下方免费领取!

AIGC所有方向的学习路线思维导图
这里为大家提供了总的路线图。它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。如果下面这个学习路线能帮助大家将AI利用到自身工作上去,那么我的使命也就完成了:
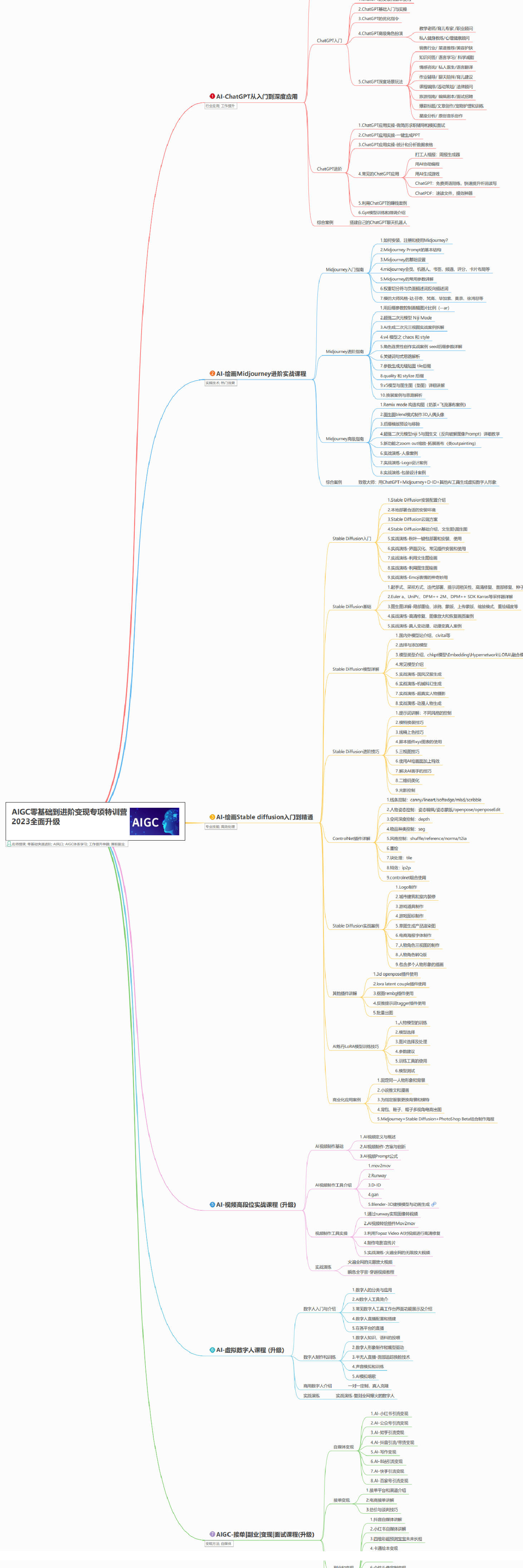
AIGC工具库
AIGC工具库是一个利用人工智能技术来生成应用程序的代码和内容的工具集合,通过使用AIGC工具库,能更加快速,准确的辅助我们学习AIGC

有需要的朋友,可以点击下方卡片免费领取!

精品AIGC学习书籍手册
书籍阅读永不过时,阅读AIGC经典书籍可以帮助读者提高技术水平,开拓视野,掌握核心技术,提高解决问题的能力,同时也可以借鉴他人的经验,结合自身案例融会贯通。
AI绘画视频合集
我们在学习的时候,往往书籍源码难以理解,阅读困难,这时候视频教程教程是就很适合了,生动形象加上案例实战,科学有趣才能更方便的学习下去。


















 1204
1204

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









