







摘要
本文研究了十种优化算法对BP神经网络的优化效果,包括鳑鲏鱼算法、鹦鹉算法、角蜥蜴算法、灰狼算法、河马算法、遗传算法、粒子群算法、冠状豪猪算法、大鹅算法和爱情优化算法。通过优化网络权重和偏置以提升BP神经网络的收敛速度和预测精度,实验结果表明,不同优化算法对BP神经网络在均方误差(MSE)、平均绝对误差(MAE)和拟合优度(R²)等指标上有显著影响。最终分析得出不同优化算法在不同应用场景下的适用性。
理论
BP神经网络是一种常用的前馈神经网络,通过误差反向传播算法更新权重和偏置。然而,其传统的梯度下降法存在易陷入局部最优和收敛速度慢的问题。优化算法的引入为BP神经网络的训练提供了新的路径,这些优化算法主要分为以下几类:
-
仿生算法:包括鳑鲏鱼、鹦鹉、角蜥蜴等,以模仿生物行为的方式解决优化问题。
-
群体智能算法:如粒子群算法、灰狼算法等,通过模拟群体协作行为提高优化效率。
-
进化算法:如遗传算法,通过选择、交叉和变异的机制增强全局搜索能力。
-
新兴算法:如爱情优化算法和冠状豪猪算法,结合了新颖的自然现象,具有高效的搜索性能。
每种算法根据其独特的搜索机制,分别在加速收敛和提高网络泛化性能方面展现出不同的优势。
实验结果
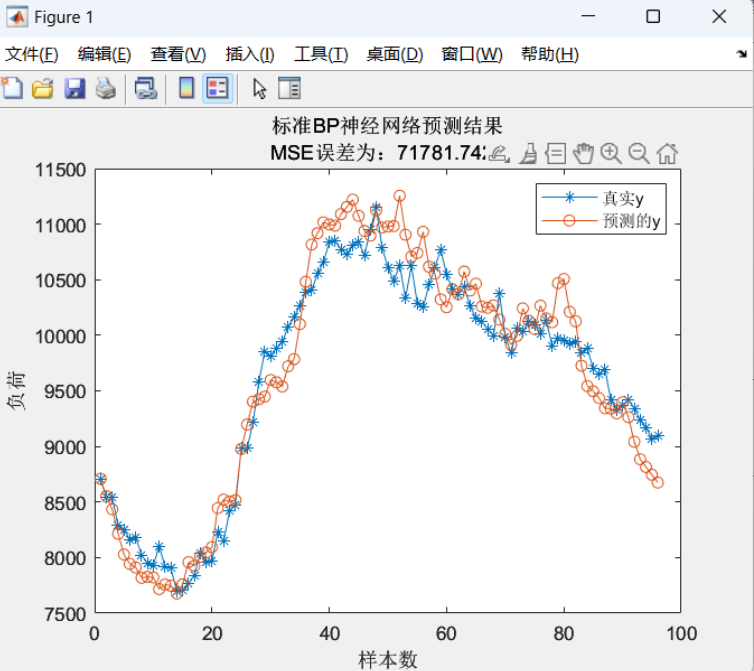
在实验中,分别采用上述十种优化算法对标准BP神经网络进行优化,并使用均方误差(MSE)、均方根误差(RMSE)、平均绝对误差(MAE)、拟合优度(R²)等指标评估其效果。
-
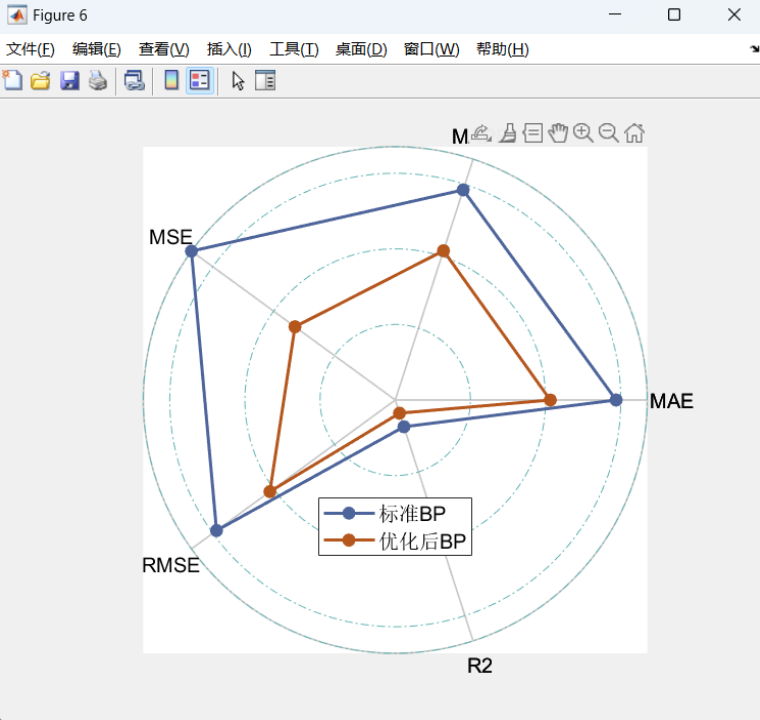
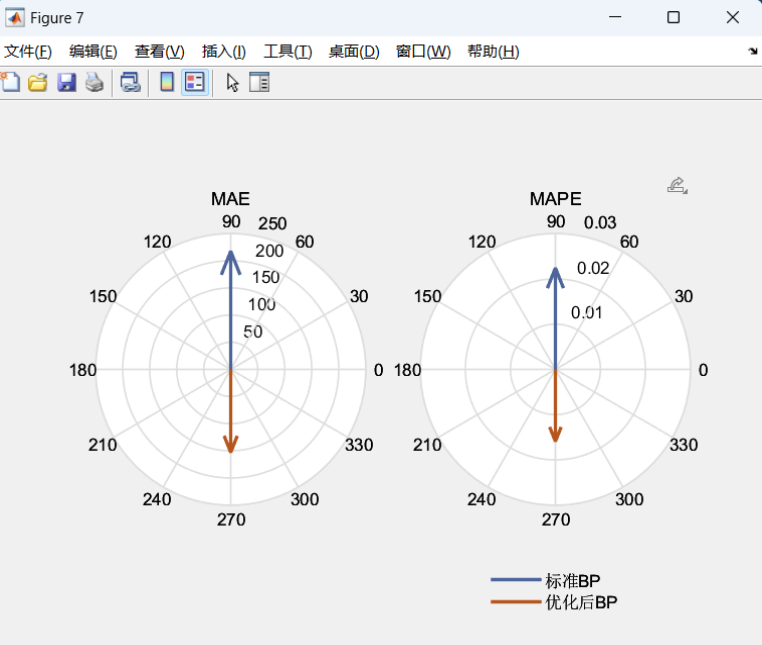
MSE和MAE对比:优化后BP神经网络的MSE和MAE均显著低于标准BP。
-
R²提高:优化后的BP网络对样本的拟合程度显著增强,拟合优度R²值提升。
-
不同算法性能比较:
-
在收敛速度方面,粒子群算法和爱情优化算法表现突出。
-
在精度优化上,灰狼算法和河马算法具有明显优势。
-
可视化结果:使用雷达图对比了不同算法在各性能指标上的表现
部分代码
% 初始化BP神经网络
net = feedforwardnet(10); % 隐藏层节点数为10
net.trainParam.epochs = 100; % 最大训练次数
net.trainParam.goal = 1e-6; % 训练目标误差
% 粒子群算法参数设置
n_particles = 30; % 粒子数量
n_iterations = 50; % 迭代次数
w = 0.5; % 惯性权重
c1 = 1.5; % 自我学习因子
c2 = 1.5; % 群体学习因子
% 初始化粒子群
positions = randn(n_particles, numel(getwb(net))); % 粒子初始位置
velocities = zeros(size(positions)); % 粒子速度
best_positions = positions; % 个体最优位置
global_best = positions(1, :); % 全局最优位置
% 优化过程
for iter = 1:n_iterations
for i = 1:n_particles
% 设置网络权重
net = setwb(net, positions(i, :)');
% 计算目标函数(均方误差)
outputs = net(input_data);
error = mse(net, target_data, outputs);
% 更新个体最优
if error < mse(net, target_data, net(best_positions(i, :)))
best_positions(i, :) = positions(i, :);
end
% 更新全局最优
if error < mse(net, target_data, net(global_best))
global_best = positions(i, :);
end
end
% 更新粒子速度和位置
for i = 1:n_particles
velocities(i, :) = w * velocities(i, :) + ...
c1 * rand * (best_positions(i, :) - positions(i, :)) + ...
c2 * rand * (global_best - positions(i, :));
positions(i, :) = positions(i, :) + velocities(i, :);
end
end
% 输出优化结果
net = setwb(net, global_best');
outputs = net(input_data);
fprintf('优化后的均方误差:%.4f\n', mse(net, target_data, outputs));
涉及技术
❝
Kennedy, J., & Eberhart, R. (1995). "Particle swarm optimization." Proceedings of IEEE International Conference on Neural Networks, 1942–1948.
Mirjalili, S., Mirjalili, S. M., & Lewis, A. (2014). "Grey Wolf Optimizer." Advances in Engineering Software, 69, 46–61.
Holland, J. H. (1992). "Adaptation in Natural and Artificial Systems." The MIT Press.
Dorigo, M., & Stützle, T. (2004). "Ant Colony Optimization." The MIT Press.
(文章内容仅供参考,具体效果以图片为准)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









