




 本文介绍了如何使用jieba库对文本进行分词,并统计词频,以农为主题生成词云图。作者强调了系统性学习的重要性,分享了一套免费的学习资源,并邀请读者加入技术交流社群,共同提升IT技能。
本文介绍了如何使用jieba库对文本进行分词,并统计词频,以农为主题生成词云图。作者强调了系统性学习的重要性,分享了一套免费的学习资源,并邀请读者加入技术交流社群,共同提升IT技能。

skls

通过解霸将句子分成字词:
import jieba # pkuseg
words=jieba.lcut(skls)
words
counts={} # items
mytextlist=[]
for word in words:
if len(word)==1: # 如果词语中只有一个字,比如‘的’,‘你’之类的就将其删除
continue
else:
counts[word]=counts.get(word,0)+1
mytextlist.append(word.replace(" “,”"))
cloud_text=‘,’.join(mytextlist)
items=list(counts.items())
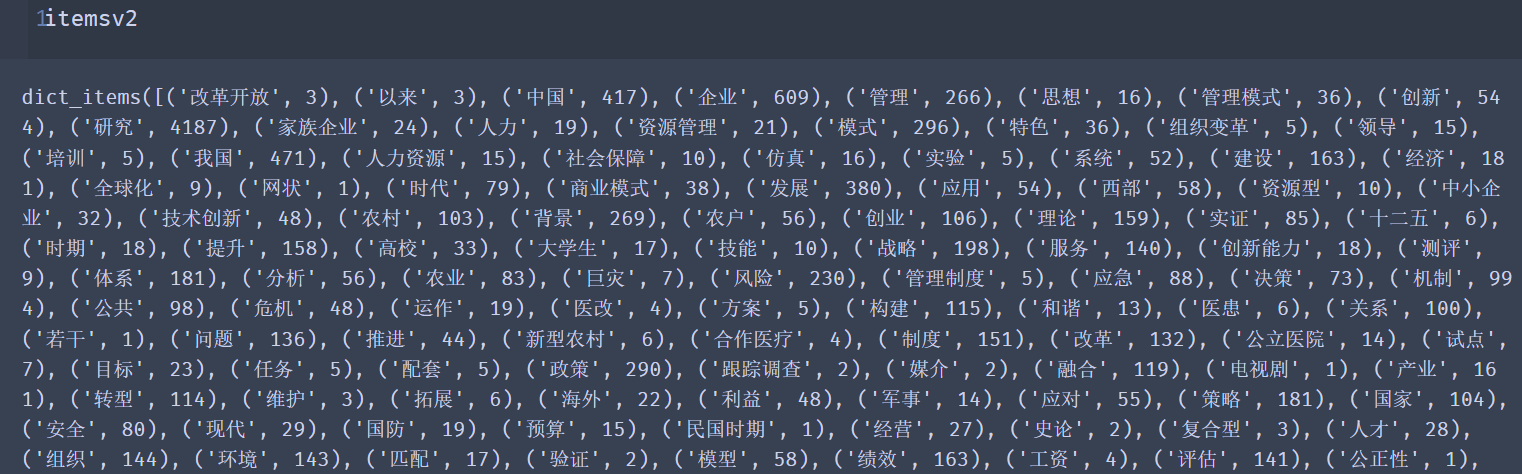
itemsv2=counts.items()
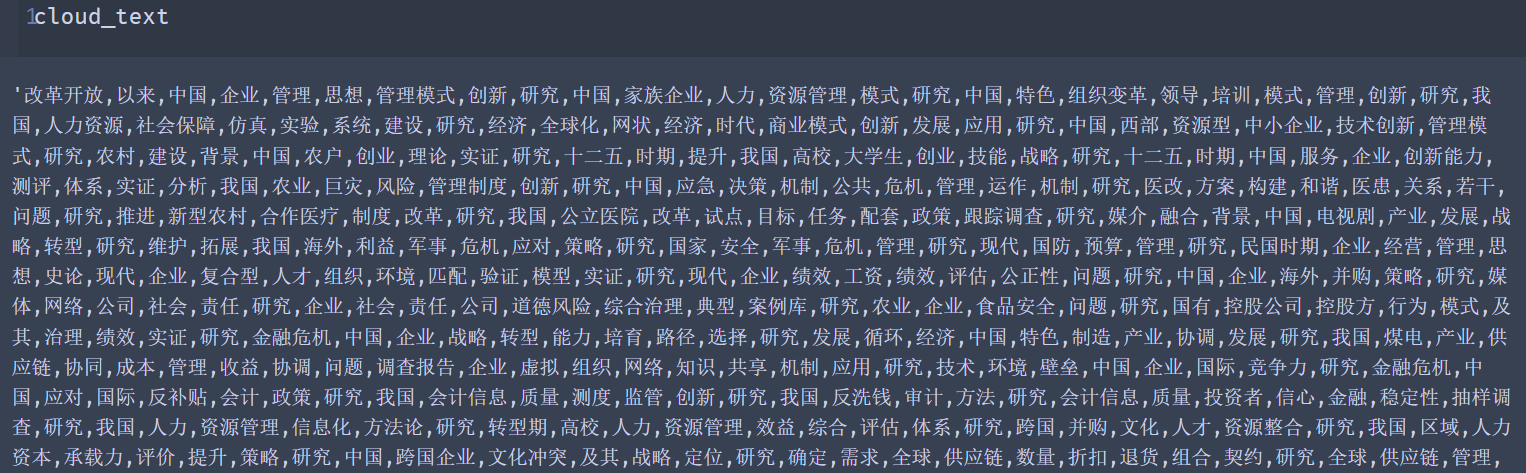
可以看到后面的数字就是词语出现的次数。
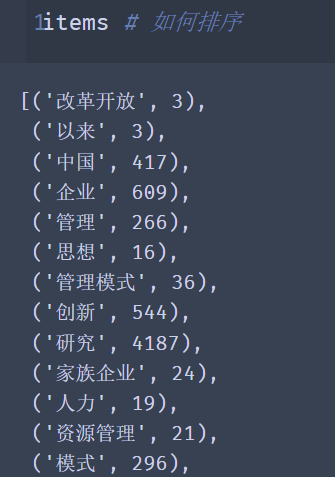
对items进行排序:
items.sort(key=lambda x:x[1],reverse=True) # 排序
for i in range(len(items)):
word,count=items[i]
找出词语中带有‘农’字的:
itemsv3={k:v for k,v in itemsv2 if ‘农’ in k}
itemsv3ls=list(itemsv3)

开始绘图!:
import os
cloud_mask=np.array(Image.open(‘zgv2.jpg’)) # 以中国地图为整体形状
bg_Image=np.array(Image.open(“YMG.jpg”)) # 调色盘,但由于这张图片整体是蓝色,所以数据大体也是蓝色
st=set([“FR”,“平方公里”,“成为”,“10”,“我们”,“可以”,“这个”,“这里”,“一个”,“就是”]) # 过滤
#生成wordcloud对象
wc = WordCloud(background_color=“white”,
mask=cloud_mask,
max_words=300,
font_path=“叶根友微刚体.TTF”, # 字体,在我前面上传的数据当中
min_font_size=5, # 最小字体
max_font_size=200, # 最大字体
width=800,
height=1200,
stopwords=st)
wc.generate(cloud_text)
image_colors=ImageColorGenerator(bg_Image)
plt.imshow(wc.recolor(color_func=image_colors))
plt.axis(“off”)
plt.show()
wc.to_file(“skwc01.png”) # 将图片进行保存
os.system(‘skwc01.png’) # 会自动跳出来生成的图片
查看图片请点击:》skwc01.png
使用系统自带的调色盘,可以呈现如下效果:
import os
cloud_mask=np.array(Image.open(‘zgv2.jpg’))
bg_Image=np.array(Image.open(“YMG.jpg”)) # 调色盘
现在能在网上找到很多很多的学习资源,有免费的也有收费的,当我拿到1套比较全的学习资源之前,我并没着急去看第1节,我而是去审视这套资源是否值得学习,有时候也会去问一些学长的意见,如果可以之后,我会对这套学习资源做1个学习计划,我的学习计划主要包括规划图和学习进度表。
分享给大家这份我薅到的免费视频资料,质量还不错,大家可以跟着学习

网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!

















 393
393

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









