 基于Python的文本分析与词云可视化:构建系统学习资源指南
基于Python的文本分析与词云可视化:构建系统学习资源指南





 本文介绍了如何使用Python进行词频分析,包括从CSV文件读取数据,使用jieba库分词,生成词云并结合中国地图背景。同时,作者提供了丰富的IT学习资源,强调了系统学习的重要性,以及欢迎加入一个技术交流和学习支持的IT社区。
本文介绍了如何使用Python进行词频分析,包括从CSV文件读取数据,使用jieba库分词,生成词云并结合中国地图背景。同时,作者提供了丰富的IT学习资源,强调了系统学习的重要性,以及欢迎加入一个技术交流和学习支持的IT社区。
import pandas as pd
skdfsorttjfilter =pd.read_csv(“skdfsorttjfilter.csv”,encoding=‘utf-8-sig’)
from PIL import Image #需要下载安装PIL包
import numpy as np
from wordcloud import WordCloud, ImageColorGenerator
from matplotlib import pyplot as plt
import pandas as pd
词频分析
sklist=[]
skforcut=[]
for i in skdfsorttjfilter[‘项目名称’]:
sklist.append(i)
skls=‘,’.join(sklist)
sklist

skls

通过解霸将句子分成字词:
import jieba # pkuseg
words=jieba.lcut(skls)
words
counts={} # items
mytextlist=[]
for word in words:
if len(word)==1: # 如果词语中只有一个字,比如‘的’,‘你’之类的就将其删除
continue
else:
counts[word]=counts.get(word,0)+1
mytextlist.append(word.replace(" “,”"))
cloud_text=‘,’.join(mytextlist)
items=list(counts.items())
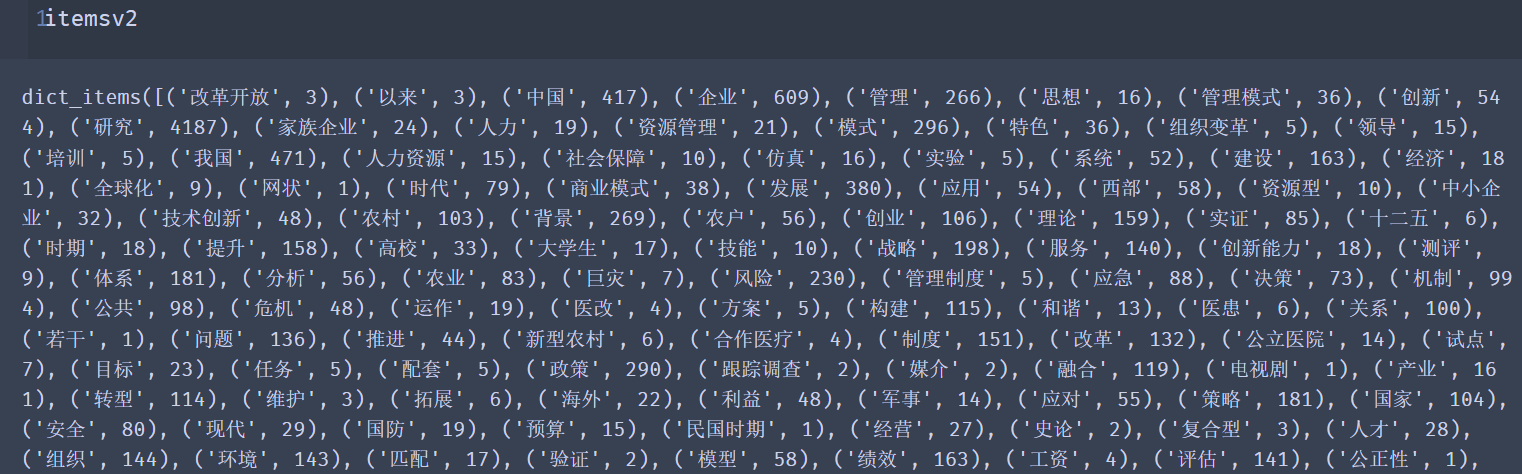
itemsv2=counts.items()
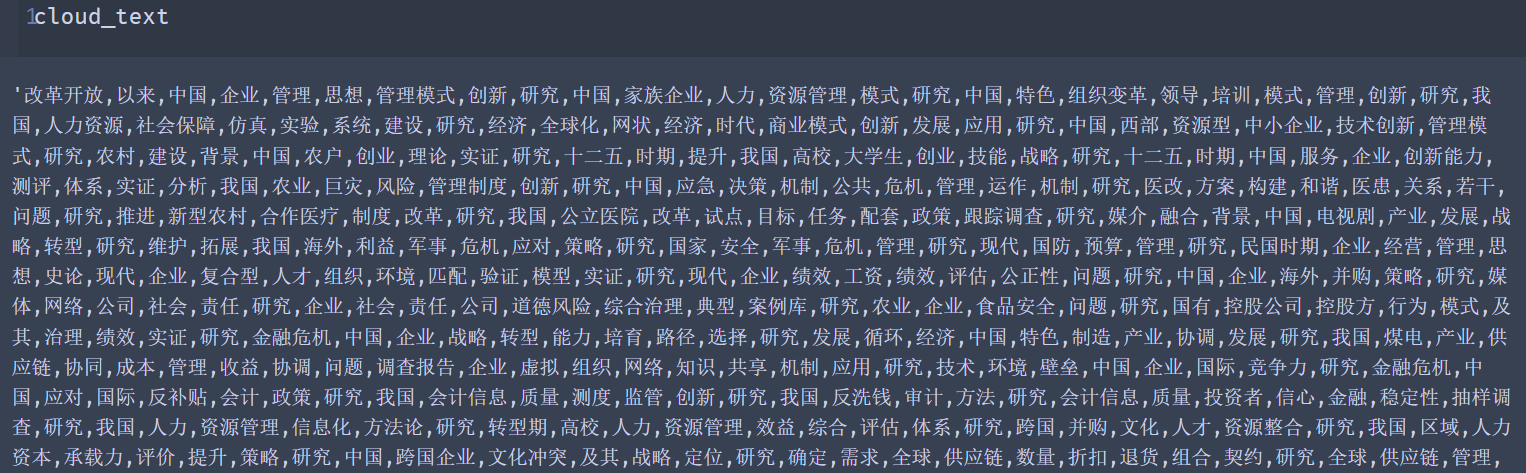
可以看到后面的数字就是词语出现的次数。
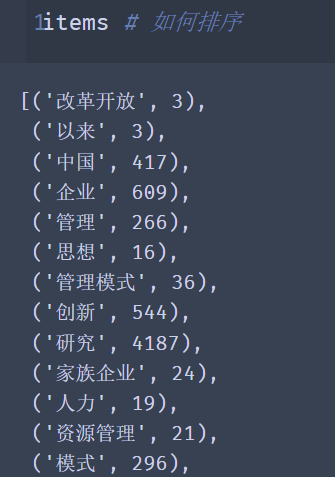
对items进行排序:
items.sort(key=lambda x:x[1],reverse=True) # 排序
for i in range(len(items)):
word,count=items[i]
找出词语中带有‘农’字的:
itemsv3={k:v for k,v in itemsv2 if ‘农’ in k}
itemsv3ls=list(itemsv3)

开始绘图!:
import os
cloud_mask=np.array(Image.open(‘zgv2.jpg’)) # 以中国地图为整体形状
bg_Image=np.array(Image.open(“YMG.jpg”)) # 调色盘,但由于这张图片整体是蓝色,所以数据大体也是蓝色
st=set([“FR”,“平方公里”,“成为”,“10”,“我们”,“可以”,“这个”,“这里”,“一个”,“就是”]) # 过滤
#生成wordcloud对象
wc = WordCloud(background_color=“white”,
mask=cloud_mask,
max_words=300,
font_path=“叶根友微刚体.TTF”, # 字体,在我前面上传的数据当中

感谢每一个认真阅读我文章的人,看着粉丝一路的上涨和关注,礼尚往来总是要有的:
① 2000多本Python电子书(主流和经典的书籍应该都有了)
② Python标准库资料(最全中文版)
③ 项目源码(四五十个有趣且经典的练手项目及源码)
④ Python基础入门、爬虫、web开发、大数据分析方面的视频(适合小白学习)
⑤ Python学习路线图(告别不入流的学习)
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!

















 393
393

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









